Posted by Deborah Cohen, Staff Research Scientist, and Craig Boutilier, Principal Scientist, Google Research

As virtual assistants become ubiquitous, users increasingly interact with them to learn about new topics or obtain recommendations and expect them to deliver capabilities beyond narrow dialogues of one or two turns. Dynamic planning, namely the capability to look ahead and replan based on the flow of the conversation, is an essential ingredient for the making of engaging conversations with the deeper, open-ended interactions that users expect.
While large language models (LLMs) are now beating state-of-the-art approaches in many natural language processing benchmarks, they are typically trained to output the next best response, rather than planning ahead, which is required for multi-turn interactions. However, in the past few years, reinforcement learning (RL) has delivered incredible results addressing specific problems that involve dynamic planning, such as winning games and protein folding.
Today, we are sharing our recent advances in dynamic planning for human-to-assistant conversations, in which we enable an assistant to plan a multi-turn conversation towards a goal and adapt that plan in real-time by adopting an RL-based approach. Here we look at how to improve long interactions by applying RL to compose answers based on information extracted from reputable sources, rather than relying on content generated by a language model. We expect that future versions of this work could combine LLMs and RL in multi-turn dialogues. The deployment of RL “in the wild” in a large-scale dialogue system proved a formidable challenge due to the modeling complexity, tremendously large state and action spaces, and significant subtlety in designing reward functions.
What is dynamic planning?
Many types of conversations, from gathering information to offering recommendations, require a flexible approach and the ability to modify the original plan for the conversation based on its flow. This ability to shift gears in the middle of a conversation is known as dynamic planning, as opposed to static planning, which refers to a more fixed approach. In the conversation below, for example, the goal is to engage the user by sharing interesting facts about cool animals. To begin, the assistant steers the conversation to sharks via a sound quiz. Given the user's lack of interest in sharks, the assistant then develops an updated plan and pivots the conversation to sea lions, lions, and then cheetahs.
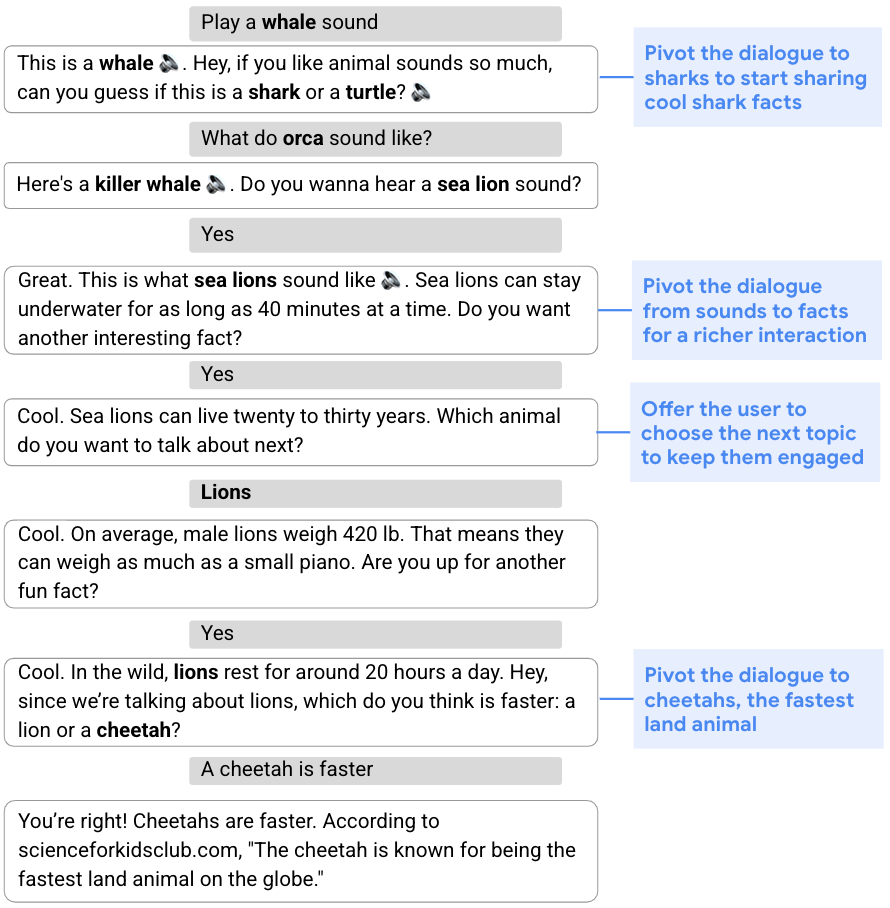 |
| The assistant dynamically modifies its original plan to talk about sharks and shares facts about other animals. |
Dynamic composition
To cope with the challenge of conversational exploration, we separate the generation of assistant responses into two parts: 1) content generation, which extracts relevant information from reputable sources, and 2) flexible composition of such content into assistant responses. We refer to this two-part approach as dynamic composition. Unlike LLM methods, this approach gives the assistant the ability to fully control the source, correctness, and quality of the content that it may offer. At the same time, it can achieve flexibility via a learned dialogue manager that selects and combines the most appropriate content.
In an earlier paper, “Dynamic Composition for Conversational Domain Exploration”, we describe a novel approach which consists of: (1) a collection of content providers, which offer candidates from different sources, such as news snippets, knowledge graph facts, and questions; (2) a dialogue manager; and (3) a sentence fusion module. Each assistant response is incrementally constructed by the dialogue manager, which selects candidates proposed by the content providers. The selected sequence of utterances is then fused into a cohesive response.
Dynamic planning using RL
At the core of the assistant response composition loop is a dialogue manager trained using off-policy RL, namely an algorithm that evaluates and improves a policy that is different from the policy used by the agent (in our case, the latter is based on a supervised model). Applying RL to dialogue management presents several challenges, including a large state space (as the state represents the conversation state, which needs to account for the whole conversation history) and an effectively unbounded action space (that may include all existing words or sentences in natural language).
We address these challenges using a novel RL construction. First, we leverage powerful supervised models — specifically, recurrent neural networks (RNNs) and transformers — to provide a succinct and effective dialogue state representation. These state encoders are fed with the dialogue history, composed of a sequence of user and assistant turns, and output a representation of the dialogue state in the form of a latent vector.
Second, we use the fact that a relatively small set of reasonable candidate utterances or actions can be generated by content providers at each conversation turn, and limit the action space to these. Whereas the action space is typically fixed in RL settings, because all states share the same action space, ours is a non-standard space in which the candidate actions may differ with each state, since content providers generate different actions depending on the dialogue context. This puts us in the realm of stochastic action sets, a framework that formalizes cases where the set of actions available in each state is governed by an exogenous stochastic process, which we address using Stochastic Action Q-Learning, a variant of the Q-learning approach. Q-learning is a popular off-policy RL algorithm, which does not require a model of the environment to evaluate and improve the policy. We trained our model on a corpus of crowd-compute–rated conversations obtained using a supervised dialogue manager.
 |
| Given the current dialogue history and a new user query, content providers generate candidates from which the assistant selects one. This process runs in a loop, and at the end the selected utterances are fused into a cohesive response. |
Reinforcement learning model evaluation
We compared our RL dialogue manager with a launched supervised transformer model in an experiment using Google Assistant, which conversed with users about animals. A conversation starts when a user triggers the experience by asking an animal-related query (e.g., “How does a lion sound?”). The experiment was conducted using an A/B testing protocol, in which a small percentage of Assistant users were randomly sampled to interact with our RL-based assistant while other users interacted with the standard assistant.
We found that the RL dialogue manager conducts longer, more engaging conversations. It increases conversation length by 30% while improving user engagement metrics. We see an increase of 8% in cooperative responses to the assistant’s questions — e.g., “Tell me about lions,” in response to “Which animal do you want to hear about next?” Although there is also a large increase in nominally “non-cooperative” responses (e.g., “No,” as a reply to a question proposing additional content, such as “Do you want to hear more?”), this is expected as the RL agent takes more risks by asking pivoting questions. While a user may not be interested in the conversational direction proposed by the assistant (e.g., pivoting to another animal), the user will often continue to engage in a dialogue about animals.
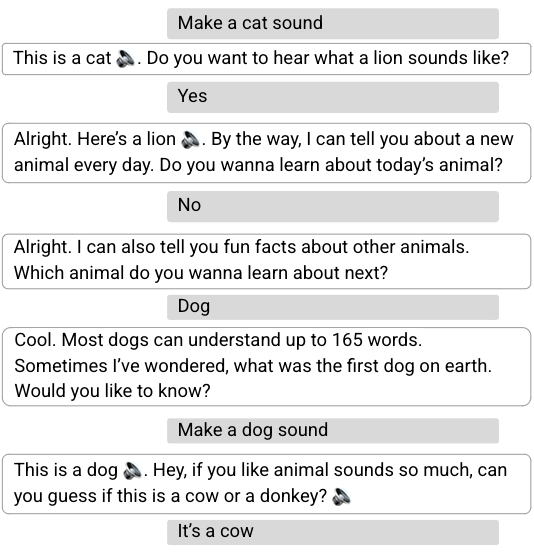 |
| From the non-cooperative user response in the 3rd turn (“No.”) and the query “Make a dog sound,” in the 5th turn, the assistant recognizes that the user is mostly interested in animal sounds and modifies its plan, providing sounds and sound quizzes. |
In addition, some user queries contain explicit positive (e.g., “Thank you, Google,” or “I’m happy.”) or negative (e.g., “Shut up,” or “Stop.”) feedback. While an order of magnitude fewer than other queries, they offer a direct measure of user (dis)satisfaction. The RL model increases explicit positive feedback by 32% and reduces negative feedback by 18%.
Learned dynamic planning characteristics and strategies
We observe several characteristics of the (unseen) RL plan to improve user engagement while conducting longer conversations. First, the RL-based assistant ends 20% more turns in questions, prompting the user to choose additional content. It also better harnesses content diversity, including facts, sounds, quizzes, yes/no questions, open questions, etc. On average, the RL assistant uses 26% more distinct content providers per conversation than the supervised model.
Two observed RL planning strategies are related to the existence of sub-dialogues with different characteristics. Sub-dialogues about animal sounds are poorer in content and exhibit entity pivoting at every turn (i.e., after playing the sound of a given animal, we can either suggest the sound of a different animal or quiz the user about other animal sounds). In contrast, sub-dialogues involving animal facts typically contain richer content and have greater conversation depth. We observe that RL favors the richer experience of the latter, selecting 31% more fact-related content. Lastly, when restricting analysis to fact-related dialogues, the RL assistant exhibits 60% more focus-pivoting turns, that is, conversational turns that change the focus of the dialogue.
Below, we show two example conversations, one conducted by the supervised model (left) and the second by the RL model (right), in which the first three user turns are identical. With a supervised dialogue manager, after the user declined to hear about “today’s animal”, the assistant pivots back to animal sounds to maximize the immediate user satisfaction. While the conversation conducted by the RL model begins identically, it exhibits a different planning strategy to optimize the overall user engagement, introducing more diverse content, such as fun facts.
 |
| In the left conversation, conducted by the supervised model, the assistant maximizes the immediate user satisfaction. The right conversation, conducted by the RL model, shows different planning strategies to optimize the overall user engagement. |
Future research and challenges
In the past few years, LLMs trained for language understanding and generation have demonstrated impressive results across multiple tasks, including dialogue. We are now exploring the use of an RL framework to empower LLMs with the capability of dynamic planning so that they can dynamically plan ahead and delight users with a more engaging experience.
Acknowledgements
The work described is co-authored by: Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor and Gal Elidan. We would like to thank: Roee Aharoni, Moran Ambar, John Anderson, Ido Cohn, Mohammad Ghavamzadeh, Lotem Golany, Ziv Hodak, Adva Levin, Fernando Pereira, Shimi Salant, Shachar Shimoni, Ronit Slyper, Ariel Stolovich, Hagai Taitelbaum, Noam Velan, Avital Zipori and the CrowdCompute team led by Ashwin Kakarla. We thank Sophie Allweis for her feedback on this blogpost and Tom Small for the visualization.