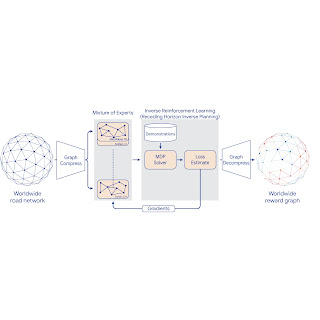
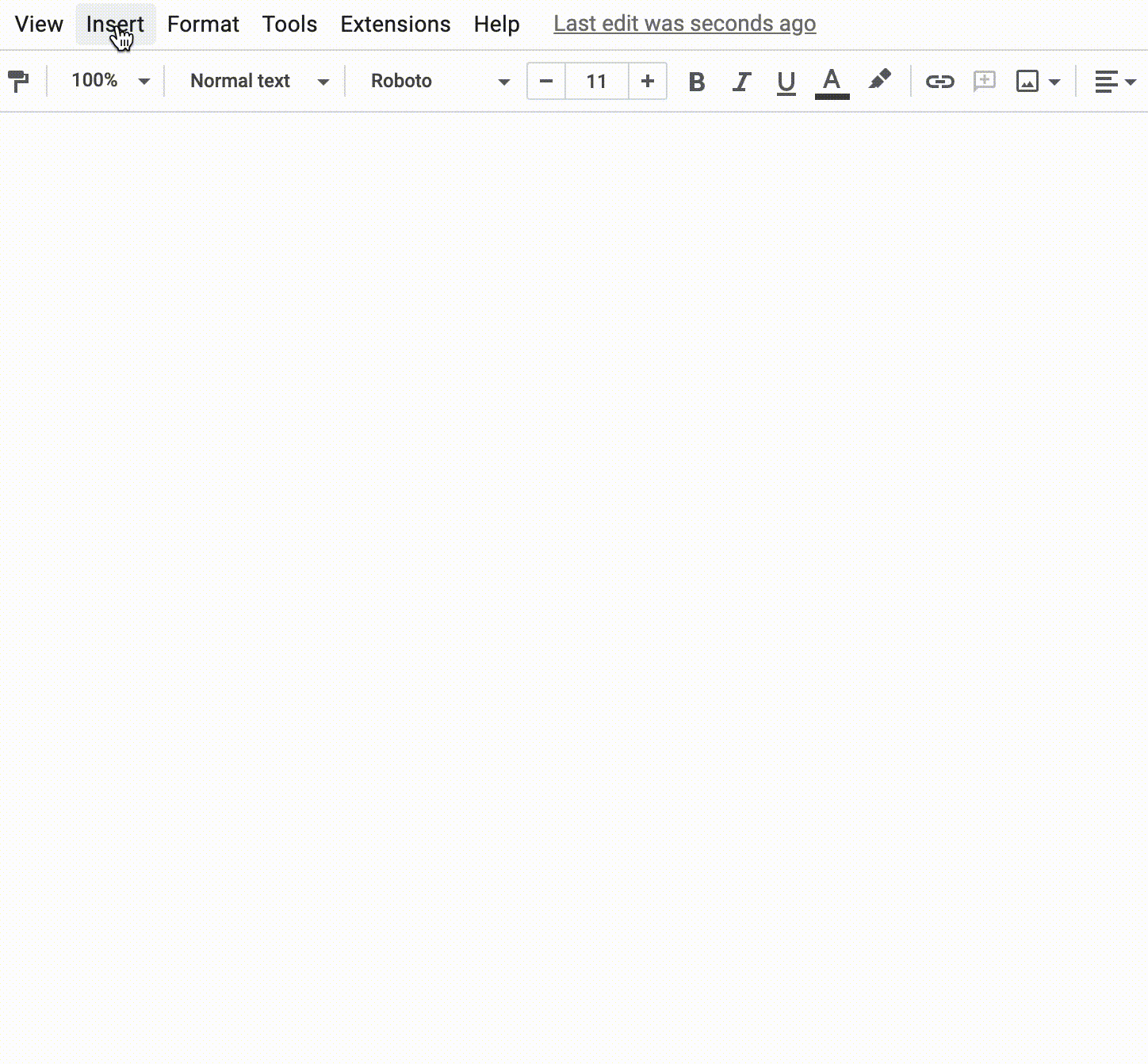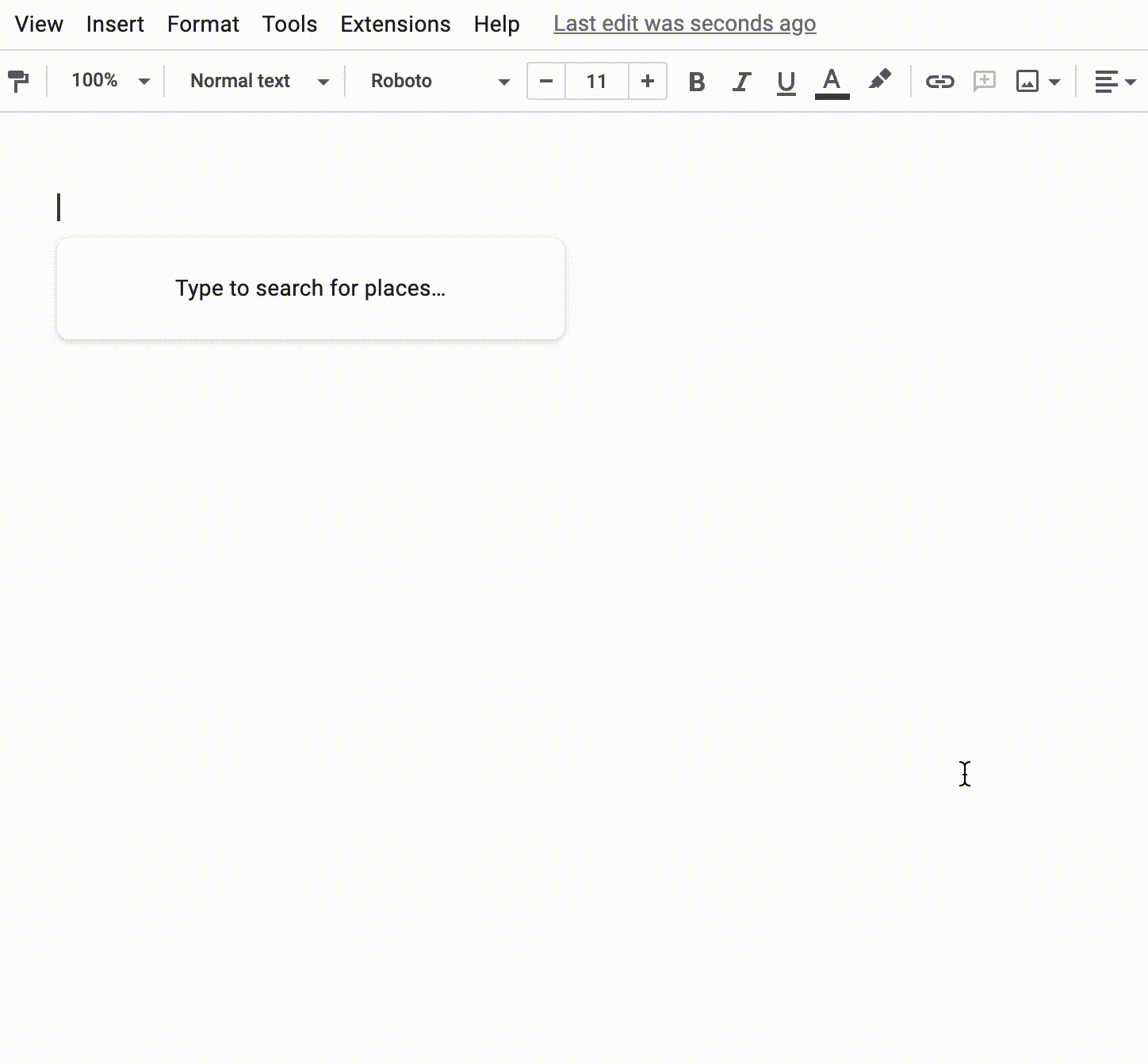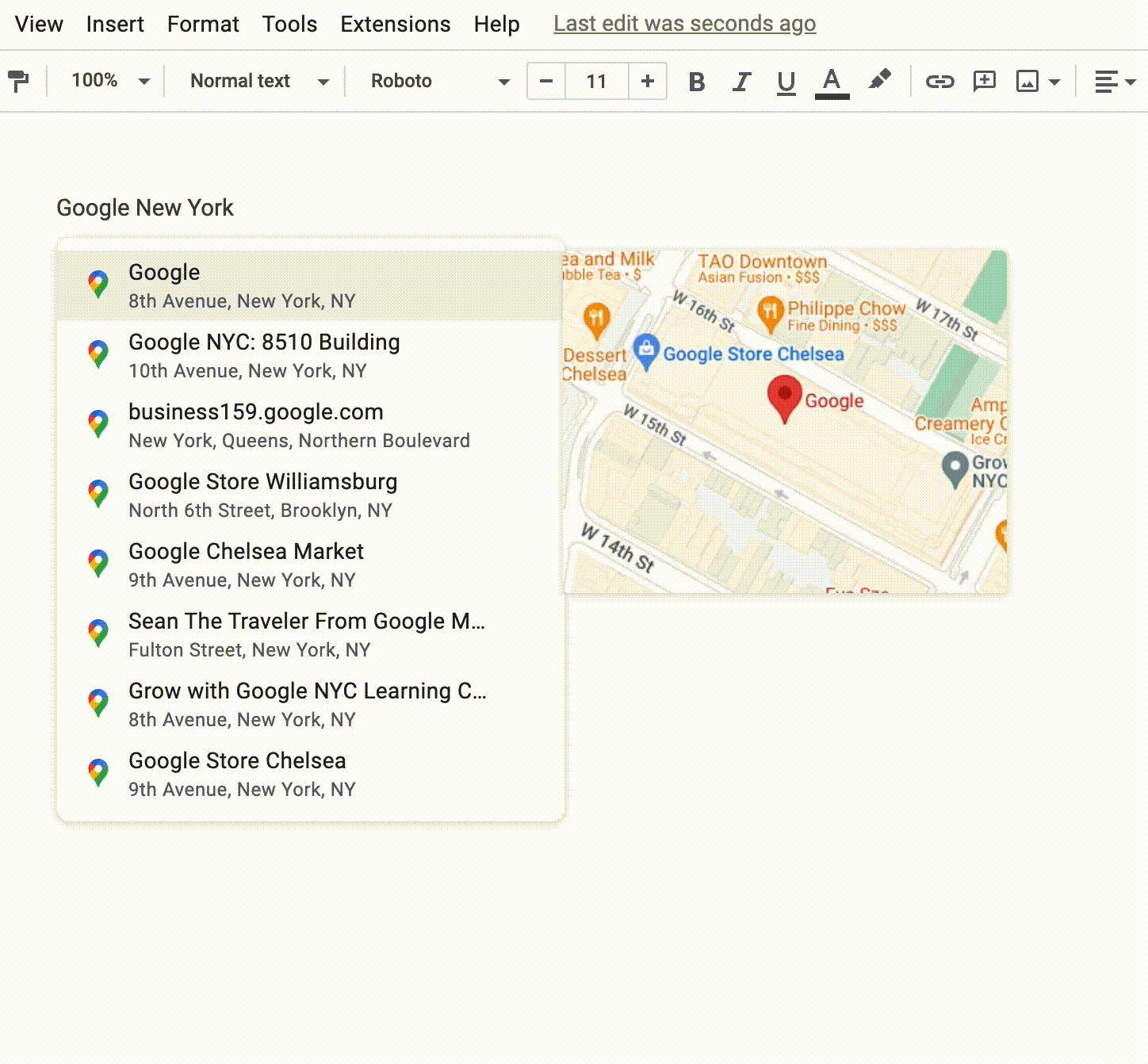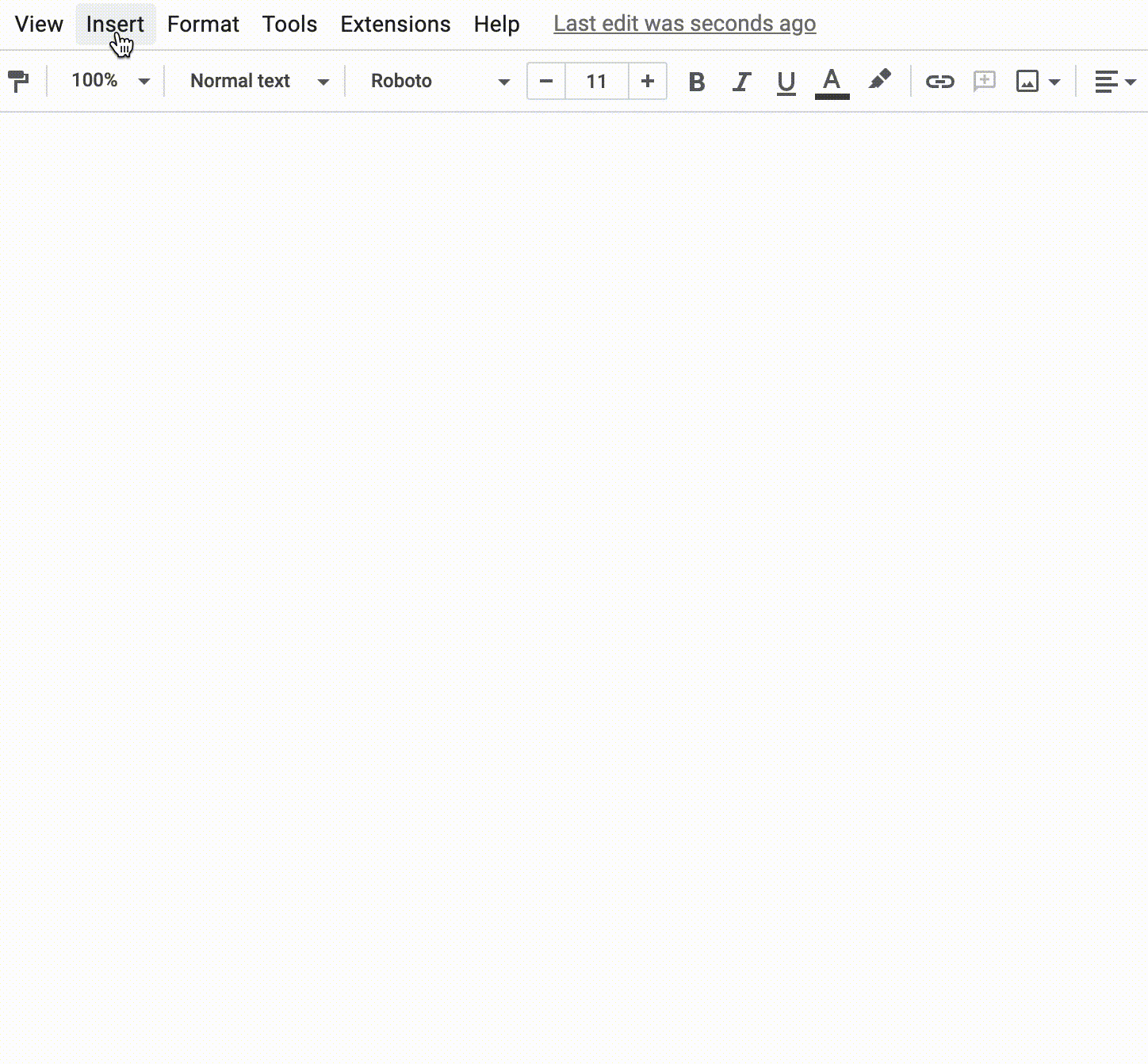
Fifteen minutes. That’s how long it took to empty the Colosseum, an engineering marvel that’s still standing as the largest amphitheater in the world. Two thousand years later, this design continues to work well to move enormous crowds out of sporting and entertainment venues.
But of course, exiting the arena is only the first step. Next, people must navigate the traffic that builds up in the surrounding streets. This is an age-old problem that remains unsolved to this day. In Rome, they addressed the issue by prohibiting private traffic on the street that passes directly by the Colosseum. This policy worked there, but what if you’re not in Rome? What if you’re at the Superbowl? Or at a Taylor Swift concert?
An approach to addressing this problem is to use simulation models, sometimes called "digital twins", which are virtual replicas of real-world transportation networks that attempt to capture every detail from the layout of streets and intersections to the flow of vehicles. These models allow traffic experts to mitigate congestion, reduce accidents, and improve the experience of drivers, riders, and walkers alike. Previously, our team used these models to quantify sustainability impact of routing, test evacuation plans and show simulated traffic in Maps Immersive View.
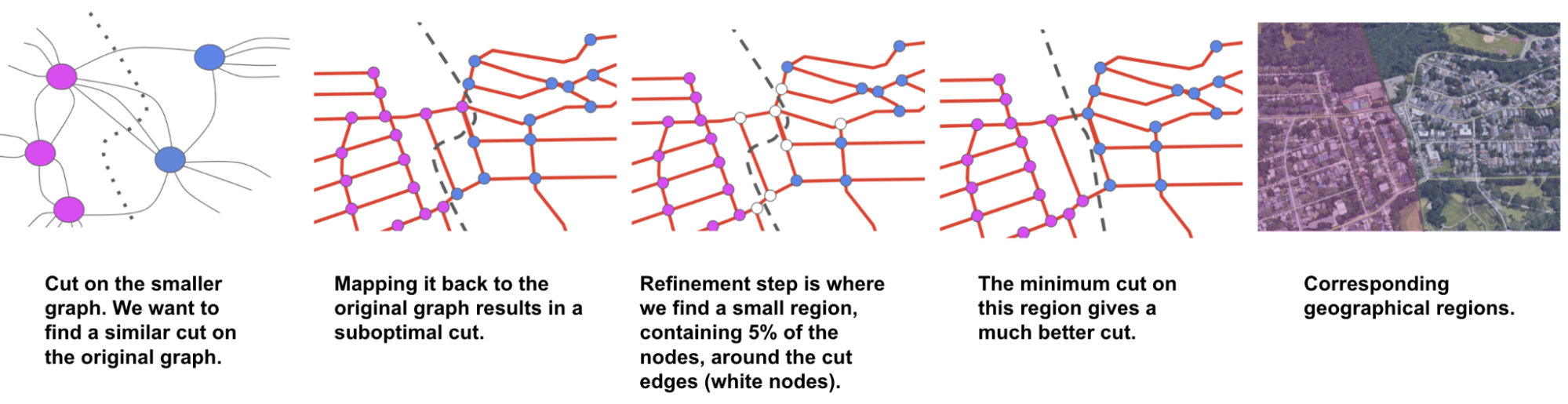
Calibrating high-resolution traffic simulations to match the specific dynamics of a particular setting is a longstanding challenge in the field. The availability of aggregate mobility data, detailed Google Maps road network data, advances in transportation science (such as understanding the relationship between segment demands and speeds for road segments with traffic signals), and calibration techniques which make use of speed data in physics-informed traffic models are paving the way for compute-efficient optimization at a global scale.
To test this technology in the real world, Google Research partnered with the Seattle Department of Transportation (SDOT) to develop simulation-based traffic guidance plans. Our goal is to help thousands of attendees of major sports and entertainment events leave the stadium area quickly and safely. The proposed plan reduced average trip travel times by 7 minutes for vehicles leaving the stadium region during large events. We deployed it in collaboration with SDOT using Dynamic Message Signs (DMS) and verified impact over multiple events between August and November, 2023.
 |
 |
| One policy recommendation we made was to divert traffic from S Spokane St, a major thoroughfare that connects the area to highways I-5 and SR 99, and is often congested after events. Suggested changes improved the flow of traffic through highways and arterial streets near the stadium, and reduced the length of vehicle queues that formed behind traffic signals. (Note that vehicles are larger than reality in this clip for demonstration.) |
Simulation model
For this project, we created a new simulation model of the area around Seattle’s stadiums. The intent for this model is to replay each traffic situation for a specified day as closely as possible. We use an open-source simulation software, Simulation of Urban MObility (SUMO). SUMO’s behavioral models help us describe traffic dynamics, for instance, how drivers make decisions, like car-following, lane-changing and speed limit compliance. We also use insights from Google Maps to define the network’s structure and various static segment attributes (e.g., number of lanes, speed limit, presence of traffic lights).
 |
| Overview of the Simulation framework. |
Travel demand is an important simulator input. To compute it, we first decompose the road network of a given metropolitan area into zones, specifically level 13 S2 cells with 1.27 km2 area per cell. From there, we define the travel demand as the expected number of trips that travel from an origin zone to a destination zone in a given time period. The demand is represented as aggregated origin–destination (OD) matrices.
To get the initial expected number of trips between an origin zone and a destination zone, we use aggregated and anonymized mobility statistics. Then we solve the OD calibration problem by combining initial demand with observed traffic statistics, like segment speeds, travel times and vehicular counts, to reproduce event scenarios.
We model the traffic around multiple past events in Seattle’s T-Mobile Park and Lumen Field and evaluate the accuracy by computing aggregated and anonymized traffic statistics. Analyzing these event scenarios helps us understand the effect of different routing policies on congestion in the region.
 |
| Heatmaps demonstrate a substantial increase in numbers of trips in the region after a game as compared to the same time on a non-game day. |
 |
| The graph shows observed segment speeds on the x-axis and simulated speeds on the y-axis for a modeled event. The concentration of data points along the red x=y line demonstrates the ability of the simulation to reproduce realistic traffic conditions. |
Routing policies
SDOT and the Seattle Police Department’s (SPD) local knowledge helped us determine the most congested routes that needed improvement:
- Traffic from T-Mobile Park stadium parking lot’s Edgar Martinez Dr. S exit to eastbound I-5 highway / westbound SR 99 highway
- Traffic through Lumen Field stadium parking lot to northbound Cherry St. I-5 on-ramp
- Traffic going southbound through Seattle’s SODO neighborhood to S Spokane St.
We developed routing policies and evaluated them using the simulation model. To disperse traffic faster, we tried policies that would route northbound/southbound traffic from the nearest ramps to further highway ramps, to shorten the wait times. We also experimented with opening HOV lanes to event traffic, recommending alternate routes (e.g., SR 99), or load sharing between different lanes to get to the nearest stadium ramps.


Evaluation results
We model multiple events with different traffic conditions, event times, and attendee counts. For each policy, the simulation reproduces post-game traffic and reports the travel time for vehicles, from departing the stadium to reaching their destination or leaving the Seattle SODO area. The time savings are computed as the difference of travel time before/after the policy, and are shown in the below table, per policy, for small and large events. We apply each policy to a percentage of traffic, and re-estimate the travel times. Results are shown if 10%, 30%, or 50% of vehicles are affected by a policy.

Based on these simulation results, the feasibility of implementation, and other considerations, SDOT has decided to implement the “Northbound Cherry St ramp” and “Southbound S Spokane St ramp” policies using DMS during large events. The signs suggest drivers take alternative routes to reach their destinations. The combination of these two policies leads to an average of 7 minutes of travel time savings per vehicle, based on rerouting 30% of traffic during large events.
Conclusion
This work demonstrates the power of simulations to model, identify, and quantify the effect of proposed traffic guidance policies. Simulations allow network planners to identify underused segments and evaluate the effects of different routing policies, leading to a better spatial distribution of traffic. The offline modeling and online testing show that our approach can reduce total travel time. Further improvements can be made by adding more traffic management strategies, such as optimizing traffic lights. Simulation models have been historically time consuming and hence affordable only for the largest cities and high stake projects. By investing in more scalable techniques, we hope to bring these models to more cities and use cases around the world.
Acknowledgements
In collaboration with Alex Shashko, Andrew Tomkins, Ashley Carrick, Carolina Osorio, Chao Zhang, Damien Pierce, Iveel Tsogsuren, Sheila de Guia, and Yi-fan Chen. Visual design by John Guilyard. We would like to thank our SDOT partners Carter Danne, Chun Kwan, Ethan Bancroft, Jason Cambridge, Laura Wojcicki, Michael Minor, Mohammed Said, Trevor Partap, and SPD partners Lt. Bryan Clenna and Sgt. Brian Kokesh.