Our teams at Google continue to support the tireless work of hospitals, nonprofits, and public health service providers across the country. Right now, we’re focused on three priority areas: ensuring people can access the latest and most authoritative information; amplifying vital safety and vaccination messages; and providing financial backing for affected communities, health authorities and other organizations.
Providing critical and authoritative information
On all our platforms, we’re taking steps to surface the critical information families and communities need to care for their own health and look after others.
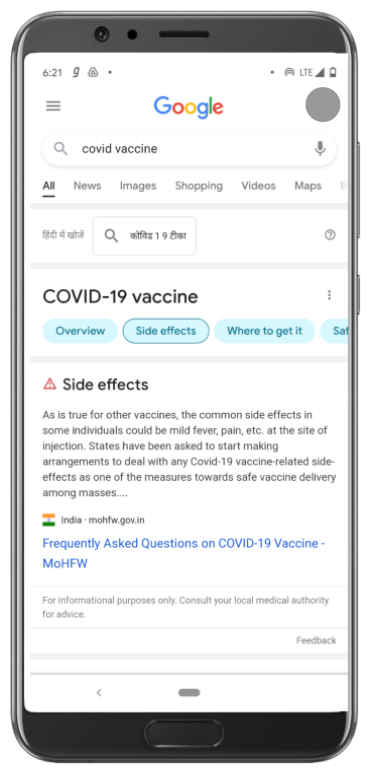
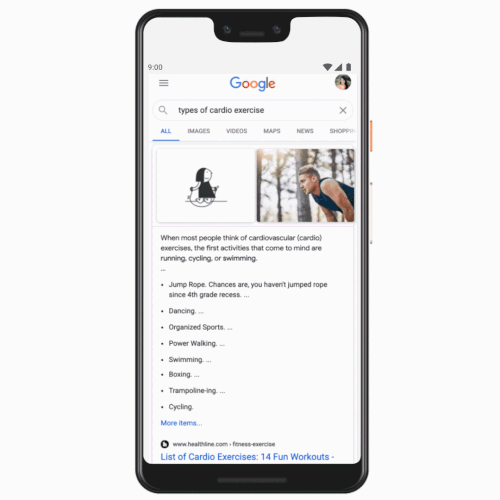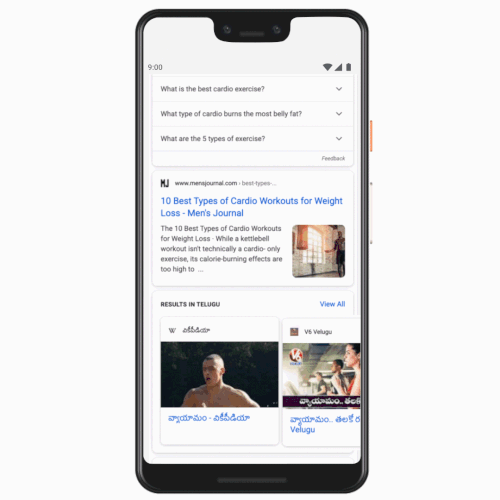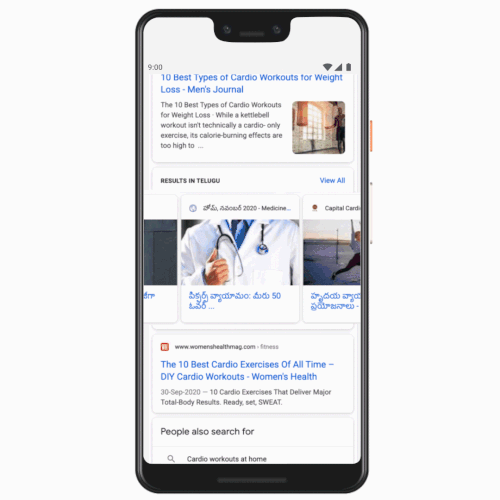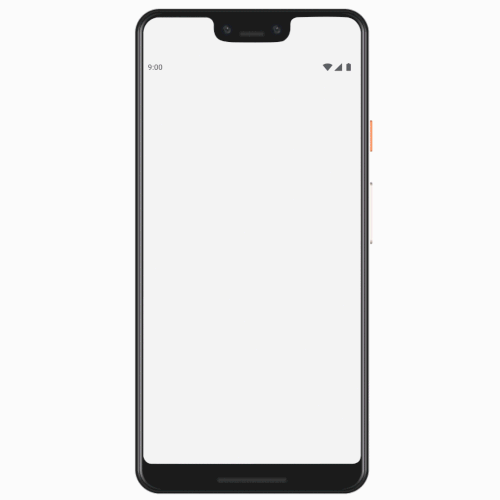
Searches on the COVID-19 vaccine display key information around side effects, effectiveness, and registration details, while treatment-related queries surface guidance from ministry resources

When people ask questions about vaccines on Google Search, they see information panels that display the latest updates on vaccine safety, efficacy and side-effects, plus registration information that directs users to the Co-WIN website. You will also find information about prevention, self-care, and treatment under the Prevention and Treatment tab, in easy-to-understand language sourced from authorised medical sources and the Ministry of Health and Family Welfare.
On YouTube we’re surfacing authoritative information in a set of playlists, about vaccines, preventing the spread of COVID-19, and facts from experts on COVID-19 care.

Our YouTube India channel features a set of playlists to share tips and information on COVID-19 care
Testing and vaccination center locations
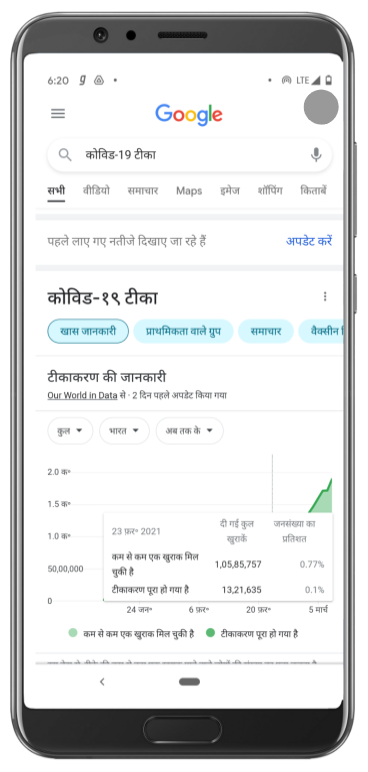
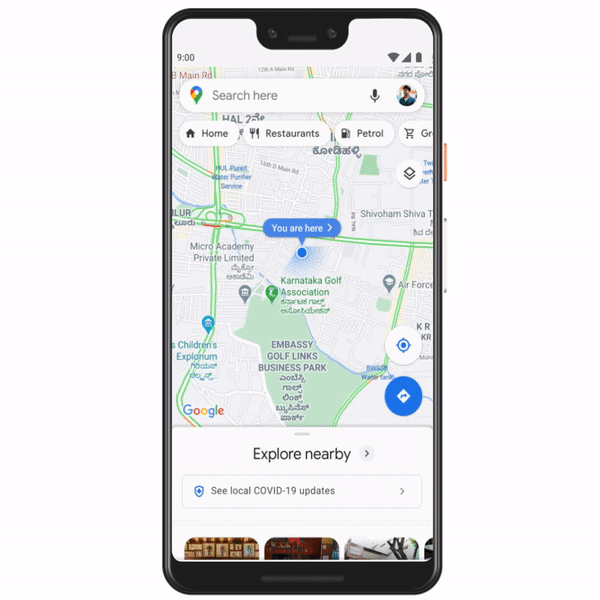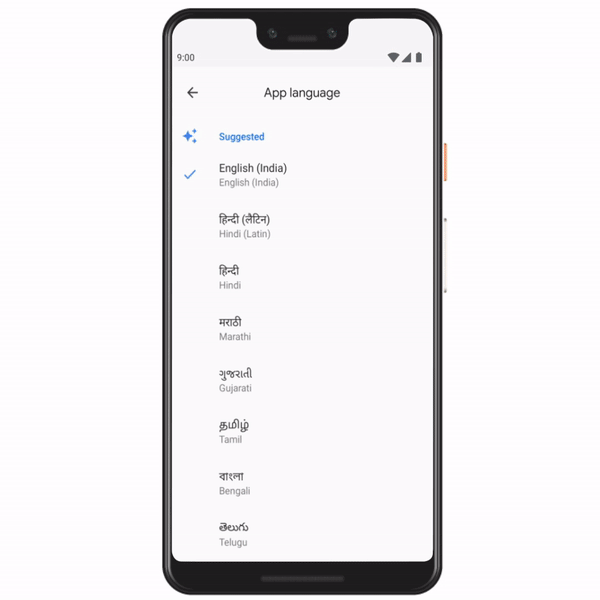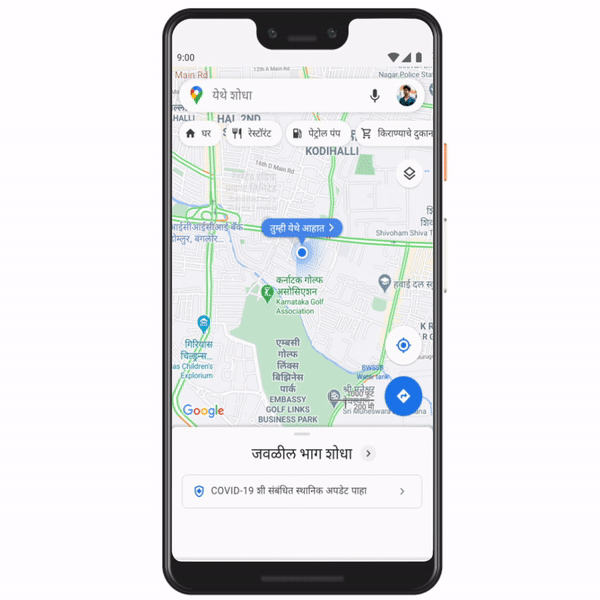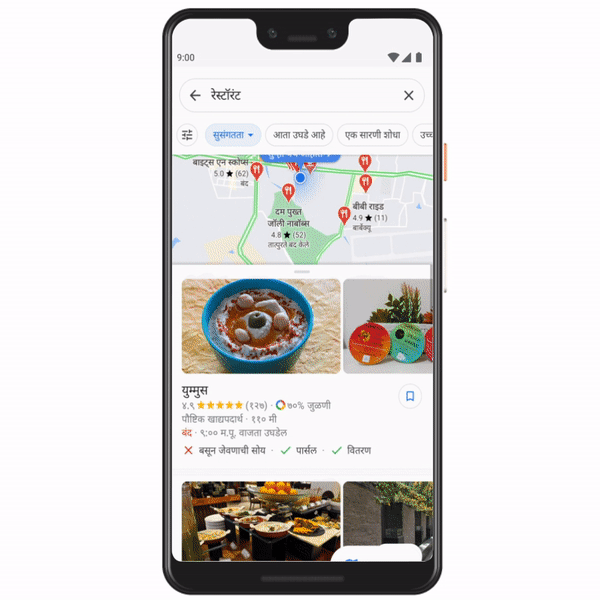
In addition to showing 2,500 testing centers on Search and Maps, we’re now sharing the locations of over 23,000 vaccination centers nationwide, in English and eight Indian languages. And we’re continuing to work closely with the Ministry of Health and Family Welfare to make more vaccination center information available to users throughout India.

Searching for vaccines in Maps and Search now shows over 23,000 vaccination centers across the country, in English and eight Indian languages
Pilot on hospital beds and medical oxygen availability
We know that some of the most crucial information people are searching for is the availability of hospital beds and access to medical oxygen. To help them find answers more easily, we’re testing a new feature using the Q&A function in Maps that enables people to ask about and share local information on availability of beds and medical oxygen in select locations. As this will be user generated content and not provided by authorised sources, it may be required to verify the accuracy and freshness of the information before utilizing it.
Amplifying vital safety and vaccination messages
As well as providing authoritative answers to queries, we’re using our channels to help extend the reach of health information campaigns. That includes the ‘Get the Facts’ around vaccines campaign, to encourage people to focus on authoritative information and content for vaccines. We’re also surfacing important safety messages through promotions on the Google homepage, Doodles and reminders within our apps and services.


Via the Google Search homepage and reminders within our apps and services, we are reminding people to stay safe and stay masked, and get authoritative information on vaccines
Supporting health authorities, organizations, and affected communities
Since the second wave began, we’ve been running an internal donation campaign to raise funds for nonprofit organizations helping those most in need, including GiveIndia, Charities Aid Foundation India, GOONJ, and United Way of Mumbai. This campaign has raised over $4.6 million (INR 33 crore) to date, and continues to generate much-needed support for relief efforts.
We recognize that many more nonprofits need donations, and that Indians are eager to help where they can—so we’ve rolled out a COVID Aid campaign on Google Pay, featuring non-profit organizations like GiveIndia, Charities Aid Foundation, Goonj, Save the Children, Seeds, UNICEF India (National NGOs) and United Way. We want to thank all our Google Pay users who have contributed to these organisations, and we hope this effort will make a difference where it matters most.

On Google Pay people can contribute funds to non-profit organizations involved in COVID response
As India battles this devastating wave, we’ll keep doing all we can to support the selfless individuals and committed organizations on the front lines of the response. There’s a long way to go—but standing together in solidarity, working together with determination, we can and will turn the tide.
Posted by the Covid Response team, Google India