 Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks
Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks

In the fast-paced world of software development, Continuous Integration and Continuous Deployment (CI/CD) have become cornerstones, enabling teams to deliver high-quality software faster than ever. However, the rise of rapid innovation, increasing use of third-party libraries, and AI-generated code have accelerated vulnerabilities and risks. Therefore, addressing these issues early in the development lifecycle is essential so that teams can launch their products quickly and confidently.
The introduction of Checks privacy compliance CI/CD tooling feature represents a significant stride towards addressing these concerns, by reducing manual intervention and automating compliance and privacy standards as part of a release cycle.
In this post, we explore the meaning of CI/CD for compliance team members unfamiliar with this technology and how Checks can weave privacy and compliance protection practices into that pipeline.
What is CI/CD?
Continuous Integration (CI) and Continuous Deployment (CD) are foundational practices in modern software development. They enable development teams to increase efficiency, improve quality, and accelerate delivery.
Continuous Integration (CI) automatically integrates code changes from multiple contributors into a software project. This practice enables teams to detect problems early by running automated tests on each change before it is merged into the main branch.
 |
Continuous Deployment (CD) takes automation further by automatically deploying all code changes to a testing or production environment after the build stage. This means that, in addition to automated testing, automated release processes ensure that new changes are accessible to users as quickly as possible.
Shifting issue-spotting left with CI/CD pipelines
The automation of CI/CD processes is typically called “pipelines.” CI/CD pipelines automate the steps software changes go through, from development to deployment. These steps include compiling code, running tests (unit tests, integration tests, etc.), security scans, and more. If all automated tests pass, the changes go live without human intervention in a specific environment, such as testing or production.
These pipelines are designed to catch issues as early as possible, embodying the practice known as “shifting left.” The benefits of “shifting left”, particularly when applied through CI/CD pipelines, include:
- Improved quality and security: Automated testing in CI/CD pipelines ensures that code is rigorously tested for functional and compliance issues before it reaches production. This early detection enables teams to address vulnerabilities and errors when they are generally easier and less costly to fix.
- Faster release cycles: By catching and addressing issues early, teams avoid the bottlenecks associated with late-stage discovery of problems. This efficiency reduces the time from development to deployment, enabling faster release cycles and more responsive delivery of features and fixes.
- Reduced costs: Detecting issues later in the development process can be significantly more expensive to resolve, especially if they're found after deployment. Early detection through CI/CD pipelines minimizes these costs by preventing complex rollbacks and the need for emergency fixes in production environments.
- Increased reliability and trust: Software that undergoes thorough testing before release is generally more reliable and secure. This reliability builds trust among users and stakeholders, crucial for maintaining a positive reputation and ensuring user satisfaction.
Checks brings privacy and compliance tests to your CI/CD
TChecks CI/CD tooling seamlessly integrates app compliance scanning into CI/CD pipelines via plugins for GitHub, Jenkins, and FastLane. You can also use Checks in any other CI/CD system that supports custom scripts, such as GitLab, TeamCity, Bitbucket, and more.
 |
When Checks scans an app, the binary undergoes dynamic and static analysis to understand your data collection and sharing practices, including app dependencies such as SDKs, permissions, and endpoints. This data is then tested against global regulatory requirements, store policies, your custom Checks policies, and your privacy policy to find potential issues and opportunities for improvement.
Top 5 benefits of integrating Checks into your CI/CD
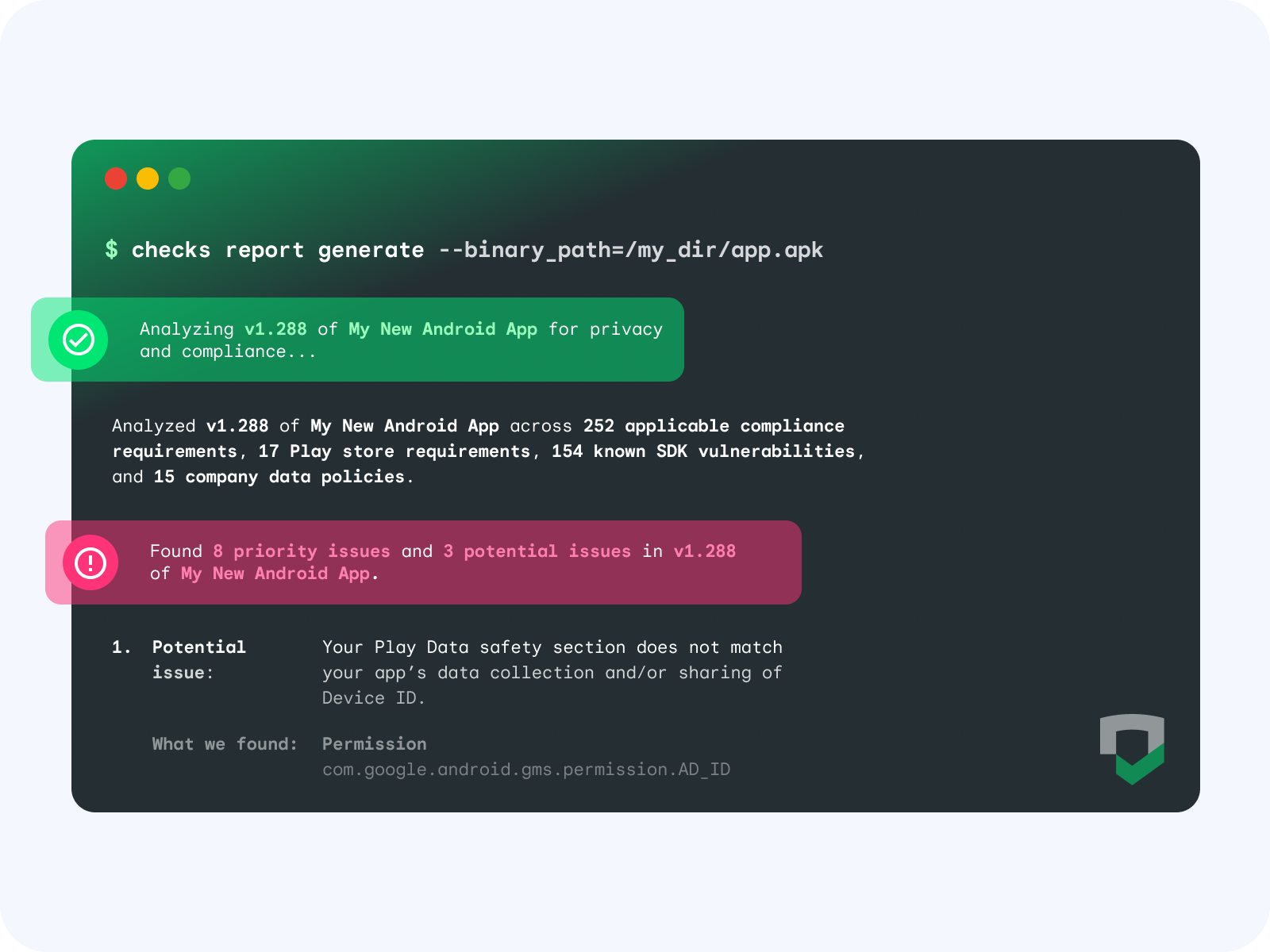 |
By adding Checks as a step in your CI/CD pipeline, you can automate app and code compliance scanning as part of the development lifecycle.
The top 5 benefits of integrating Checks in your CI/CD are:
- Real-time, intelligent alerting: You can stay informed of new compliance issues or changes in data behavior across your product portfolio with instant notifications via email or Slack.
- Understand data sharing & SDKs: Checks can help ensure secure third-party data sharing by gaining visibility into SDK integrations, permissions, and data flow analysis. By using Checks, you can be confident in your third-party dependencies before your public release.
- Ensure new builds follow your company policies: Checks enables you to automate data governance with custom policies that let you set up safeguards against specific endpoints, SDKs, data types, and permissions, tailoring privacy to your specific needs. These policies help ensure all new releases comply with your company’s data policies.
- Keep your Google Play Data safety section up-to-date: Checks can recommend Google Play Data safety section disclosures and alert you if you should make an update before releasing publicly, ensuring your declarations are always up-to-date.
- Deploy quickly and with confidence: When Checks finds issues in the CI/CD, these vulnerabilities are caught and remedied early, significantly reducing the risk of compliance violations once you deploy the app. Checks helps you maintain high compliance standards without slowing down the release cycle, enabling teams to deploy with confidence and ensuring that user data is protected from the outset.
Next steps
Getting started is simple. Start by first signing up for Checks and then adding Checks to your CI/CD pipelines with these simple configuration steps. Once configured, Checks is ready to perform a variety of privacy and compliance verifications.
This proactive approach to privacy and compliance safeguards against potential risks and aligns with regulatory compliance requirements, making it an invaluable asset for any compliance and development team.




 Posted by Matt Ridenour, Head of Startup Developer Ecosystem - USA
Posted by Matt Ridenour, Head of Startup Developer Ecosystem - USA

 Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager
Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager



 Posted by Bitnoori Keum – DevRel Community Manager
Posted by Bitnoori Keum – DevRel Community Manager

 Posted by Leticia Lago – Developer Marketing
Posted by Leticia Lago – Developer Marketing






 Posted by Joe Fernandez – Google AI Developer Relations
Posted by Joe Fernandez – Google AI Developer Relations

 Posted by Cher Hu, Product Manager and Saravanan Ganesh, Software Engineer for Gemini API
Posted by Cher Hu, Product Manager and Saravanan Ganesh, Software Engineer for Gemini API



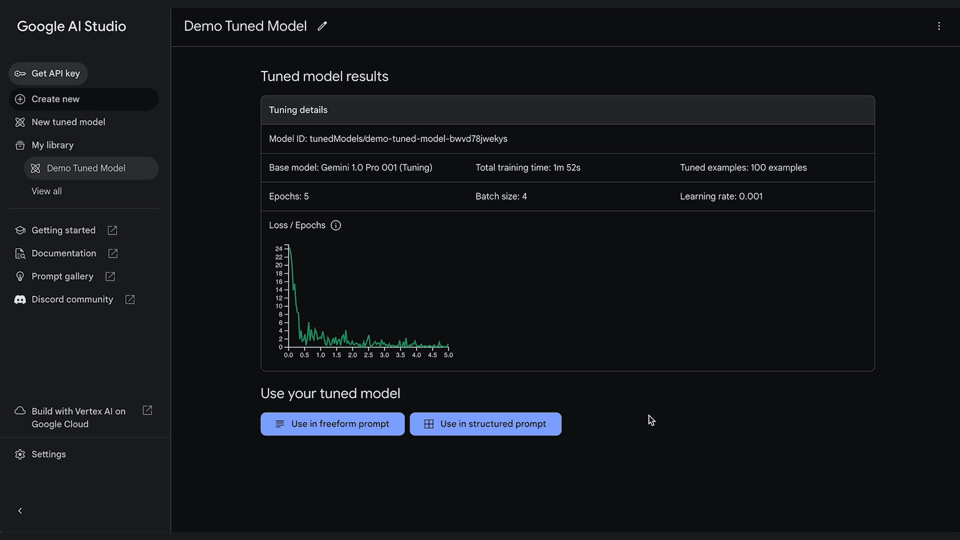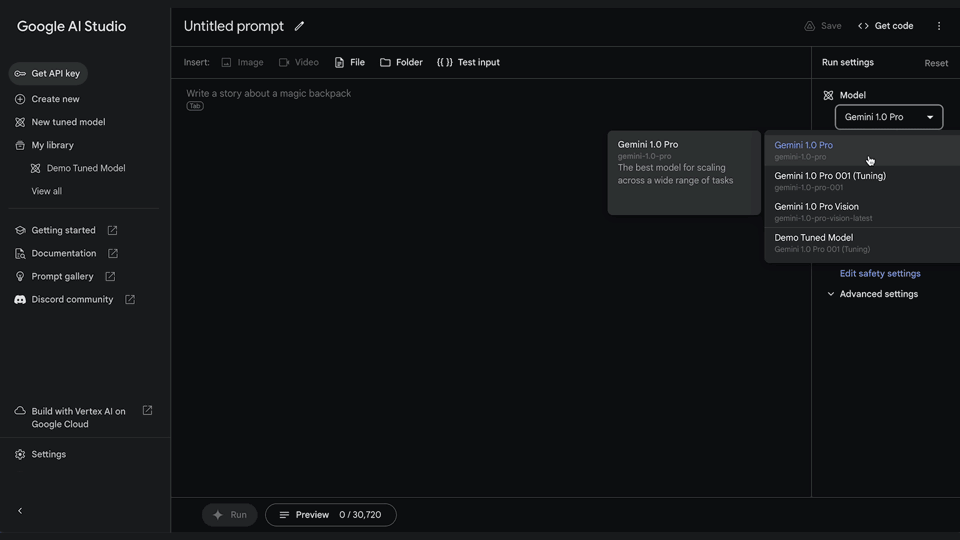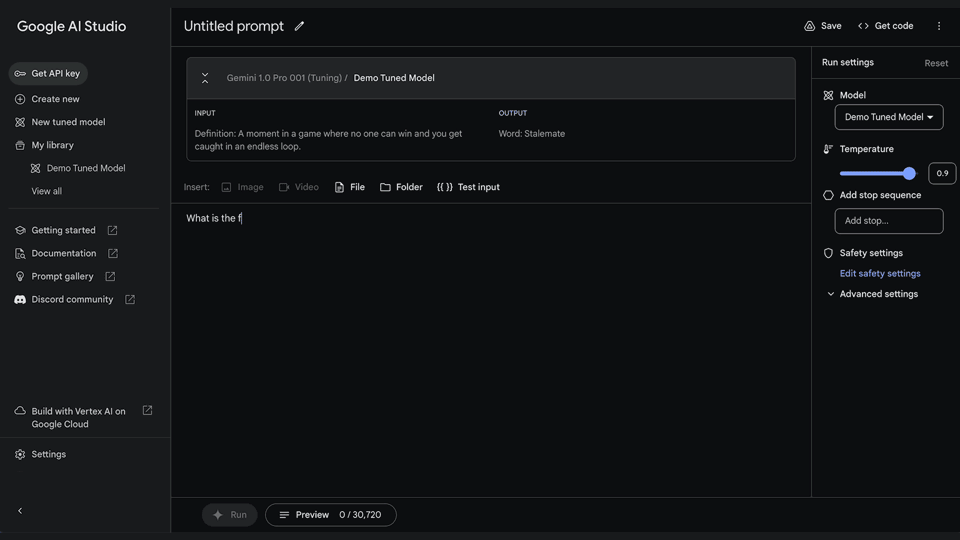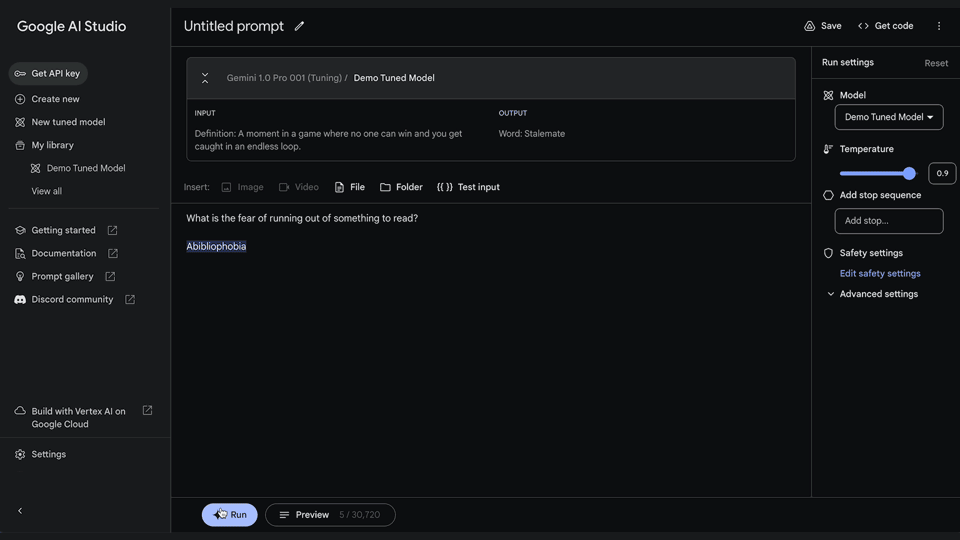
 Posted by Jeanine Banks – VP & General Manager, Developer X, and Head of Developer Relations
Posted by Jeanine Banks – VP & General Manager, Developer X, and Head of Developer Relations

 Posted by Justyna Politanska-Pyszko – Program Manager, Google Developer Experts
Posted by Justyna Politanska-Pyszko – Program Manager, Google Developer Experts

