6 New updates
Unless otherwise indicated, the features below are available to all Google Workspace customers, and are fully launched or in the process of rolling out. Rollouts should take no more than 15 business days to complete if launching to both Rapid and Scheduled Release at the same time. If not, each stage of rollout should take no more than 15 business days to complete.
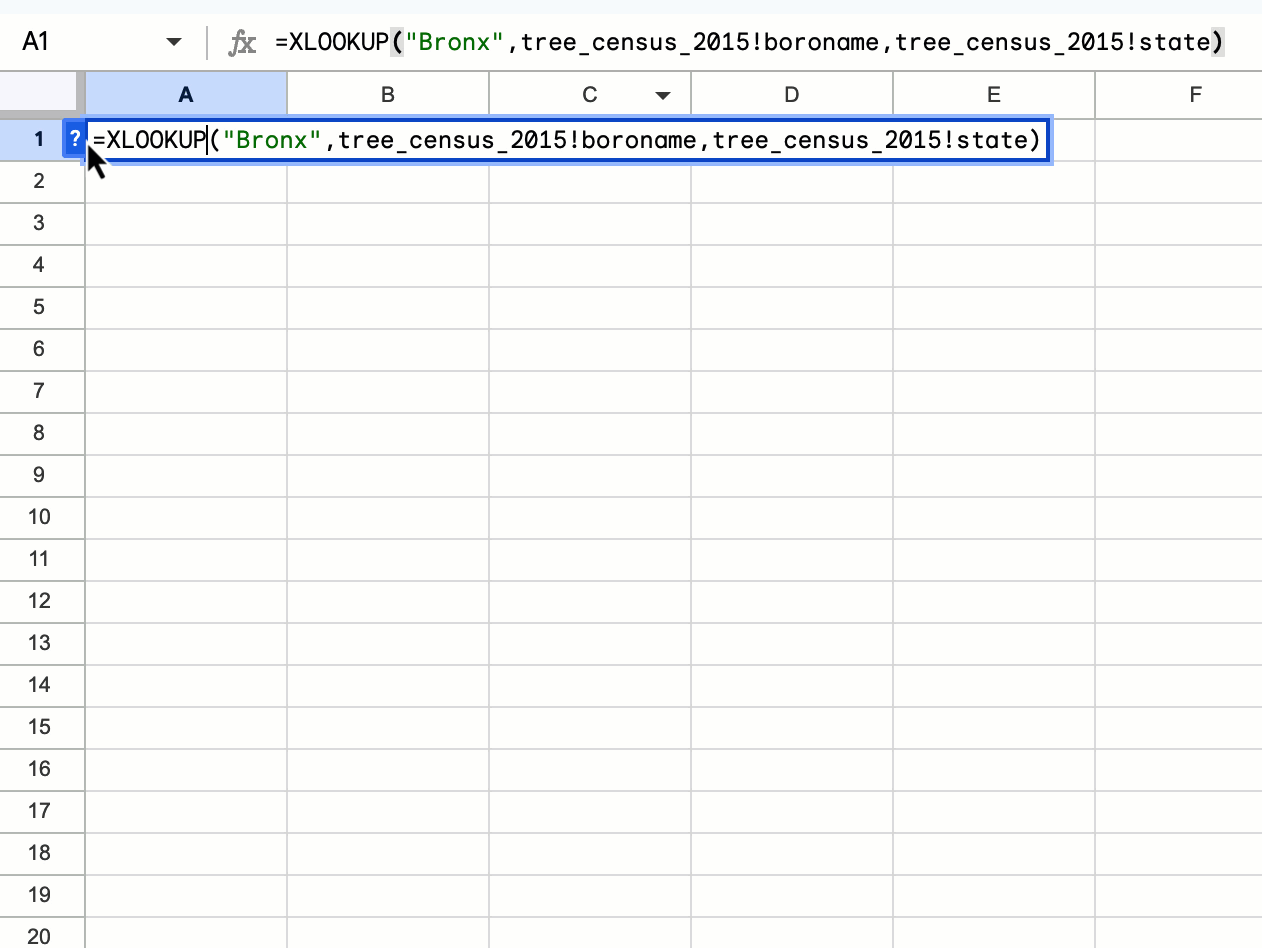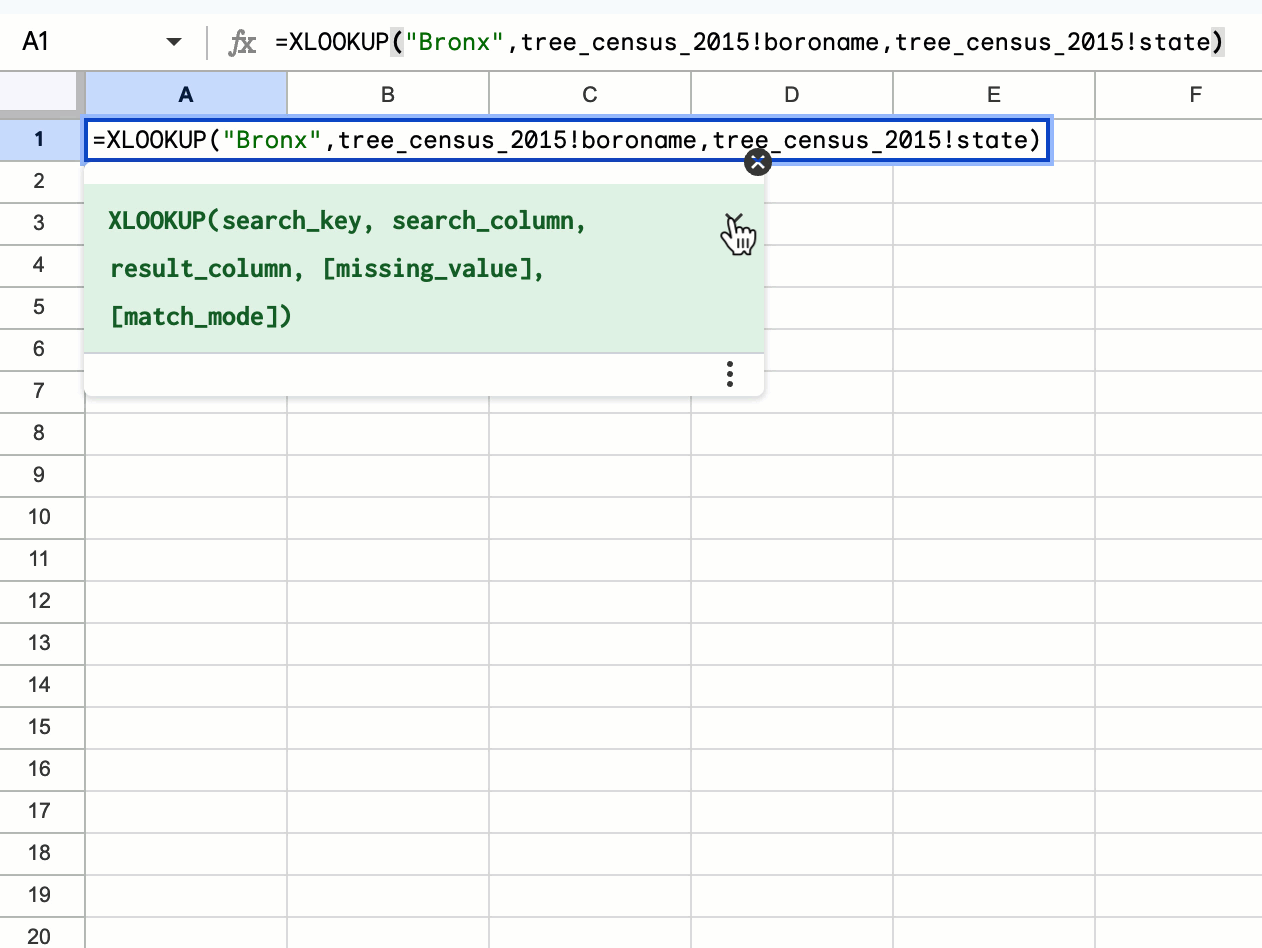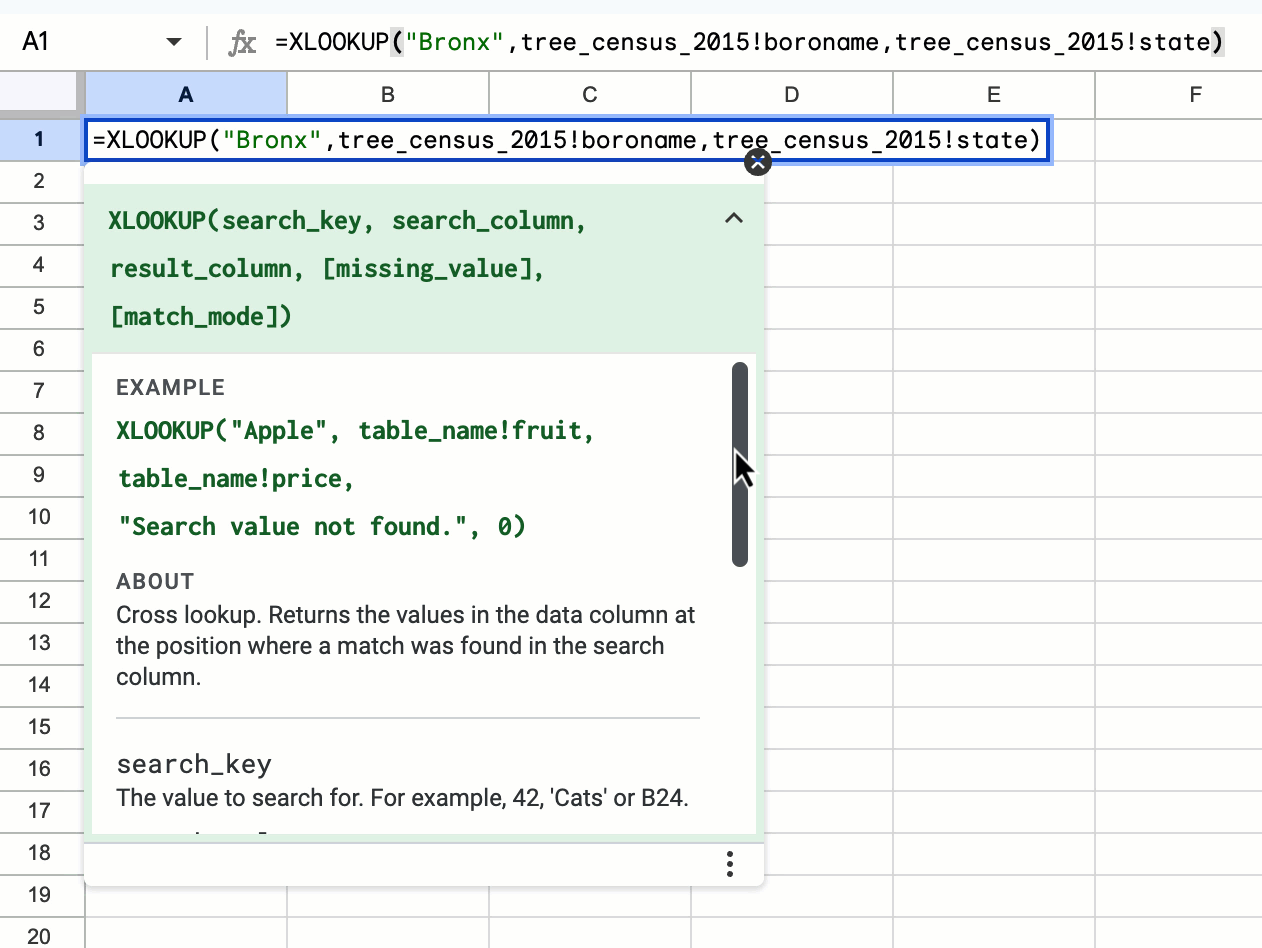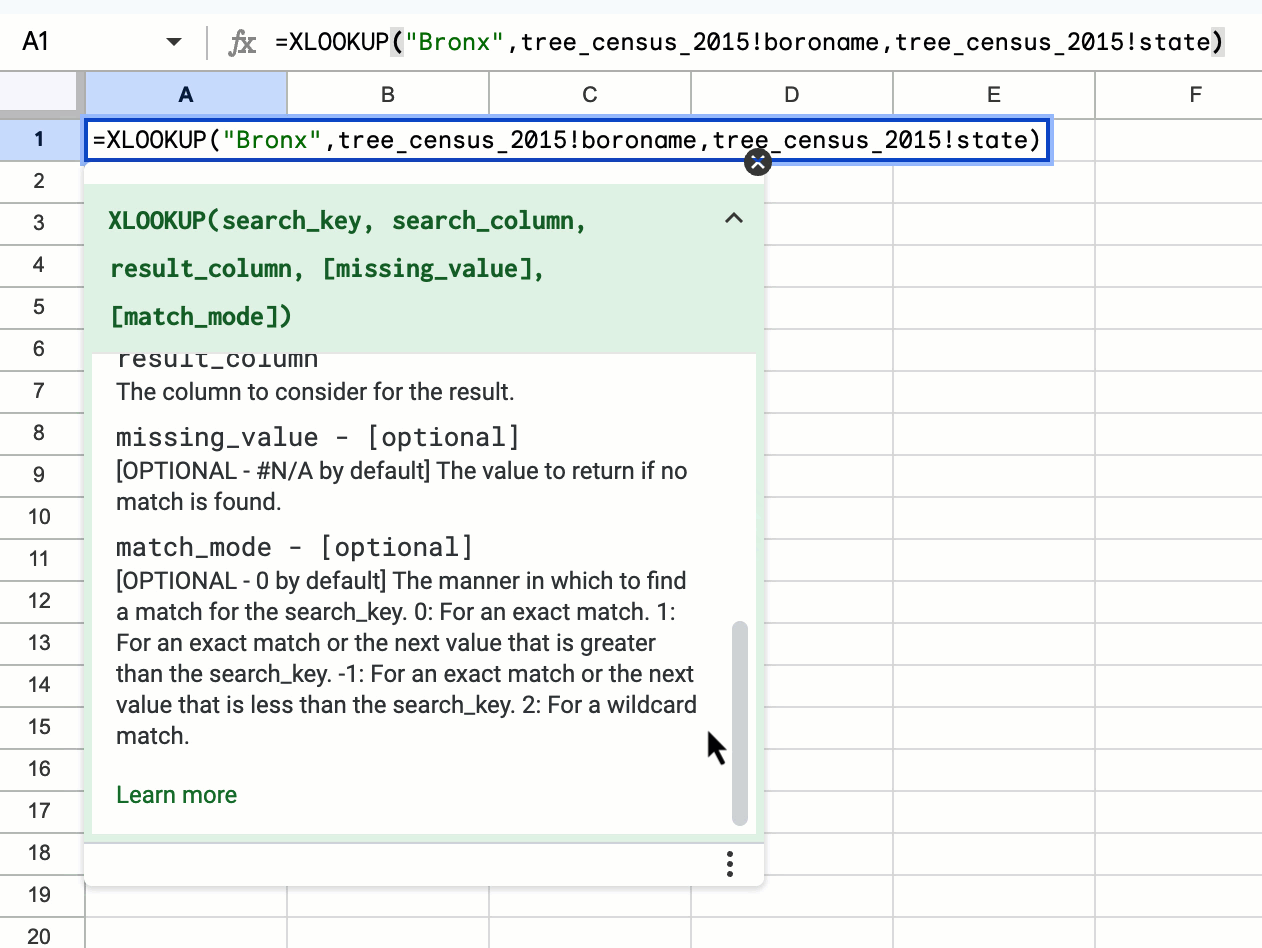
Easily connect to BigQuery data using Saved Queries in Connected Sheets
We’re launching direct access to the BigQuery saved queries feature directly from Connected Sheets. Users can now quickly and easily create a new Connected Sheet by selecting a previously saved query under any project they have access to. | Rolling out now to Rapid Release and Scheduled Release domains. | Available to all Google Workspace customers, Workspace Individual Subscribers, and users with personal Google accounts. | Learn more about analyzing & refreshing BigQuery data in Google Sheets using Connected Sheets, getting started with BigQuery data in Google Sheets and writing & editing a query.
Scan documents easier using Google Drive on Android devices
To improve upon the scanning experience in the Google Drive app on Android devices, we’re increasing the size and updating the style of the scan buttons. To scan something, open the Drive app on your Android device > scan a document > edit scan (if desired) > upload to Drive. | Rollout to Rapid Release domains is complete; Rolling out now to Scheduled Release domains, with expected completion by June 30, 2025. | Available to Google Workspace customers, Google Workspace Individual subscribers, and users with personal Google accounts. | Visit the Help Center to learn more about scanning documents with Google Drive.

Chat apps can now create spaces with their own identity using the Google Chat API
Last year, we introduced a feature through the Google Workspace Developer Preview Program that enables Chat apps to create spaces and memberships - using application identity - via the Google Chat API. This update further enhances Chat apps for real-time collaboration and allows for even more sophisticated and autonomous Chat apps by eliminating the need to create spaces and memberships on behalf of a user. This week, we’re excited to announce that this is now generally available for Google Workspace developers. | Rolling out now to Rapid Release and Scheduled Release domains. | Available to all Google Workspace customers. | Visit the Developer blog to see an example and learn more about what this means for developers. You can also visit our developer documentation to explore how to authenticate and authorize Chat apps, and learn how to create spaces and add space members using application identity.

Export Gemini responses to a Google Doc or Sheet from Gemini in the side panel of Google Drive
Users can collaborate with Gemini in Google Drive to perform various tasks, such as extracting data, drafting proposals, creating study guides and more. We’re excited to build upon this by giving users the ability to convert Gemini’s response directly into a Sheet or a Doc. After asking Gemini a question, click the ‘Export to Doc’ or ‘Export to Sheet’ button, and you’ll have an artifact that you can continue working on or share with others. | Rolling out now to Rapid Release and Scheduled Release domains. | Available to Business Standard and Plus; Enterprise Standard and Plus; Google One AI Premium; Customers with the Gemini Education or Gemini Education Premium add-on, and anyone who previously purchased a Gemini Business or Gemini Enterprise add-on. | Visit the Help Center to learn more about collaborating with Gemini in Google Drive.

Create even more interactive YouTube assignments in Google Classroom
In 2024, we added AI-suggested questions that educators can easily attach to the video based on its content to save educators time. Today, we’re excited to announce that we’re expanding the collection of YouTube videos that have AI-suggested questions available. As a result, educators can create even more interactive YouTube assignments in Classroom more quickly and efficiently, with the help of Gemini. Before assigning the interactive video activity, educators will be able to edit the suggested questions ahead of attaching the YouTube video to the assignment. | Rollout to Rapid Release and Scheduled Release domains is complete. | Available for Google Workspace Education Plus and the Teaching and Learning add-on. | Visit the Help Center to learn more about interactive questions for YouTube videos in Google Classroom.
Your users can now express interest in upgrading their Google Workspace subscription
We’re introducing a simple way for Workspace end users to request an upgraded edition of Google Workspace from their admins. To send this request, Workspace end users will see a path to request an upgraded Workspace edition including additional Gemini features when they interact with Gemini, such as with the Gemini icon displayed across Workspace apps. This interaction will provide an end user a path to complete a request form for an upgraded Workspace edition. Super admins will receive this request by email, and from there they can choose to upgrade their Workspace subscription directly in the Admin console. | Admins can disable these requests at any time in the Admin console by going to Account > Account Settings > Gemini for Google Workspace, and deselecting the ‘User-requested upgrades’ setting — use this article in our Help Center for more information. | Please note this is only available for customers in the US and India with fewer than 300 licenses. | Rolling out now to Rapid Release and Scheduled Release domains. | Learn more about Gemini for Workspace, including our recent Gemini for Workspace announcements.
Previous announcements
The announcements below were published on the Workspace Updates blog earlier this week. Please refer to the original blog posts for complete details.
Use Gemini in Drive to interact with folders in 20+ additional languages
Last year, we added folder support to Gemini in the side panel of Google Drive. This week, we’re excited to announce this experience is now available in 20+ languages. | Learn more about language availability for Gemini in Drive.
Use Gemini in Google Sheets to quickly add dropdowns, pivot tables, filters, and more
Analyzing and manipulating data in spreadsheets can be complex and time-consuming, even for experienced users. This week, we're introducing powerful new editing options within Gemini in Sheets that are designed to help everyone accomplish more, faster. | Learn more about Gemini in Sheets.
Google Workspace apps for Gmail, Google Drive, Google Docs, Calendar, Keep, and Tasks are now generally available for the Gemini app
Earlier this year, we launched Google Workspace apps (formerly known as "extensions") in Gemini in open beta. When enabled, Gemini can reference and incorporate data from these apps to generate even more informed and relevant responses, bringing Gemini’s capabilities more seamlessly into your daily workflows, helping enhance productivity. Workspace apps are available for: Calendar, Docs, Drive, Gmail, Keep, Tasks. | Learn more about Workspace apps in the Gemini app.
Extract and categorize data in AppSheet with the power of Gemini
At Google Cloud Next 2025, we introduced Gemini in AppSheet solutions for AppSheet Enterprise Plus users. Now you can automatically extract key information from uploaded photos, parse through complex PDFs, or even categorize, route and prioritize incoming requests based on their content – all seamlessly within your existing AppSheet apps. The new AI Task (Preview) feature, powered by Gemini, makes this a reality. | Learn more about Gemini in AppSheet.
Upcoming Changes to Microsoft Exchange Migrations
Beginning May 31, 2025, the legacy Data Migration Service will no longer support migrating email, calendar, and contact data from Microsoft Exchange on-premises servers (e.g., Exchange 2010, 2013, or 2016). Admins will not be able to start new migrations after May 31, 2025 – migrations that are in progress will continue until completion. | Learn more about changes to Microsoft Exchange Migrations.
Completed rollouts
The features below completed their rollouts to Rapid Release domains, Scheduled Release domains, or both. Please refer to the original blog posts for additional details.
Rapid Release Domains:
Scheduled Release Domains:
Rapid and Scheduled Release Domains:
- Educators can now upload content to Read Along in Google Classroom
- Control Workspace Business and Enterprise users’ access to new Google Workspace with Gemini features before general availability
- Updates for configuring your preferred language for “Take notes for me”, recorded captions, and meeting transcripts (Calendar availability)
- Generate and use images with Gemini in the side panel of Gmail on Android and iOS devices (Android only)
- Expanding Google Vids to Business Starter, Enterprise Starter and Nonprofit customers
- Google Voice gets support for three way calling and a refreshed in-call user interface
- Generate custom video clips in Google Vids with Veo 2
- Gemini app reporting now available for all Google Workspace for Education customers
- 2.5 Pro Preview: our latest Pro experimental model is now available in the Gemini app
- Audio Overview in the Gemini app is now available in 45 additional languages
- Use Gemini in Google Sheets to quickly add dropdowns, pivot tables, filters, and more
- Extract and categorize data in AppSheet with the power of Gemini
- Conduct in-depth two-way conversations with Gemini Live