3 New updates
Unless otherwise indicated, the features below are available to all Google Workspace customers, and are fully launched or in the process of rolling out. Rollouts should take no more than 15 business days to complete if launching to both Rapid and Scheduled Release at the same time. If not, each stage of rollout should take no more than 15 business days to complete.
Updates to the attachment menu in the Gmail app
We’ve updated and added new attachment options to the Gmail app on Android and iOS devices.
- On Android, in addition to the current options for attaching a file or inserting an item from Drive, you’ll now notice a dedicated menu item for Camera.
- On iOS, we recently replaced the attachment sheet that previously appeared at the bottom of your screen after clicking the attachment icon. Now, iOS users will see a menu experience similar to the one on Android devices that includes: Photos, Camera, Files, and Drive.
Rollout to
Rapid Release and Scheduled Release domains is complete for iOS devices. | Rolling out now to
Rapid Release and Scheduled Release domains for Android devices. | Available to Google Workspace customers, Google Workspace Individual subscribers, and users with personal Google accounts. | Visit the Help Center to learn more about
sending attachments with your Gmail message.
Additional accessibility tags for Tables, Equations, and Checkboxes in PDFs exported from Google Docs
2.0 Flash Thinking Experimental model upgrades in the Gemini app and Deep Research We’re pleased to announce that an improved version of Gemini 2.0 Flash Thinking Experimental will become available to Gemini app users. Built on the foundation of 2.0 Flash, this model delivers improved performance and better advanced reasoning capabilities with efficiency and speed. Gemini Advanced users will also have access to a 1M token context window with this model.
Additionally, we're upgrading
Gemini Deep Research to use the 2.0 Flash Thinking Experimental model. With advanced reasoning from 2.0 Flash Thinking Experimental, Gemini is even better at all stages of research from planning to delivering even more insightful and detailed reports.
Rollout to
Rapid Release and Scheduled Release domains is complete. | The improved version of 2.0 Flash Thinking Experimental and Deep Research with 2.0 Flash Thinking Experimental is available for Google Workspace Business Starter, Standard and Plus; Enterprise Starter, Standard and Plus; Frontline Starter and Standard; Essentials, Enterprise Essentials, Enterprise Essentials Plus; Education Standard and Plus; and Google Workspace for Nonprofits and customers with a Gemini Education or Gemini Education Premium add-on, and anyone who
previously purchased a Gemini Business or Gemini Enterprise add-on. | Visit the Help Center to learn more about using the
Gemini app with a work or school account in general, as well as for
in-depth research.
Previous announcements
The announcements below were published on the Workspace Updates blog earlier this week. Please refer to the original blog posts for complete details.
Quickly add events to Google Calendar based on your emails with Gemini in Gmail
Create files and folders using Gemini in the side panel of Google Drive
View invited meeting participants on Google Meet hardware
You can now see participants who were invited to the meeting but have yet to join the call right on Google Meet hardware. | Learn more about
invited Meet participants.
Use Gemini in the side panel of Workspace apps in four more languages
More AI-powered features in Google Meet and Google Chat are coming to Google Workspace Business and Enterprise editions
Earlier this year, we announced that we’re including the best of Google AI in Workspace Business and Enterprise plans without the need to purchase a separate Gemini add-on. Beginning this week, even more AI-powered features are available for Business and Enterprise editions. | Learn more about additional
AI-powered features.
Export your client-side encrypted documents to Microsoft Word files
Launching in beta, you can now export client-side encrypted Google Docs to Word files. This means you'll continue to own the encryption keys that protect your files to prevent unauthorized access from any third party (including Google or foreign governments) but convert your files as needed. | Learn more about
exporting your client-side encrypted documents to Microsoft Word files.
Embed AppSheet apps directly in Google Sites
You can now embed authenticated AppSheet applications as iframes directly within Google Sites pages. | Learn more about
AppSheet apps in Sites.
More languages are available for recorded captions and transcripts in Google Meet
"Take notes for me" in Google Meet is available in seven additional languages
We’re rolling out support “take notes for me” in the following seven additional languages: French, German, Italian, Japanese, Korean, Portuguese, and Spanish. | Learn more about
“Take notes for me” in Google Meet.
Deep Research and Gems in the Gemini app are now available for more Google Workspace customers
We’re expanding the availability of Deep Research and Gems in the Gemini app to Google Workspace:
- Business Starter
- Enterprise Starter
- Education Fundamentals, Standard, and Plus
- Frontline Starter and Standard
- Essentials, Enterprise Essentials, and Enterprise Essentials Plus
- Nonprofits
Learn more about
Deep Research and Gems.
Introducing AppSheet User Pass
You can now license any user of your apps with AppSheet User Pass. | Learn more about the
AppSheet User Pass.
Consent re-confirmation for under 18 users accessing Additional Services will soon be required
In September 2024, we communicated that we now require admins who have Additional Services enabled for users under the age of 18 to re-review them on an annual basis. Admins are always in control of which services their users have access to, and this gives admins an opportunity to ensure the right users have access to the right services. | Learn more about
consent re-confirmation for under 18 users accessing Additional Services.
Completed rollouts
Rapid Release Domains:
Scheduled Release Domains:
Rapid and Scheduled Release Domains:
For a recap of announcements in the past six months, check out What’s new in Google Workspace (recent releases).
 Example of customized captions in Meet
Example of customized captions in Meet
.png)




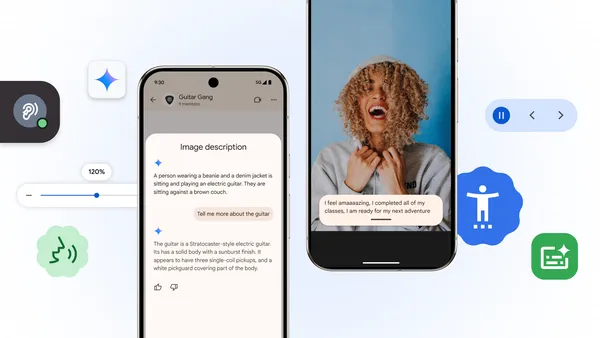 In honor of Global Accessibility Awareness Day, we’re excited to roll out new updates across Android and Chrome, plus new resources for the ecosystem.
In honor of Global Accessibility Awareness Day, we’re excited to roll out new updates across Android and Chrome, plus new resources for the ecosystem.


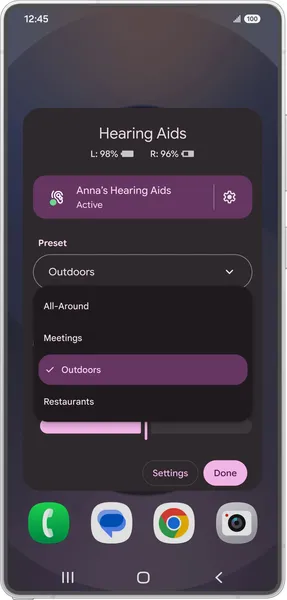 Today we’re rolling out a handful of updates to make Android’s hearing aid and screenreader experiences even more accessible.Starting with the Samsung Galaxy S25, we’re …
Today we’re rolling out a handful of updates to make Android’s hearing aid and screenreader experiences even more accessible.Starting with the Samsung Galaxy S25, we’re …
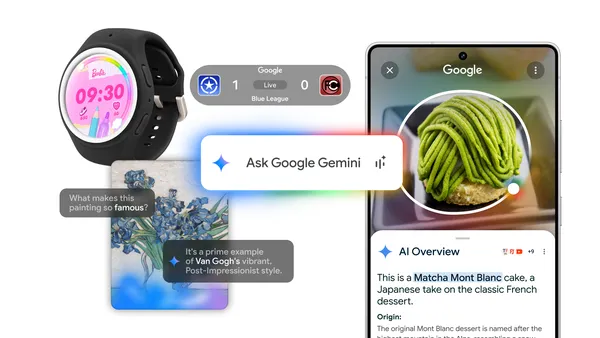 Learn more about the Google and Android updates announced at Galaxy Unpacked.
Learn more about the Google and Android updates announced at Galaxy Unpacked.

 The new Live Caption feature gives you the full picture of emotion in what’s being said on your device.
The new Live Caption feature gives you the full picture of emotion in what’s being said on your device.
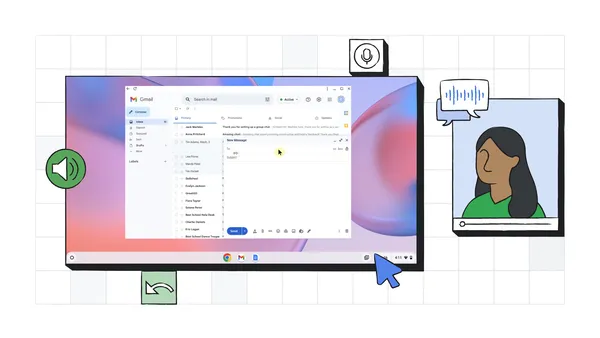 Face control on Chromebooks uses facial gestures and machine learning to let people with motor impairments control their devices without having to use their hands.
Face control on Chromebooks uses facial gestures and machine learning to let people with motor impairments control their devices without having to use their hands.