Posted by Google for Developers
Posted by Google for Developers

For many, Halloween is the perfect excuse to dress up and celebrate the things that haunt us. Google for Developers is embracing the spirit of the season by diving into the spine-chilling challenges that spook software developers and engineers. Read on to uncover these lurking terrors and discover the tricks – and treats – to conquer them.
The code cemetery
Resilient code requires regular updates, and when it comes to solving bugs, it’s much easier to find them when there are fewer lines of code. When faced with legacy or lengthy code, consider simplifying and refreshing it to make it more manageable – because no one likes an ancient or overly complex codebase. Here are some best practices.
Start small: Don't try to update your entire codebase at once. Instead, start by updating small, isolated parts of the codebase to minimize the risk of introducing new bugs.
Use a version control system: Track your changes and easily revert to a previous version if necessary.
Consider a refactoring tool: This can help you to make changes to your code without breaking it.
Test thoroughly: Make sure to test your changes thoroughly before deploying them to production. This includes testing the changes in isolation, as well as testing them in conjunction with the rest of the codebase. See more tips about testing motivation below.
Document your changes: Include new tooling, updated APIs, and any changes so other developers understand what you have done and why.
Testing terrors
When you want to build and ship quickly, it’s tempting to avoid writing tests for your code because they might slow you down in the short term. But beware, untested code will come back to haunt you later. Testing is a best practice that can save you time, money, and angst in the long run. Even if you know you should run tests, it doesn’t mean you want to. Use these tips to help make writing tests easier.
Test gamification: Turn test writing into a game. Challenge yourself to write tests faster than your coworker can say "code coverage."
Pair programming: Write tests together with a colleague. It's like having a workout buddy – more fun and motivating.
Set up test automation: Automate tests wherever possible– it's better AND more efficient.
A monster problem: not being able to choose your tech stack
Many developers have strong preferences when it comes to products, but sometimes legacy technology or organizational needs can limit choices. This can be deflating, especially if it prevents you from using the latest tools. If you’re faced with a similar situation, it’s worth expressing your recommendations to your team. Here’s how:
Lobby for change: If the current tech stack really isn't working out, advocate for a change. This may require documentation over a series of events, but you can use that to build your case.
Pitch the benefits: If you’re ready to share your preferences, explain how your tech stack of choice benefits the project, similarly to how optimized code improves performance.
Showcase expertise: Demonstrate your knowledge in your preferred stack, whether it’s through a Proof of Concept or a presentation.
Upskill: If you have to dive into a top-down tech stack that you are not familiar with, consider it a learning opportunity. It’s like exploring a new coding language.
Compromise is key: First, recognize that all of the points above are still well-worth aiming for, but sometimes, you do have to compromise. Think of it as working with legacy code - not ideal, but doable. So if you aren’t able to influence in your favor, don’t be dismayed.
Not a trick: ship your code smarter
The only thing worse than spending the end of the week fixing buggy code isexcept for spending the weekend fixing buggy code when you had other plans. Between less time to react to problems, taking up personal time, and fewer people available to help troubleshoot – shipping code when you don’t have the proper resources in place to help is risky at best. Here are a handful of best practices to help you build a better schedule and avoid the Saturday and Sunday Scaries.
Consider business hours and user impact: Schedule deployments during off-peak times when fewer users will be impacted. For B2B companies, Friday afternoons can minimize disruption for customers, but for smaller companies, Friday deployments might mean spending your weekend fixing critical issues. Pick a schedule that works for you.
Automate testing: Implement automated testing in your development process to catch issues early.
Make sure your staging environment is right: Thoroughly test changes in a staging environment that mirrors production.
Be rollback-ready: Have a rollback plan ready to revert quickly if problems arise.
Monitoring and alerts: Set up monitoring and alerts to catch issues 24/7.
Communication: Ensure clear communication among team members regarding deployment schedules and procedures.
Scheduled deployments: If you’re a team who doesn’t regularly ship at the end of the week, consider READ-ONLY Fridays. Or if necessary, schedule Friday deployments for the morning or early afternoon.
Weekend on-call: Consider a weekend on-call rotation to address critical issues.
Post-deployment review: Analyze and learn from each deployment's challenges to improve processes.
Plan thoroughly: Ensure deployment processes are well-documented and communication is clear across teams and stakeholders.
Evaluate risks: Assess potential business and user impact to determine deployment frequency and timing.
A nightmare come true: getting hacked
Realizing you've been hacked is a heart-stopping event, but even the most tech-savvy developers are vulnerable to attacks. Before it happens to you, remember to implement these best practices.
Keep your systems and software up-to-date: Think of it as patching vulnerabilities in your code.
Use strong passwords: Just like strong encryption, use robust passwords.
Use two-factor authentication: Always add a second layer of security.
Beware of phishermen: Don't take the bait. Be as cautious with suspicious emails as you are with untested code.
Perform security audits: Regularly audit your systems for vulnerabilities, like running code reviews but for your cybersecurity.
Backup plan: Just like version control, maintain backups. They're your safety net in case things go full horror-movie.
The horror: third party data breaches
Data breaches are arguably the most terrifying yet plausible threat to developer happiness. No company wants to be associated with them, let alone the dev who chose the service or API to work with. Here are some tips for minimizing issues with third party vendors to help you avoid this scenario.
Perform due diligence on third-party vendors: Before working with a third-party vendor, carefully review their security practices and policies. Ask about security certifications, vulnerability management practices, and their incident response plan.
Require vendors to comply with security requirements: Create or add your input in a written contract with each third-party vendor that outlines the security requirements that the vendor must meet. This contract should include requirements for data encryption, access control, and incident reporting.
Monitor vendor activity: Ensure vendors comply with the security requirements in the contract by reviewing audit logs and conducting security assessments. Only grant access to data that a vendor needs to perform their job duties to help to minimize the impact of a data breach if the vendor is compromised.
Implement strong security controls: Within your own systems, protect data from unauthorized access through firewalls, intrusion detection systems, and data encryption.
Be wary of third-party APIs: Vet all security risks. Carefully review the API documentation to understand the permissions that are required and to ensure the API uses strong security practices.
Use secure coding practices: Use input validation, escaping output, and strong cryptography.
Keep software up to date: Always update with the latest security patch to help to protect against known vulnerabilities.
Creepin' it real
It’s easy to get spooked knowing what can go wrong, but by implementing these best practices, the chance of your work going awry goes down significantly.
What other spine-chilling developer challenges have you experienced? Share them with the community.



 Posted by Lidia Gaymond – Product Manager, Google Play
Posted by Lidia Gaymond – Product Manager, Google Play


 Posted by Fergus Hurley – Co-Founder & GM,
Posted by Fergus Hurley – Co-Founder & GM, 
 Posted by Alex Vanyo – Developer Relations Engineer
Posted by Alex Vanyo – Developer Relations Engineer

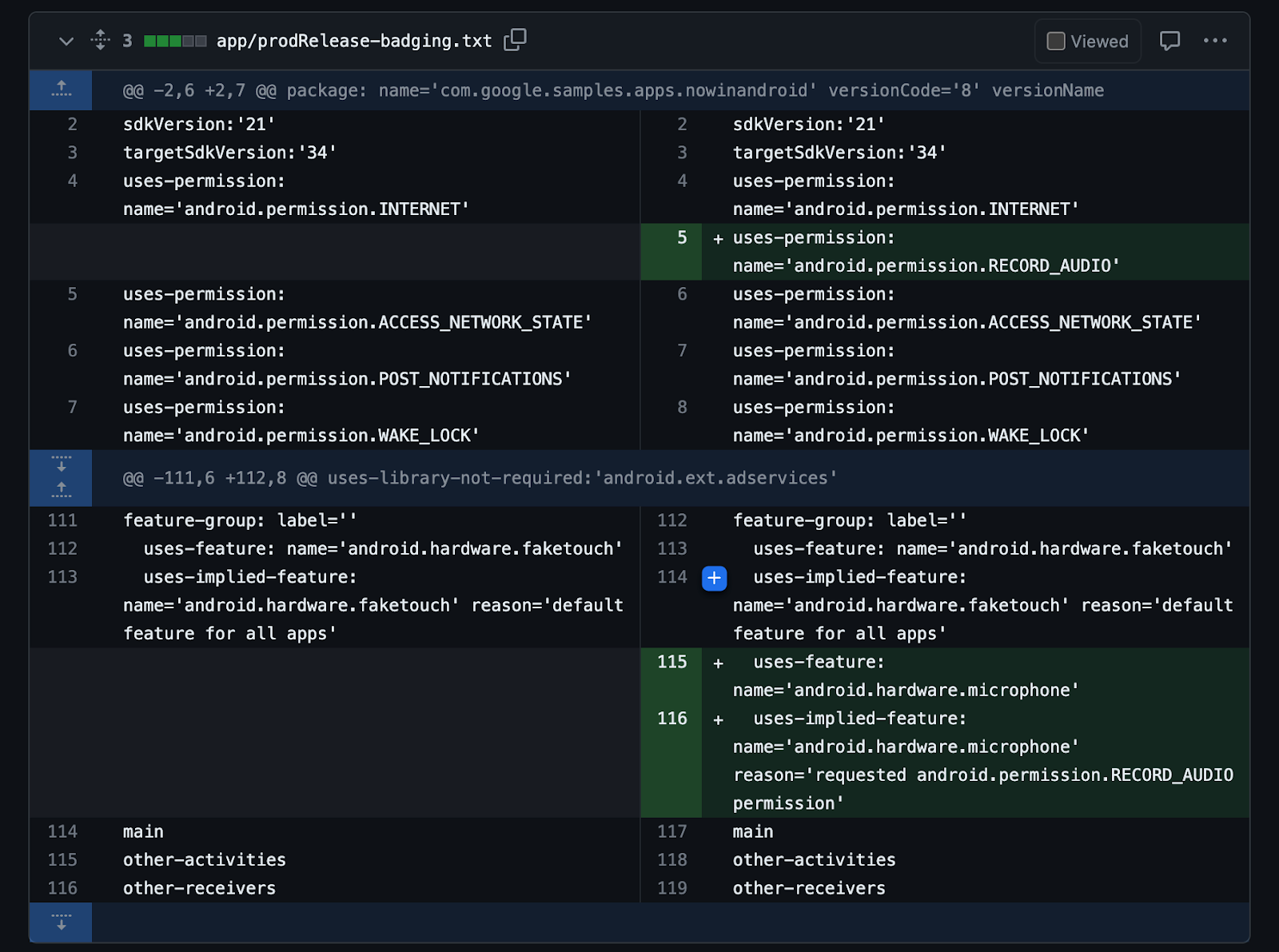
 Posted by Chris Wailes - Senior Software Engineer
Posted by Chris Wailes - Senior Software Engineer

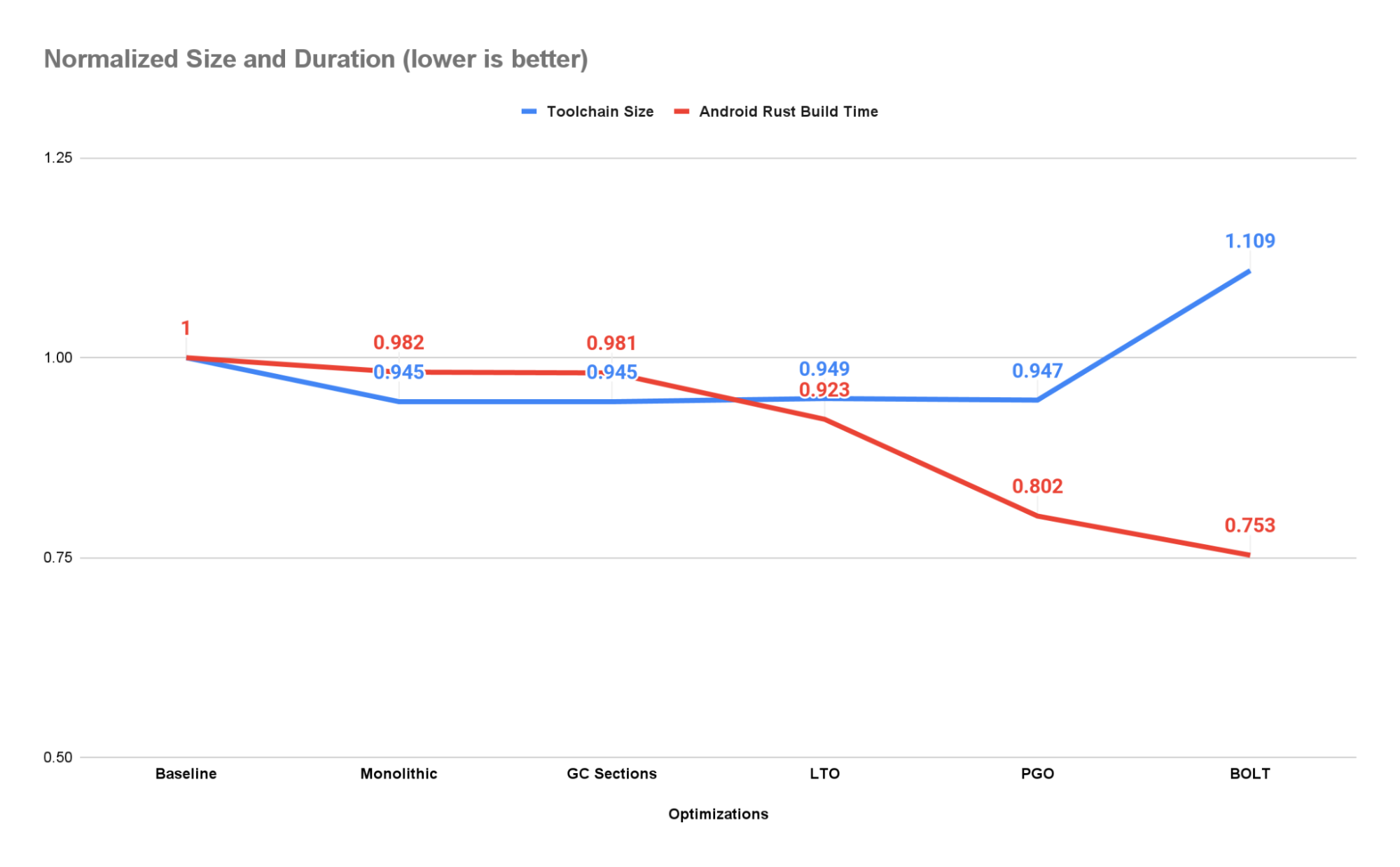
 Posted by Amy Zeppenfeld – Developer Relations Engineer
Posted by Amy Zeppenfeld – Developer Relations Engineer

 Posted by Vikrant Rana, Product Manager
Posted by Vikrant Rana, Product Manager