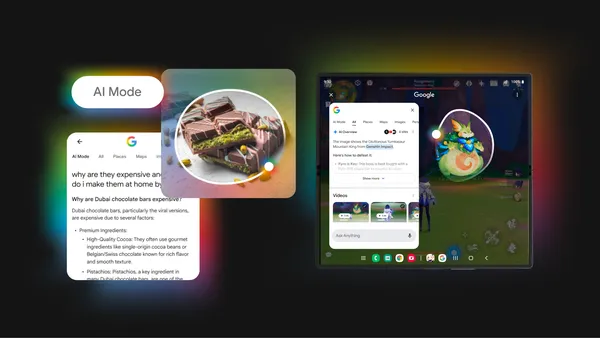
 We’re bringing new AI capabilities to Circle to Search, so you can dive deeper and ask follow-ups in AI Mode, and get gaming tips.
We’re bringing new AI capabilities to Circle to Search, so you can dive deeper and ask follow-ups in AI Mode, and get gaming tips.
Dive deeper with AI Mode and get gaming help in Circle to Search
We’re bringing new AI capabilities to Circle to Search, so you can dive deeper and ask follow-ups in AI Mode, and get gaming tips.
 Cosmetics company Lush is embracing Google Cloud AI to improve how they work.
Cosmetics company Lush is embracing Google Cloud AI to improve how they work.
 This field guide and investment support AI’s potential in evidence-based mental health interventions and research.
This field guide and investment support AI’s potential in evidence-based mental health interventions and research.
 Here are Google’s latest AI updates from June 2025
Here are Google’s latest AI updates from June 2025
 In Moving Archives, we’re bringing the iconic Harley-Davidson Museum archives to life with the help of Veo and Gemini.
In Moving Archives, we’re bringing the iconic Harley-Davidson Museum archives to life with the help of Veo and Gemini.
 Learn more about expanded access to Google Vids for all education users, and Gemini in Classroom, a new suite of no-cost AI tools available for educators.
Learn more about expanded access to Google Vids for all education users, and Gemini in Classroom, a new suite of no-cost AI tools available for educators.
 We love seeing how you’re using Ask Photos in early access, like asking "suggest photos that'd make great phone backgrounds" or "what did I eat on my trip to Barcelona?"…
We love seeing how you’re using Ask Photos in early access, like asking "suggest photos that'd make great phone backgrounds" or "what did I eat on my trip to Barcelona?"…
 Learn more about how startups can use Gemini models and other AI resources from Google.
Learn more about how startups can use Gemini models and other AI resources from Google.
 Here are five tips for making videos with Flow, Google’s new AI filmmaking tool.
Here are five tips for making videos with Flow, Google’s new AI filmmaking tool.
 Free and open source, Gemini CLI brings Gemini directly into developers’ terminals — with unmatched access for individuals.
Free and open source, Gemini CLI brings Gemini directly into developers’ terminals — with unmatched access for individuals.