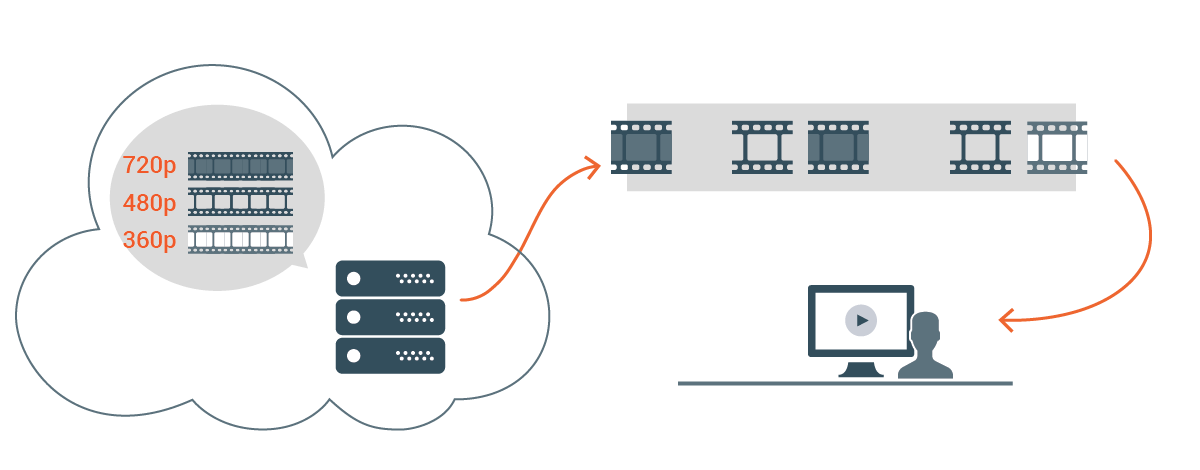
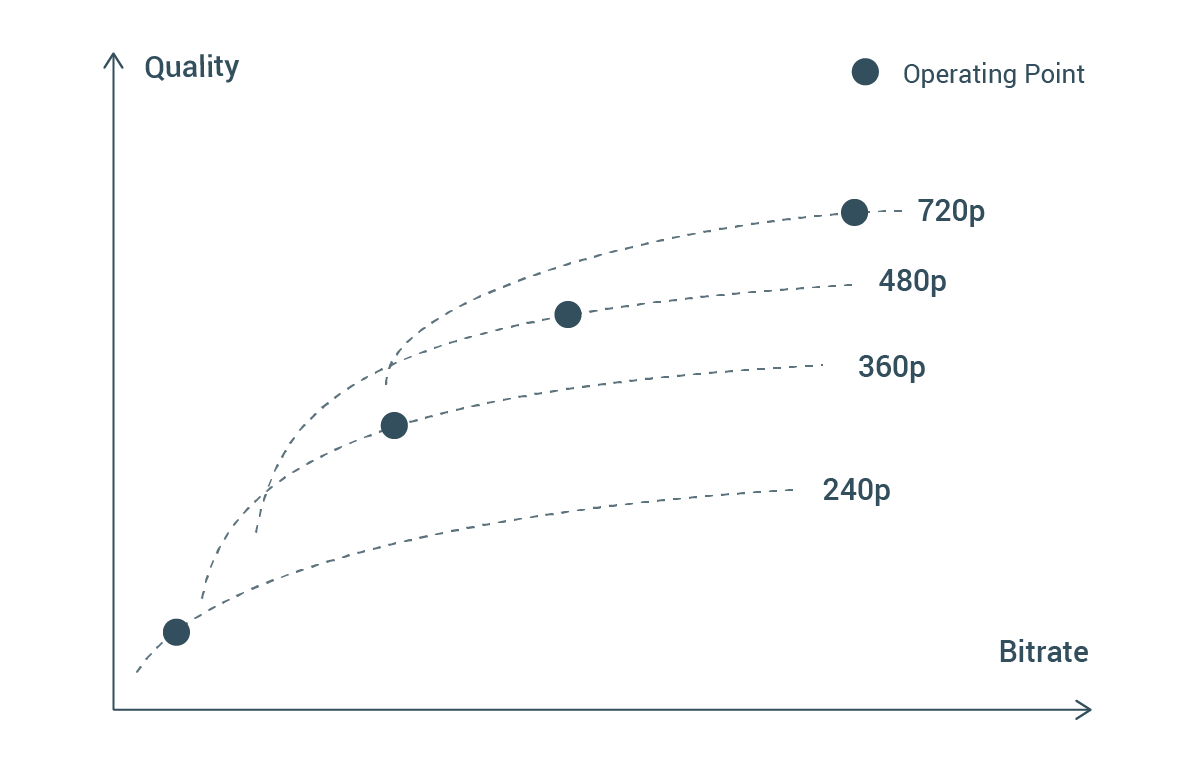
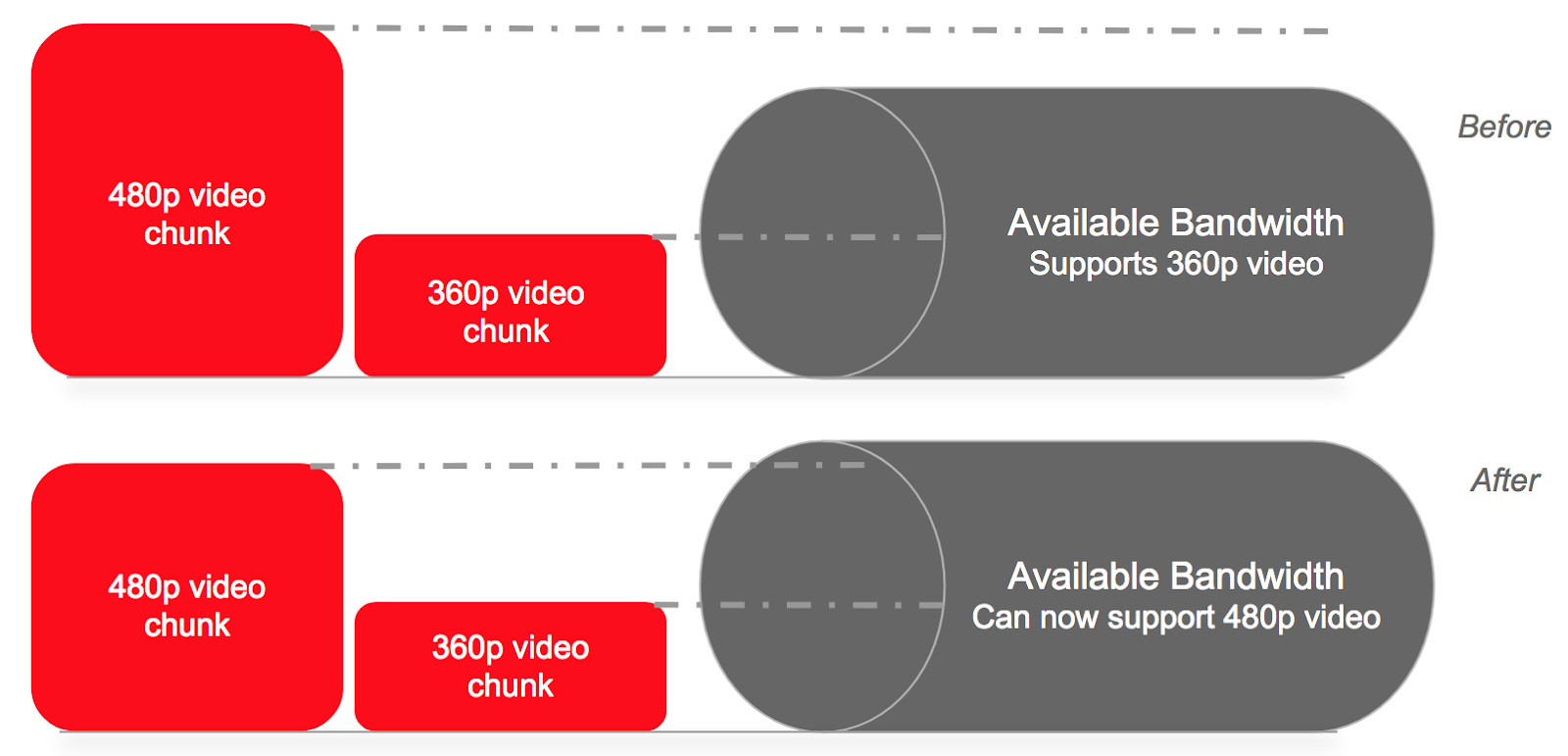
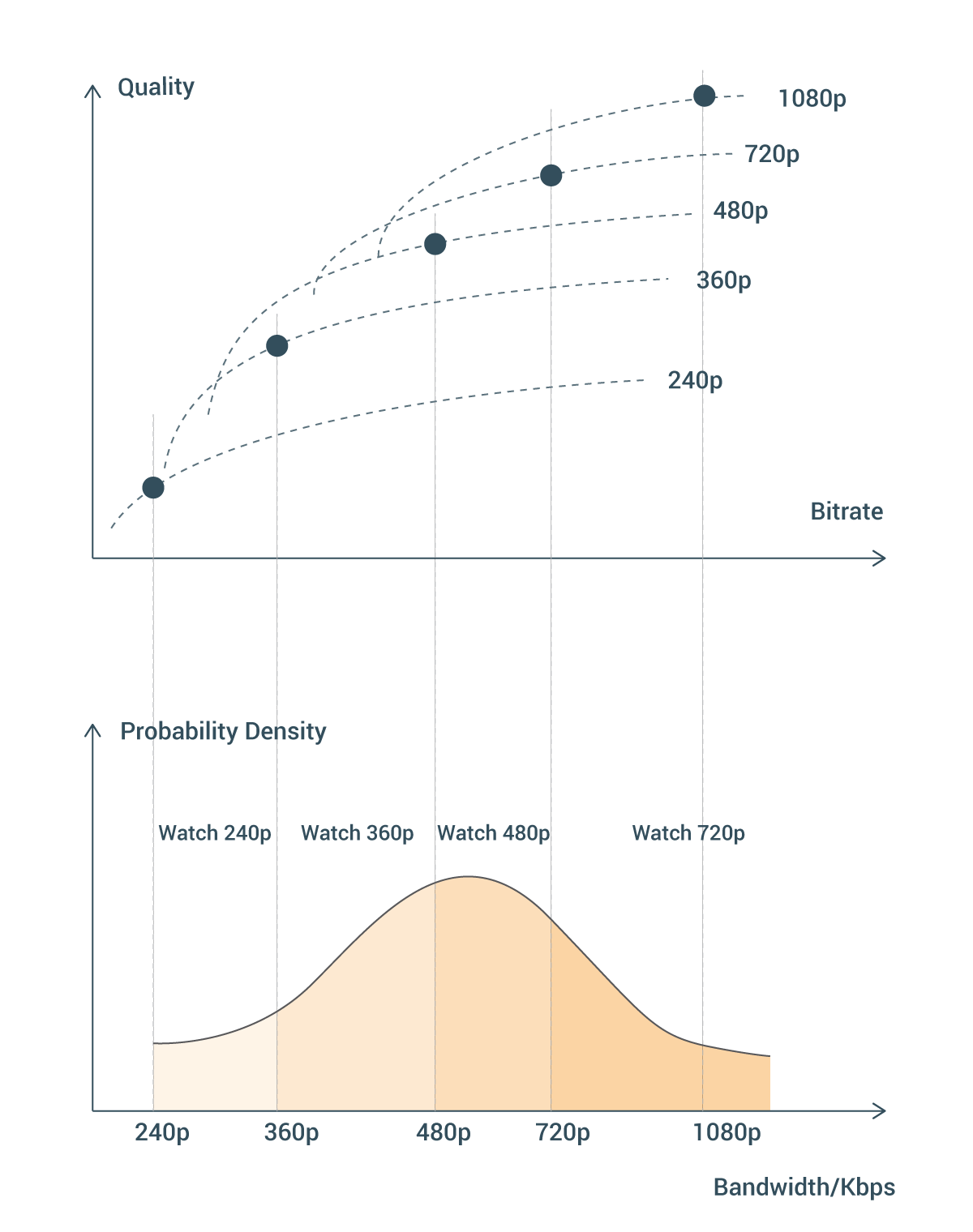
We are excited to launch a large-scale dataset of public user-generated content (UGC) videos uploaded to YouTube under a Creative Commons license. This dataset is intended to aid the advancement of research on video compression and quality evaluation.
We created this dataset to help baseline research efforts, as well as foster algorithmic development. We hope that this dataset will help the industry better comprehend UGC quality and tackle UGC challenges at scale.
What is UGC?
User-generated content (UGC) videos are uploaded by users and creators. These videos are not always professionally curated and could exhibit perceptual artifacts. For the purpose of this dataset, we've selected original videos with specific and perceptual quality issues, like blockiness, blur, banding, noise, jerkiness, and so on.
These videos have a wide array of categories, such as “how to” videos, technology reviews, gaming, pets, etc.
Since these videos are often captured in environments without controlled lighting, with ambient noise, or on low-end capture devices, they may end up exhibiting various video quality issues, such as camera shaking, low visibility, or jarring audio.
Before sharing these videos, creators may edit the video for aesthetics and generally compress the captured video for a faster upload (e.g. depending on the network conditions). Creators also may annotate the video or add additional overlays. The editing, annotating, and overlaying processes change the underlying video data at the pixel and/or frame levels. Additionally, any associated compression may introduce visible compression artifacts within the video such as blockiness, banding, or ringing.
For these reasons, in our experience, UGC should be evaluated and treated differently from traditional, professional video.
The challenges with UGC
Processing and encoding UGC video presents a variety of challenges that are less prevalent in traditional video.
For instance, look at these clips shown below that are heavily ridden with blockiness and noise. Many modern video codecs would target their encoding algorithms based on reference-based metrics, such as PSNR or SSIM. These metrics measure the fidelity of accurately reproducing the original content roughly pixel for pixel, including artifacts. The assumption here is that the video that acts as the reference is “pristine,” but for UGC, this assumption often breaks down.
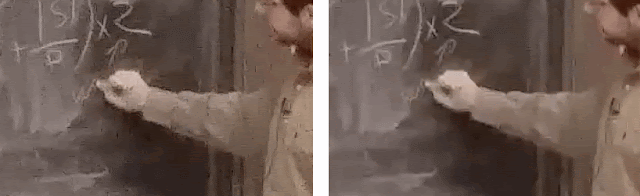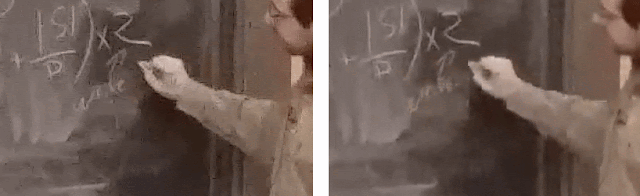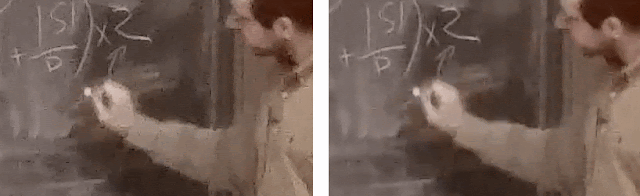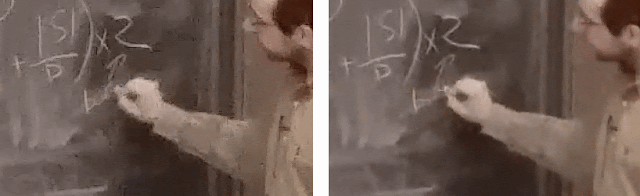
In this case, the videos on the left ends up having 5 Mbps bitrate to faithfully represent the originally uploaded user video content. However, the heavily compressed video on the right has a bitrate of only 1 Mbps, but looks similar when compared to the 5 Mbps counterpart.
Another unconventional challenge can come from a lack of understanding of the provided quality of the uploaded video. With traditional video, quite often a lower quality is a result of heavy editing or processing and an un-optimized encoding. However, this is not always true for UGC, where the uploaded video itself could be sufficiently low quality that any number of optimizations on the encoding operation would not increase the quality of the encoded video.
How is the dataset put together?
This dataset is sampled from millions of YouTube uploaded videos licensed under a Creative Commons license. Only publicly shared videos from uploaders are sampled.
The sample space the videos were chosen from can be divided into four discrete dimensions: Spatial, Motion, Color, and Chunk-level variations. We believe that this dataset reasonably represents the variety of content that we observe as uploads within these dimensions.
For technical details on how this dataset was composed, the coverage correlations scores and more, please refer to our
paper on dataset generation in arxiv (also submitted to ICIP 2019).
Where can I see and download it?
This UGC dataset can be explored over various content categories and resolutions in the explore tab of
media.withyoutube.com. The video preview will be shown when you mouse-over the video, along with an overlay of the attribution.
Various content categories are separated out for simplicity of selection. HDR and VR formats are available in addition for each resolution. Though some high frame rate content is present as part of the offering, it is not currently separated out as a category. Frame rate information is embedded in the video metadata and can be obtained when the corresponding video is downloaded.
Videos can be downloaded from the download tab of
media.withyoutube.com page. Here you will also notice the
CC BY creative commons attribution file for the whole set of videos. Details about the video download format along with the link to the
Google Cloud Platform location are available on this page.
Additionally, three no-reference metrics that have been computed on the UGC video dataset by the YouTube Media Algorithms team are available to download from this page. These three metrics are Noise, Banding, and SLEEQ. Explanations of each were published in ICIPs and ACM Multimedia Conferences.
Posted by Balu Adsumilli, Sasi Inguva, Yilin Wang, Jani Huoponen, Ross Wolf.https://00e9e64bace9f5e25eea751bfc166a8b1fbaa1ba7953e385ec-apidata.googleusercontent.com/download/storage/v1/b/ugc-dataset/o/ugc_dataset.pdf?qk=AD5uMEubH8dw1x99vqYiYYT-xf8d2C6SaB68mY_STRb02_DIfFsYUNL5oaYz5nLDe-wSUHpvz91A0qWfScMWs19Vru89BLon5YrNy0ed0x50Weo-jrTNPzOP14BpJgA7bu-H0t4zTidJITRw8u9FP0AKPuDhDsXJXI5NpffFF_ilsR93DbbVK_6t-iIF772CYxGFE9aYvgSrLHJDy6Q81H4uMhJKgE5jcEwLGhpEdYy1Hsa31rBMxy03cAmEBkqjKXHxAn5Ap0qAGpfAKeJ6aEQaKat14OlfOiAhCH9Bw2bN5BD5LE3b1X-tcTyrmb6zdGzIOJo2qDltBsD9ug3Hy-H7BRDYCOSszG_m88xqiiQ0Rx6ElsnkK5jG17atPf7o3Iefb7CLD2DsPZfKKXdDbOdR-q5THFYl9M15Jg2lfBaYjztT7Kv4aX2rTzl0-C1t5pAcEiIlCO0eMmCv7Vx7BV-s-YsEMk_vwfgd3X58lbezgoIgg651cEN4EGqx2_X2vZP0JJjV5sRDvr3_KZnnpRyhM8xUL_-f2OMKEHGYe0Gw4FqcdU4n1Lu70ezWvQ3E4yx3FGXjIs8w6jxBhP3H5Of4EsbWUScXoNflzTI65R1JR1KGojSvf_oZ0jgXya2KzwW4sBD2bb9w_BTqH3K_CpdGXQ7a-XCc8Jns7dQVQDyB4uxzDSb4HGfry1y3LzFMpCDBwsjKwLbea3BL7Keq6DdIntEsQOJZE0VUgrQ7DdGUklj3rF-D2mtVP7IZ5n9oUvAYVL4wqbRVuOS4lP6w-MHEeGYVoOYgnA