gVisor is a sandboxing technology that provides a secure environment for running untrusted code. In our previous blog post, we discussed how gVisor performance improves with a root filesystem overlay. In this post, we'll dive into another filesystem optimization that was recently launched: directfs. It gives gVisor’s application kernel (the Sentry) secure direct access to the container filesystem, avoiding expensive round trips to the filesystem gofer.
Origins of the Gofer
gVisor is used internally at Google to run a variety of services and workloads. One of the challenges we faced while building gVisor was providing remote filesystem access securely to the sandbox. gVisor’s strict security model and defense in depth approach assumes that the sandbox may get compromised because it shares the same execution context as the untrusted application. Hence the sandbox cannot be given sensitive keys and credentials to access Google-internal remote filesystems.
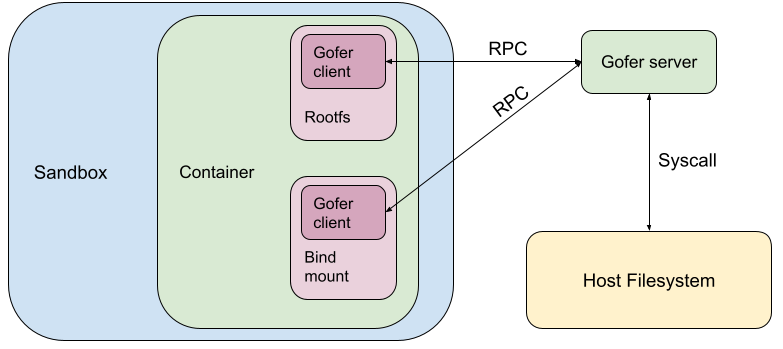
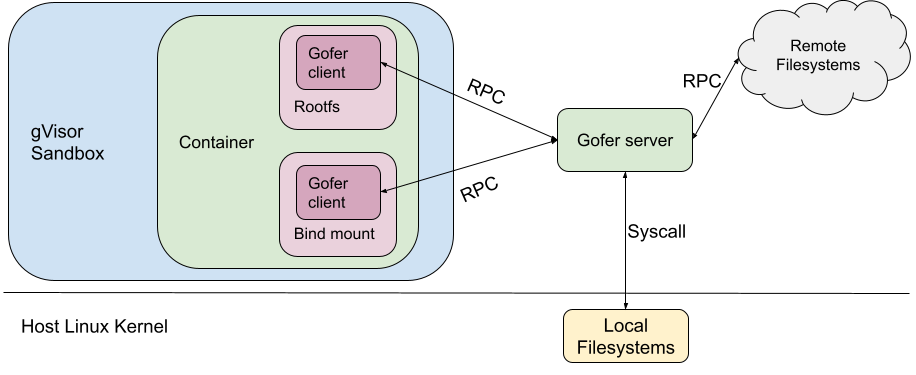
To address this challenge, we added a trusted filesystem proxy called a "gofer". The gofer runs outside the sandbox, and provides a secure interface for untrusted containers to access such remote filesystems. For architectural simplicity, gofers were also used to serve local filesystems as well as remote.
 |
Isolating the Container Filesystem in runsc
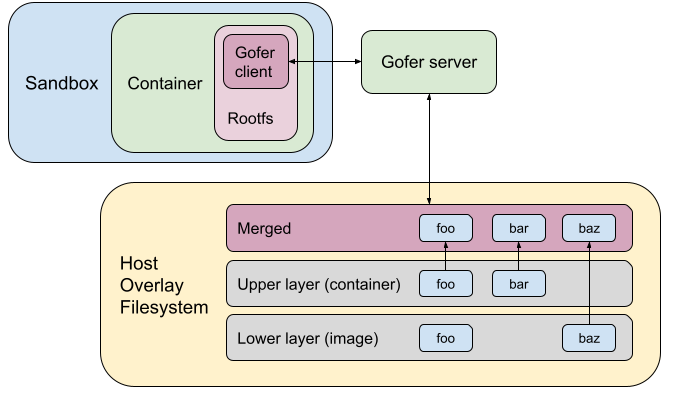
When gVisor was open sourced as runsc, the same gofer model was copied over to maintain the same security guarantees. runsc was configured to start one gofer process per container which serves the container filesystem to the sandbox over a predetermined protocol (now LISAFS). However, a gofer adds a layer of indirection with significant overhead.
This gofer model (built for remote filesystems) brings very few advantages for the runsc use-case, where all the filesystems served by the gofer (like rootfs and bind mounts) are mounted locally on the host. The gofer directly accesses them using filesystem syscalls.
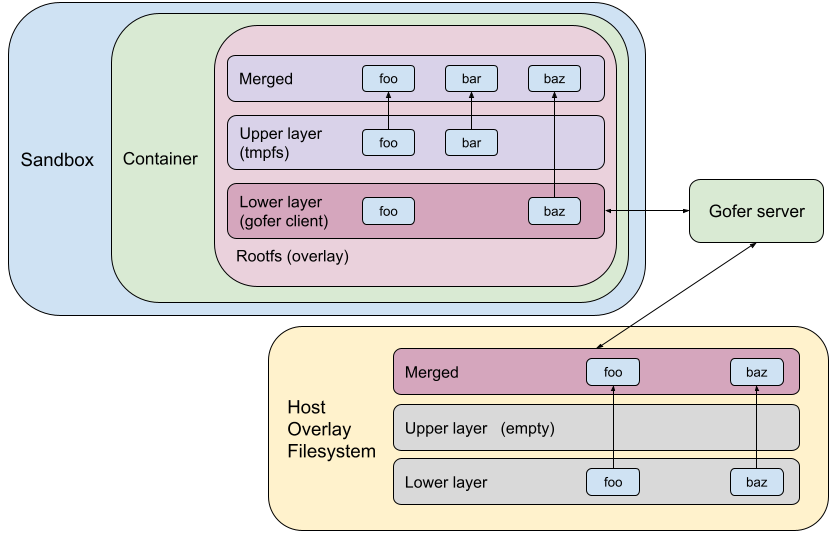
Linux provides some security primitives to effectively isolate local filesystems. These include, mount namespaces, pivot_root and detached bind mounts1. Directfs is a new filesystem access mode that uses these primitives to expose the container filesystem to the sandbox in a secure manner. The sandbox’s view of the filesystem tree is limited to just the container filesystem. The sandbox process is not given access to anything mounted on the broader host filesystem. Even if the sandbox gets compromised, these mechanisms provide additional barriers to prevent broader system compromise.
Directfs
In directfs mode, the gofer still exists as a cooperative process outside the sandbox. As usual, the gofer enters a new mount namespace, sets up appropriate bind mounts to create the container filesystem in a new directory and then pivot_root(2)s into that directory. Similarly, the sandbox process enters new user and mount namespaces and then pivot_root(2)s into an empty directory to ensure it cannot access anything via path traversal. But instead of making RPCs to the gofer to access the container filesystem, the sandbox requests the gofer to provide file descriptors to all the mount points via SCM_RIGHTS messages. The sandbox then directly makes file-descriptor-relative syscalls (e.g. fstatat(2), openat(2), mkdirat(2), etc) to perform filesystem operations.
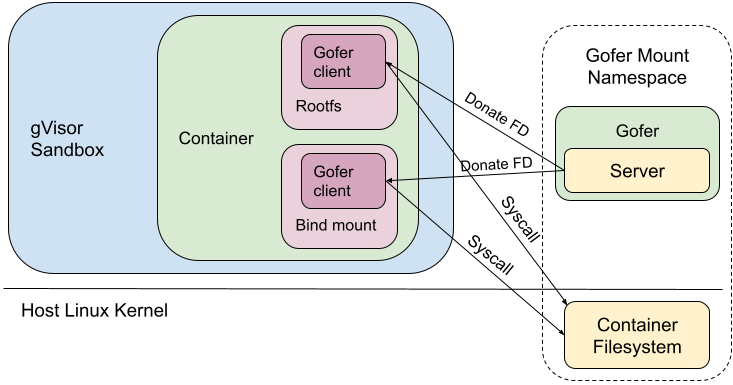 |
Earlier when the gofer performed all filesystem operations, we could deny all these syscalls in the sandbox process using seccomp. But with directfs enabled, the sandbox process's seccomp filters need to allow the usage of these syscalls. Most notably, the sandbox can now make openat(2) syscalls (which allow path traversal), but with certain restrictions: O_NOFOLLOW is required, no access to procfs and no directory FDs from the host. We also had to give the sandbox the same privileges as the gofer (for example CAP_DAC_OVERRIDE and CAP_DAC_READ_SEARCH), so it can perform the same filesystem operations.
It is noteworthy that only the trusted gofer provides FDs (of the container filesystem) to the sandbox. The sandbox cannot walk backwards (using ‘..’) or follow a malicious symlink to escape out of the container filesystem. In effect, we've decreased our dependence on the syscall filters to catch bad behavior, but correspondingly increased our dependence on Linux's filesystem isolation protections.
Performance
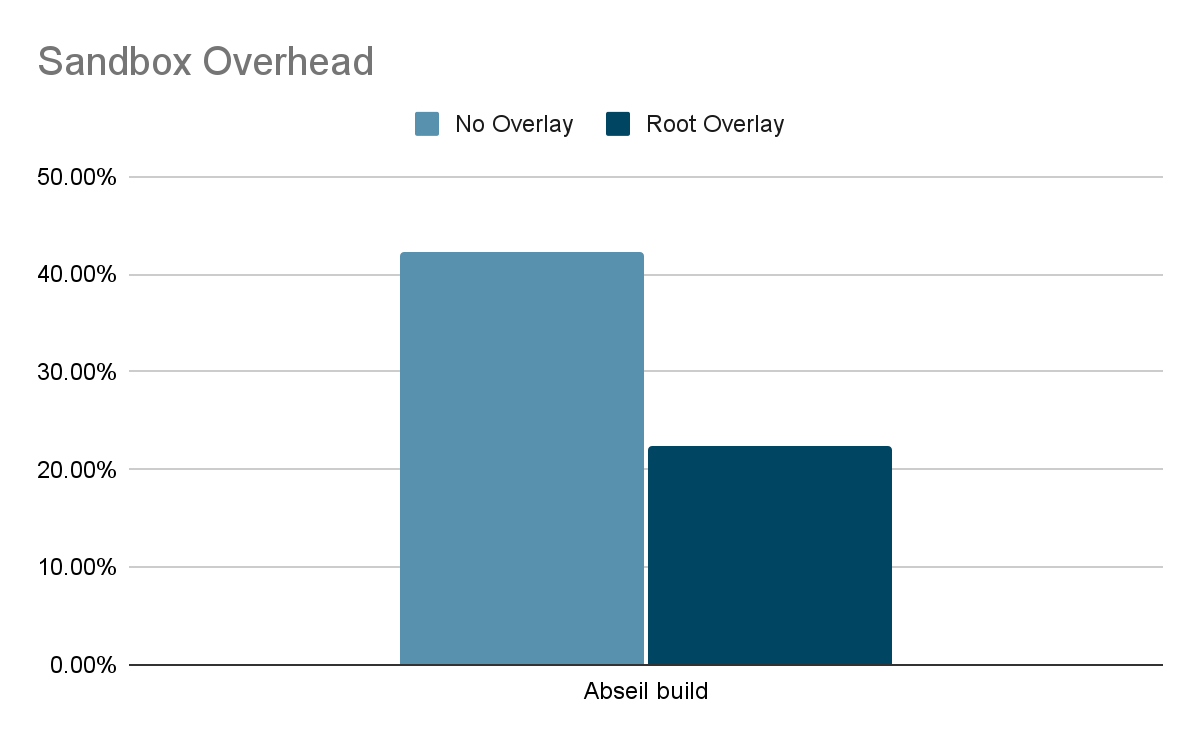
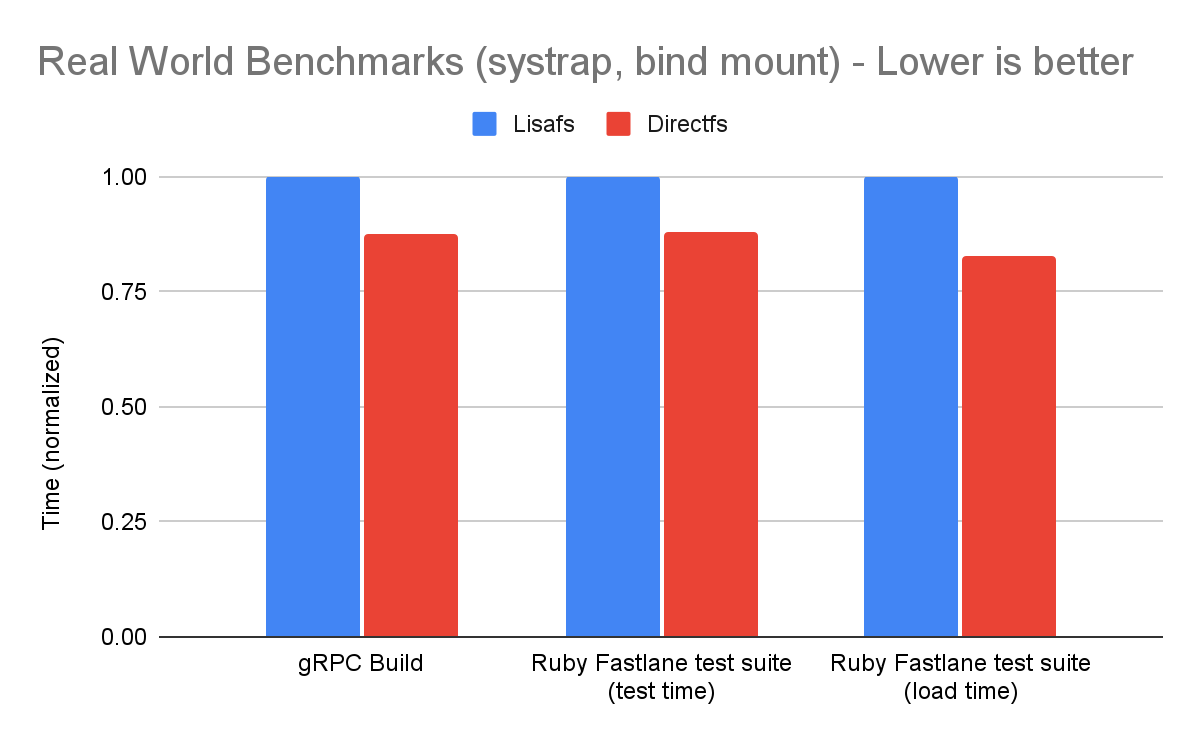
Making RPCs to the gofer for every filesystem operation adds a lot of overhead to runsc. Hence, avoiding gofer round trips significantly improves performance. Let's find out what this means for some of our benchmarks. We will run the benchmarks using our newly released systrap platform on bind mounts (as opposed to rootfs). This would simulate more realistic use cases because bind mounts are extensively used while configuring filesystems in containers. Bind mounts also do not have an overlay (like the rootfs mount), so all operations go through goferfs / directfs mount.
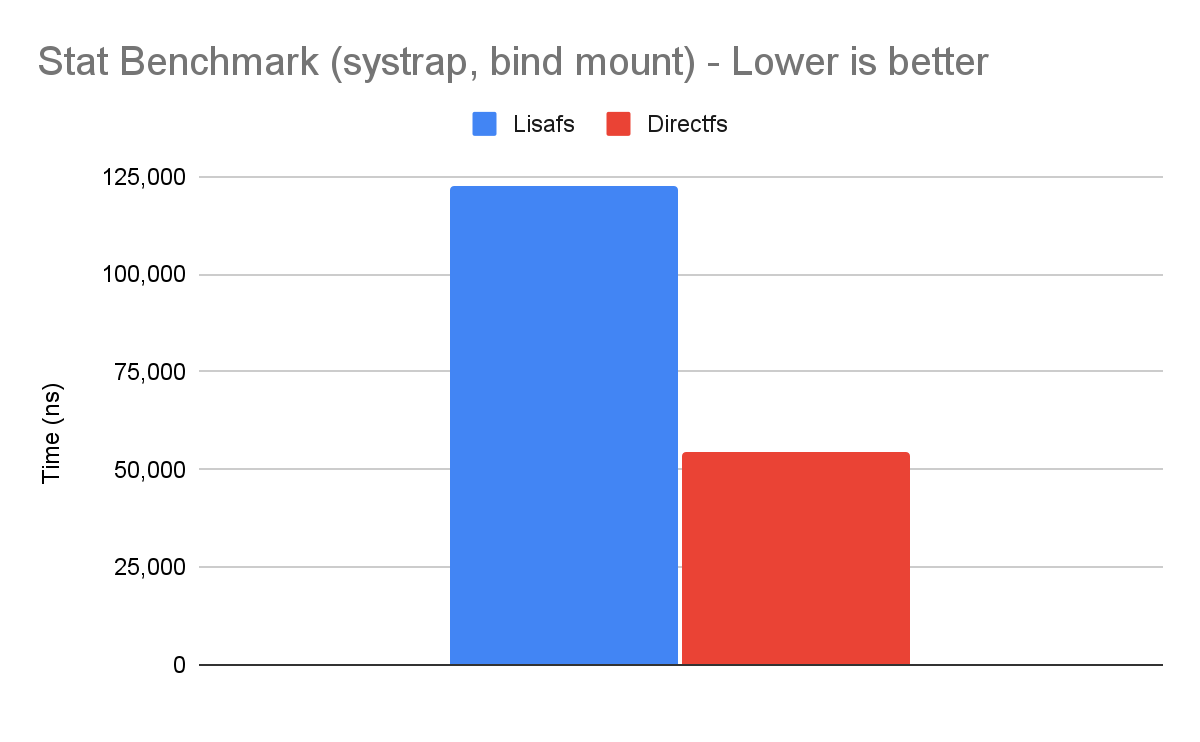
Let's first look at our stat micro-benchmark, which repeatedly calls stat(2) on a file.
 |
 |
Conclusion
The gofer model in runsc was overly restrictive for accessing host files. We were able to leverage existing filesystem isolation mechanisms in Linux to bypass the gofer without compromising security. Directfs significantly improves performance for certain workloads. This is part of our ongoing efforts to improve gVisor performance. You can learn more about gVisor at gvisor.dev. You can also use gVisor in GKE with GKE Sandbox. Happy sandboxing!
1Detached bind mounts can be created by first creating a bind mount using mount(MS_BIND) and then detaching it from the filesystem tree using umount(MNT_DETACH).
By Ayush Ranjan, Software Engineer – Google