Originally posted on
Google Cloud Platform Blog Posted by Sara Robinson, Developer Advocate
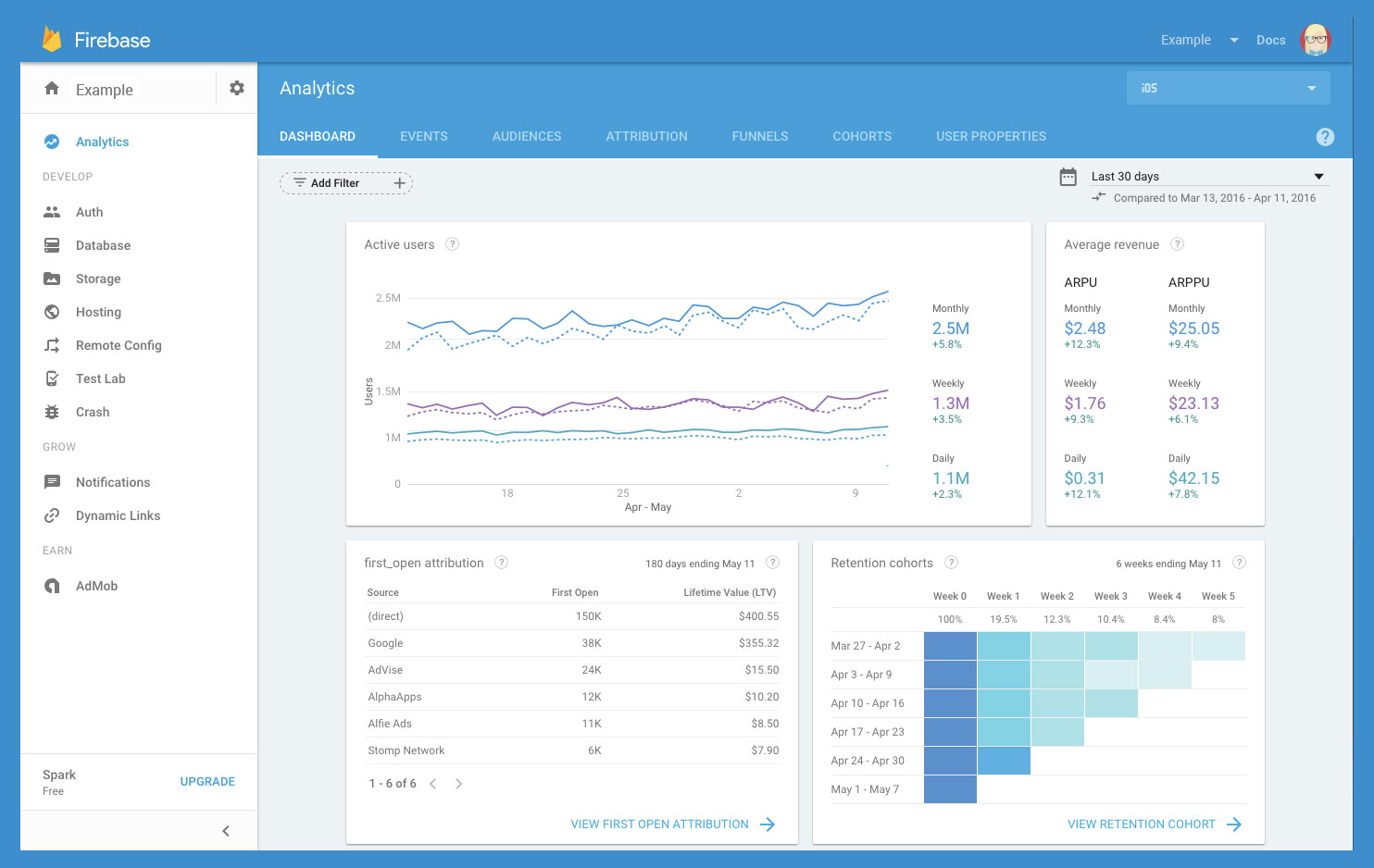
At Google I/O this May, Firebase
announced a new suite of products to help developers build mobile apps. Firebase Analytics, a part of the new Firebase platform, is a tool that automatically captures data on how people are using your iOS and Android app, and lets you define your own custom app events. When the data's captured, it’s available through a dashboard in the Firebase console. One of my favorite cloud integrations with the new Firebase platform is the ability to export raw data from Firebase Analytics to
Google BigQuery for custom analysis. This custom analysis is particularly useful for aggregating data from the iOS and Android versions of your app, and accessing custom parameters passed in your Firebase Analytics events. Let’s take a look at what you can do with this powerful combination.
How does the BigQuery export work?
After
linking your Firebase project to BigQuery, Firebase automatically exports a new table to an associated BigQuery dataset every day. If you have both iOS and Android versions of your app, Firebase exports the data for each platform into a separate dataset. Each table contains the user activity and demographic data automatically captured by Firebase Analytics, along with any custom events you’re capturing in your app. Thus, after exporting one week’s worth of data for a cross-platform app, your BigQuery project would contain two datasets, each with seven tables:
Diving into the data
The schema for every Firebase Analytics export table is the same, and we’ve created two datasets (
one for iOS and
one for Android) with sample user data for you to run the example queries below. The datasets are for a sample cross-platform iOS and Android gaming app. Each dataset contains seven tables
— one week’s worth of analytics data.
The following query will return some basic user demographic and device data for one day of usage on the iOS version of our app:
SELECT
user_dim.app_info.app_instance_id,
user_dim.device_info.device_category,
user_dim.device_info.user_default_language,
user_dim.device_info.platform_version,
user_dim.device_info.device_model,
user_dim.geo_info.country,
user_dim.geo_info.city,
user_dim.app_info.app_version,
user_dim.app_info.app_store,
user_dim.app_info.app_platform
FROM
[firebase-analytics-sample-data:ios_dataset.app_events_20160601]
Since the schema for every BigQuery table exported from Firebase Analytics is the same, you can run any of the queries in this post on your own Firebase Analytics data by replacing the dataset and table names with the ones for your project.
The schema has user data and event data. All user data is automatically captured by Firebase Analytics, and the event data is populated by any custom events you add to your app. Let’s take a look at the specific records for both user and event data.
User data
The user records contain a unique app instance ID for each user (
user_dim.app_info.app_instance_id in the schema), along with data on their location, device and app version. In the Firebase console, there are separate dashboards for the app’s Android and iOS analytics. With BigQuery, we can run a query to find out where our users are accessing our app around the world across both platforms. The query below makes use of BigQuery’s
union feature, which lets you use a comma as a
UNION ALL operator. Since a row is created in our table for each bundle of events a user triggers, we use
EXACT_COUNT_DISTINCT to make sure each user is only counted once:
SELECT
user_dim.geo_info.country as country,
EXACT_COUNT_DISTINCT( user_dim.app_info.app_instance_id ) as users
FROM
[firebase-analytics-sample-data:android_dataset.app_events_20160601],
[firebase-analytics-sample-data:ios_dataset.app_events_20160601]
GROUP BY
country
ORDER BY
users DESC
User data also includes a
user_properties record, which includes attributes you define to describe different segments of your user base, like language preference or geographic location. Firebase Analytics captures
some user properties by default, and you can create up to 25 of your own.
A user’s language preference is one of the default user properties. To see which languages our users speak across platforms, we can run the following query:
SELECT
user_dim.user_properties.value.value.string_value as language_code,
EXACT_COUNT_DISTINCT(user_dim.app_info.app_instance_id) as users,
FROM
[firebase-analytics-sample-data:android_dataset.app_events_20160601],
[firebase-analytics-sample-data:ios_dataset.app_events_20160601]
WHERE
user_dim.user_properties.key = "language"
GROUP BY
language_code
ORDER BY
users DESC
Event data
Firebase Analytics makes it easy to log custom events such as tracking item purchases or button clicks in your app. When you log an event, you pass an event name and up to 25 parameters to Firebase Analytics and it automatically tracks the number of times the event has occurred. The following query shows the number of times each event in our app has occurred on Android for a particular day:
SELECT
event_dim.name,
COUNT(event_dim.name) as event_count
FROM
[firebase-analytics-sample-data:android_dataset.app_events_20160601]
GROUP BY
event_dim.name
ORDER BY
event_count DESC
If you have another type of value associated with an event (like item prices), you can pass it through as an optional value parameter and filter by this value in BigQuery. In our sample tables, there is a spend_virtual_currency event. We can write the following query to see how much virtual currency players spend at one time:
SELECT
event_dim.params.value.int_value as virtual_currency_amt,
COUNT(*) as num_times_spent
FROM
[firebase-analytics-sample-data:android_dataset.app_events_20160601]
WHERE
event_dim.name = "spend_virtual_currency"
AND
event_dim.params.key = "value"
GROUP BY
1
ORDER BY
num_times_spent DESC
Building complex queries
What if we want to run a query across both platforms of our app over a specific date range? Since Firebase Analytics data is split into tables for each day, we can do this using BigQuery’s
TABLE_DATE_RANGE function. This query returns a count of the cities users are coming from over a one week period:
SELECT
user_dim.geo_info.city,
COUNT(user_dim.geo_info.city) as city_count
FROM
TABLE_DATE_RANGE([firebase-analytics-sample-data:android_dataset.app_events_], DATE_ADD('2016-06-07', -7, 'DAY'), CURRENT_TIMESTAMP()),
TABLE_DATE_RANGE([firebase-analytics-sample-data:ios_dataset.app_events_], DATE_ADD('2016-06-07', -7, 'DAY'), CURRENT_TIMESTAMP())
GROUP BY
user_dim.geo_info.city
ORDER BY
city_count DESC
We can also write a query to compare mobile vs. tablet usage across platforms over a one week period:
SELECT
user_dim.app_info.app_platform as appPlatform,
user_dim.device_info.device_category as deviceType,
COUNT(user_dim.device_info.device_category) AS device_type_count FROM
TABLE_DATE_RANGE([firebase-analytics-sample-data:android_dataset.app_events_], DATE_ADD('2016-06-07', -7, 'DAY'), CURRENT_TIMESTAMP()),
TABLE_DATE_RANGE([firebase-analytics-sample-data:ios_dataset.app_events_], DATE_ADD('2016-06-07', -7, 'DAY'), CURRENT_TIMESTAMP())
GROUP BY
1,2
ORDER BY
device_type_count DESC
Getting a bit more complex, we can write a query to generate a report of unique user events across platforms over the past two weeks. Here we use
PARTITION BY and
EXACT_COUNT_DISTINCT to de-dupe our event report by users, making use of user properties and the
user_dim.user_id field:
SELECT
STRFTIME_UTC_USEC(eventTime,"%Y%m%d") as date,
appPlatform,
eventName,
COUNT(*) totalEvents,
EXACT_COUNT_DISTINCT(IF(userId IS NOT NULL, userId, fullVisitorid)) as users
FROM (
SELECT
fullVisitorid,
openTimestamp,
FORMAT_UTC_USEC(openTimestamp) firstOpenedTime,
userIdSet,
MAX(userIdSet) OVER(PARTITION BY fullVisitorid) userId,
appPlatform,
eventTimestamp,
FORMAT_UTC_USEC(eventTimestamp) as eventTime,
eventName
FROM FLATTEN(
(
SELECT
user_dim.app_info.app_instance_id as fullVisitorid,
user_dim.first_open_timestamp_micros as openTimestamp,
user_dim.user_properties.value.value.string_value,
IF(user_dim.user_properties.key = 'user_id',user_dim.user_properties.value.value.string_value, null) as userIdSet,
user_dim.app_info.app_platform as appPlatform,
event_dim.timestamp_micros as eventTimestamp,
event_dim.name AS eventName,
event_dim.params.key,
event_dim.params.value.string_value
FROM
TABLE_DATE_RANGE([firebase-analytics-sample-data:android_dataset.app_events_], DATE_ADD('2016-06-07', -7, 'DAY'), CURRENT_TIMESTAMP()),
TABLE_DATE_RANGE([firebase-analytics-sample-data:ios_dataset.app_events_], DATE_ADD('2016-06-07', -7, 'DAY'), CURRENT_TIMESTAMP())
), user_dim.user_properties)
)
GROUP BY
date, appPlatform, eventName
If you have data in Google Analytics for the same app, it’s also possible to
export your Google Analytics data to BigQuery and do a JOIN with your Firebase Analytics BigQuery tables.
Visualizing analytics data
Now that we’ve gathered new insights from our mobile app data using the raw BigQuery export, let’s visualize it using
Google Data Studio. Data Studio can read directly from BigQuery tables, and we can even pass it a custom query like the ones above. Data Studio can generate many different types of charts depending on the structure of your data, including time series, bar charts, pie charts and geo maps.
For our first visualization, let’s create a bar chart to compare the device types from which users are accessing our app on each platform. We can paste the mobile vs. tablet query above directly into Data Studio to generate the following chart:
From this chart, it’s easy to see that iOS users are much more likely to access our game from a tablet. Getting a bit more complex, we can use the above event report query to create a bar chart comparing the number of events across platforms:
Check out
this post for detailed instructions on connecting your BigQuery project to Data Studio.
What’s next?
If you’re new to Firebase, get started
here. If you’re already building a mobile app on Firebase, check out
this detailed guide on linking your Firebase project to BigQuery. For questions, take a look at the
BigQuery reference docs and use the
firebase-analytics and
google-bigquery tags on Stack Overflow. And
let me know if there are any particular topics you’d like me to cover in an upcoming post.