 Posted by Matt Van Der Staay – Engineering Director, Google Home
Posted by Matt Van Der Staay – Engineering Director, Google Home
As the saying goes, “home is where the heart is.” It’s where we spend the most time; it’s your space to be comfortable, where you can truly relax, connect and make memories. Our homes have gotten more helpful with connected products, such as a smart door lock or Nest thermostat. Despite this momentum, it's still too hard to develop for the home.
We are changing all of that. Building on the foundation of Matter, we've re-envisioned Google Home as a platform for developers - all developers, not just those that build smart home devices. Google Home is the destination to create innovative experiences for the home.
Today, we’re announcing the Home APIs and Home runtime. With the Home APIs, app developers can access over 600M devices, Google’s hubs and Matter infrastructure, and an automation engine powered by Google intelligence - all available on both Android and iOS. Here are five things to know:
1. Any developer can now build an experience that works with Google Home.
The home offers a unique opportunity for developers to create seamless and deeper relationships with users, but developing for the smart home is harder than it needs to be. Building for the smart home means integrations with many device makers, operating hubs and Matter fabrics, and operating automations engines driven by intelligent signals.
Whether you build an app specifically for smart home devices or build apps that have nothing to do with the smart home – like a fitness app or delivery app - the Home APIs will let you create app experiences that offer your customers delightful and differentiated experiences on both Android and iOS.
2. Access 600 million connected devices from your app
The new Device and Structure APIs let you access over 600M devices with a single integration. Control and manage the devices already connected to Google Home, such as Matter light bulbs or the Nest Learning Thermostat, whether at home, or on the go. You can build a complex app to manage any aspect of a smart home, or simply integrate with a smart device to solve pain points - like turning on the lights automatically before the food delivery driver arrives.
The Home APIs have been designed with privacy and security in mind, leveraging industry standard best practices. Users are always in control and need to explicitly grant access to their structure and smart home devices before an app can access it. And they can easily revoke access at any time from the Google Home app. To ensure quality experiences, developers who adopt the Home APIs must pass certification before launching their app.
The Device and Structure APIs provide all of the foundational building blocks to create a smart home experience.
The new Commissioning API lets you setup Matter devices in your app or the Home app or directly with Fast Pair on Android, without the need to create a new Matter fabric, saving you time and resources.
The Commissioning API provides all of the customer experience to set up a Matter device.
3. Automate with Google’s unique intelligence about the home
As people add more devices to their home, it becomes challenging to make them all work in unison. Over the past year, we have added new signals and allowed those with advanced skills to script their home using generative AI. With the new Automation API, you can create and manage home automations in your app, using Google Home’s new automation engine and intelligent signals.
Automations can be triggered by device signals from the home such as occupancy events from motion sensors, mode changes from appliances, or media events from a smart TV. For example, Yale is using the Automation API to turn on the foyer lights when the front door is unlocked at night. Automations can also use Google’s intelligence signals like home and away, which fuses together signals from devices across the home to create a more accurate presence detection.
The Automations API provides all of the tools for creating and managing automations.
4. Expanding hubs for Google Home to the TV
A hub for Google Home is a device that enables remote access and local control of their Matter devices across Wifi and Thread. The Home APIs use the network of hubs for Google Home to control Matter devices whether the user is in the home or away.
Later this year, we’re upgrading our hubs and introducing the Home runtime, so other devices, including Chromecast with Google TV, select panel TVs with Google TV running Android 14, or higher and eligible LG brand TVs will also become hubs for Google Home.
Home APIs make controlling lights and switches locally over a hub feel snappy. We are adopting these APIs in the Google Home app, and our early tests show device control operating up to three times faster than before. Developers using the Home APIs can see faster and more responsive local control in their apps as well.
5. Delightful new experiences from a diverse set of apps
We are working with a broad range of brands across lighting, security, automotive, energy, and entertainment to build seamless smart home experiences that help get more usefulness from the smart home.
Partners from every major smart home category are building on the Home APIs.
Here are how some of our first partners are using the Home APIs:
ADT’s new Trusted Neighbor will revolutionize the universal practice of “giving a trusted neighbor a key to your home,” enabling users to easily grant secure and temporary access to their homes for neighbors, friends or helpers.
LG will enable millions of TVs to be hubs for Google Home, allowing seamless control of devices from any app built using Home APIs. You will also be able to use the ThinQ mobile app or the Home Hub on the LG TV to control devices.
Eve Systems will bring their experience to Android for the first time and build helpful automations like lowering the blinds when the temperature drops at night.
Google Pixel is bridging the digital and physical worlds so that bedtime mode can not only dim your screen, but can also automatically dim your bedroom lights, lower the shades and lock the front door.
And this is just the beginning. With the Home APIs, a workout app could keep you cool while you are burning calories by turning on the fan before you begin working out. Or a vacation rental app could make sure that the lights are on and the temperature is just right when a guest arrives. With the Home APIs, now anyone can bridge digital experiences and physical devices.
Sign Up to Build with the Home APIs
Do you have a great idea or feature that you'd like to build into your app with the Home APIs? Tell us about it and join the waitlist for access to the Home APIs or Home runtime. We will expand access on a rolling basis and the first apps built on the Home APIs will come to the Play Store and App Store starting this fall. Learn more about what’s included in the Home APIs from our I/O session on the Google Home Developer Center.


 Posted by Mike Taylor (Privacy Sandbox), and Mihai Cîrlănaru (Web on Android)
Posted by Mike Taylor (Privacy Sandbox), and Mihai Cîrlănaru (Web on Android)










 Posted by Maru Ahues Bouza – Director, Product Management, and Jeffrey van Gogh – Director, Engineering
Posted by Maru Ahues Bouza – Director, Product Management, and Jeffrey van Gogh – Director, Engineering



 Posted by Timothy Jordan – Director, Developer Relations and Open Source
Posted by Timothy Jordan – Director, Developer Relations and Open Source



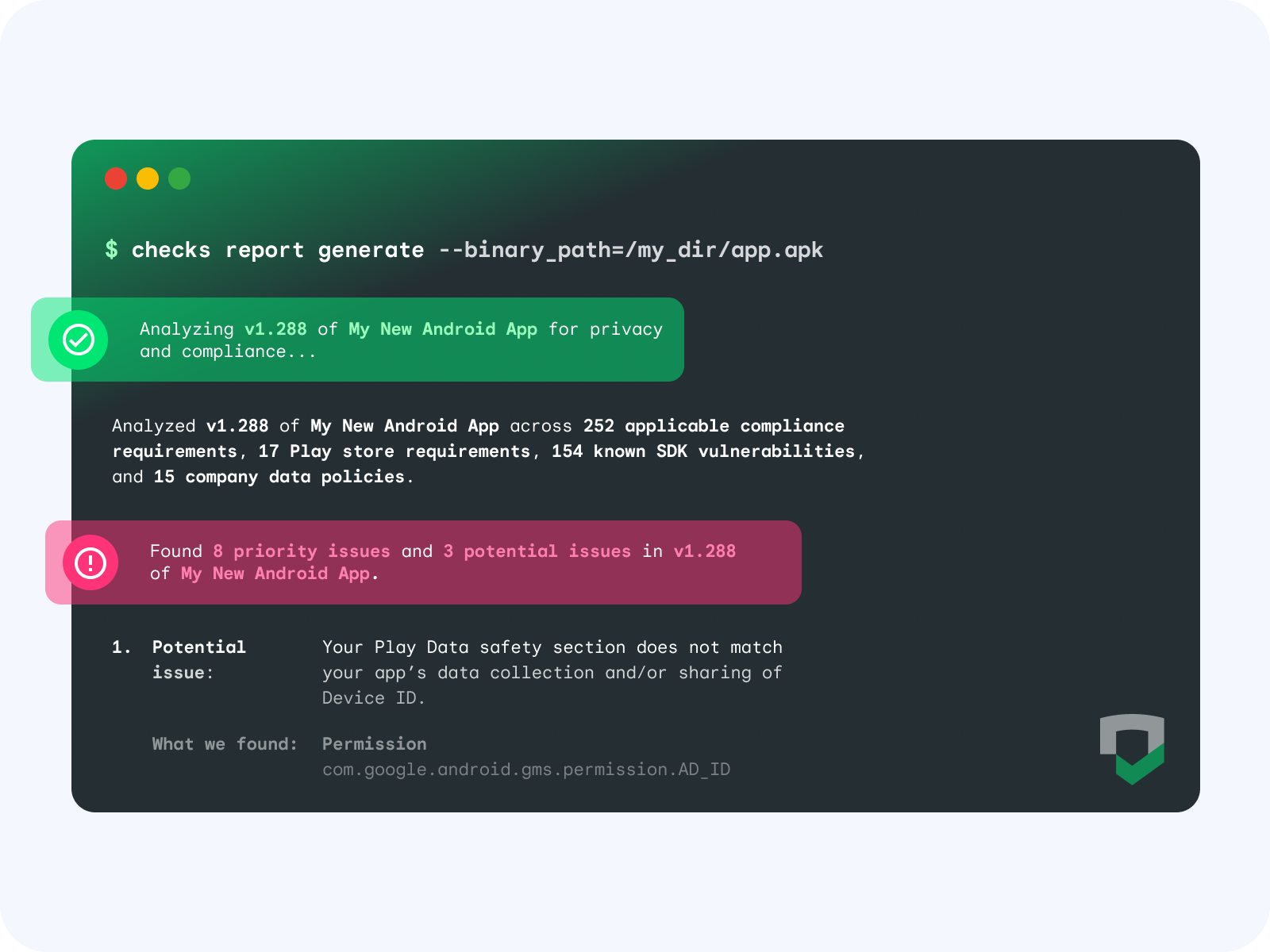
 Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks
Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks



 Posted by Joe Fernandez – Google AI Developer Relations
Posted by Joe Fernandez – Google AI Developer Relations
