Posted by Steve Francia, Go Team
Posted by Steve Francia, Go TeamThe Go gopher was created by renowned illustrator Renee French. This image is adapted from a drawing by Egon Elbre.
November 10 marked Go’s 10th anniversary—a milestone that we are lucky enough to celebrate with our global developer community.
The Gopher community will be celebrating Go’s 10th anniversary at conferences such as Gopherpalooza in Mountain View and KubeCon in San Diego, and dozens of meetups around the world.
In recognition of this milestone, we’re taking a moment to reflect on the tremendous growth and progress Go (also known as golang) has made: from its creation at Google and open sourcing, to many early adopters and enthusiasts, to the global enterprises that now rely on Go everyday for critical workloads.
New to Go?
Go is an open-source programming language designed to help developers build fast, reliable, and efficient software at scale. It was created at Google and is now supported by over 2100 contributors, primarily from the open-source community. Go is syntactically similar to C, but with the added benefits of memory safety, garbage collection, structural typing, and CSP-style concurrency.
Most importantly, Go was purposefully designed to improve productivity for multicore, networked machines and large codebases—allowing programmers to rapidly scale both software development and deployment.
Millions of Gophers!
Today, Go has more than a million users worldwide, ranging across industries, experience, and engineering disciplines. Go’s simple and expressive syntax, ease-of-use, formatting, and speed have helped it become one of the fastest growing languages—with a thriving open source community.
As Go’s use has grown, more and more foundational services have been built with it. Popular open source applications built on Go include Docker, Hugo, Kubernetes. Google’s hybrid cloud platform, Anthos, is also built with Go.
Go was first adopted to support large amounts of Google’s services and infrastructure. Today, Go is used by companies including, American Express, Dropbox, The New York Times, Salesforce, Target, Capital One, Monzo, Twitch, IBM, Uber, and Mercado Libre. For many enterprises, Go has become their language of choice for building on the cloud.
An Example of Go In the Enterprise
One exciting example of Go in action is at MercadoLibre, which uses Go to scale and modernize its ecommerce ecosystem, improve cost-efficiencies, and system response times.
MercadoLibre’s core API team builds and maintains the largest APIs at the center of the company’s microservices solutions. Historically, much of the company’s stack was based on Grails and Groovy backed by relational databases. However this big framework with multiple layers was soon found encountering scalability issues.
Converting that legacy architecture to Go as a new, very thin framework for building APIs streamlined those intermediate layers and yielded great performance benefits. For example, one large Go service is now able to run 70,000 requests per machine with just 20 MB of RAM.
“Go was just marvelous for us,” explains Eric Kohan, Software Engineering Manager at MercadoLibre. “It’s very powerful and very easy to learn, and with backend infrastructure has been great for us in terms of scalability.”
Using Go allowed MercadoLibre to cut the number of servers they use for this service to one-eighth the original number (from 32 servers down to four), plus each server can operate with less power (originally four CPU cores, now down to two CPU cores). With Go, the company obviated 88 percent of their servers and cut CPU on the remaining ones in half—producing a tremendous cost-savings.
With Go, MercadoLibre’s build times are three times (3x) faster and their test suite runs an amazing 24 times faster. This means the company’s developers can make a change, then build and test that change much faster than they could before.
Today, roughly half of Mercadolibre's traffic is handled by Go applications.
"We really see eye-to-eye with the larger philosophy of the language," Kohan explains. "We love Go's simplicity, and we find that having its very explicit error handling has been a gain for developers because it results in safer, more stable code in production."
Visit go.dev to Learn More
We’re thrilled by how the Go community continues to grow, through developer usage, enterprise adoption, package contribution, and in many other ways.
Building off of that growth, we’re excited to announce go.dev, a new hub for Go developers.
There you’ll find centralized information for Go packages and modules, a wealth of learning resources to get started with the language, and examples of critical use cases and case studies of companies using Go.
MercadoLibre’s recent experience is just one example of how Go is being used to build fast, reliable, and efficient software at scale.
You can read more about MercadoLibre’s success with Go in the full case study.












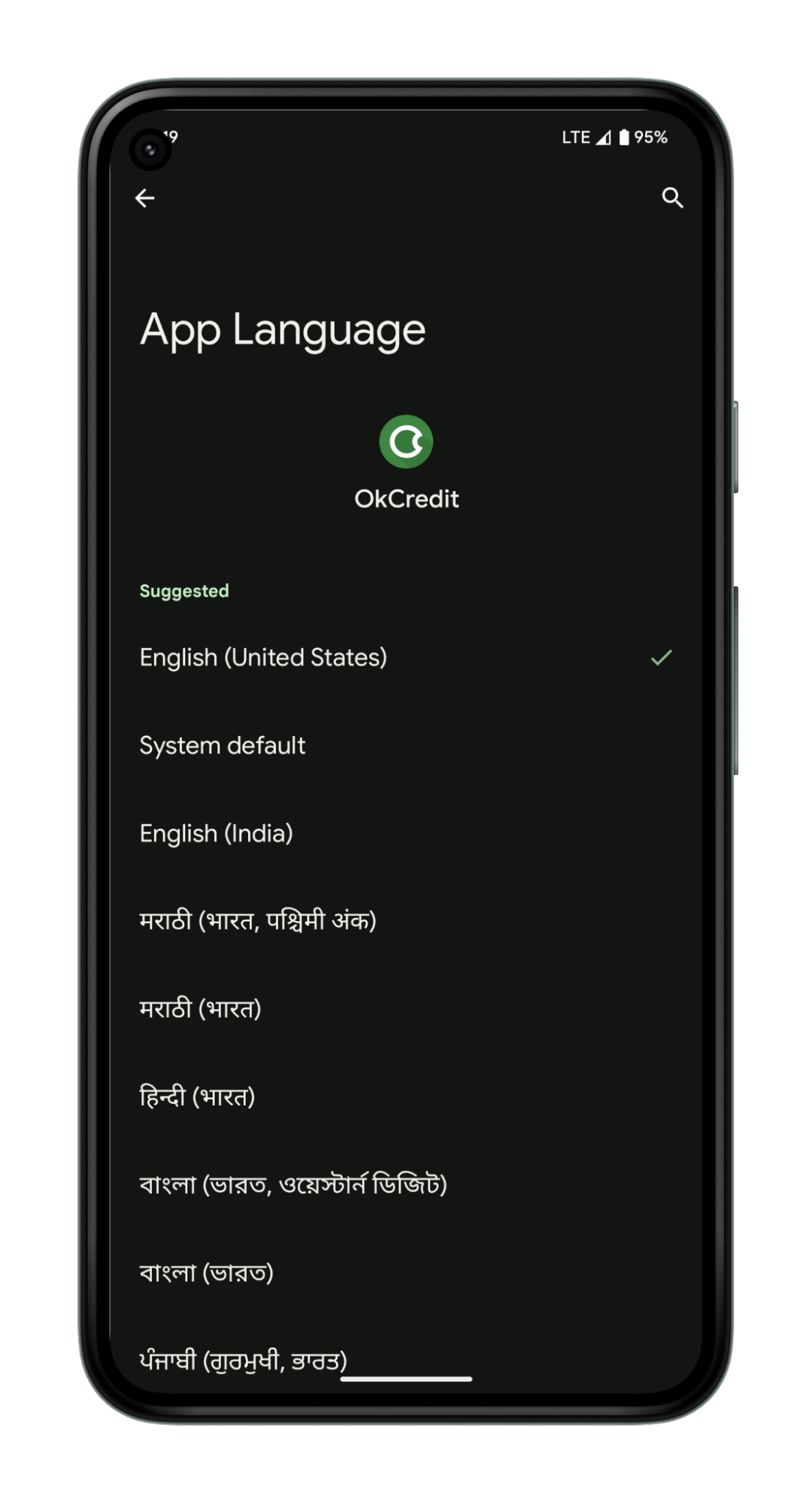



![A cellphone screen demonstrating finding the language settings from system settings by selecting Settings → System → Languages & Input → App Languages → [Select the desired App] → [Select the desired Language]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEigMMkDrk24GFhwQYTFL3SOe7BtcvUXhnudcyYkJE4um0woEr2aRZ78LqcP8_UaqoSJliwQmoBllEw44RwSYuPTaG372Oyorri8Q_qkaapDOrzkU6nR_kWh9pQTx6Jj6Tqmjb4VwqiPtn43bZsOoAQyQ1RZ9kLnhbEScICv-ApjTaPNS7Gd3L4HxJZu/s1600/image1.gif)