Posted by Zaid Nabulsi, Software Engineer and Po-Hsuan Cameron Chen, Software Engineer, Google Health The adoption of machine learning (ML) for medical imaging applications presents an exciting opportunity to improve the availability, latency, accuracy, and consistency of chest X-ray (CXR) image interpretation. Indeed, a plethora of algorithms have already been developed to detect specific conditions, such as lung cancer, tuberculosis and pneumothorax. By virtue of being trained to detect a specific disease, however, the utility of these algorithms may be limited in a general clinical setting, where a wide variety of abnormalities could surface. For example, a pneumothorax detector is not expected to highlight nodules suggestive of cancer, and a tuberculosis detector may not identify findings specific to pneumonia. Since an initial triaging step is to determine whether a CXR contains concerning abnormalities, a general-purpose algorithm that identifies X-rays containing any sort of abnormality could significantly facilitate the workflow. However, developing a classifier to do this is challenging due to the wide variety of abnormal findings that present on CXRs.
In “Deep Learning for Distinguishing Normal versus Abnormal Chest Radiographs and Generalization to Two Unseen Diseases Tuberculosis and COVID-19”, published in Scientific Reports, we present a model that can distinguish between normal and abnormal CXRs across multiple de-identified datasets and settings. We find that the model performs well on general abnormalities, as well as unseen examples of tuberculosis and COVID-19. We are also releasing our set of radiologists’ labels1 for the test set used in this study for the publicly available ChestX-ray14 dataset.
A Deep Learning System for Detecting Abnormal Chest X-rays
The deep learning system we used is based on the EfficientNet-B7 architecture, pre-trained on ImageNet. We trained the model using over 200,000 de-identified CXRs from the Apollo Hospitals in India. Each CXR was assigned a label of either “normal” or “abnormal” using a regular expression–based natural language processing approach on the associated radiology reports.
To evaluate how well the system generalizes to new patient populations, we compared its performance on two datasets consisting of a wide spectrum of abnormalities: the test split from the Apollo Hospitals dataset (DS-1), and the publicly available ChestX-ray14 (CXR-14). The labels for these two test sets were annotated for the purposes of this project by a group of US board-certified radiologists. The system achieved areas under the receiver operating characteristic curve (AUROC) of 0.87 on DS-1 and 0.94 on CXR-14 (higher is better).
Though the evaluations on DS-1 and CXR-14 contained a wide range of abnormalities, a possible use-case would be to utilize such an abnormality detector in novel or unforeseen settings with diseases that it had not encountered before. To evaluate the generalizability of the system to new patient populations and in the presence of diseases not seen in the training set, we used four de-identified datasets from three countries, including two publicly available tuberculosis datasets and two COVID-19 datasets from Northwestern Medicine. The system achieved AUCs of 0.95-0.97 in detecting tuberculosis, and 0.65-0.68 in detecting COVID-19. Because CXRs that are negative for these diseases could still contain other concerning abnormalities, we further evaluated the system for its ability to detect abnormalities more broadly (instead of disease positive vs. negative), finding AUCs of 0.91-0.93 for the tuberculosis dataset, and AUCs of 0.86 for the COVID-19 dataset.
 |
| The purpose of multiple evaluations (abnormality detection and disease detection) is the distinction between the two: a given disease can present with a certain abnormality or not; and a certain abnormality can arise from multiple diseases. Our study evaluates for both. |
The large drop in performance for COVID-19 is because many cases flagged by the system as “positive” for abnormalities were negative for COVID-19, but nevertheless contained abnormal CXR findings that needed attention. This further highlights the usefulness of abnormality detectors even if disease-specific models are available.
In addition, it’s important to note that there is a difference between generalization to unseen diseases (i.e., tuberculosis and COVID-19) versus generalization to unseen CXR findings (e.g., pleural effusion, consolidation/infiltrate). In this study, we demonstrated the generalizability of the system to unseen diseases but not necessarily unseen CXR findings.
 |
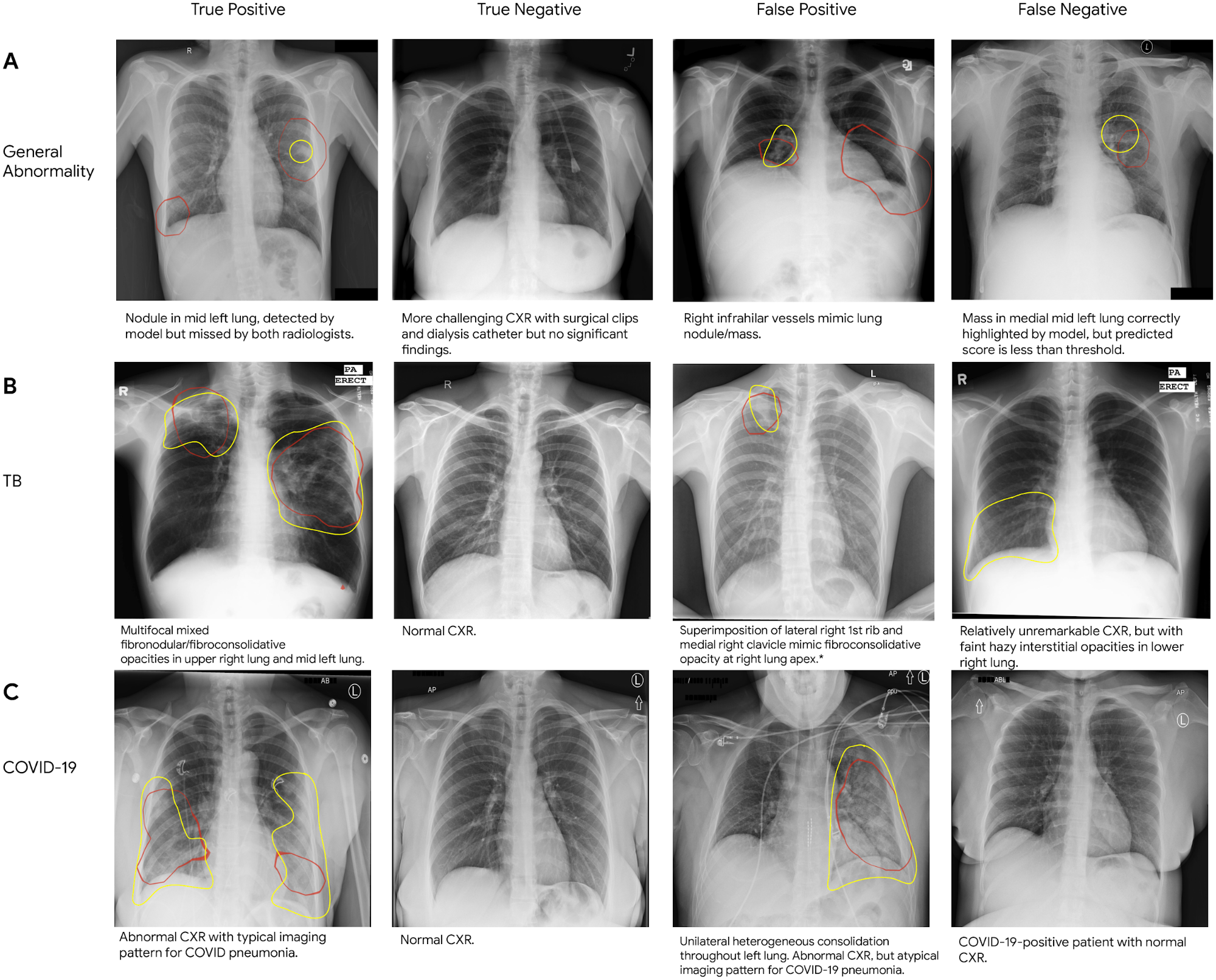
| Sample chest X-rays of true and false positives, and true and false negatives for (A) general abnormalities, (B) tuberculosis, and (C) COVID-19. On each CXR, we outline in red the areas on which the model focused to identify abnormalities (i.e., the class activation map), and outline the regions of interest indicated by a radiologist in yellow. |
Potential Benefits in the Clinic
To understand the potential utility of the deep learning model in improving clinical workflow, we simulated its use for case prioritization, where abnormal cases are “expedited” ahead of normal cases. In these simulations, the system reduced the turnaround time for abnormal cases by up to 28%. This reprioritization setup could be used to divert complex abnormal cases to cardiothoracic specialist radiologists, enable rapid triage of cases that may need urgent decisions, and provide the opportunity to batch negative CXRs for streamlined review.
 |
| Impact of a simulated deep learning model–based prioritization in comparison with random review order for (A) general abnormalities, (B) tuberculosis, and (C) COVID-19. The red bars indicate sequences of abnormal CXRs in red and normal CXRs in pink; a greater density of red towards the left indicates abnormal CXRs are reviewed sooner than normal ones. The histograms indicate the average improvement in turnaround time. |
Additionally, we found that the system can be used as a pre-trained model to improve other ML algorithms for chest X-rays, especially when data is limited. For example, we used the normal/abnormal classifier in our recent study to detect pulmonary tuberculosis from chest X-rays. Abnormality and tuberculosis detectors can play a critical role in supporting early diagnosis in regions that lack access to resources like trained radiologists or molecular testing.
Sharing Improved Reference Standard Labels
Much work remains to be done to realize the potential of ML to aid chest X-ray interpretation around the world. In particular, obtaining high-quality labels on de-identified data can be a significant barrier to developing and evaluating ML algorithms in healthcare. To accelerate these efforts, we are expanding upon our previous label release by releasing the labels used in this study for the publicly available ChestX-ray14 dataset. We look forward to future machine learning projects by the community in this space.
AcknowledgementsKey contributors to this project at Google include Zaid Nabulsi, Andrew Sellergren, Shahar Jamshy, Charles Lau, Eddie Santos, Atilla P. Kiraly, Wenxing Ye, Jie Yang, Rory Pilgrim, Sahar Kazemzadeh, Jin Yu, Greg S. Corrado, Lily Peng, Krish Eswaran, Daniel Tse, Neeral Beladia, Yun Liu, Po-Hsuan Cameron Chen, Shravya Shetty. Significant contributions and input were also made by radiologist collaborators Sreenivasa Raju Kalidindi, Mozziyar Etemadi, Florencia Garcia Vicente, David Melnick. For the CXR-14 dataset, we thank the NIH Clinical Center for making it publicly available. For tuberculosis data collection, thanks go to Sameer Antani, Stefan Jaeger, Sema Candemir, Zhiyun Xue, Alex Karargyris, George R. Thomas, Pu-Xuan Lu, Yi-Xiang Wang, Michael Bonifant, Ellan Kim, Sonia Qasba, and Jonathan Musco. The authors would also like to acknowledge many members of the Google Health Radiology and labeling software teams, in particular Shruthi Prabhakara, Scott McKinney, and Akib Uddin. Sincere appreciation also goes to the radiologists who enabled this work with their image interpretation and annotation efforts throughout the study; Jonny Wong for coordinating the imaging annotation work; Gavin Bee, Mikhail Fomitchev, Shabir Adeel, Jeff Bertram, and Benedict Noero for data releasing; David F. Steiner, Kunal Nagpal, and Michael D. Howell for providing feedback on the manuscript; Craig Mermel, Lauren Winer, Johnny Luu, Adrienne Welch, Annisah Um'rani, and Ashley Zlatinov for feedback on the blogpost.
1Labels include atelectasis, cardiomegaly, effusion, infiltration, mass, nodule, pneumonia, pneumothorax, consolidation, edema, emphysema, fibrosis, pleural thickening, hernia, other abnormality, and normal vs abnormal. ↩