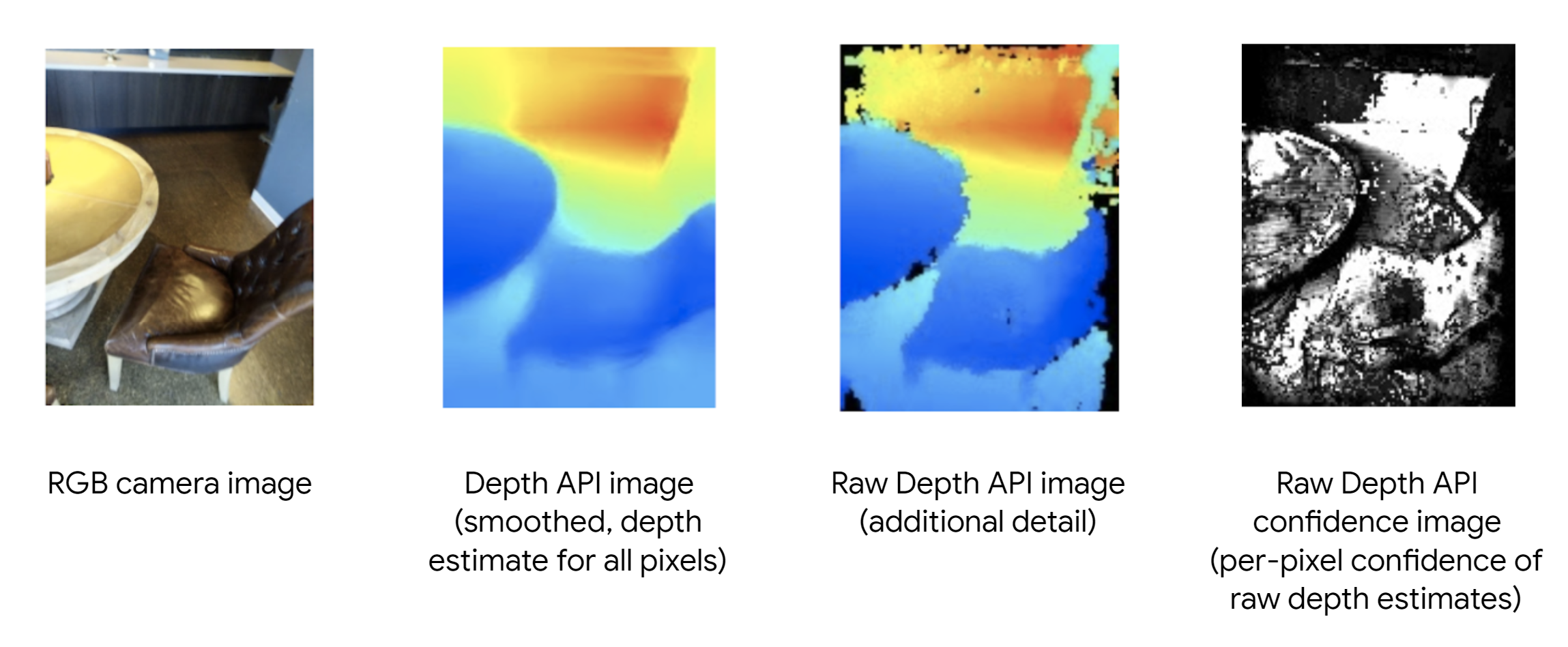
Posted by Kira Rich – Senior Product Marketing Manager, AR and Bradford Lee – Product Marketing Manager, AR
Posted by Kira Rich – Senior Product Marketing Manager, AR and Bradford Lee – Product Marketing Manager, AR

Navigating a large-scale convention like CES can be overwhelming. To enhance the attendee experience, we've created a 360° event-scale augmented reality (AR) experience in our Google booth. Our friendly Android Bot served as a digital guide, providing:
- Seamless wayfinding within our booth, letting you know about the must try demos
- Delightful content, only possible with AR, like replacing the Las Vegas Convention Center facade with our Generative AI Wallpapers or designing an interactive version of Android on Sphere for those who missed it in real life
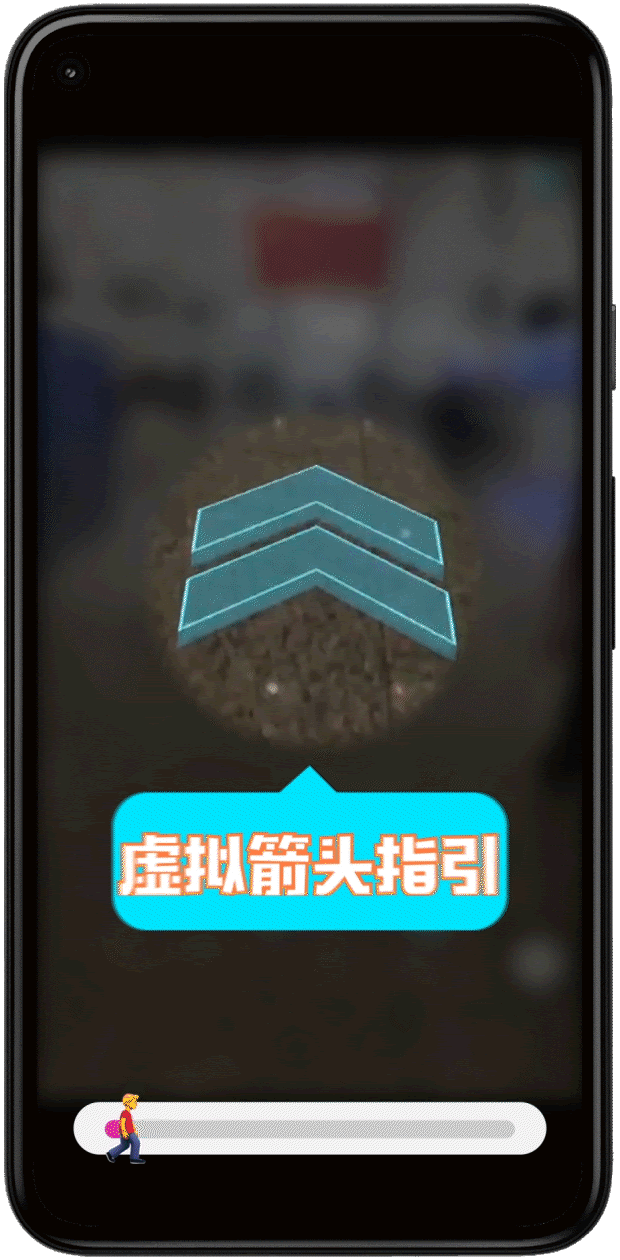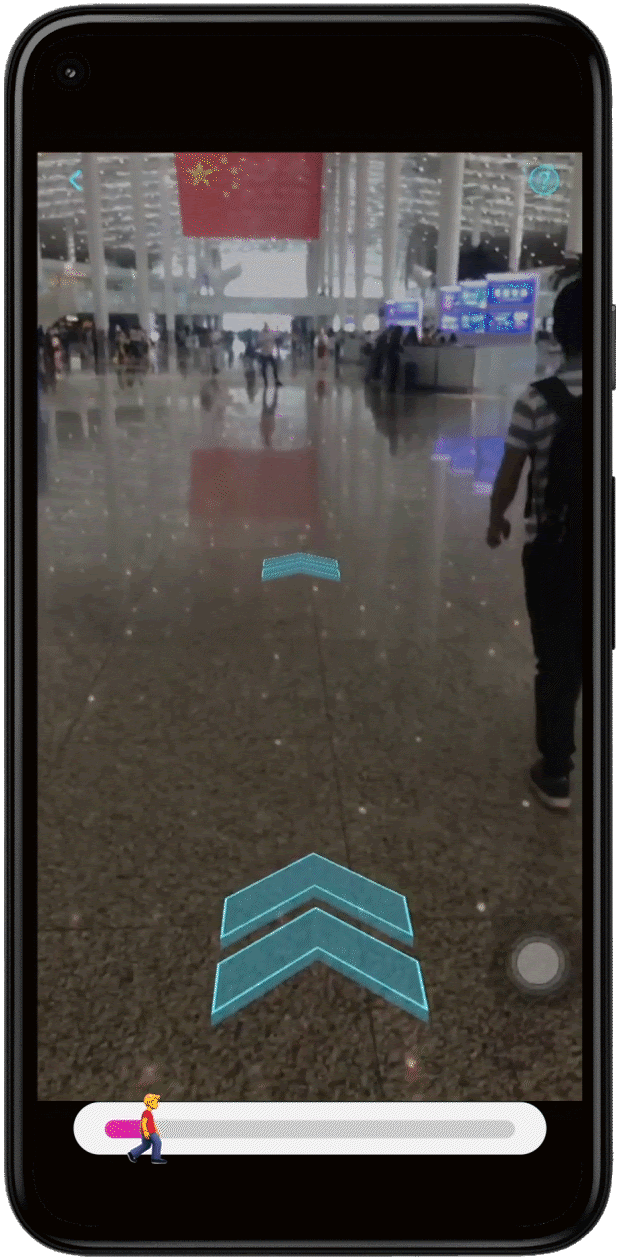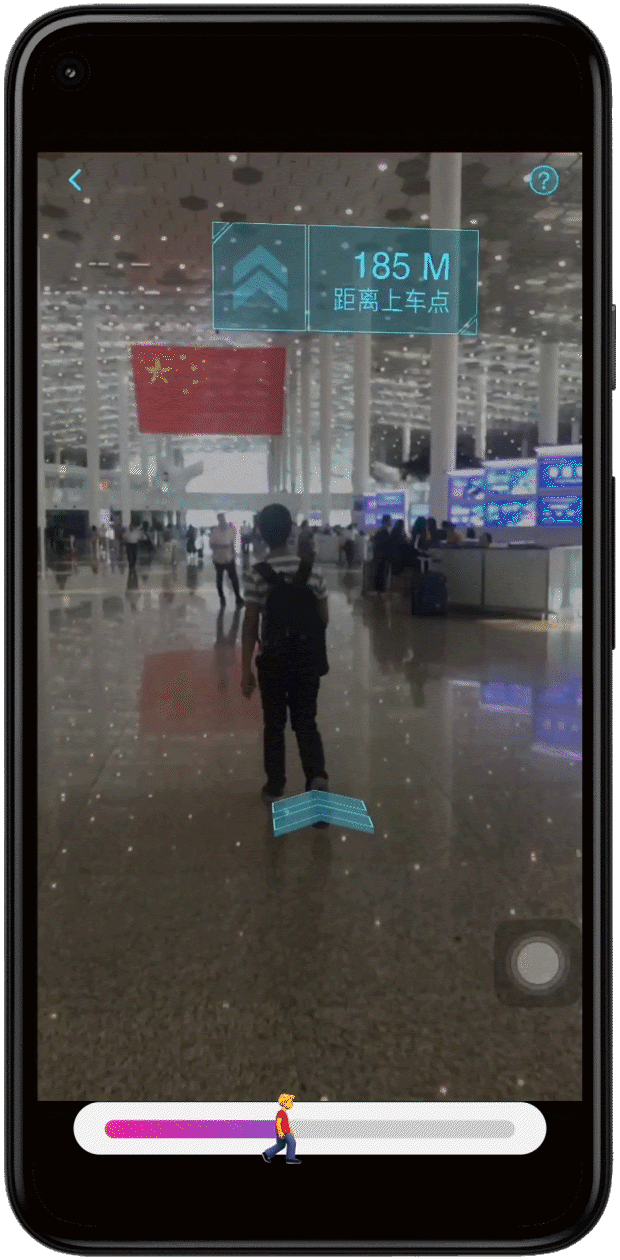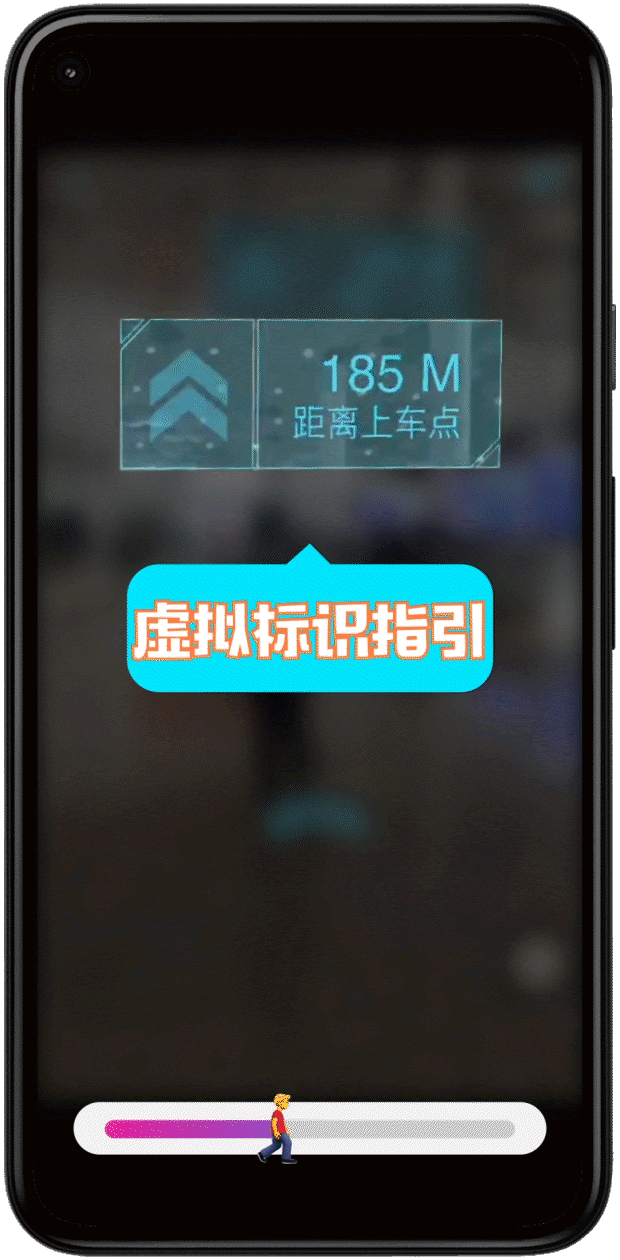
- Helpful navigation tips and quick directions to transportation hubs (Monorail, shuttle buses)
In partnership with Left Field Labs and Adobe, we used Google’s latest AR technologies to inspire developers, creators, and brands on how to elevate the conference experience for attendees. Here’s a behind the scenes look at how we used Geospatial Creator, powered by ARCore and Photorealistic 3D Tiles from Google Maps Platform, to promote the power and usefulness of Google on Android.
 |
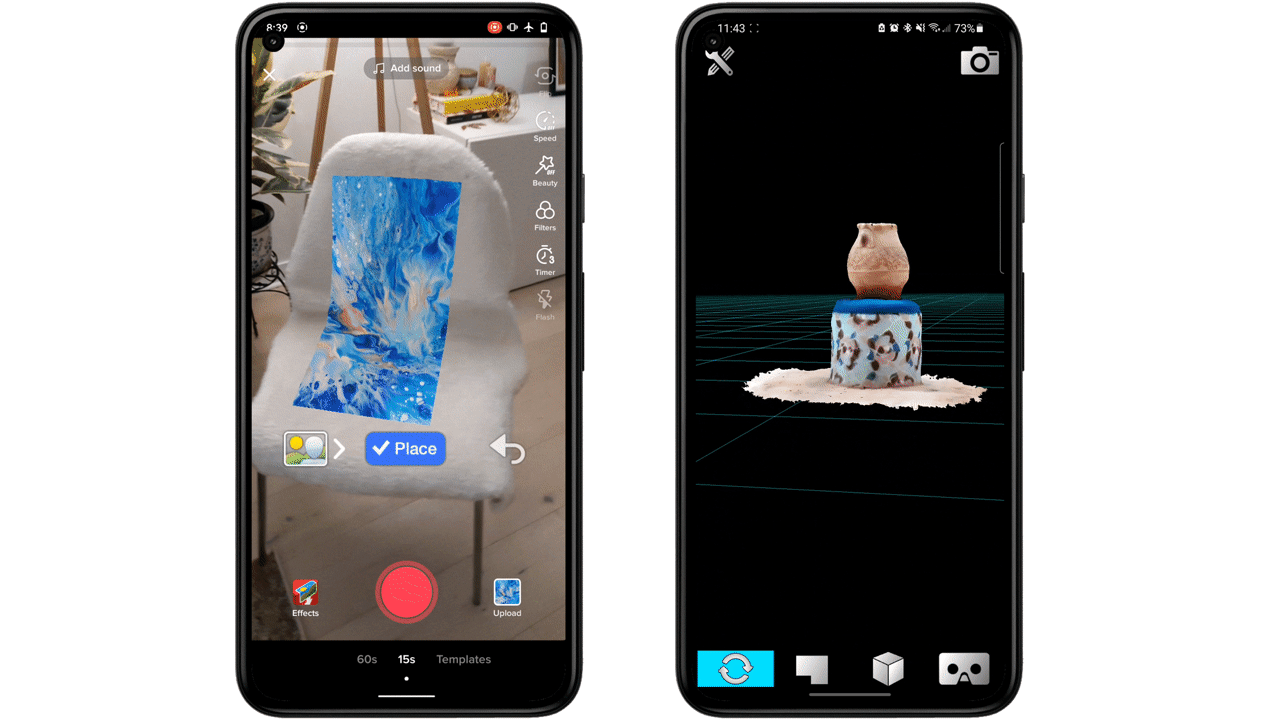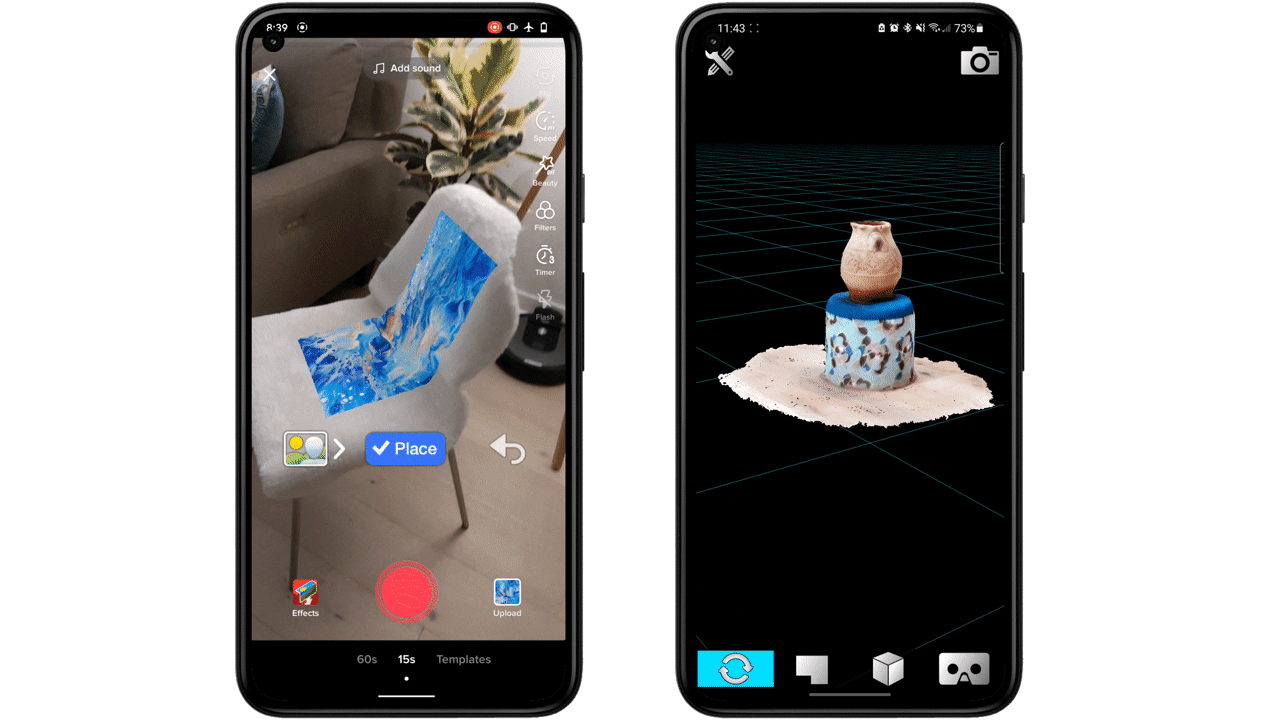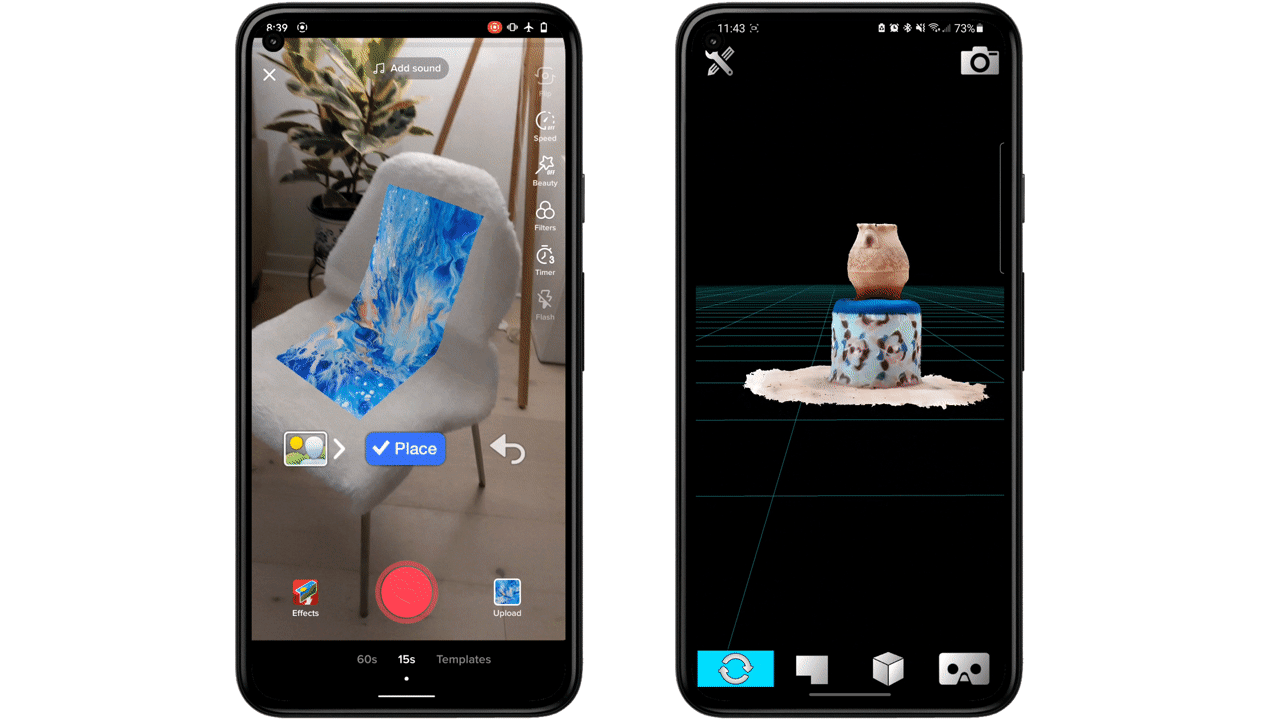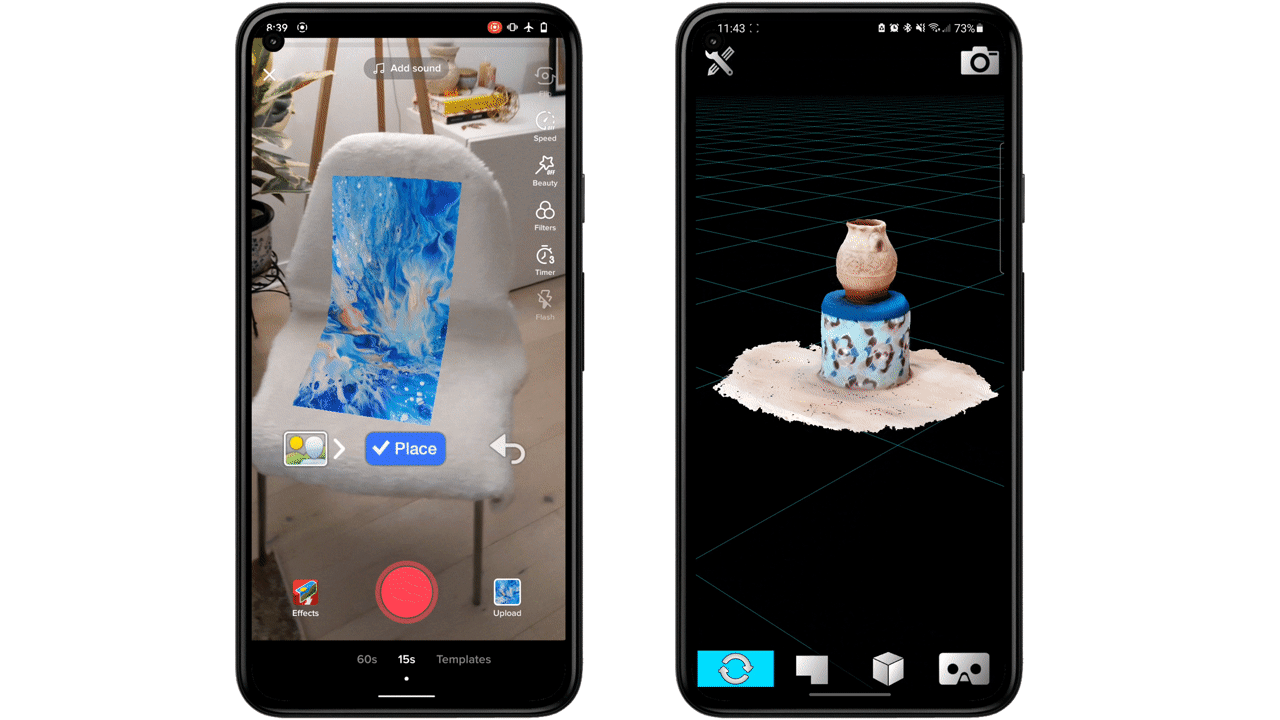
| Using Google’s Geospatial Creator, we helped attendees navigate CES with the Android Bot as a virtual guide, providing helpful and delightful immersive tips on what to experience in our Google Booth. |
Tools We Used
Geospatial Creator in Adobe Aero Pre-Release
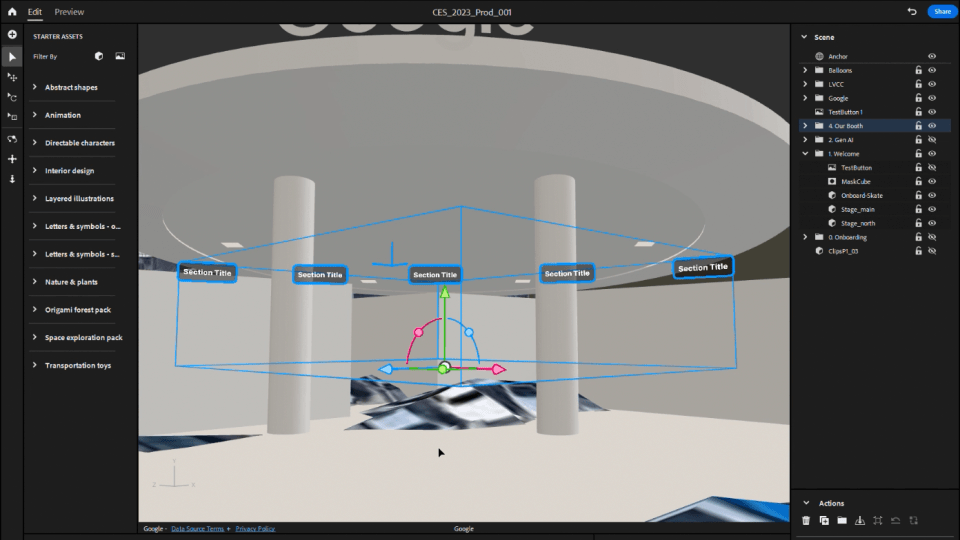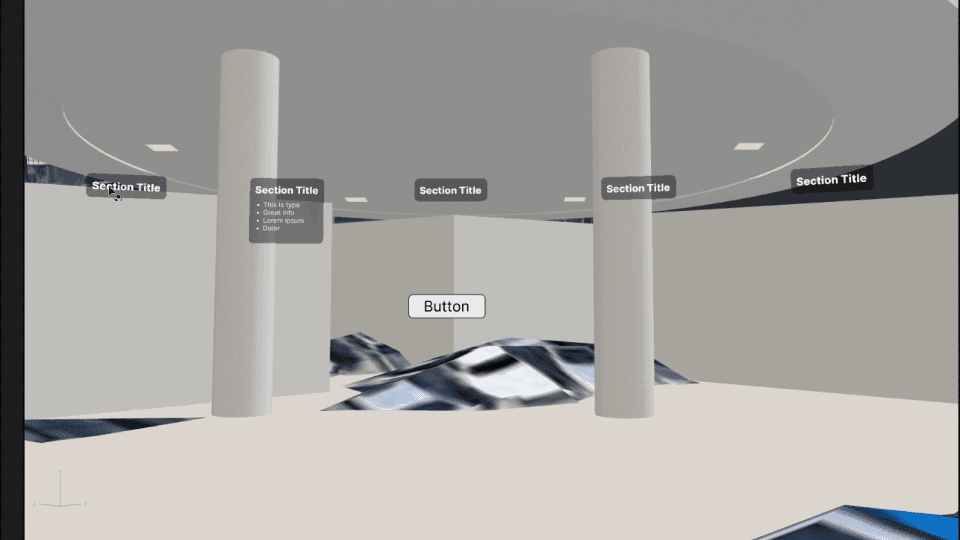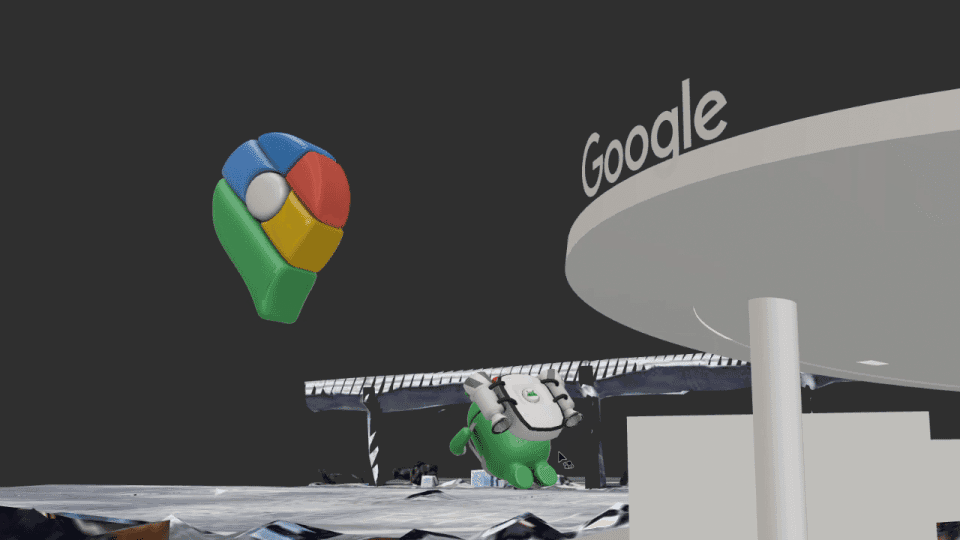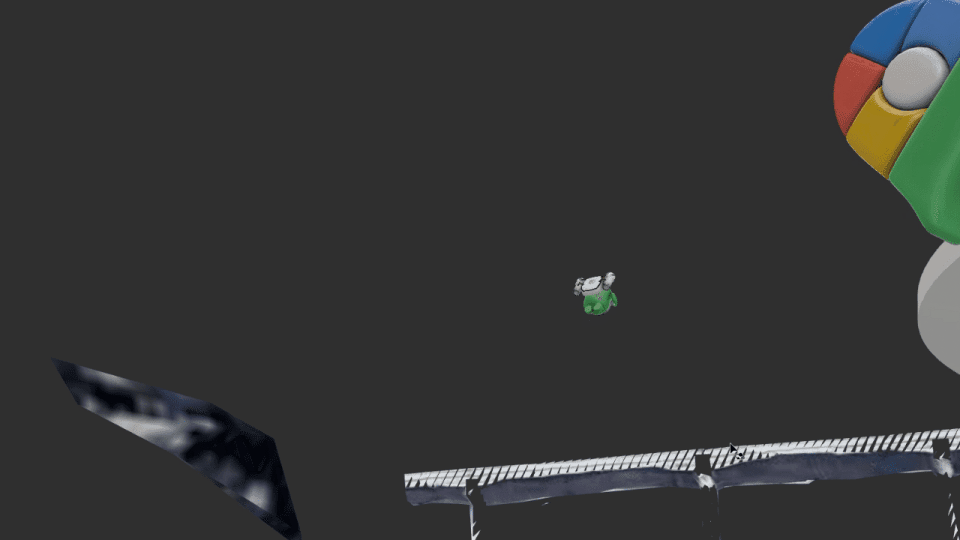
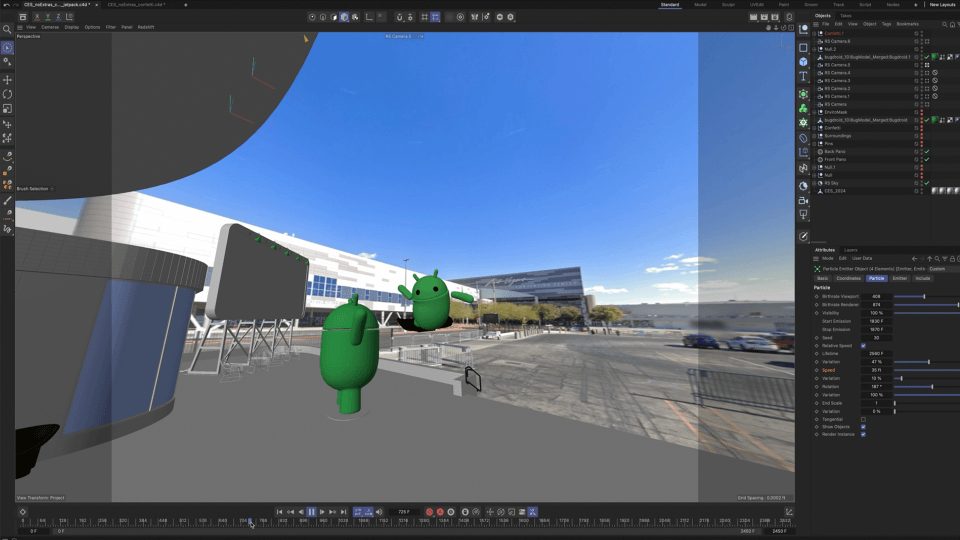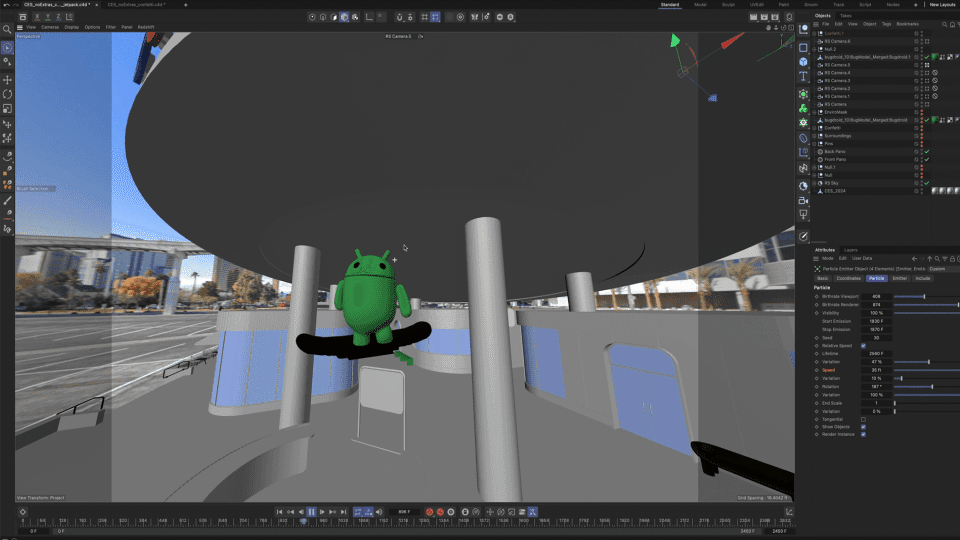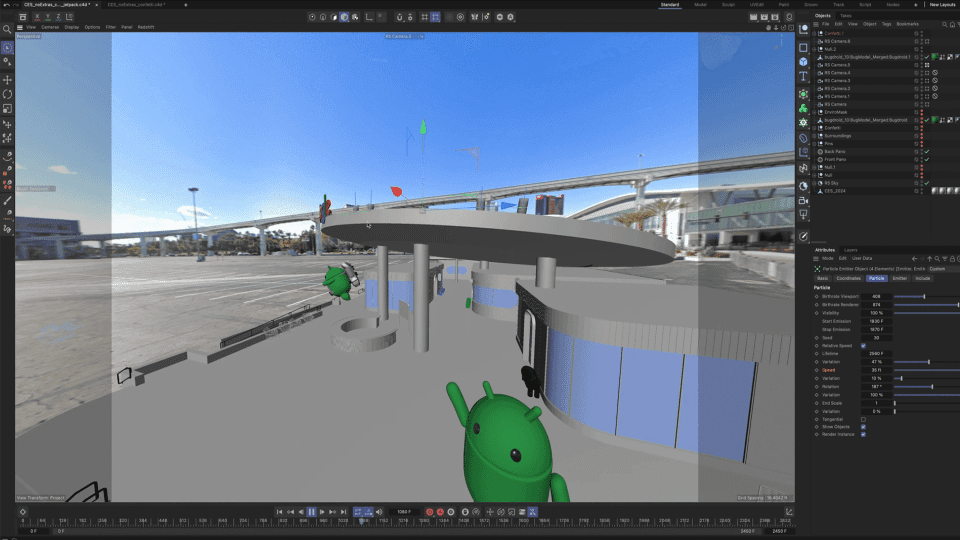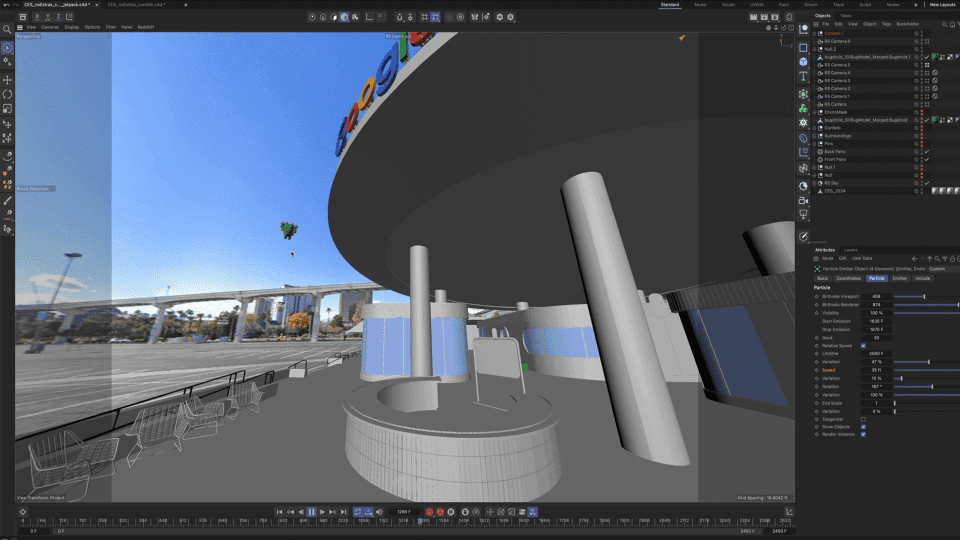
Geospatial Creator in Adobe Aero enables creators and developers to easily visualize where in the real-world they want to place their digital content, similar to how Google Earth visualizes the world. With Geospatial Creator, we were able to bring up Las Vegas Convention Center in Photorealistic 3D Tiles from Google Maps Platform and understand the surroundings of where the Google Booth would be placed. In this case, the booth did not exist in the Photorealistic 3D Tiles because it was a temporary build for the conference. However, by utilizing the 3D model of the booth and the coordinates of where it would be built, we were able to easily estimate and visualize the booth inside of Adobe Aero and build the experience around it seamlessly, including anchoring points for the digital content and the best attendee viewing points for the experience.
"At CES 2024, the Android AR experience, created in partnership with the Google AR, Android, and Adobe teams, brought smiles and excitement to attendees - ultimately that's what it's all about. The experience not only showcased the amazing potential of app-less AR with Geospatial Creator, but also demonstrated its practical applications in enhancing event navigation and engagement, all accessible with a simple QR scan."
– Yann Caloghiris, Executive Creative Director at Left Field Labs
 |
| Adobe Aero provided us with an easy way to visualize and anchor the AR experience around the 3D model of the Google Booth at the Las Vegas Convention Center. |
With Geospatial Creator, we had multiple advantages for designing the experience:
- Rapid iteration with live previews of 3D assets and high fidelity visualization of the location with Photorealistic 3D Tiles from Google Maps Platform were crucial for building a location-based, AR experience without having to be there physically.
- Easy selection of the Las Vegas Convention Center and robust previews of the environment, as you would navigate in Google Earth, helped us visualize and develop the AR experience with precision and alignment to the real world location.
In addition, Google Street View imagery generated a panoramic skybox, which helped visualize the sight lines in Cinema 4D for storyboards. We also imported this and Photorealistic 3D Tiles from Google Maps Platform into Unreal Engine to visualize occlusion models at real world scale.
In Adobe Aero, we did the final assembly of all 3D assets and created all interactive behaviors in the experience. We also used it for animating simpler navigational elements, like the info panel assets in the booth.
| AR development was primarily done with Geospatial Creator in Adobe Aero. Supplementary tools, including Unreal Engine and Autodesk Maya, were used to bring the experience to life. |

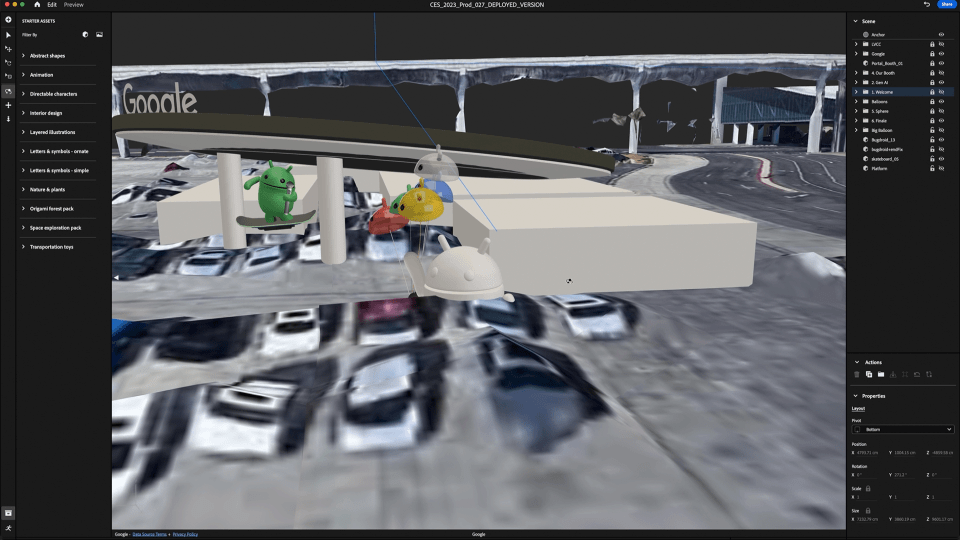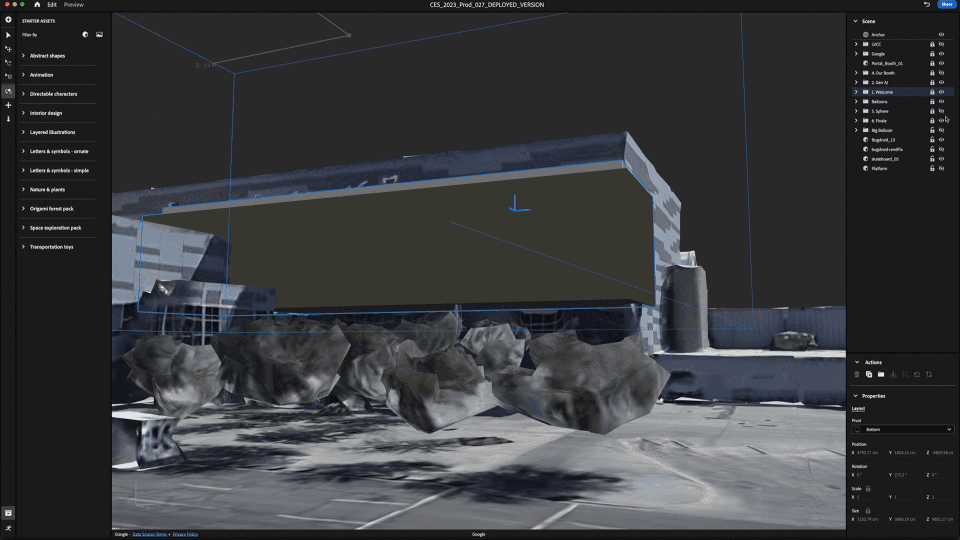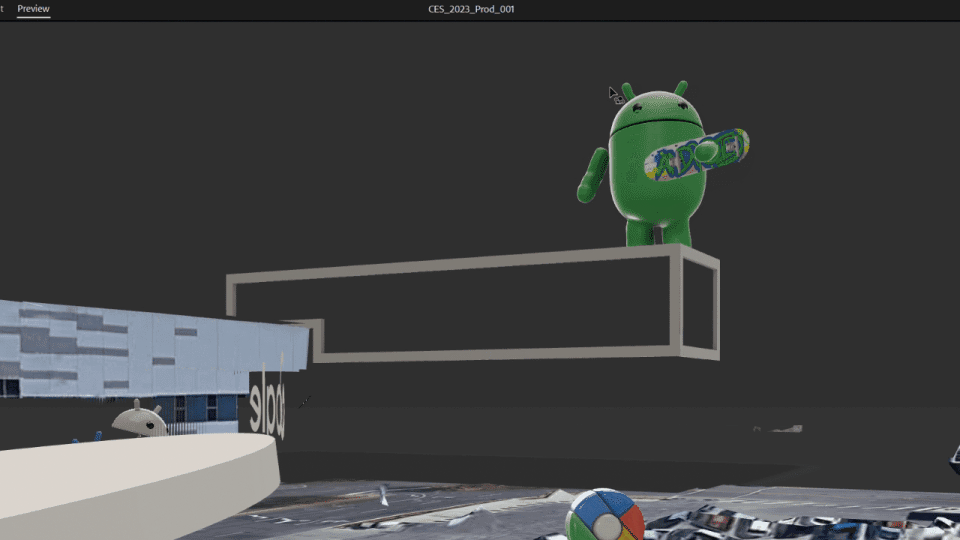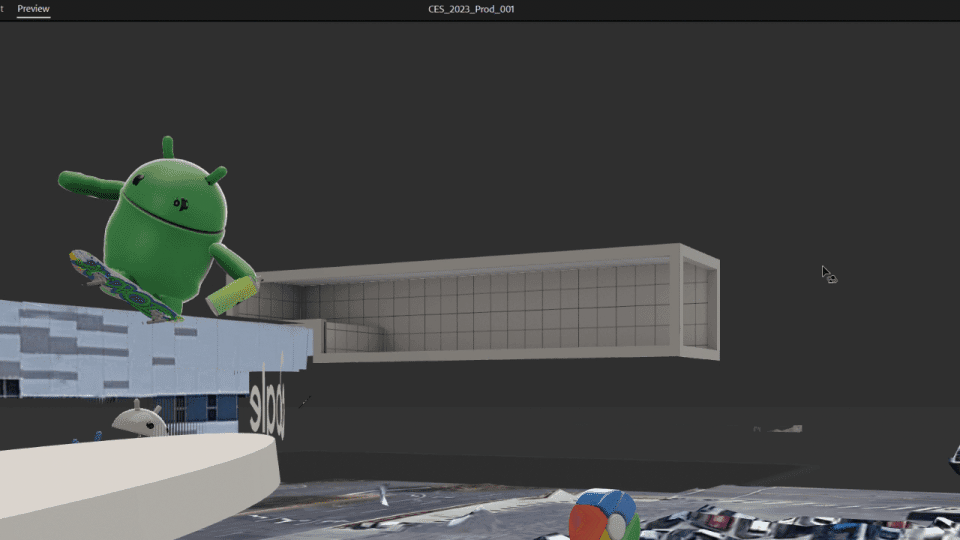

Adobe Aero also supports Google Play Instant apps and App Clips1, which means attendees did not have to download an app to access the experience. They simply scanned a QR code at the booth and launched directly into the experience, which proved to be ideal for onboarding users and reducing friction especially at a busy event like CES.
Unreal Engine was used to bring in the Photorealistic 3D Tiles, allowing them to build the 3D animated Android Bot that really interacted closely with the surrounding environment. This approach was crucial for previews of the experience, allowing us to understand sight lines and where to best locate content for optimal viewing from the Google booth.
Autodesk Maya was used to create the Android Bot character, environmental masks, and additional 3D props for the different scenes in the experience. It was also used for authoring the final materials.
Babylon exporter was used for exporting from Autodesk Maya to glTF format for importing into Adobe Aero.
Figma was used for designing flat user interface elements that could be easily imported into Adobe Aero.
Cinema 4D was used for additional visualization and promotional shots, which helped with stakeholder alignment during the development of the experience.
Designing the experience
During the design phase, we envisioned the AR experience to have multiple interactions, so attendees could experience the delight of seeing precise and robust AR elements blended into the real world around them. In addition, they could experience the helpfulness of contextual information embedded into the real objects around them, providing the right information at the right time.
 |
| To make the AR experience more engaging for attendees, we created several possibilities for people to interact with their environment (click to enlarge). |
Creative storyboarding
Creating an effective storyboard for a Geospatial AR experience using Adobe Aero begins with a clear vision of how the digital overlays interact with the real-world locations.
Left Field Labs started by mapping out key geographical points at the Las Vegas Convention Center location where the Google booth was going to stand, integrating physical and digital elements along the way. Each scene sketched in the storyboard illustrated how virtual objects and real-world environments would interplay, ensuring that user interactions and movements felt natural and intuitive.
“Being able to pin content to a location that’s mapped by Google and use Photorealistic 3D Tiles in Google’s Geospatial Creator provided incredible freedom when choosing how the experience would move around the environment. It gave us the flexibility to create the best flow possible.”
– Chris Wnuk, Technical Director at Left Field Labs
Early on in the storyboarding process, we decided that the virtual 3D Android Bot would act as the guide. Users could follow the Bot around the venue by turning around in 360°, but staying at the same vantage point. This allowed us to design the interactive experience and each element in it for the right perspective from where the user would be standing, and give them a full look around the Google Booth and surrounding Google experiences, like the Monorail or Sphere.
The storyboard not only depicted the AR elements but also considered user pathways, sightlines, and environmental factors like time of day, occlusion, and overall layout of the AR content around the Booth and surrounding environment.
| We aimed to connect the attendees with engaging, helpful, and delightful content, helping them visually navigate Google Booth at CES. |
User experience and interactivity
When designing for AR, we have learned that user interactivity and ensuring that the experience has both helpful and delightful elements are key. Across the experience, we added multiple interactions that allowed users to explore different demo stations in the Booth, get navigation via Google Maps for the Monorail and shuttles, and interact with the Android Bot directly.
The Android brand team and Left Field Labs created the Android character to be both simple and expressive, showing playfulness and contextual understanding of the environment to delight users while managing the strain on users’ devices. Taking an agile approach, the team iterated on a wide range of both Android and iOS mobile devices to ensure smooth performance across different smartphones, form factors such as foldables, as well as operating system versions, making the AR experience accessible and enjoyable to the widest audience.
 |
| With Geospatial Creator in Adobe Aero, we were able to ensure that 3D content would be accurate to specific locations throughout the development process. |
Testing the experience
We consistently iterated on the interactive elements based on location testing. We performed two location tests: First, in the middle of the design phase, which helped us validate the performance of the Visual Positioning Service (VPS) at the Las Vegas Convention Center. Second, at the end of the design phase and a few days before CES, which further validated the placement of the 3D content and enabled us to refine any final adjustments once the Google booth structure was built on site.
“It was really nice to never worry about deploying. The tracking on physical objects and quickness of localization was some of the best I’ve seen!”
– Devin Thompson, Associate Technical Director at Left Field Labs
Attendee Experience
When attendees came to the Google Booth, they saw a sign with the QR code to enter the AR experience. We positioned the sign at the best vantage point at the booth, ensuring that people had enough space around them to scan with their device and engage in the AR experience.
 |
| By scanning a QR code, attendees entered directly into the experience and saw the virtual Android Bot pop up behind the Las Vegas Convention Center, guiding them through the full AR experience. |
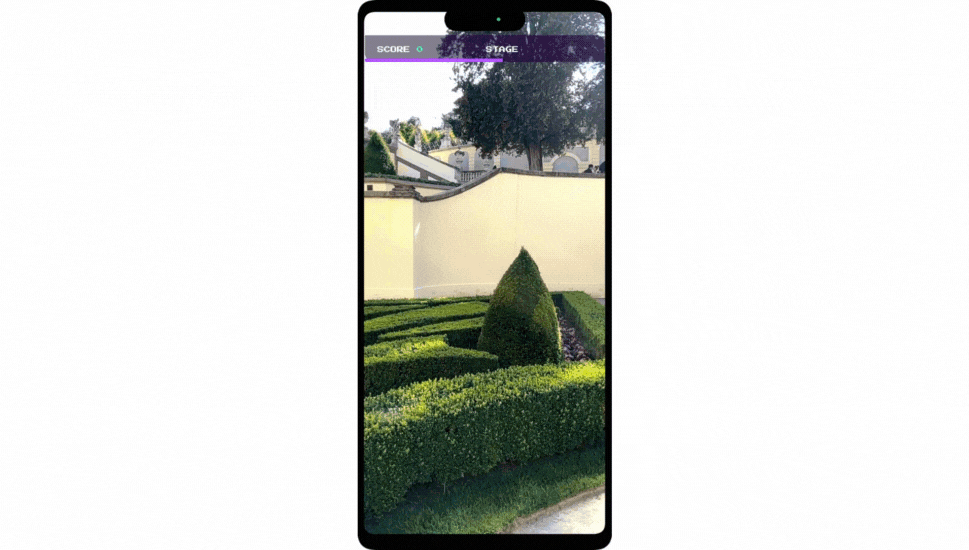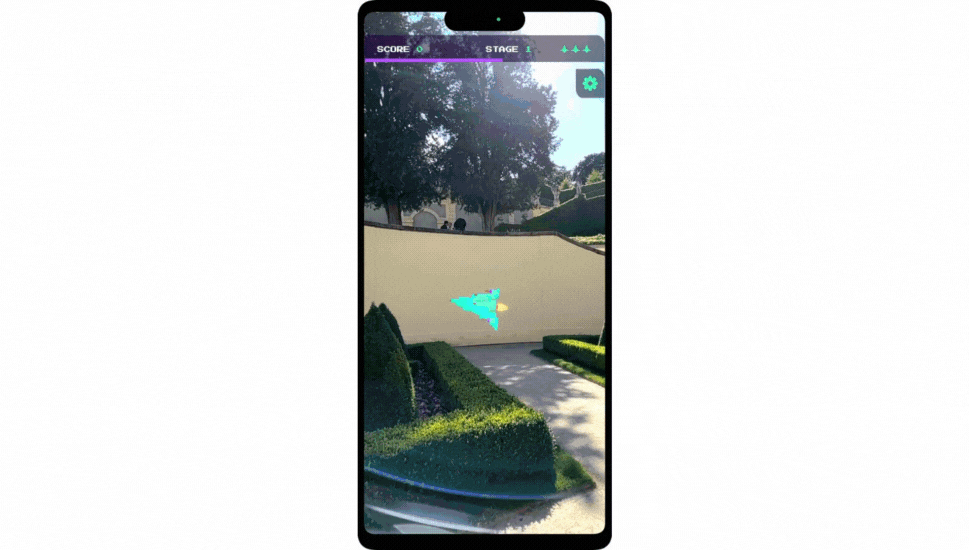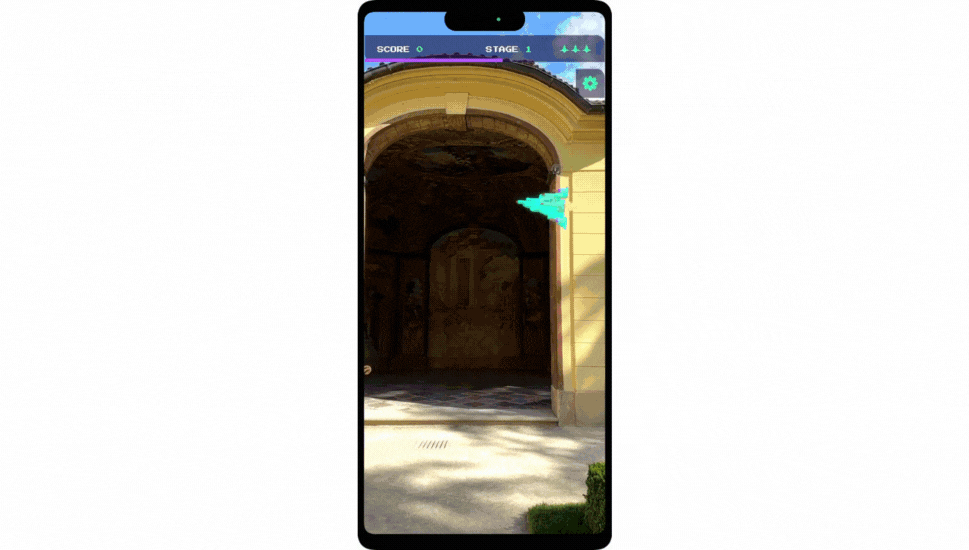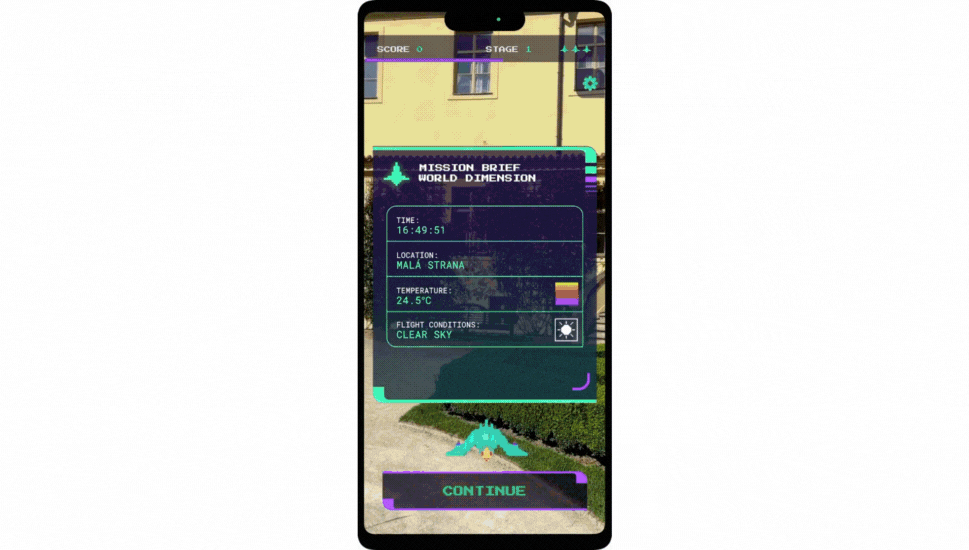
Attendees enjoyed seeing the Android Bot take over the Las Vegas Convention Center. Upon initializing the AR experience, the Bot revealed a Generative AI wallpaper scene right inside of a 3D view of the building, all while performing skateboarding tricks at the edge of the building’s facade.
 |
| With Geospatial Creator, it was possible for us to “replace” the facade of the Las Vegas Convention Center, revealing a playful scene where the Android Bot highlighted the depth and occlusion capabilities of the technology while showcasing a Generative AI Wallpaper demo. |
Many people also called out the usefulness of seeing location-based, AR content with contextual information, like navigation through Google Maps, embedded into interesting locations around the Booth. Interactive panels overlaid around the Booth then introduced key physical demos located at each station around the Booth. Attendees could quickly scan the different themes and features demoed, orient themselves around the Booth, and decide which area they wanted to visit first.
“I loved the experience! Maps and AR make so much sense together. I found it super helpful seeing what demos are in each booth, right on top of the booth, as well as the links to navigation. I could see using this beyond CES as well!”
– CES Attendee
 |
| The Android Bot helped attendees visually understand the different areas and demos at the Google Booth, helping them decide what they wanted to go see first. |
From the attendees we spoke to, over half of them engaged with the full experience. They were able to skip parts of the experience that felt less relevant to them and focus only on the interactions that added value. Overall, we’ve learned that most people liked seeing a mix of delightful and helpful content and they felt excited to explore the Booth further with other demos.
 |
| Many attendees engaged with the full AR experience to learn more about the Google Booth at CES. |
 |
| Shahram Izadi, Google’s VP and GM, AR/XR, watching a demonstration of the full Geospatial AR experience at CES. |
Location-based, AR experiences can transform event experiences for attendees who desire more ways to discover and engage with exhibitors at events. This trend underscores a broader shift in consumer expectations for a more immersive and interactive world around them and the blurring lines between online and offline experiences. At events like CES, AR content can offer a more immersive and personalized experience that not only entertains but also educates and connects attendees in meaningful ways.
To hear the latest updates about Google AR, Geospatial Creator, and more follow us on LinkedIn (@GoogleARVR) and X (@GoogleARVR). Plus, visit our ARCore and Geospatial Creator websites to learn how to get started building with Google’s AR technology.
1Available on select devices and may depend on regional availability and user settings.
 Posted by Bradford Lee – Product Marketing Manager, Augmented Reality, and Ahsan Ashraf – Product Marketing Manager, Google Maps Platform
Posted by Bradford Lee – Product Marketing Manager, Augmented Reality, and Ahsan Ashraf – Product Marketing Manager, Google Maps Platform






 Posted by
Posted by 

 Posted by Dereck Bridie, Developer Relations Engineer, ARCore and Bradford Lee, Product Marketing Manager, Augmented Reality
Posted by Dereck Bridie, Developer Relations Engineer, ARCore and Bradford Lee, Product Marketing Manager, Augmented Reality










 Posted by Stevan Silva, Senior Product Manager
Posted by Stevan Silva, Senior Product Manager