Posted by Ankita Tripathi, Community Manager (Dev Library)


Witnessing a plethora of open-source enthusiasts in the developer ecosystem in recent years gave birth to the idea of Google’s Dev Library. The inception of the platform happened in June 2021 with the only objective of giving visibility to developers who have been creating and building projects relentlessly using Google technologies. But why the Dev Library?
Why Dev Library?
Open-source communities are currently at a boom. The past 3 years have seen a surge of folks constantly building in public, talking about open-source contributions, digging into opportunities, and carving out a valuable portfolio for themselves. The idea behind the Dev Library as a whole was also to capture these open-source projects and leverage them for the benefit of other developers.
This platform acted as a gold mine for projects created using Google technologies (Android, Angular, Flutter, Firebase, Machine Learning, Google Assistant, Google Cloud).
With the platform, we also catered to the burning issue – creating a central place for the huge number of projects and articles scattered across various platforms. Therefore, the Dev Library became a one-source platform for all the open source projects and articles for Google technologies.
How can you use the Dev Library?
“It is a library full of quality projects and articles.”
External developers cannot construe Dev Library as the first platform for blog posts or projects, but the vision is bigger than being a mere platform for the display of content. It envisages the growth of developers along with tech content creation. The uniqueness of the platform lies in the curation of its submissions. Unlike other platforms, you don’t get your submitted work on the site by just clicking ‘Submit’. Behind the scenes, Dev Library has internal Google engineers for each product area who:
- thoroughly assess each submission,
- check for relevancy, freshness, and quality,
- approve the ones that pass the check, and reject the others with a note.
It is a painstaking process, and Dev Library requires a 4-6 week turnaround time to complete the entire curation procedure and get your work on the site.
What we aim to do with the platform:
- Provide visibility: Developers create open-source projects and write articles on platforms to bring visibility to their work and attract more contributions. Dev Library’s intention is to continue to provide this amplification for the efforts and time spent by external contributors.
- Kickstart a beginner’s open-source contribution journey: The biggest challenge for a beginner to start applying their learnings to build Android or Flutter applications is ‘Where do I start my contributions from’? While we see an open-source placard unfurled everywhere, beginners still struggle to find their right place. With the Dev Library, you get a stack of quality projects hand-picked for you keeping the freshness of the tech and content quality intact. For example, Tomas Trajan, a Dev Library contributor created an Angular material starter project where they have ‘good first issues’ to start your contributions with.
- Recognition: Your selection of the content on the Dev Library acts as recognition to the tiring hours you’ve put in to build a running open-source project and explain it well. Dev Library also delivers hero content in their monthly newsletter, features top contributors, and is in the process to gamify the developer efforts. As an example, one of our contributors created a Weather application using Android and added a badge ‘Part of Dev Library’.

With your contributions at one place under the Author page, you can use it as a portfolio for your work while simultaneously increasing your chances to become the next Google Developer Expert (GDE).
Features on the platform
Keeping developers in mind, we’ve updated features on the platform as follows:
- Added a new product category; Google Assistant – All Google Assistant and Smart home projects now have a designated category on the Dev Library.
- Integrated a new way to make submissions across product areas via the Advocu form.
- Introduced a special section to submit Cloud Champion articles on Google Cloud.
- Included displays on each Author page indicating the expertise of individual contributors
- Upcoming: An expertise filter to help you segment out content based on Beginner, Intermediate, or Expert levels.
To submit your idea or suggestion, refer to this form, and put down your suggestions.
Contributor Love
Dev Library as a platform is more about the contributors who lie on the cusp of creation and consumption of the available content. Here are some contributors who have utilized the platform their way. Here's how the Dev Library has helped along their journey:
 Roaa Khaddam: Roaa is a Senior Flutter Mobile Developer and Co-Founder at MultiCaret Inc.
Roaa Khaddam: Roaa is a Senior Flutter Mobile Developer and Co-Founder at MultiCaret Inc.How has the Dev Library helped you?
“It gave me the opportunity to share what I created with an incredible community and look at the projects my fellow Flutter mates have created. It acts as a great learning resource.”

How has the Dev Library helped you?
“I used to discover new open source libraries and helpful articles for Android development in many places and it took me longer than necessary. But the Dev Library allows me to explore these useful resources in one place.”

How has the Dev Library helped you?
“Dev Library is a great tool to find excellent Angular articles or open source projects. Dev Library offers a great filtering function and therefore makes it much easier to find the right open source library for your use case.”
What started as a platform to highlight and showcase some open-source projects has grown into a product where developers can share their learnings, inspire others, and contribute to the ecosystem at large.
Do you have an Open Source learning or project in the form of a blog or GitHub repo you'd like to share? Please submit it to the Dev Library platform. We'd love to add you to our ever growing list of developer contributors!
Source: Google Developers Blog
Reproducibility in Deep Learning and Smooth Activations
Ever queried a recommender system and found that the same search only a few moments later or on a different device yields very different results? This is not uncommon and can be frustrating if a person is looking for something specific. As a designer of such a system, it is also not uncommon for the metrics measured to change from design and testing to deployment, bringing into question the utility of the experimental testing phase. Some level of such irreproducibility can be expected as the world changes and new models are deployed. However, this also happens regularly as requests hit duplicates of the same model or models are being refreshed.
Lack of replicability, where researchers are unable to reproduce published results with a given model, has been identified as a challenge in the field of machine learning (ML). Irreproducibility is a related but more elusive problem, where multiple instances of a given model are trained on the same data under identical training conditions, but yield different results. Only recently has irreproducibility been identified as a difficult problem, but due to its complexity, theoretical studies to understand this problem are extremely rare.
In practice, deep network models are trained in highly parallelized and distributed environments. Nondeterminism in training from random initialization, parallelism, distributed training, data shuffling, quantization errors, hardware types, and more, combined with objectives with multiple local optima contribute to the problem of irreproducibility. Some of these factors, such as initialization, can be controlled, but it is impractical to control others. Optimization trajectories can diverge early in training by following training examples in the order seen, leading to very different models. Several recently published solutions [1, 2, 3] based on advanced combinations of ensembling, self-ensembling, and distillation can mitigate the problem, but usually at the cost of accuracy and increased complexity, maintenance and improvement costs.
In “Real World Large Scale Recommendation Systems Reproducibility and Smooth Activations”, we consider a different practical solution to this problem that does not incur the costs of other solutions, while still improving reproducibility and yielding higher model accuracy. We discover that the Rectified Linear Unit (ReLU), which is very popular as the nonlinearity function (i.e., activation function) used to transform values in neural networks, exacerbates the irreproducibility problem. On the other hand, we demonstrate that smooth activation functions, which have derivatives that are continuous for the whole domain, unlike those of ReLU, are able to substantially reduce irreproducibility levels. We then propose the Smooth reLU (SmeLU) activation function, which gives comparable reproducibility and accuracy benefits to other smooth activations but is much simpler.
 |
| The ReLU function (left) as function of the input signal, and its gradient (right) as function of the input. |
Smooth Activations
An ML model attempts to learn the best model parameters that fit the training data by minimizing a loss, which can be imagined as a landscape with peaks and valleys, where the lowest point attains an optimal solution. For deep models, the landscape may consist of many such peaks and valleys. The activation function used by the model governs the shape of this landscape and how the model navigates it.
ReLU, which is not a smooth function, imposes an objective whose landscape is partitioned into many regions with multiple local minima, each providing different model predictions. With this landscape, the order in which updates are applied is a dominant factor in determining the optimization trajectory, providing a recipe for irreproducibility. Because of its non-continuous gradient, functions expressed by a ReLU network will contain sudden jumps in the gradient, which can occur internally in different layers of the deep network, affecting updates of different internal units, and are likely strong contributors to irreproducibility.
Suppose a sequence of model updates attempts to push the activation of some unit down from a positive value. The gradient of the ReLU function is 1 for positive unit values, so with every update it pushes the unit to become smaller and smaller (to the left in the panel above). At the point the activation of this unit crosses the threshold from a positive value to a negative one, the gradient suddenly changes from magnitude 1 to magnitude 0. Training attempts to keep moving the unit leftwards, but due to the 0 gradient, the unit cannot move further in that direction. Therefore, the model must resort to updating other units that can move.
We find that networks with smooth activations (e.g., GELU, Swish and Softplus) can be substantially more reproducible. They may exhibit a similar objective landscape, but with fewer regions, giving a model fewer opportunities to diverge. Unlike the sudden jumps with ReLU, for a unit with decreasing activations, the gradient gradually reduces to 0, which gives other units opportunities to adjust to the changing behavior. With equal initialization, moderate shuffling of training examples, and normalization of hidden layer outputs, smooth activations are able to increase the chances of converging to the same minimum. Very aggressive data shuffling, however, loses this advantage.
The rate that a smooth activation function transitions between output levels, i.e., its “smoothness”, can be adjusted. Sufficient smoothness leads to improved accuracy and reproducibility. Too much smoothness, though, approaches linear models with a corresponding degradation of model accuracy, thus losing the advantages of using a deep network.
 |
| Smooth activations (top) and their gradients (bottom) for different smoothness parameter values β as a function of the input values. β determines the width of the transition region between 0 and 1 gradients. For Swish and Softplus, a greater β gives a narrower region, for SmeLU, a greater β gives a wider region. |
Smooth reLU (SmeLU)
Activations like GELU and Swish require complex hardware implementations to support exponential and logarithmic functions. Further, GELU must be computed numerically or approximated. These properties can make deployment error-prone, expensive, or slow. GELU and Swish are not monotonic (they start by slightly decreasing and then switch to increasing), which may interfere with interpretability (or identifiability), nor do they have a full stop or a clean slope 1 region, properties that simplify implementation and may aid in reproducibility.
The Smooth reLU (SmeLU) activation function is designed as a simple function that addresses the concerns with other smooth activations. It connects a 0 slope on the left with a slope 1 line on the right through a quadratic middle region, constraining continuous gradients at the connection points (as an asymmetric version of a Huber loss function).
SmeLU can be viewed as a convolution of ReLU with a box. It provides a cheap and simple smooth solution that is comparable in reproducibility-accuracy tradeoffs to more computationally expensive and complex smooth activations. The figure below illustrates the transition of the loss (objective) surface as we gradually transition from a non-smooth ReLU to a smoother SmeLU. A transition of width 0 is the basic ReLU function for which the loss objective has many local minima. As the transition region widens (SmeLU), the loss surface becomes smoother. If the transition is too wide, i.e., too smooth, the benefit of using a deep network wanes and we approach the linear model solution — the objective surface flattens, potentially losing the ability of the network to express much information.
 |
| Loss surfaces (as functions of a 2D input) for two sample loss functions (middle and right) as the activation function’s transition region widens, going from from ReLU to an increasingly smoother SmeLU (left). The loss surface becomes smoother with increasing the smoothness of the SmeLU function. |
Performance
SmeLU has benefited multiple systems, specifically recommendation systems, increasing their reproducibility by reducing, for example, recommendation swap rates. While the use of SmeLU results in accuracy improvements over ReLU, it also replaces other costly methods to address irreproducibility, such as ensembles, which mitigate irreproducibility at the cost of accuracy. Moreover, replacing ensembles in sparse recommendation systems reduces the need for multiple lookups of model parameters that are needed to generate an inference for each of the ensemble components. This substantially improves training and inference efficiency.
To illustrate the benefits of smooth activations, we plot the relative prediction difference (PD) as a function of change in some loss for the different activations. We define relative PD as the ratio between the absolute difference in predictions of two models and their expected prediction, averaged over all evaluation examples. We have observed that in large scale systems, it is sufficient, and inexpensive, to consider only two models for very consistent results.
The figure below shows curves on the PD-accuracy loss plane. For reproducibility, being lower on the curve is better, and for accuracy, being on the left is better. Smooth activations can yield a ballpark 50% reduction in PD relative to ReLU, while still potentially resulting in improved accuracy. SmeLU yields accuracy comparable to other smooth activations, but is more reproducible (lower PD) while still outperforming ReLU in accuracy.
 |
| Relative PD as a function of percentage change in the evaluation ranking loss, which measures how accurately items are ranked in a recommendation system (higher values indicate worse accuracy), for different activations. |
Conclusion and Future Work
We demonstrated the problem of irreproducibility in real world practical systems, and how it affects users as well as system and model designers. While this particular issue has been given very little attention when trying to address the lack of replicability of research results, irreproducibility can be a critical problem. We demonstrated that a simple solution of using smooth activations can substantially reduce the problem without degrading other critical metrics like model accuracy. We demonstrate a new smooth activation function, SmeLU, which has the added benefits of mathematical simplicity and ease of implementation, and can be cheap and less error prone.
Understanding reproducibility, especially in deep networks, where objectives are not convex, is an open problem. An initial theoretical framework for the simpler convex case has recently been proposed, but more research must be done to gain a better understanding of this problem which will apply to practical systems that rely on deep networks.
Acknowledgements
We would like to thank Sergey Ioffe for early discussions about SmeLU; Lorenzo Coviello and Angel Yu for help in early adoptions of SmeLU; Shiv Venkataraman for sponsorship of the work; Claire Cui for discussion and support from the very beginning; Jeremiah Willcock, Tom Jablin, and Cliff Young for substantial implementation support; Yuyan Wang, Mahesh Sathiamoorthy, Myles Sussman, Li Wei, Kevin Regan, Steven Okamoto, Qiqi Yan, Todd Phillips, Ed Chi, Sunita Verna, and many many others for many discussions, and for integrations in many different systems; Matt Streeter and Yonghui Wu for feedback on the paper and this post; Tom Small for help with the illustrations in this post.

Source: Google AI Blog
Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
In recent years, large neural networks trained for language understanding and generation have achieved impressive results across a wide range of tasks. GPT-3 first showed that large language models (LLMs) can be used for few-shot learning and can achieve impressive results without large-scale task-specific data collection or model parameter updating. More recent LLMs, such as GLaM, LaMDA, Gopher, and Megatron-Turing NLG, achieved state-of-the-art few-shot results on many tasks by scaling model size, using sparsely activated modules, and training on larger datasets from more diverse sources. Yet much work remains in understanding the capabilities that emerge with few-shot learning as we push the limits of model scale.
Last year Google Research announced our vision for Pathways, a single model that could generalize across domains and tasks while being highly efficient. An important milestone toward realizing this vision was to develop the new Pathways system to orchestrate distributed computation for accelerators. In “PaLM: Scaling Language Modeling with Pathways”, we introduce the Pathways Language Model (PaLM), a 540-billion parameter, dense decoder-only Transformer model trained with the Pathways system, which enabled us to efficiently train a single model across multiple TPU v4 Pods. We evaluated PaLM on hundreds of language understanding and generation tasks, and found that it achieves state-of-the-art few-shot performance across most tasks, by significant margins in many cases.
 |
| As the scale of the model increases, the performance improves across tasks while also unlocking new capabilities. |
Training a 540-Billion Parameter Language Model with Pathways
PaLM demonstrates the first large-scale use of the Pathways system to scale training to 6144 chips, the largest TPU-based system configuration used for training to date. The training is scaled using data parallelism at the Pod level across two Cloud TPU v4 Pods, while using standard data and model parallelism within each Pod. This is a significant increase in scale compared to most previous LLMs, which were either trained on a single TPU v3 Pod (e.g., GLaM, LaMDA), used pipeline parallelism to scale to 2240 A100 GPUs across GPU clusters (Megatron-Turing NLG) or used multiple TPU v3 Pods (Gopher) with a maximum scale of 4096 TPU v3 chips.
PaLM achieves a training efficiency of 57.8% hardware FLOPs utilization, the highest yet achieved for LLMs at this scale. This is due to a combination of the parallelism strategy and a reformulation of the Transformer block that allows for attention and feedforward layers to be computed in parallel, enabling speedups from TPU compiler optimizations.
PaLM was trained using a combination of English and multilingual datasets that include high-quality web documents, books, Wikipedia, conversations, and GitHub code. We also created a “lossless” vocabulary that preserves all whitespace (especially important for code), splits out-of-vocabulary Unicode characters into bytes, and splits numbers into individual tokens, one for each digit.
Breakthrough Capabilities on Language, Reasoning, and Code Tasks
PaLM shows breakthrough capabilities on numerous very difficult tasks. We highlight a few examples for language understanding and generation, reasoning, and code-related tasks below.
Language Understanding and Generation
We evaluated PaLM on 29 widely-used English natural language processing (NLP) tasks. PaLM 540B surpassed few-shot performance of prior large models, such as GLaM, GPT-3, Megatron-Turing NLG, Gopher, Chinchilla, and LaMDA, on 28 of 29 of tasks that span question-answering tasks (open-domain closed-book variant), cloze and sentence-completion tasks, Winograd-style tasks, in-context reading comprehension tasks, common-sense reasoning tasks, SuperGLUE tasks, and natural language inference tasks.
 |
| PaLM 540B performance improvement over prior state-of-the-art (SOTA) results on 29 English-based NLP tasks. |
In addition to English NLP tasks, PaLM also shows strong performance on multilingual NLP benchmarks, including translation, even though only 22% of the training corpus is non-English.
We also probe emerging and future capabilities of PaLM on the Beyond the Imitation Game Benchmark (BIG-bench), a recently released suite of more than 150 new language modeling tasks, and find that PaLM achieves breakthrough performance. We compare the performance of PaLM to Gopher and Chinchilla, averaged across a common subset of 58 of these tasks. Interestingly, we note that PaLM’s performance as a function of scale follows a log-linear behavior similar to prior models, suggesting that performance improvements from scale have not yet plateaued. PaLM 540B 5-shot also does better than the average performance of people asked to solve the same tasks.
 |
| Scaling behavior of PaLM on a subset of 58 BIG-bench tasks. |
PaLM demonstrates impressive natural language understanding and generation capabilities on several BIG-bench tasks. For example, the model can distinguish cause and effect, understand conceptual combinations in appropriate contexts, and even guess the movie from an emoji.
 |
| Examples that showcase PaLM 540B 1-shot performance on BIG-bench tasks: labeling cause and effect, conceptual understanding, guessing movies from emoji, and finding synonyms and counterfactuals. |
Reasoning
By combining model scale with chain-of-thought prompting, PaLM shows breakthrough capabilities on reasoning tasks that require multi-step arithmetic or common-sense reasoning. Prior LLMs, like Gopher, saw less benefit from model scale in improving performance.
 |
| Standard prompting versus chain-of-thought prompting for an example grade-school math problem. Chain-of-thought prompting decomposes the prompt for a multi-step reasoning problem into intermediate steps (highlighted in yellow), similar to how a person would approach it. |
We observed strong performance from PaLM 540B combined with chain-of-thought prompting on three arithmetic datasets and two commonsense reasoning datasets. For example, with 8-shot prompting, PaLM solves 58% of the problems in GSM8K, a benchmark of thousands of challenging grade school level math questions, outperforming the prior top score of 55% achieved by fine-tuning the GPT-3 175B model with a training set of 7500 problems and combining it with an external calculator and verifier.
This new score is especially interesting, as it approaches the 60% average of problems solved by 9-12 year olds, who are the target audience for the question set. We suspect that separate encoding of digits in the PaLM vocabulary helps enable these performance improvements.
Remarkably, PaLM can even generate explicit explanations for scenarios that require a complex combination of multi-step logical inference, world knowledge, and deep language understanding. For example, it can provide high quality explanations for novel jokes not found on the web.
 |
| PaLM explains an original joke with two-shot prompts. |
Code Generation
LLMs have also been shown [1, 2, 3, 4] to generalize well to coding tasks, such as writing code given a natural language description (text-to-code), translating code from one language to another, and fixing compilation errors (code-to-code).
PaLM 540B shows strong performance across coding tasks and natural language tasks in a single model, even though it has only 5% code in the pre-training dataset. Its few-shot performance is especially remarkable because it is on par with the fine-tuned Codex 12B while using 50 times less Python code for training. This result reinforces earlier findings that larger models can be more sample efficient than smaller models because they better transfer learning from other programming languages and natural language data.
 |
| Examples of a fine-tuned PaLM 540B model on text-to-code tasks, such as GSM8K-Python and HumanEval, and code-to-code tasks, such as Transcoder. |
We also see a further increase in performance by fine-tuning PaLM on a Python-only code dataset, which we refer to as PaLM-Coder. For an example code repair task called DeepFix, where the objective is to modify initially broken C programs until they compile successfully, PaLM-Coder 540B demonstrates impressive performance, achieving a compile rate of 82.1%, which outperforms the prior 71.7% state of the art. This opens up opportunities for fixing more complex errors that arise during software development.
 |
| An example from the DeepFix Code Repair task. The fine-tuned PaLM-Coder 540B fixes compilation errors (left, in red) to a version of code that compiles (right). |
Ethical Considerations
Recent research has highlighted various potential risks associated with LLMs trained on web text. It is crucial to analyze and document such potential undesirable risks through transparent artifacts such as model cards and datasheets, which also include information on intended use and testing. To this end, our paper provides a datasheet, model card and Responsible AI benchmark results, and it reports thorough analyses of the dataset and model outputs for biases and risks. While the analysis helps outline some potential risks of the model, domain- and task-specific analysis is essential to truly calibrate, contextualize, and mitigate possible harms. Further understanding of risks and benefits of these models is a topic of ongoing research, together with developing scalable solutions that can put guardrails against malicious uses of language models.
Conclusion and Future Work
PaLM demonstrates the scaling capability of the Pathways system to thousands of accelerator chips across two TPU v4 Pods by training a 540-billion parameter model efficiently with a well-studied, well-established recipe of a dense decoder-only Transformer model. Pushing the limits of model scale enables breakthrough few-shot performance of PaLM across a variety of natural language processing, reasoning, and code tasks.
PaLM paves the way for even more capable models by combining the scaling capabilities with novel architectural choices and training schemes, and brings us closer to the Pathways vision:
| “Enable a single AI system to generalize across thousands or millions of tasks, to understand different types of data, and to do so with remarkable efficiency." |
Acknowledgements
PaLM is the result of a large, collaborative effort by many teams within Google Research and across Alphabet. We’d like to thank the entire PaLM team for their contributions: Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, and Jason Wei. PaLM builds on top of work by many, many teams at Google and we would especially like to recognize the T5X team, the Pathways infrastructure team, the JAX team, the Flaxformer team, the XLA team, the Plaque team, the Borg team, and the Datacenter networking infrastructure team. We’d like to thank our co-authors on this blog post, Alexander Spiridonov and Maysam Moussalem, as well as Josh Newlan and Tom Small for the images and animations in this blog post. Finally, we would like to thank our advisors for the project: Noah Fiedel, Slav Petrov, Jeff Dean, Douglas Eck, and Kathy Meier-Hellstern.
Source: Google AI Blog
Auto-generated Summaries in Google Docs
For many of us, it can be challenging to keep up with the volume of documents that arrive in our inboxes every day: reports, reviews, briefs, policies and the list goes on. When a new document is received, readers often wish it included a brief summary of the main points in order to effectively prioritize it. However, composing a document summary can be cognitively challenging and time-consuming, especially when a document writer is starting from scratch.
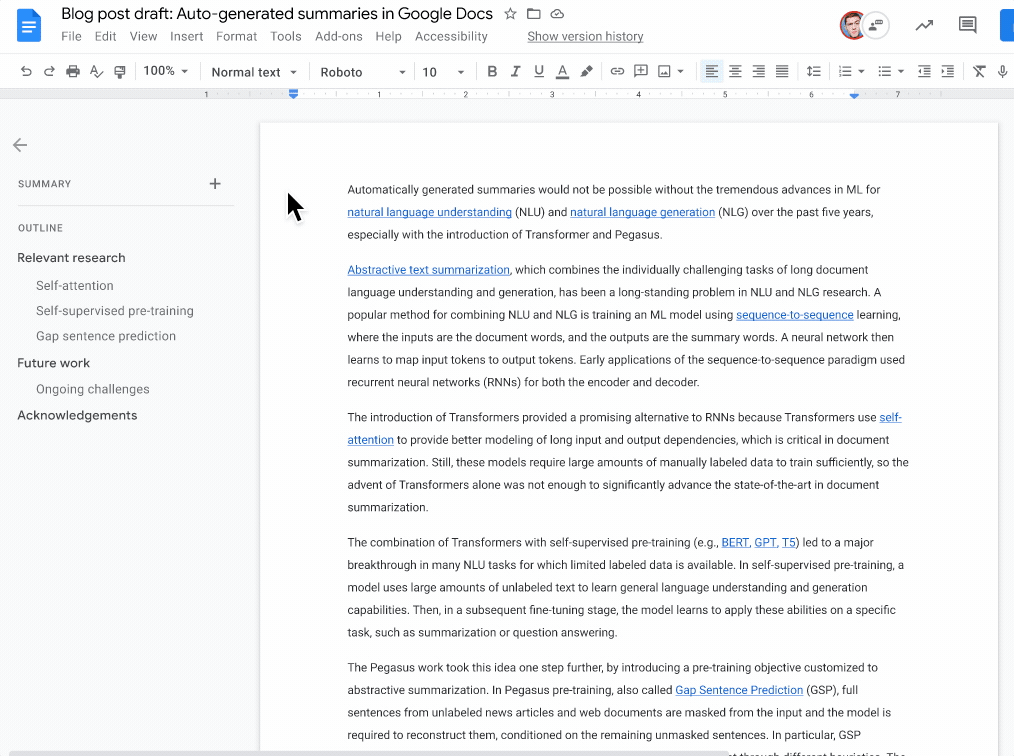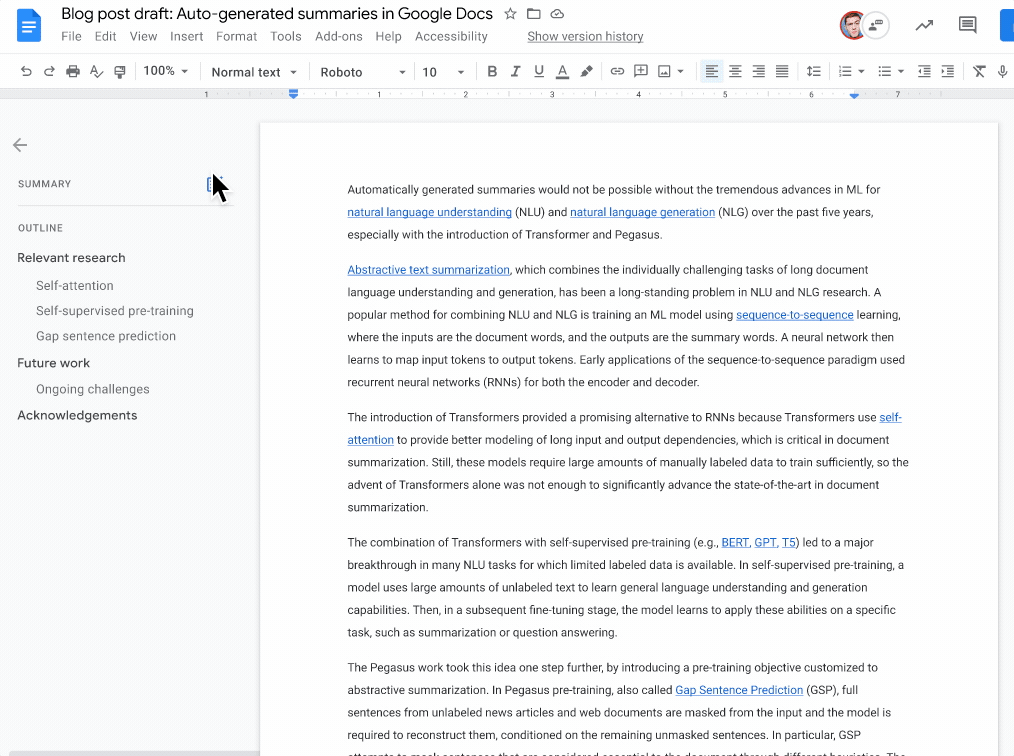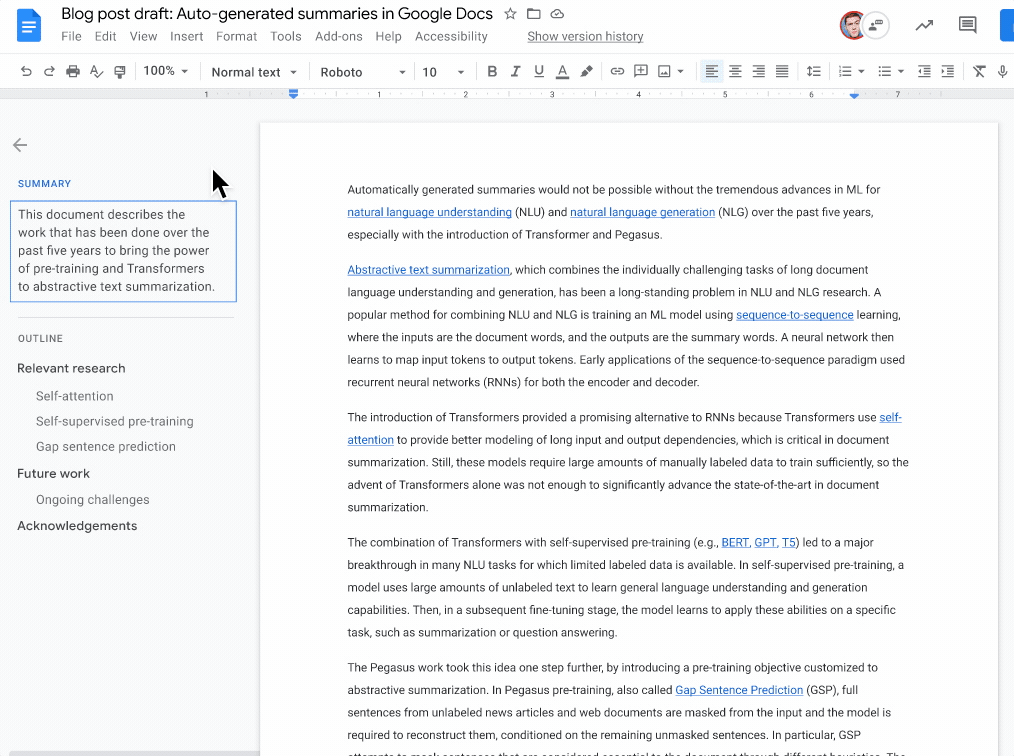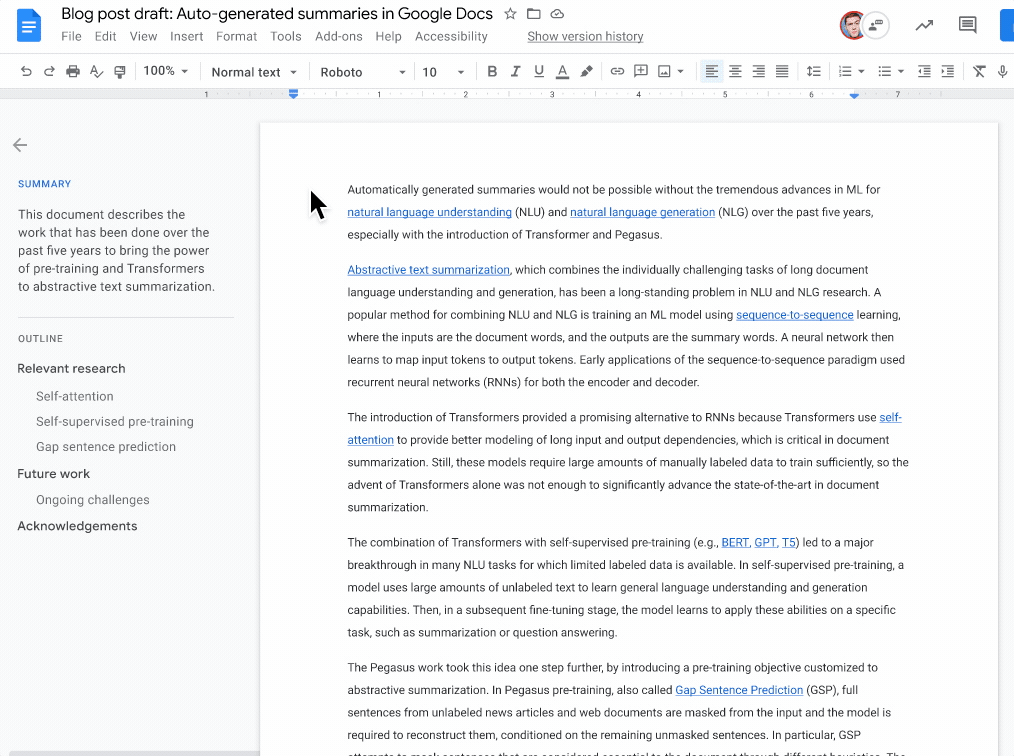
To help with this, we recently announced that Google Docs now automatically generates suggestions to aid document writers in creating content summaries, when they are available. Today we describe how this was enabled using a machine learning (ML) model that comprehends document text and, when confident, generates a 1-2 sentence natural language description of the document content. However, the document writer maintains full control — accepting the suggestion as-is, making necessary edits to better capture the document summary or ignoring the suggestion altogether. Readers can also use this section, along with the outline, to understand and navigate the document at a high level. While all users can add summaries, auto-generated suggestions are currently only available to Google Workspace business customers. Building on grammar suggestions, Smart Compose, and autocorrect, we see this as another valuable step toward improving written communication in the workplace.
 |
| A blue summary icon appears in the top left corner when a document summary suggestion is available. Document writers can then view, edit, or ignore the suggested document summary. |
Model Details
Automatically generated summaries would not be possible without the tremendous advances in ML for natural language understanding (NLU) and natural language generation (NLG) over the past five years, especially with the introduction of Transformer and Pegasus.
Abstractive text summarization, which combines the individually challenging tasks of long document language understanding and generation, has been a long-standing problem in NLU and NLG research. A popular method for combining NLU and NLG is training an ML model using sequence-to-sequence learning, where the inputs are the document words, and the outputs are the summary words. A neural network then learns to map input tokens to output tokens. Early applications of the sequence-to-sequence paradigm used recurrent neural networks (RNNs) for both the encoder and decoder.
The introduction of Transformers provided a promising alternative to RNNs because Transformers use self-attention to provide better modeling of long input and output dependencies, which is critical in document summarization. Still, these models require large amounts of manually labeled data to train sufficiently, so the advent of Transformers alone was not enough to significantly advance the state-of-the-art in document summarization.
The combination of Transformers with self-supervised pre-training (e.g., BERT, GPT, T5) led to a major breakthrough in many NLU tasks for which limited labeled data is available. In self-supervised pre-training, a model uses large amounts of unlabeled text to learn general language understanding and generation capabilities. Then, in a subsequent fine-tuning stage, the model learns to apply these abilities on a specific task, such as summarization or question answering.
The Pegasus work took this idea one step further, by introducing a pre-training objective customized to abstractive summarization. In Pegasus pre-training, also called Gap Sentence Prediction (GSP), full sentences from unlabeled news articles and web documents are masked from the input and the model is required to reconstruct them, conditioned on the remaining unmasked sentences. In particular, GSP attempts to mask sentences that are considered essential to the document through different heuristics. The intuition is to make the pre-training as close as possible to the summarization task. Pegasus achieved state-of-the-art results on a varied set of summarization datasets. However, a number of challenges remained to apply this research advancement into a product.
Applying Recent Research Advances to Google Docs
- Data
Self-supervised pre-training results in an ML model that has general language understanding and generation capabilities, but a subsequent fine-tuning stage is critical for the model to adapt to the application domain. We fine-tuned early versions of our model on a corpus of documents with manually-generated summaries that were consistent with typical use cases.
However, early versions of this corpus suffered from inconsistencies and high variation because they included many types of documents, as well as many ways to write a summary — e.g., academic abstracts are typically long and detailed, while executive summaries are brief and punchy. This led to a model that was easily confused because it had been trained on so many different types of documents and summaries that it struggled to learn the relationships between any of them.
Fortunately, one of the key findings in the Pegasus work was that an effective pre-training phase required less supervised data in the fine-tuning stage. Some summarization benchmarks required as few as 1,000 fine-tuning examples for Pegasus to match the performance of Transformer baselines that saw 10,000+ supervised examples — suggesting that one could focus on quality rather than quantity.
We carefully cleaned and filtered the fine-tuning data to contain training examples that were more consistent and represented a coherent definition of summaries. Despite the fact that we reduced the amount of training data, this led to a higher quality model. The key lesson, consistent with recent work in domains like dataset distillation, was that it was better to have a smaller, high quality dataset, than a larger, high-variance dataset.


- Serving
Once we trained the high quality model, we turned to the challenge of serving the model in production. While the Transformer version of the encoder-decoder architecture is the dominant approach to train models for sequence-to-sequence tasks like abstractive summarization, it can be inefficient and impractical to serve in real-world applications. The main inefficiency comes from the Transformer decoder where we generate the output summary token by token through autoregressive decoding. The decoding process becomes noticeably slow when summaries get longer since the decoder attends to all previously generated tokens at each step. RNNs are a more efficient architecture for decoding since there is no self-attention with previous tokens as in a Transformer model.
We used knowledge distillation, which is the process of transferring knowledge from a large model to a smaller more efficient model, to distill the Pegasus model into a hybrid architecture of a Transformer encoder and an RNN decoder. To improve efficiency we also reduced the number of RNN decoder layers. The resulting model had significant improvements in latency and memory footprint while the quality was still on par with the original model. To further improve the latency and user experience, we serve the summarization model using TPUs, which provide significant speed ups and allow more requests to be handled by a single machine.
Ongoing Challenges and Next Steps
While we are excited by the progress so far, there are a few challenges we are continuing to tackle:
- Document coverage: Developing a set of documents for the fine-tuning stage was difficult due to the tremendous variety that exists among documents, and the same challenge is true at inference time. Some of the documents our users create (e.g., meeting notes, recipes, lesson plans and resumes) are not suitable for summarization or can be difficult to summarize. Currently, our model only suggests a summary for documents where it is most confident, but we hope to continue broadening this set as our model improves.
- Evaluation: Abstractive summaries need to capture the essence of a document while being fluent and grammatically correct. A specific document may have many summaries that can be considered correct, and different readers may prefer different ones. This makes it hard to evaluate summaries with automatic metrics only, user feedback and usage statistics will be critical for us to understand and keep improving quality.
- Long documents: Long documents are some of the toughest documents for the model to summarize because it is harder to capture all the points and abstract them in a single summary, and it can also significantly increase memory usage during training and serving. However, long documents are perhaps most useful for the model to automatically summarize because it can help document writers get a head start on this tedious task. We hope we can apply the latest ML advancements to better address this challenge.
Conclusion
Overall, we are thrilled that we can apply recent progress in NLU and NLG to continue assisting users with reading and writing. We hope the automatic suggestions now offered in Google Workspace make it easier for writers to annotate their documents with summaries, and help readers comprehend and navigate documents more easily.
Acknowledgements
The authors would like to thank the many people across Google that contributed to this work: AJ Motika, Matt Pearson-Beck, Mia Chen, Mahdis Mahdieh, Halit Erdogan, Benjamin Lee, Ali Abdelhadi, Michelle Danoff, Vishnu Sivaji, Sneha Keshav, Aliya Baptista, Karishma Damani, DJ Lick, Yao Zhao, Peter Liu, Aurko Roy, Yonghui Wu, Shubhi Sareen, Andrew Dai, Mekhola Mukherjee, Yinan Wang, Mike Colagrosso, and Behnoosh Hariri. .
Source: Google AI Blog
Stepping up as a Machine Learning Developer —My Experience With the Google Machine Learning Bootcamp
Posted by Hyunkil Kim, Software Quality Engineer at Line Corp.
This article is written by Hyunkil Kim who participated in the Machine Learning Bootcamp which is a machine learning training program conducted in Korea to nurture next-generation ML engineers and help them to find jobs.

As a developer, I had developed a certain level of curiosity about machine learning. I had also heard that many former developers were switching their specialization over to machine learning. Thus, I signed up for the <Google Machine Learning Bootcamp>, thinking it would be a good chance to get my feet wet.
I was a bit nervous and excited at the same time after getting the acceptance notification. Wondering if I should go over my Python skills one more time in preparation, I installed the newest version of TensorFlow on my machine. I also skimmed through documents on the basics of machine learning. Those were all unnecessary. To put it bluntly, I had to relearn everything from scratch over the course of the bootcamp. It was quite challenging to be introduced to new concepts I wasn't familiar with, such as functional API and the concept of functional programming in general, various visualization libraries, and data processing frameworks and services that were new to me. I worked very hard with the mindset of starting fresh.
Journey to Becoming a Machine Learning Engineer
There were three main objectives for the participants: completing the Deep Learning Specialization on Coursera which is based on TensorFlow, acquiring ML certifications(TensorFlow certificate or Google Cloud ML(or Data Science) Engineer certification), and participating in Kaggle competitions. Google Developers team provided the course fee for Coursera and the certification fee and offered many benefits to those who completed the course. You could really make it worth your while as long as you took the initiative and applied your passion.
<Coursera Deep Learning Specialization>
The Coursera class is based on TensorFlow 2.x and requires watching a set amount of instructor Andrew Ng's lectures on AI every week with screenshots and proof. It was pretty tough at first as the lectures were not in Korean. However, because the class was so famous, I was able to find posts on the internet that broke down the lectures and made them easier to understand. The class also provided reference links, so you could study more on your own once you got used to the class.
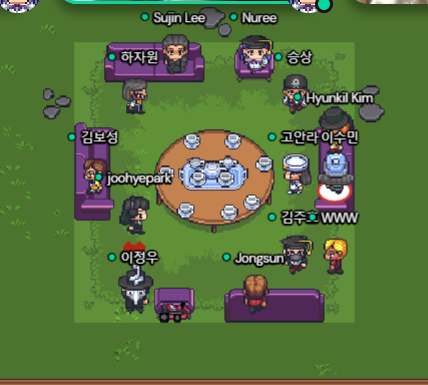
While this is not really related to the Coursera class, I also participated in online coding meetups by the bootcamp participants in-between classes as in the picture below, and it was a memorable experience. These are basically sessions held in coffee shops or study rooms where people got together and worked individually on their own coding projects in normal times. Because of the pandemic, we could not meet in person obviously and used Google Meet or Gather town and left our cameras on as we coded. It felt like I was studying with other people, and I liked the solidarity of relating to others.
<Machine Learning Certifications>
You were required to acquire at least one certification during the bootcamp. I chose to work on the GCP ML Engineer certification. As I used Google Cloud, I had wondered how ML services could be used on cloud. Coursera happened to have a specialization program for the GCP ML certification, so I took it, too. However, in the end, Google's website offering GCP AI operations and use cases helped me more with the certification than the course on Coursera.

<Kaggle Competition>
I didn't get to spend as much time on Kaggle. I didn't see any current projects that interested me, so I tried the TPS to review what I had learned so far. TPS stands for Tabular Playground Series, which is a beginner-to-intermediate level competition for new-ish Kagglers that are just getting the hang of it. You're required to predict the value of the target from the provided tabular data. It is slightly more difficult than Titanic Survival Predictions, which is a beginner competition. I chose this competition because I figured it would be a good practice of things I had learned so far, like data analysis, feature engineering, and hyperparameter tuning.
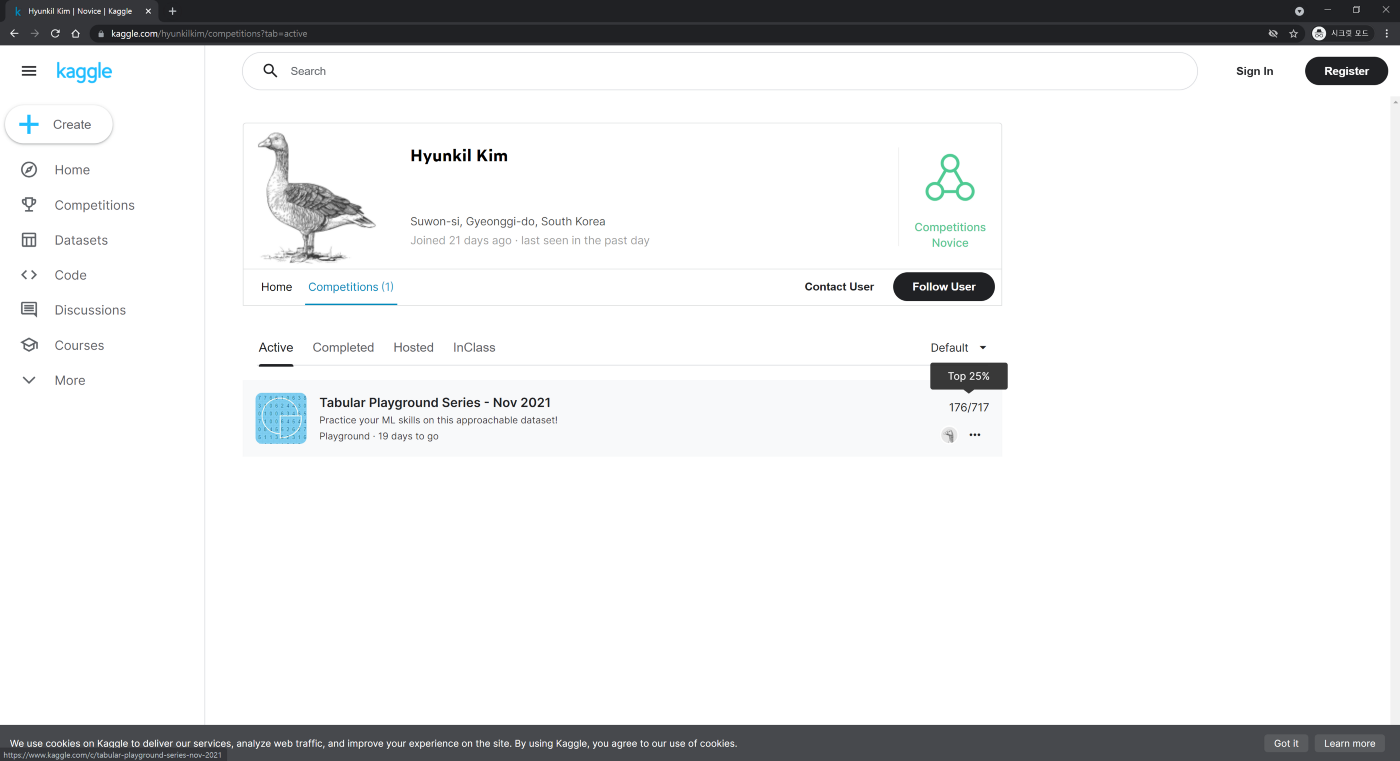
This was the part where I personally felt like I could have done better. I had many ideas for improving the model or enhancing the performance, but it took way more time to apply and experiment with them than I had expected. If I had known that model learning would take this much time, I would have started working on Coursera, the certification, and the Kaggle competition all at once from the beginning. Maybe I was too nervous about entering a Kaggle competition and put it off until the end. I should have just tried without getting so nervous. I hesitated too long and ended up regretting it a little too late.
<Tech Talk and Career Talk>
The bootcamp also included many other activities, including a weekly Tech Talk on specific themes and recruiting sessions of potential employers. Companies looking for ML talents were invited and had a chance to introduce themselves, explain the available positions, and take questions about joining their workforce. Some companies sent their current Machine Learning engineers to explain how they solved business problems with which models or what kind of data. Some companies focused more on describing the type of people they were looking for in detail. I didn't know at the time, but I heard that some of the speakers were big names in the industry. Personally, I found these talks very helpful in terms of both finding employment and familiarizing myself with the trends in the industry. The sessions were very inspiring as new ideas kept flowing as I heard about applications of technologies I only knew in theory or thought about what kind of investments in AI would be promising.
Besides the Tech Talks, there were also more relaxed sessions for things like career consultation and resume/CV reviews. There were even sessions by the Googlers, where they personally answered participants' questions and offered some advice. As I attended various sessions, I noticed that the bootcamp crew and many Tech Talk speakers from hiring companies offered authentic and valuable advice and were very eager to help out the bootcamp participants. Nobody talked about the cold reality of the world out there. Knowing how rare it is to find mentors that offer genuinely constructive feedback and guidance, I personally was very touched and grateful about that.
Concluding the Machine Learning Bootcamp.
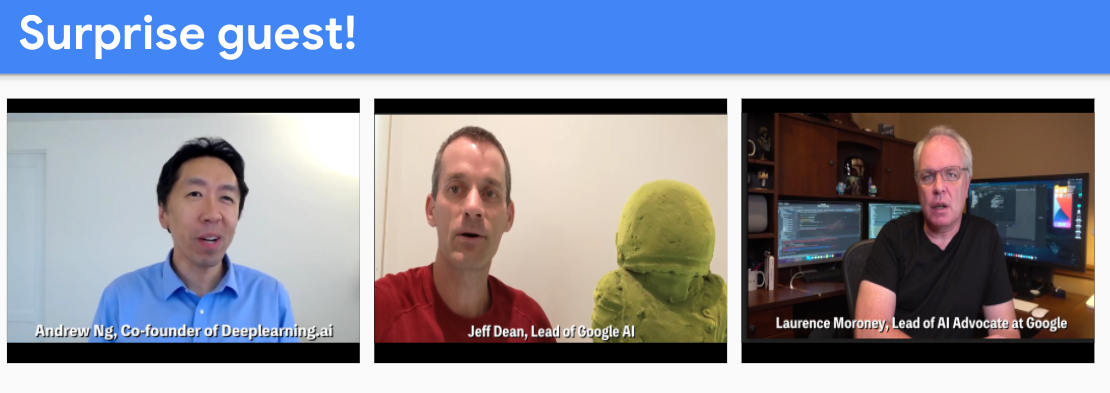
The Google Machine Learning Bootcamp captured the essence of what it would be like to work for Google. I felt like they expected you to take your own initiative to do what you wanted. They showed that they were willing and able to help you grow as much as possible as long as you did your best. For example, one of the world's most famous programmers Jeff Dean was at the kickoff session, and there was even an AMA session with Laurence Moroney, who had developed the training course for TensorFlow. They also allowed maximum freedom about finding teammates for the Kaggle competitions so that you didn't have to worry about having to carry your team. Things covered in the Tech Talks or recruitment sessions were not included in assignments. They let the participants do their thing freely while promising the best support possible in the industry if needed. I could see how some people would find it too lax that Google lets you study on your own at your own pace.
I think this was a rare chance to meet people from various backgrounds with the common goal of becoming machine learning engineers or developers. It was a unique experience where I got to talk and study with good people and even do something strange like the online coding meetup. There were also times when I was vainly taking pride in what little knowledge I had, but I ended up putting a lot of work into the bootcamp, wanting to make the most of it and to come ahead of others.
In the end, the take-home message is to "try anything."
Personally, I was very happy with the experience. I got to be a little more comfortable with machine learning. As a result, I'm able to pay more attention to details related to machine learning at my new job. The challenge of facing something new is a constant of a developer's life. Still, participating in this bootcamp felt especially meaningful to me, and I enjoyed it thoroughly.
While the bootcamp is over, I heard that some participants are still continuing with their study groups or projects. Wanting to study as a group myself, I also had asked around and volunteered to join a study group, but I ended up studying alone because none of the groups covered the area I was interested in. Even so, many people sharing useful information on Slack helped me as I studied alone, and they are still helping me even after the bootcamp.
At any rate, I keep coming up with various ideas that I want to try in my current job or as a personal project. It feels like I found a new toy that I can have fun with for a while without getting tired of it. I think I'll start slowly with a small toy project.
Source: Google Developers Blog
Offline Optimization for Architecting Hardware Accelerators
Advances in machine learning (ML) often come with advances in hardware and computing systems. For example, the growth of ML-based approaches in solving various problems in vision and language has led to the development of application-specific hardware accelerators (e.g., Google TPUs and Edge TPUs). While promising, standard procedures for designing accelerators customized towards a target application require manual effort to devise a reasonably accurate simulator of hardware, followed by performing many time-intensive simulations to optimize the desired objective (e.g., optimizing for low power usage or latency when running a particular application). This involves identifying the right balance between total amount of compute and memory resources and communication bandwidth under various design constraints, such as the requirement to meet an upper bound on chip area usage and peak power. However, designing accelerators that meet these design constraints is often result in infeasible designs. To address these challenges, we ask: “Is it possible to train an expressive deep neural network model on large amounts of existing accelerator data and then use the learned model to architect future generations of specialized accelerators, eliminating the need for computationally expensive hardware simulations?”
In “Data-Driven Offline Optimization for Architecting Hardware Accelerators”, accepted at ICLR 2022, we introduce PRIME, an approach focused on architecting accelerators based on data-driven optimization that only utilizes existing logged data (e.g., data leftover from traditional accelerator design efforts), consisting of accelerator designs and their corresponding performance metrics (e.g., latency, power, etc) to architect hardware accelerators without any further hardware simulation. This alleviates the need to run time-consuming simulations and enables reuse of data from past experiments, even when the set of target applications changes (e.g., an ML model for vision, language, or other objective), and even for unseen but related applications to the training set, in a zero-shot fashion. PRIME can be trained on data from prior simulations, a database of actually fabricated accelerators, and also a database of infeasible or failed accelerator designs1. This approach for architecting accelerators — tailored towards both single- and multi-applications — improves performance upon state-of-the-art simulation-driven methods by about 1.2x-1.5x, while considerably reducing the required total simulation time by 93% and 99%, respectively. PRIME also architects effective accelerators for unseen applications in a zero-shot setting, outperforming simulation-based methods by 1.26x.
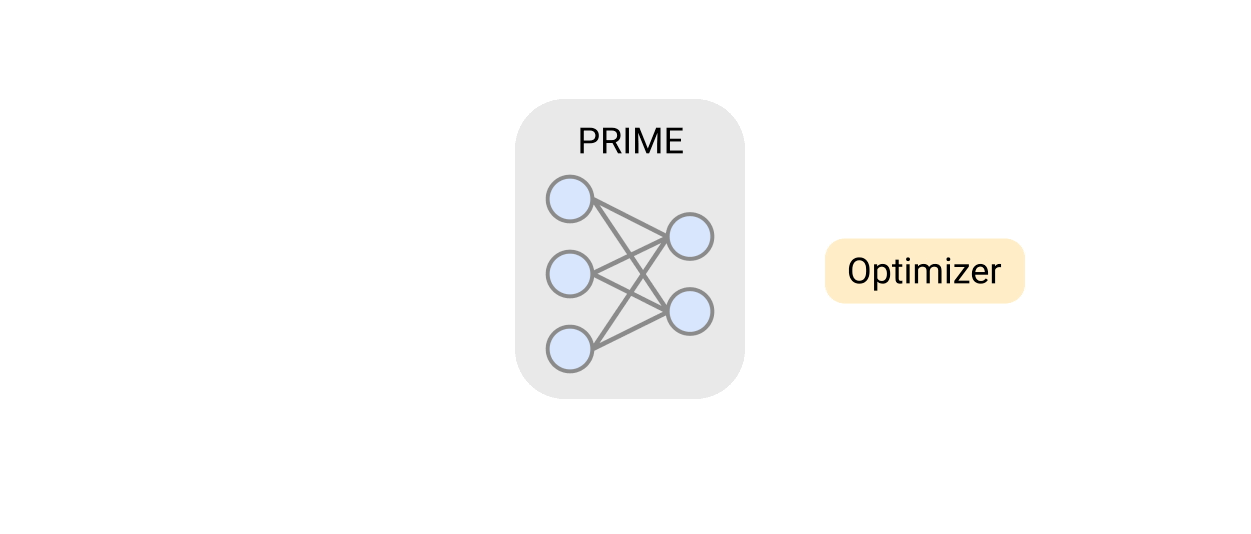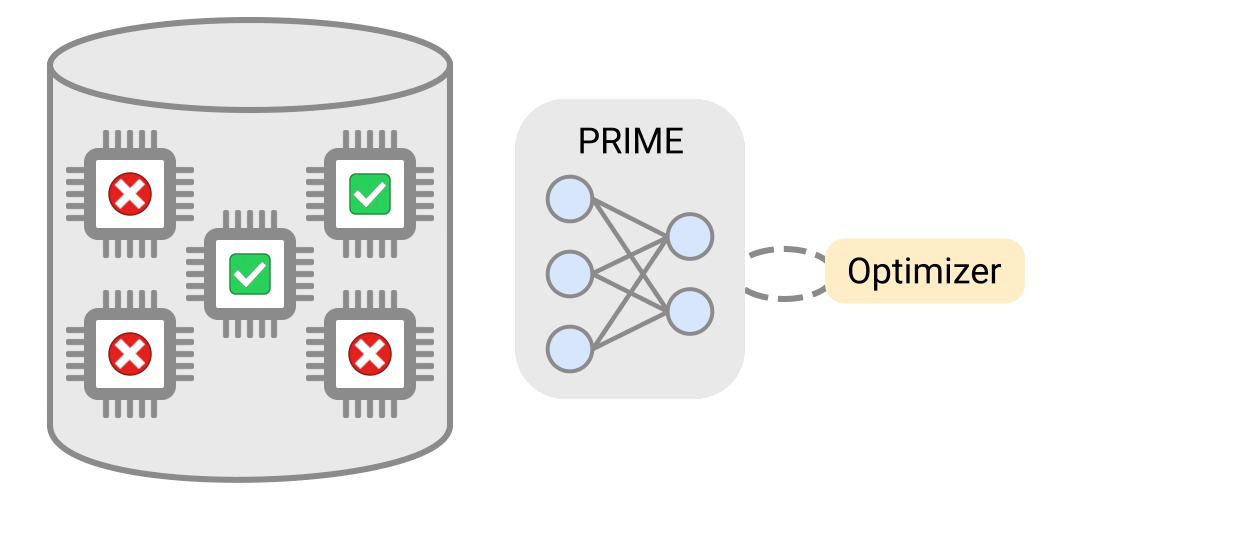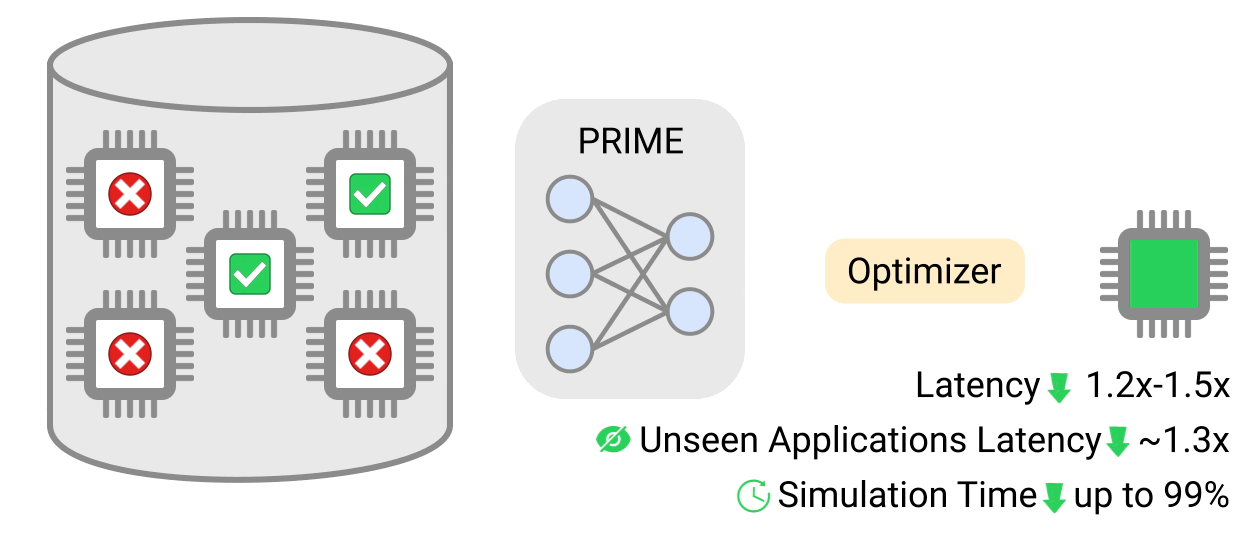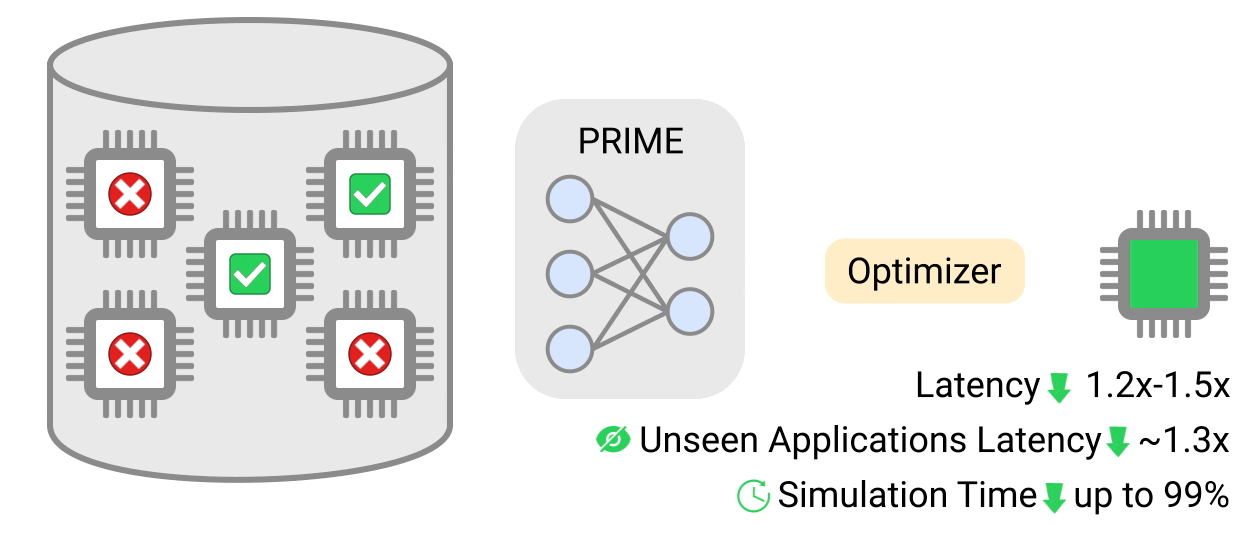 |
| PRIME uses logged accelerator data, consisting of both feasible and infeasible accelerators, to train a conservative model, which is used to design accelerators while meeting design constraints. PRIME architects accelerators with up to 1.5x smaller latency, while reducing the required hardware simulation time by up to 99%. |
The PRIME Approach for Architecting Accelerators
Perhaps the simplest possible way to use a database of previously designed accelerators for hardware design is to use supervised machine learning to train a prediction model that can predict the performance objective for a given accelerator as input. Then, one could potentially design new accelerators by optimizing the performance output of this learned model with respect to the input accelerator design. Such an approach is known as model-based optimization. However, this simple approach has a key limitation: it assumes that the prediction model can accurately predict the cost for every accelerator that we might encounter during optimization! It is well established that most prediction models trained via supervised learning misclassify adversarial examples that “fool” the learned model into predicting incorrect values. Similarly, it has been shown that even optimizing the output of a supervised model finds adversarial examples that look promising under the learned model2, but perform terribly under the ground truth objective.
To address this limitation, PRIME learns a robust prediction model that is not prone to being fooled by adversarial examples (that we will describe shortly), which would be otherwise found during optimization. One can then simply optimize this model using any standard optimizer to architect simulators. More importantly, unlike prior methods, PRIME can also utilize existing databases of infeasible accelerators to learn what not to design. This is done by augmenting the supervised training of the learned model with additional loss terms that specifically penalize the value of the learned model on the infeasible accelerator designs and adversarial examples during training. This approach resembles a form of adversarial training.
In principle, one of the central benefits of a data-driven approach is that it should enable learning highly expressive and generalist models of the optimization objective that generalize over target applications, while also potentially being effective for new unseen applications for which a designer has never attempted to optimize accelerators. To train PRIME so that it generalizes to unseen applications, we modify the learned model to be conditioned on a context vector that identifies a given neural net application we wish to accelerate (as we discuss in our experiments below, we choose to use high-level features of the target application: such as number of feed-forward layers, number of convolutional layers, total parameters, etc. to serve as the context), and train a single, large model on accelerator data for all applications designers have seen so far. As we will discuss below in our results, this contextual modification of PRIME enables it to optimize accelerators both for multiple, simultaneous applications and new unseen applications in a zero-shot fashion.
Does PRIME Outperform Custom-Engineered Accelerators?
We evaluate PRIME on a variety of actual accelerator design tasks. We start by comparing the optimized accelerator design architected by PRIME targeted towards nine applications to the manually optimized EdgeTPU design. EdgeTPU accelerators are primarily optimized towards running applications in image classification, particularly MobileNetV2, MobileNetV3 and MobileNetEdge. Our goal is to check if PRIME can design an accelerator that attains a lower latency than a baseline EdgeTPU accelerator3, while also constraining the chip area to be under 27 mm2 (the default for the EdgeTPU accelerator). Shown below, we find that PRIME improves latency over EdgeTPU by 2.69x (up to 11.84x in t-RNN Enc), while also reducing the chip area usage by 1.50x (up to 2.28x in MobileNetV3), even though it was never trained to reduce chip area! Even on the MobileNet image-classification models, for which the custom-engineered EdgeTPU accelerator was optimized, PRIME improves latency by 1.85x.
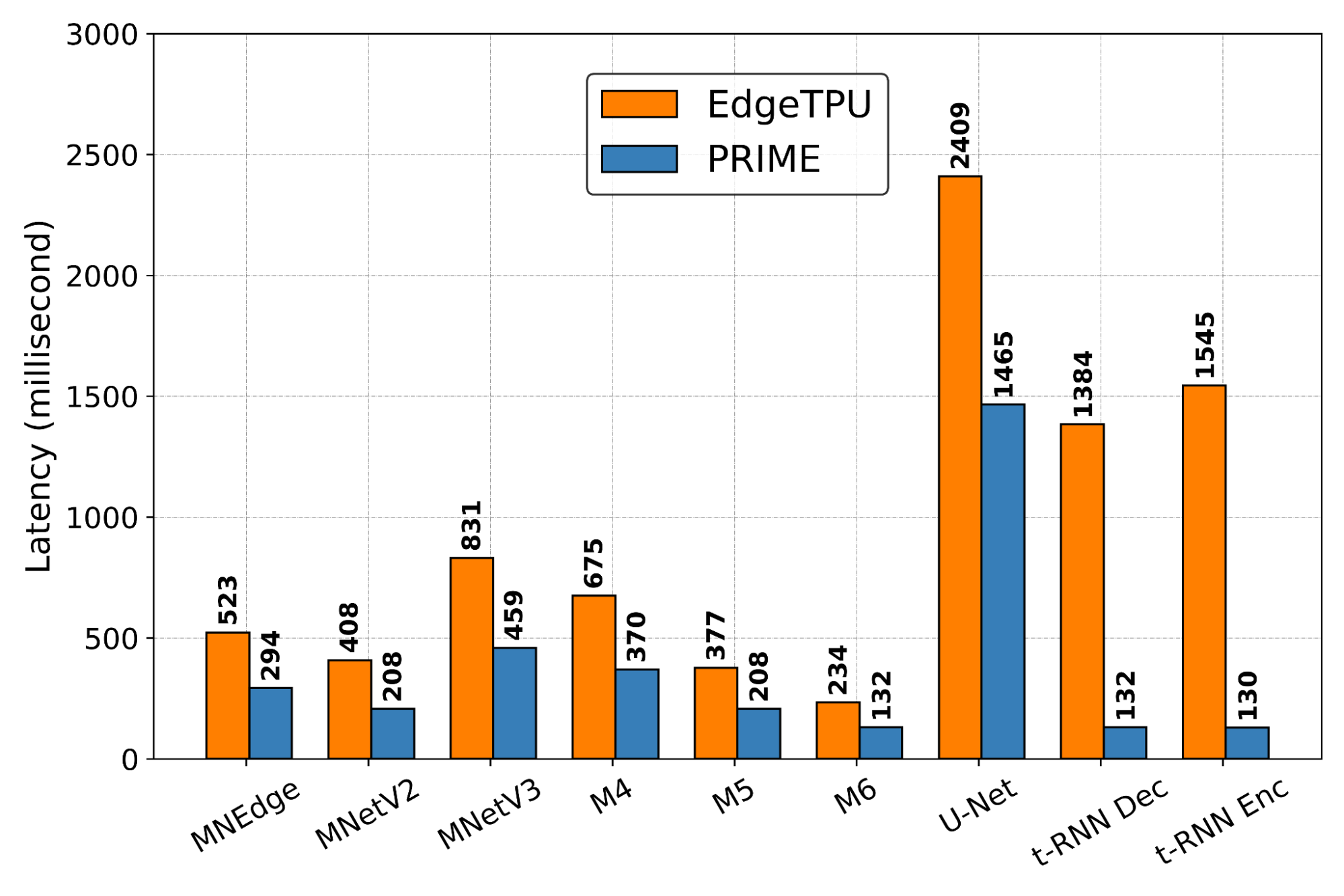 |
| Comparing latencies (lower is better) of accelerator designs suggested by PRIME and EdgeTPU for single-model specialization. |
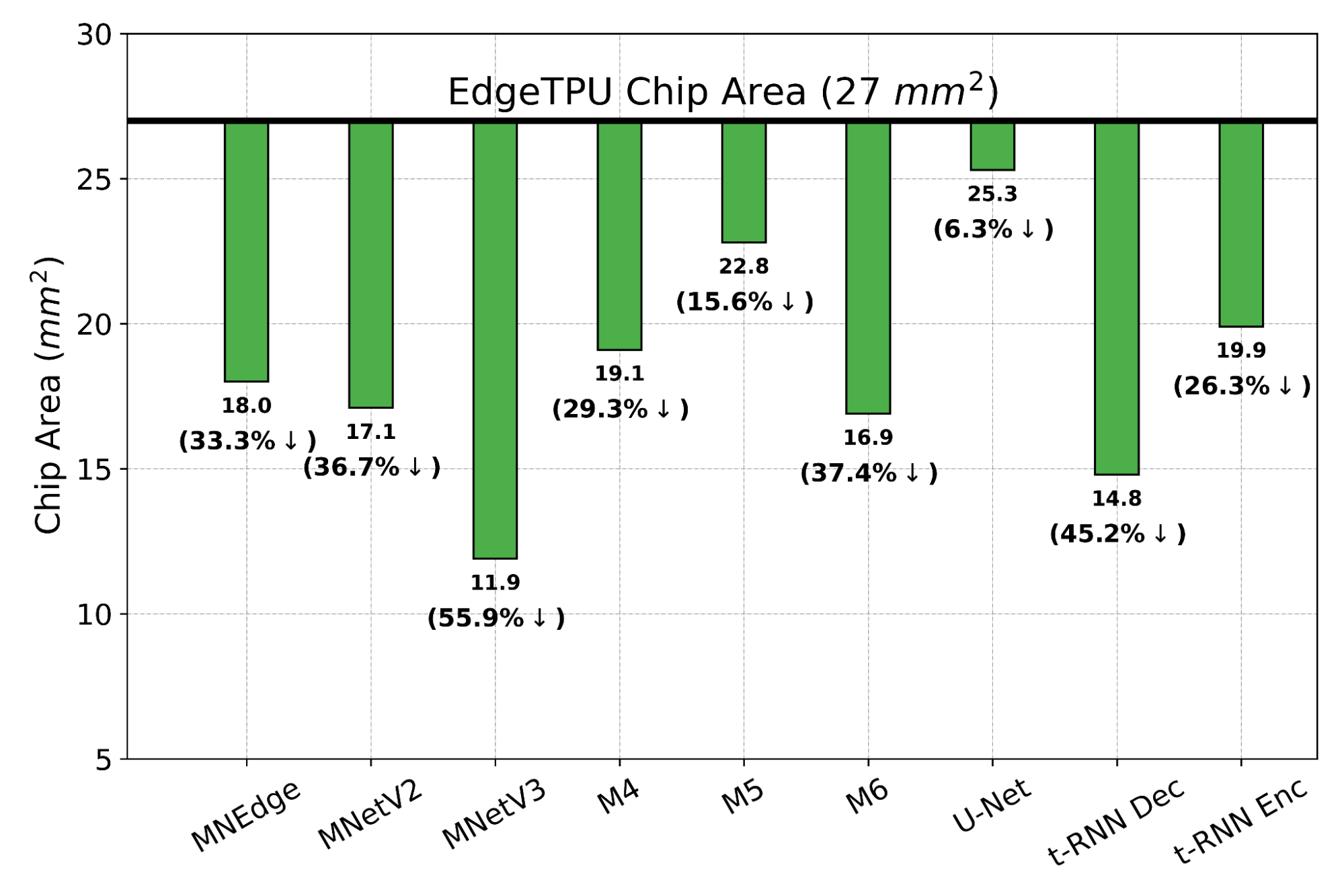 |
| The chip area (lower is better) reduction compared to a baseline EdgeTPU design for single-model specialization. |
Designing Accelerators for New and Multiple Applications, Zero-Shot
We now study how PRIME can use logged accelerator data to design accelerators for (1) multiple applications, where we optimize PRIME to design a single accelerator that works well across multiple applications simultaneously, and in a (2) zero-shot setting, where PRIME must generate an accelerator for new unseen application(s) without training on any data from such applications. In both settings, we train the contextual version of PRIME, conditioned on context vectors identifying the target applications and then optimize the learned model to obtain the final accelerator. We find that PRIME outperforms the best simulator-driven approach in both settings, even when very limited data is provided for training for a given application but many applications are available. Specifically in the zero-shot setting, PRIME outperforms the best simulator-driven method we compared to, attaining a reduction of 1.26x in latency. Further, the difference in performance increases as the number of training applications increases.
 |
| The average latency (lower is better) of test applications under zero-shot setting compared to a state-of-the-art simulator-driven approach. The text on top of each bar shows the set of training applications. |
Closely Analyzing an Accelerator Designed by PRIME
To provide more insight to hardware architecture, we examine the best accelerator designed by PRIME and compare it to the best accelerator found by the simulator-driven approach. We consider the setting where we need to jointly optimize the accelerator for all nine applications, MobileNetEdge, MobileNetV2, MobileNetV3, M4, M5, M64, t-RNN Dec, and t-RNN Enc, and U-Net, under a chip area constraint of 100 mm2. We find that PRIME improves latency by 1.35x over the simulator-driven approach.
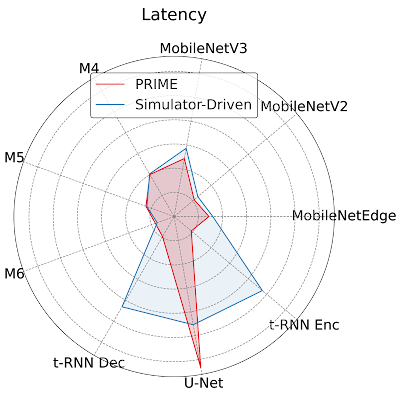 |
| Per application latency (lower is better) for the best accelerator design suggested by PRIME and state-of-the-art simulator-driven approach for a multi-task accelerator design. PRIME reduces the average latency across all nine applications by 1.35x over the simulator-driven method. |
As shown above, while the latency of the accelerator designed by PRIME for MobileNetEdge, MobileNetV2, MobileNetV3, M4, t-RNN Dec, and t-RNN Enc are better, the accelerator found by the simulation-driven approach yields a lower latency in M5, M6, and U-Net. By closely inspecting the accelerator configurations, we find that PRIME trades compute (64 cores for PRIME vs. 128 cores for the simulator-driven approach) for larger Processing Element (PE) memory size (2,097,152 bytes vs. 1,048,576 bytes). These results show that PRIME favors PE memory size to accommodate the larger memory requirements in t-RNN Dec and t-RNN Enc, where large reductions in latency were possible. Under a fixed area budget, favoring larger on-chip memory comes at the expense of lower compute power in the accelerator. This reduction in the accelerator's compute power leads to higher latency for the models with large numbers of compute operations, namely M5, M6, and U-Net.
Conclusion
The efficacy of PRIME highlights the potential for utilizing the logged offline data in an accelerator design pipeline. A likely avenue for future work is to scale this approach across an array of applications, where we expect to see larger gains because simulator-driven approaches would need to solve a complex optimization problem, akin to searching for needle in a haystack, whereas PRIME can benefit from generalization of the surrogate model. On the other hand, we would also note that PRIME outperforms prior simulator-driven methods we utilize and this makes it a promising candidate to be used within a simulator-driven method. More generally, training a strong offline optimization algorithm on offline datasets of low-performing designs can be a highly effective ingredient in at the very least, kickstarting hardware design, versus throwing out prior data. Finally, given the generality of PRIME, we hope to use it for hardware-software co-design, which exhibits a large search space but plenty of opportunity for generalization. We have also released both the code for training PRIME and the dataset of accelerators.
Acknowledgments
We thank our co-authors Sergey Levine, Kevin Swersky, and Milad Hashemi for their advice, thoughts and suggestions. We thank James Laudon, Cliff Young, Ravi Narayanaswami, Berkin Akin, Sheng-Chun Kao, Samira Khan, Suvinay Subramanian, Stella Aslibekyan, Christof Angermueller, and Olga Wichrowskafor for their help and support, and Sergey Levine for feedback on this blog post. In addition, we would like to extend our gratitude to the members of “Learn to Design Accelerators”, “EdgeTPU”, and the Vizier team for providing invaluable feedback and suggestions. We would also like to thank Tom Small for the animated figure used in this post.
1The infeasible accelerator designs stem from build errors in silicon or compilation/mapping failures. ↩
2This is akin to adversarial examples in supervised learning – these examples are close to the data points observed in the training dataset, but are misclassified by the classifier. ↩
3The performance metrics for the baseline EdgeTPU accelerator are extracted from an industry-based hardware simulator tuned to match the performance of the actual hardware. ↩
4These are proprietary object-detection models, and we refer to them as M4 (indicating Model 4), M5, and M6 in the paper. ↩
Source: Google AI Blog
Machine Learning Communities: Q4 ‘21 highlights and achievements
Posted by HyeJung Lee, DevRel Community Manager and Soonson Kwon, DevRel Program Manager
Let’s explore highlights and achievements of vast Google Machine Learning communities over the last quarter of last year! We are excited and grateful about all the activities that the communities across the globe do.

India-based Aakash Nain has completed the TF-Jax tutorial series with Part 9 (Autodiff in JAX) and Part 10 (Pytrees in JAX). Aakash also started a new tutorial series to learn about the existing methods of building models in JAX. The first tutorial Building models in JAX - Part1 (Stax) is released.

On Dec 12th, ML GDE Paolo Galeone started to solve puzzles of the Advent of Code series using “pure TensorFlow” (without any other library). His solution has been updated in a series of 12 on his blog. He explained how he designed the solutions, how he implemented them, and - when needed - focused on some TensorFlow features not widely used. (Day 1, Day 2, Day 3, Day 4, Day 5, Day 6, Day 7, Day 8, Day 9, Day 10, Day 11, Day 12, Wrap up)
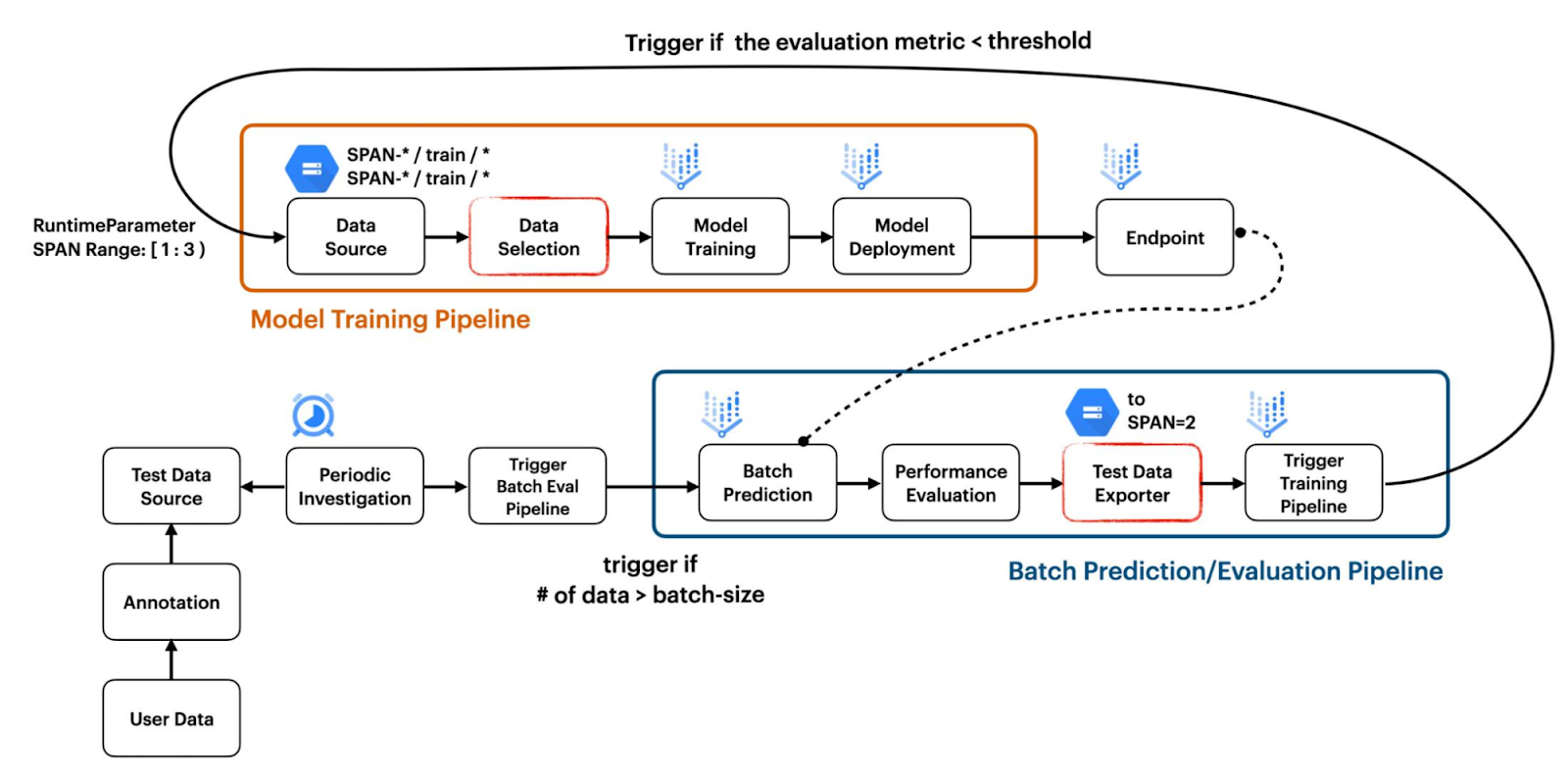
ML GDE Chansung Park (Korea) & Sayak Paul (India) published an “Continuous Adaptation for Machine Learning System to Data Changes” article on TensorFlow blog. They presented a project that implements a workflow combining batch prediction and model evaluation for continuous evaluation retraining In order to capture changes in the data.

ML GDE Elyes Manai from Tunisia wrote an article on GDE blog about his experience on the Google Cloud ML Engineer certification covering guide to certificate and tips.

TFUG organizer Ali Mustufa Shaikh and Rishit Dagli released “CPPE-5: Medical Personal Protective Equipment Dataset” (paper, code). This paper got featured on Google Research TRC's publication section on January 5, 2022.

TFUG New York hosted a series of events in Dec. End-to-End NLP Workshop with TensorFlow. Brief introduction to the Kaggle competition for Great Barrier Reef challenge by Google(Slide). TF idea for ML Projects with GCP.
ML GDE Elyes Manai from Tunisia wrote an article “The ability to change people’s lives and leave one’s mark“. Are you facing difficulties growing in constrained environments? And do you think you're not a first-class student and you don't have connections in the industry? Then, check out Elyes’s story. He shared how Google helped him accelerate his impact.
ML GDE Sayak Paul (India) and Soumik Rakshit’s Point Cloud Segmentation implemented the PointNet architecture for segmenting 3D point clouds using the ShapeNetCore dataset with TensorFlow 2.x. It is a winner of #TFCommunitySpotlight too.

Annotated Research Papers by ML GDE Aakash Kumar Nain (India) is an effort to make papers more accessible to a wider community. It also supports the web version and includes papers from Google Research and etc. This repository is popular enough to have a +2k star and a +200 fork.

Interview series of DevLibrary contributors : Meet the ML GDE Shai Reznik (Israel) and Doug Duhaime. And check out what they built with Google technology and what made them passionate.

ML DevFest 2021 by GDG Cloud San Francisco. There are 5 sessions that walk you through framing ML problems, researching ML, building proofs of concepts using existing ML APIs and models, building ML pipelines and etc. ML GDE Vikram Tiwari (USA) presented Vertex, ML Ops and GCP.

Krupal Modi (India)’s blog article and #IamaGDE video shares how he’s been leading the machine learning initiatives at Haptik, a conversational AI platform, and how the team paired with the Indian Government and WhatsApp to build a COVID-19 helpline.

Leigh Johnson from USA is the founder of Print Nanny, an automated failure detection system and monitoring system for 3D printers. Meet Leigh in this blog and video!
Source: Google Developers Blog
Learning from Weakly-Labeled Videos via Sub-Concepts
Video recognition is a core task in computer vision with applications from video content analysis to action recognition. However, training models for video recognition often requires untrimmed videos to be manually annotated, which can be prohibitively time consuming. In order to reduce the effort of collecting videos with annotations, learning visual knowledge from videos with weak labels, i.e., where the annotation is auto-generated without manual intervention, has attracted growing research interest, thanks to the large volume of easily accessible video data. Untrimmed videos, for example, are often acquired by querying with keywords for classes that the video recognition model aims to classify. A keyword, which we refer to as a weak label, is then assigned to each untrimmed video obtained.
Although large-scale videos with weak labels are easier to collect, training with unverified weak labels poses another challenge in developing robust models. Recent studies have demonstrated that, in addition to the label noise (e.g., incorrect action labels on untrimmed videos), there is temporal noise due to the lack of accurate temporal action localization — i.e., an untrimmed video may include other non-targeted content or may only show the target action in a small proportion of the video.
Reducing noise effects for large-scale weakly-supervised pre-training is critical but particularly challenging in practice. Recent work indicates that querying short videos (e.g., ~1 minute in length) to obtain more accurate temporal localization of target actions or applying a teacher model to do filtering can yield improved results. However, such data pre-processing methods prevent models from fully utilizing available video data, especially longer videos with richer content.
In "Learning from Weakly-Labeled Web Videos via Exploring Sub-Concepts", we propose a solution to these issues that uses a simple learning framework to conduct effective pre-training on untrimmed videos. Instead of simply filtering the potential temporal noise, this approach converts such “noisy” data to useful supervision by creating a new set of meaningful “middle ground” pseudo-labels that expand the original weak label space, a novel concept we call Sub-Pseudo Label (SPL). The model is pre-trained on this more "fine-grained" space and then fine-tuned on a target dataset. Our experiments demonstrate that the learned representations are much better than previous approaches. Moreover, SPL has been shown to be effective in improving the action recognition model quality for Google Cloud Video AI, which enables content producers to easily search through massive libraries of their video assets to quickly source content of interest.
 |
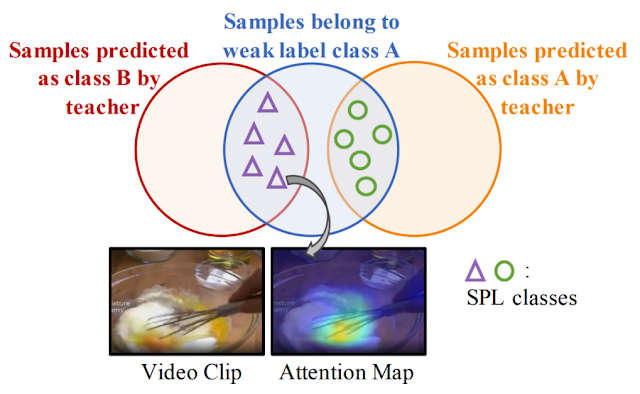 |
| Sampled training clips may represent a different visual action (whisking eggs) from the query label of the whole untrimmed video (baking cookies). SPL converts the potential label noise to useful supervision signals by creating a new set of “middle ground” pseudo-classes (i.e., sub-concepts) via extrapolating two related action classes. Enriched supervision is provided for effective model pre-training. |
Sub-Pseudo Label (SPL)
SPL is a simple technique that advances the teacher-student training framework, which is known to be effective for self-training and to improve semi-supervised learning. In the teacher-student framework, a teacher model is trained on high-quality labeled data and then assigns pseudo-labels to unlabeled data. The student model trains on both high-quality labeled data and the unlabeled data that has the teacher-predicted labels. While previous methods have proposed a number of ways to improve the pseudo-label quality, SPL takes a novel approach that combines knowledge from both weak labels (i.e., query text used to acquire data) and teacher-predicted labels, which results in better pseudo-labels overall. This method focuses on video recognition where temporal noise is challenging, but it can be extended easily to other domains, like image classification.
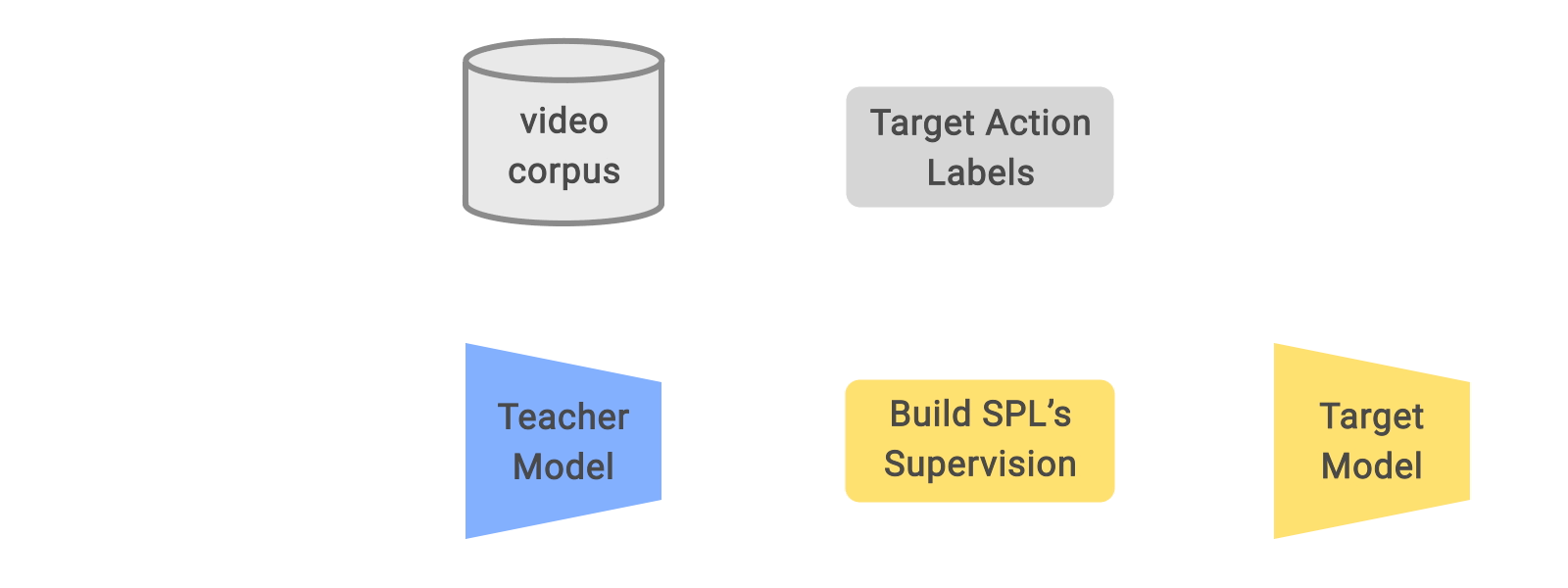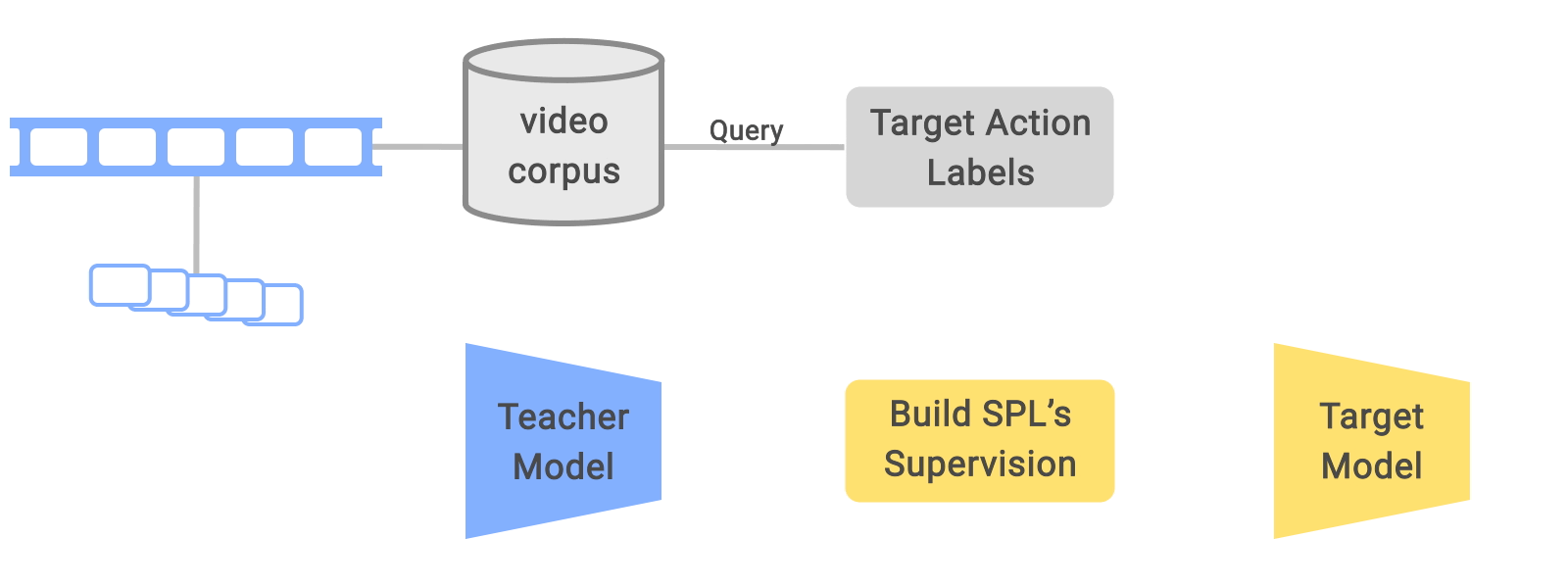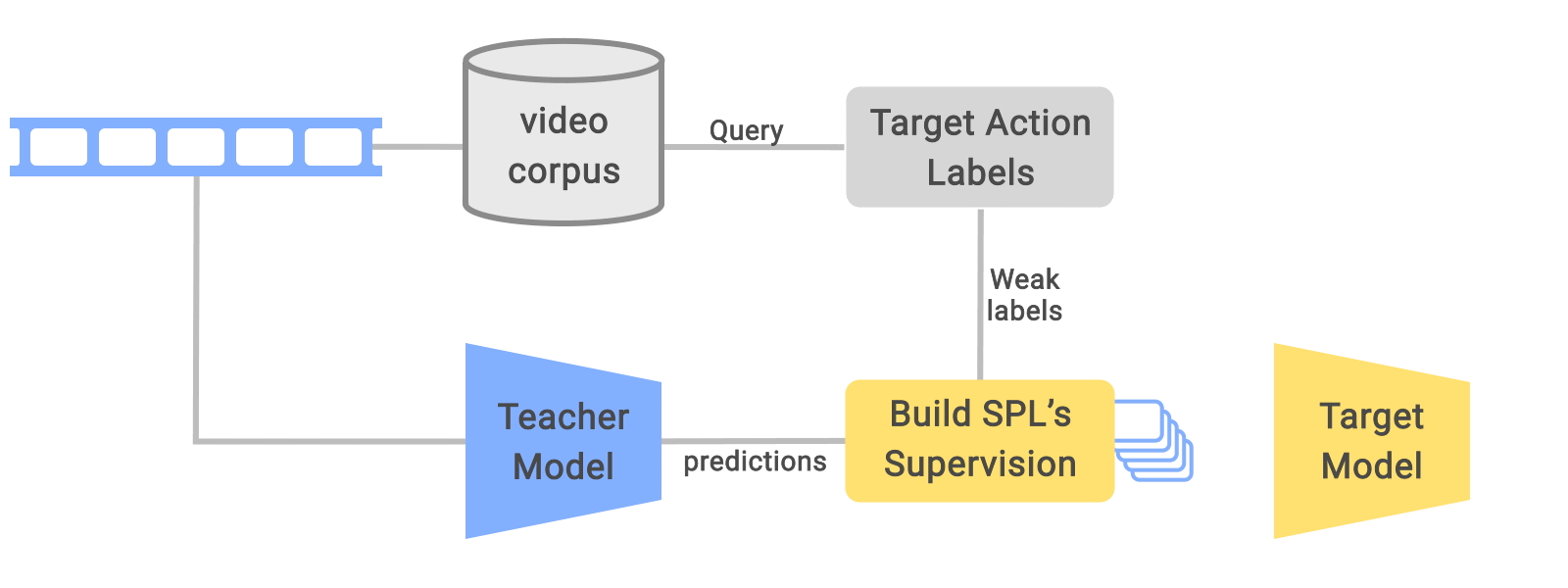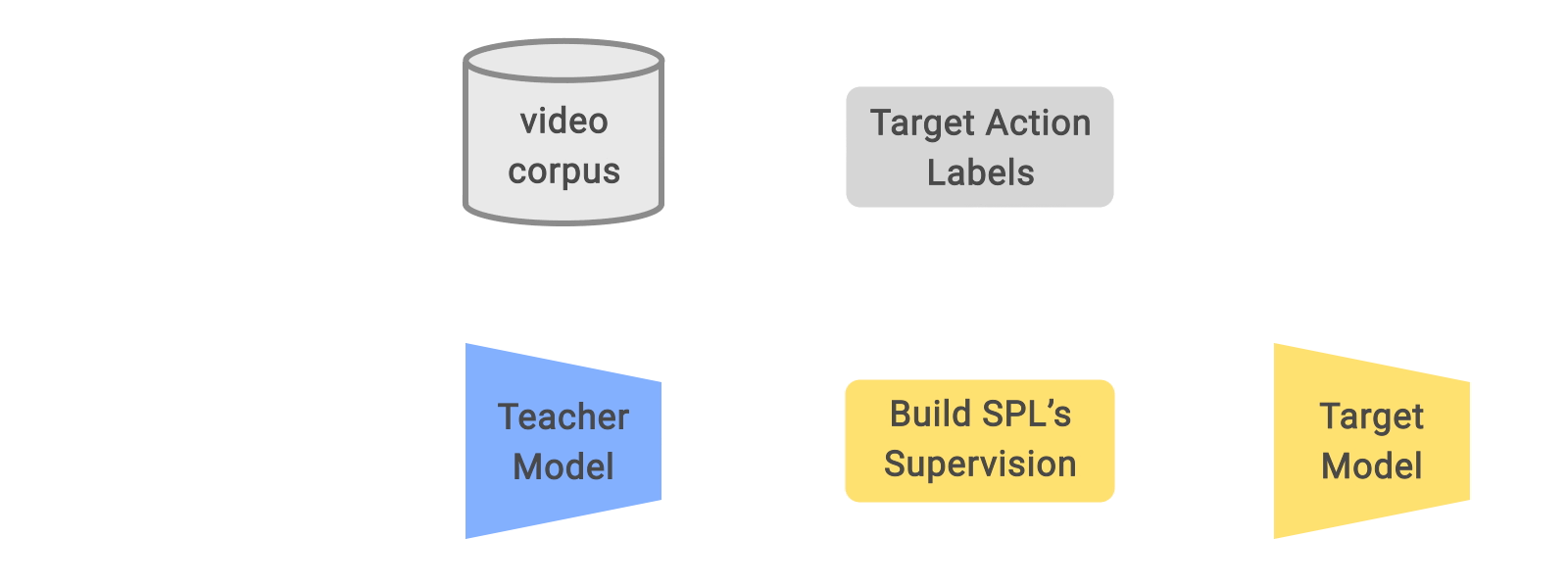 |
| The overall pre-training framework for learning from weakly labeled videos via SPLs. Each trimmed video clip is re-labeled using SPL given the teacher-predicted labels and the weak labels used to query the corresponding untrimmed video. |
The SPL method is motivated by the observation that within an untrimmed video “noisy” video clips have semantic relations with the target action (i.e., the weak label class), but may also include essential visual components of other actions, such as the teacher model–predicted class. Our approach uses the extrapolated SPLs from weak labels together with the distilled labels to capture the enriched supervision signals, encouraging learning better representations during pre-training that can be used for downstream fine-tuning tasks.
It is straightforward to determine the SPL class for each video clip. We first perform inference on each video clip using the teacher model trained from a target dataset to get a teacher prediction class. Each clip is also labeled by the class (i.e., query text) of the untrimmed source video. A 2-dimensional confusion matrix is used to summarize the alignments between the teacher model inferences and the original weak annotations. Based on this confusion matrix, we conduct label extrapolation between teacher model predictions and weak labels to obtain the raw SPL label space.
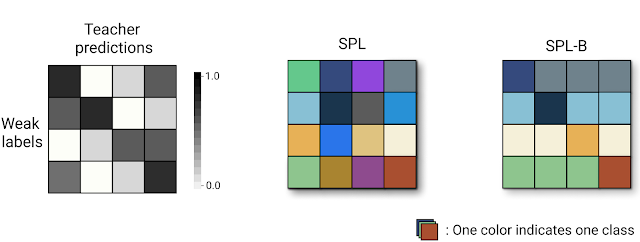 |
| Left: The confusion matrix, which is the basis of the raw SPL label space. Middle: The resulting SPL label spaces (16 classes in this example). Right: SPL-B, another SPL version, that reduces the label space by collating agreed and disagreed entries of each row as independent SPL classes, which in this example results in only 8 classes. |
Effectiveness of SPL
We evaluate the effectiveness of SPL in comparison to different pre-training methods applied to a 3D ResNet50 model that is fine-tuned on Kinetics-200 (K200). One pre-training approach simply initializes the model using ImageNet. The other pre-training methods use 670k video clips sampled from an internal dataset of 147k videos, collected following standard processes similar to those described for Kinetics-200, that cover a broad range of actions. Weak label training and teacher prediction training use either the weak labels or teacher-predicted labels on the videos, respectively. Agreement filtering uses only the training data for which the weak labels and teacher-predicted labels match. We find that SPL outperforms each of these methods. Though the dataset used to illustrate the SPL approach was constructed for this work, in principle the method we describe applies to any dataset that has weak labels.
| Pre-training Method | Top-1 | Top-5 | ||
| ImageNet Initialized | 80.6 | 94.7 | ||
| Weak Label Train | 82.8 | 95.6 | ||
| Teacher Prediction Train | 81.9 | 95.0 | ||
| Agreement Filtering Train | 82.9 | 95.4 | ||
| SPL | 84.3 | 95.7 |
We also demonstrate that sampling more video clips from a given number of untrimmed videos can help improve the model performance. With a sufficient number of video clips available, SPL consistently outperforms weak label pre-training by providing enriched supervision.
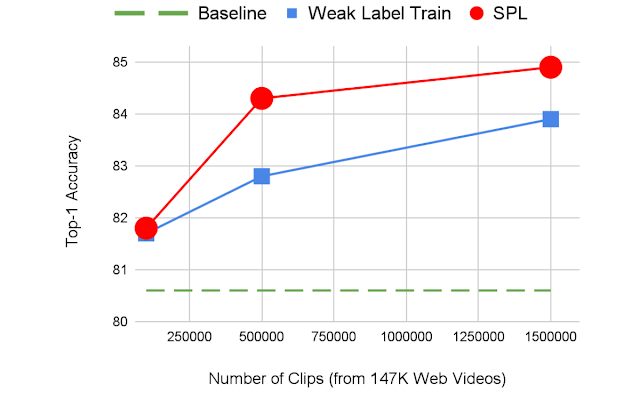 |
| As more clips are sampled from 147K videos, the label noise is increased gradually. SPL becomes more and more effective at utilizing the weakly-labeled clips to achieve better pre-training. |
We visualize the visual concepts learned from SPL with attention visualization by applying Grad-CAM on the trained model. It is interesting to observe some meaningful “middle ground” concepts that can be learned by SPL.
 |
| Examples of attention visualization for SPL classes. Some meaningful “middle ground” concepts can be learned by SPL, such as mixing up the eggs and flour (left) and using the abseiling equipment (right). |
Conclusion
We demonstrate that SPLs can provide enriched supervision for pre-training. SPL does not increase training complexity and can be treated as an off-the-shelf technique to integrate with teacher-student–based training frameworks. We believe this is a promising direction for discovering meaningful visual concepts by bridging weak labels and the knowledge distilled from teacher models. SPL has also demonstrated promising generalization to the image recognition domain and we expect future extensions that apply to tasks that have noise in labels. We have successfully applied SPL for Google Cloud Video AI where it has improved the accuracy of the action recognition models, helping users to better understand, search, and monetize their video content library.
Acknowledgements
We gratefully acknowledge the contributions of other co-authors, including Kunpeng Li, Xuehan Xiong, Chen-Yu Lee, Zhichao Lu, Yun Fu, Tomas Pfister. We also thank Debidatta Dwibedi, David A Ross, Chen Sun, Jonathan C. Stroud, and Wei Hua for their valuable comments and help on this work, and Tom Small for figure creation.
Source: Google AI Blog
Constrained Reweighting for Training Deep Neural Nets with Noisy Labels
Over the past several years, deep neural networks (DNNs) have been quite successful in driving impressive performance gains in several real-world applications, from image recognition to genomics. However, modern DNNs often have far more trainable model parameters than the number of training examples and the resulting overparameterized networks can easily overfit to noisy or corrupted labels (i.e., examples that are assigned a wrong class label). As a consequence, training with noisy labels often leads to degradation in accuracy of the trained model on clean test data. Unfortunately, noisy labels can appear in several real-world scenarios due to multiple factors, such as errors and inconsistencies in manual annotation and the use of inherently noisy label sources (e.g., the internet or automated labels from an existing system).
Earlier work has shown that representations learned by pre-training large models with noisy data can be useful for prediction when used in a linear classifier trained with clean data. In principle, it is possible to directly train machine learning (ML) models on noisy data without resorting to this two-stage approach. To be successful, such alternative methods should have the following properties: (i) they should fit easily into standard training pipelines with little computational or memory overhead; (ii) they should be applicable in “streaming” settings where new data is continuously added during training; and (iii) they should not require data with clean labels.
In “Constrained Instance and Class Reweighting for Robust Learning under Label Noise”, we propose a novel and principled method, named Constrained Instance reWeighting (CIW), with these properties that works by dynamically assigning importance weights both to individual instances and to class labels in a mini-batch, with the goal of reducing the effect of potentially noisy examples. We formulate a family of constrained optimization problems that yield simple solutions for these importance weights. These optimization problems are solved per mini-batch, which avoids the need to store and update the importance weights over the full dataset. This optimization framework also provides a theoretical perspective for existing label smoothing heuristics that address label noise, such as label bootstrapping. We evaluate the method with varying amounts of synthetic noise on the standard CIFAR-10 and CIFAR-100 benchmarks and observe considerable performance gains over several existing methods.
Method
Training ML models involves minimizing a loss function that indicates how well the current parameters fit to the given training data. In each training step, this loss is approximately calculated as a (weighted) sum of the losses of individual instances in the mini-batch of data on which it is operating. In standard training, each instance is treated equally for the purpose of updating the model parameters, which corresponds to assigning uniform (i.e., equal) weights across the mini-batch.
However, empirical observations made in earlier works reveal that noisy or mislabeled instances tend to have higher loss values than those that are clean, particularly during early to mid-stages of training. Thus, assigning uniform importance weights to all instances means that due to their higher loss values, the noisy instances can potentially dominate the clean instances and degrade the accuracy on clean test data.
Motivated by these observations, we propose a family of constrained optimization problems that solve this problem by assigning importance weights to individual instances in the dataset to reduce the effect of those that are likely to be noisy. This approach provides control over how much the weights deviate from uniform, as quantified by a divergence measure. It turns out that for several types of divergence measures, one can obtain simple formulae for the instance weights. The final loss is computed as the weighted sum of individual instance losses, which is used for updating the model parameters. We call this the Constrained Instance reWeighting (CIW) method. This method allows for controlling the smoothness or peakiness of the weights through the choice of divergence and a corresponding hyperparameter.
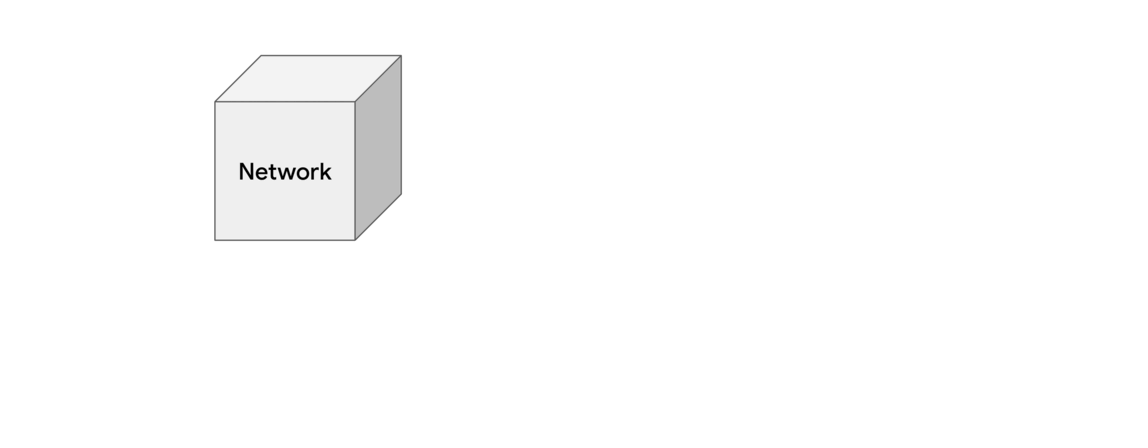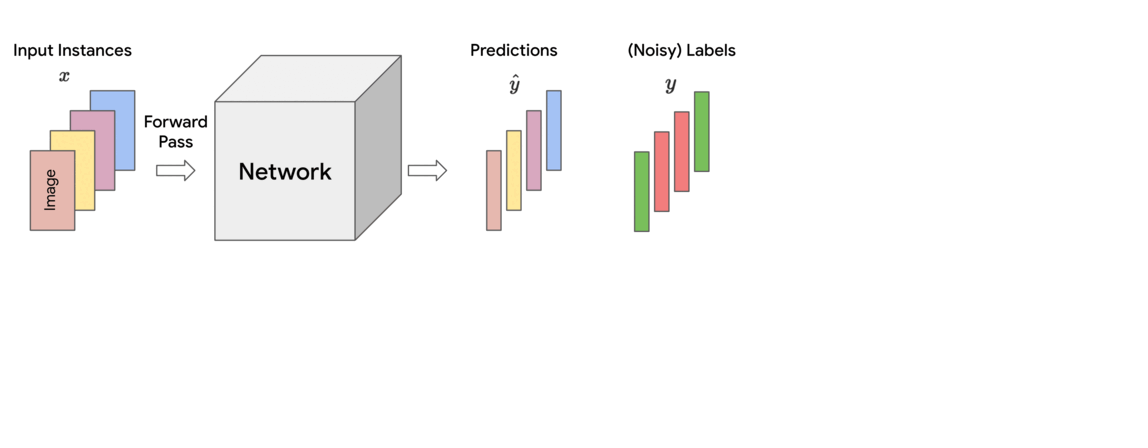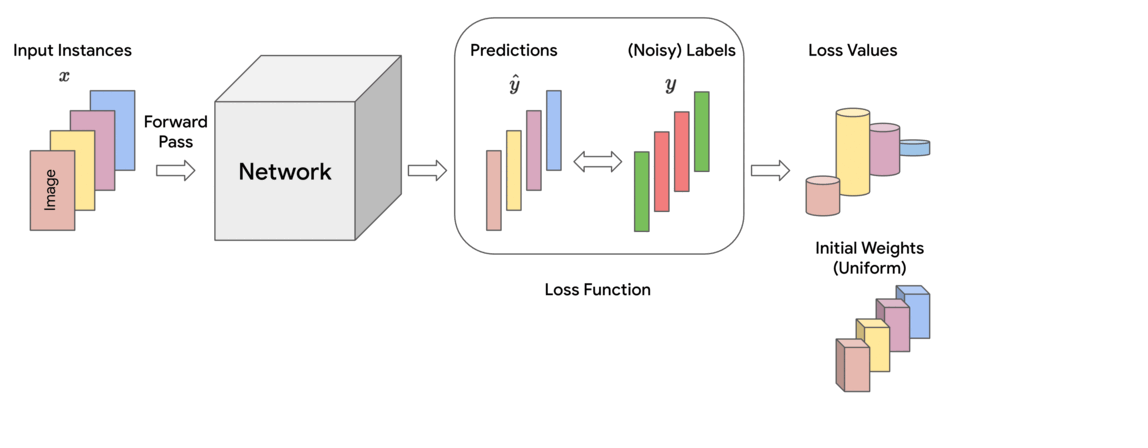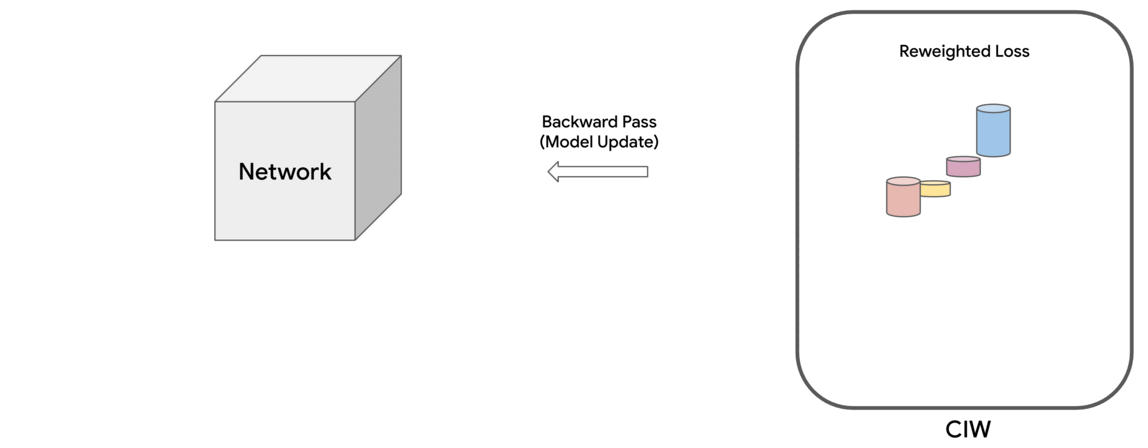 |
| Schematic of the proposed Constrained Instance reWeighting (CIW) method. |
Illustration with Decision Boundary on a 2D Dataset
As an example to illustrate the behavior of this method, we consider a noisy version of the Two Moons dataset, which consists of randomly sampled points from two classes in the shape of two half moons. We corrupt 30% of the labels and train a multilayer perceptron network on it for binary classification. We use the standard binary cross-entropy loss and an SGD with momentum optimizer to train the model. In the figure below (left panel), we show the data points and visualize an acceptable decision boundary separating the two classes with a dotted line. The points marked red in the upper half-moon and those marked green in the lower half-moon indicate noisy data points.
The baseline model trained with the binary cross-entropy loss assigns uniform weights to the instances in each mini-batch, thus eventually overfitting to the noisy instances and resulting in a poor decision boundary (middle panel in the figure below).
The CIW method reweights the instances in each mini-batch based on their corresponding loss values (right panel in the figure below). It assigns larger weights to the clean instances that are located on the correct side of the decision boundary and damps the effect of noisy instances that incur a higher loss value. Smaller weights for noisy instances help in preventing the model from overfitting to them, thus allowing the model trained with CIW to successfully converge to a good decision boundary by avoiding the impact of label noise.
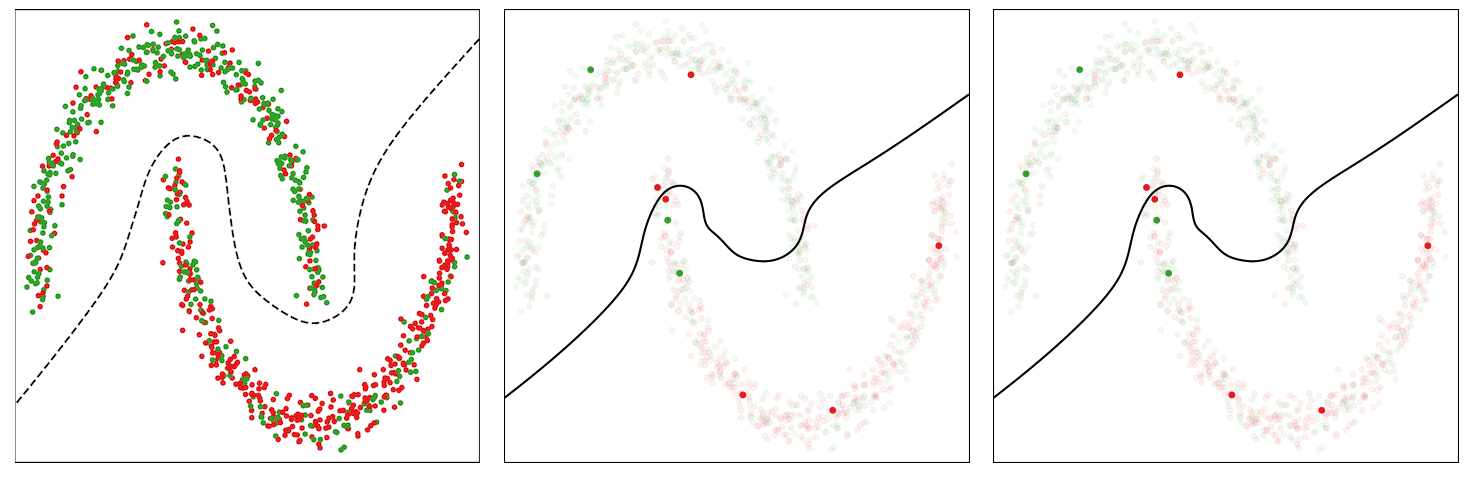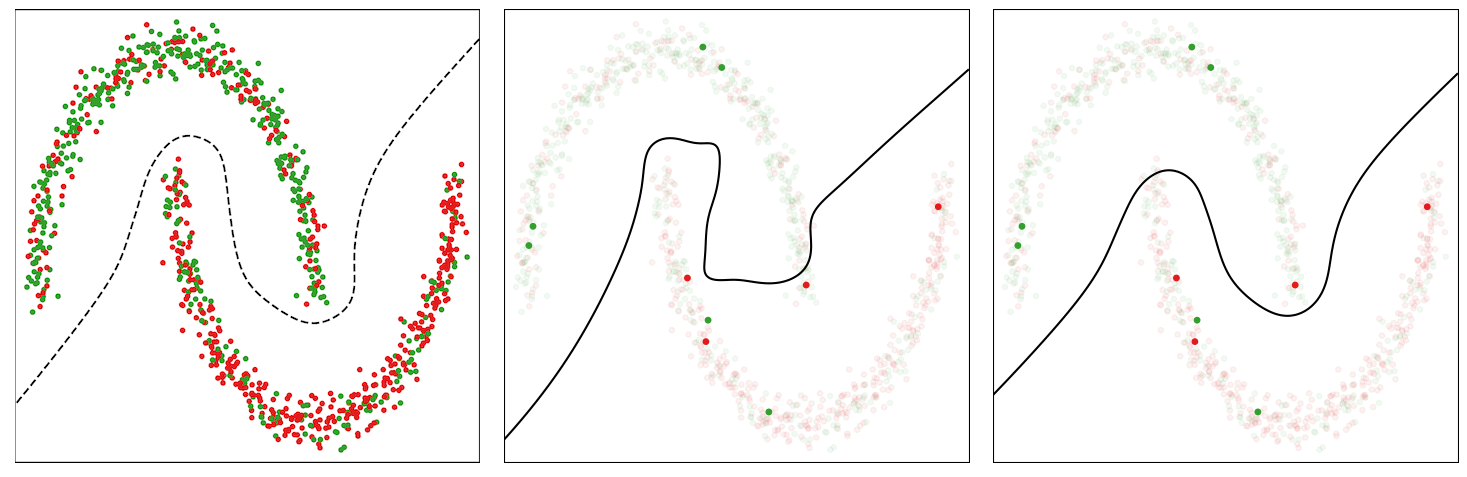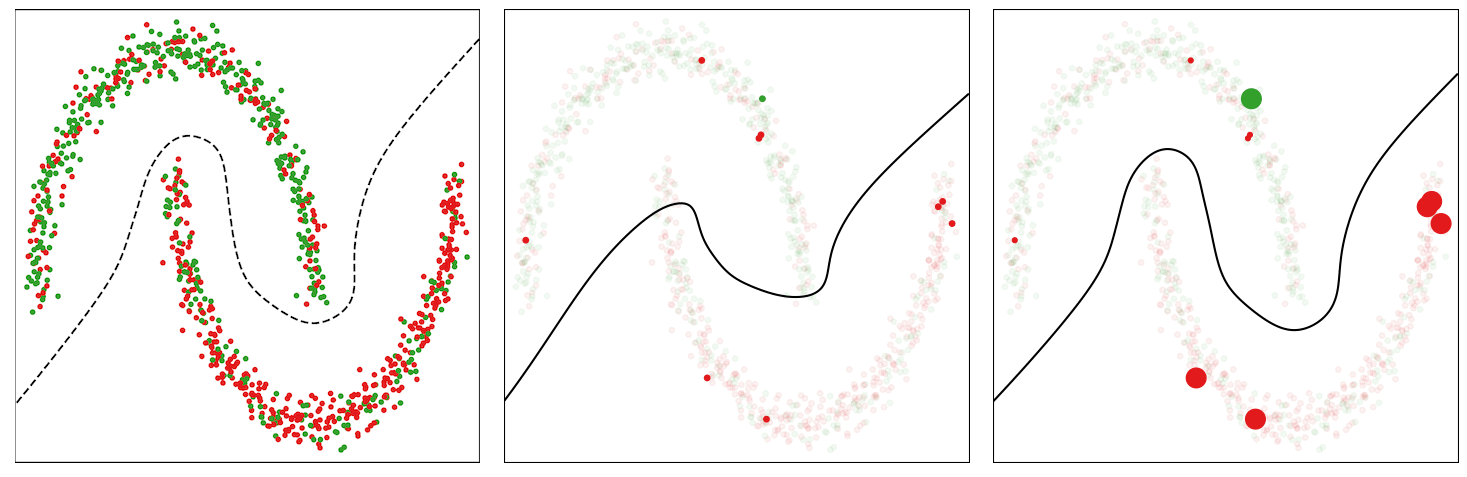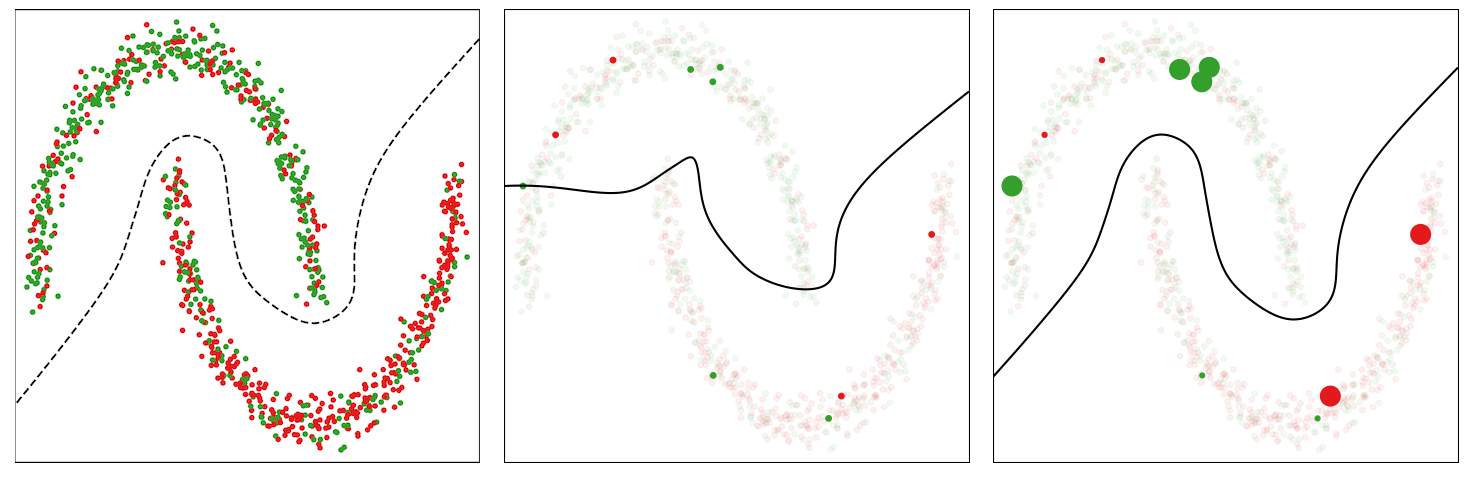 |
| Illustration of decision boundary as the training proceeds for the baseline and the proposed CIW method on the Two Moons dataset. Left: Noisy dataset with a desirable decision boundary. Middle: Decision boundary for standard training with cross-entropy loss. Right: Training with the CIW method. The size of the dots in (middle) and (right) are proportional to the importance weights assigned to these examples in the minibatch. |
Constrained Class reWeighting
Instance reweighting assigns lower weights to instances with higher losses. We further extend this intuition to assign importance weights over all possible class labels. Standard training uses a one-hot label vector as the class weights, assigning a weight of 1 to the labeled class and 0 to all other classes. However, for the potentially mislabeled instances, it is reasonable to assign non-zero weights to classes that could be the true label. We obtain these class weights as solutions to a family of constrained optimization problems where the deviation of the class weights from the label one-hot distribution, as measured by a divergence of choice, is controlled by a hyperparameter.
Again, for several divergence measures, we can obtain simple formulae for the class weights. We refer to this as Constrained Instance and Class reWeighting (CICW). The solution to this optimization problem also recovers the earlier proposed methods based on static label bootstrapping (also referred as label smoothing) when the divergence is taken to be total variation distance. This provides a theoretical perspective on the popular method of static label bootstrapping.
Using Instance Weights with Mixup
We also propose a way to use the obtained instance weights with mixup, which is a popular method for regularizing models and improving prediction performance. It works by sampling a pair of examples from the original dataset and generating a new artificial example using a random convex combination of these. The model is trained by minimizing the loss on these mixed-up data points. Vanilla mixup is oblivious to the individual instance losses, which might be problematic for noisy data because mixup will treat clean and noisy examples equally. Since a high instance weight obtained with our CIW method is more likely to indicate a clean example, we use our instance weights to do a biased sampling for mixup and also use the weights in convex combinations (instead of random convex combinations in vanilla mixup). This results in biasing the mixed-up examples towards clean data points, which we refer to as CICW-Mixup.
We apply these methods with varying amounts of synthetic noise (i.e., the label for each instance is randomly flipped to other labels) on the standard CIFAR-10 and CIFAR-100 benchmark datasets. We show the test accuracy on clean data with symmetric synthetic noise where the noise rate is varied between 0.2 and 0.8.
We observe that the proposed CICW outperforms several methods and matches the results of dynamic mixup, which maintains the importance weights over the full training set with mixup. Using our importance weights with mixup in CICW-M, resulted in significantly improved performance vs these methods, particularly for larger noise rates (as shown by lines above and to the right in the graphs below).
 |
| Test accuracy on clean data while varying the amount of symmetric synthetic noise in the training data for CIFAR-10 and CIFAR-100. Methods compared are: standard Cross-Entropy Loss (CE), Bi-tempered Loss, Active-Passive Normalized Loss, the proposed CICW, Mixup, Dynamic Mixup, and the proposed CICW-Mixup. |
Summary and Future Directions
We formulate a novel family of constrained optimization problems for tackling label noise that yield simple mathematical formulae for reweighting the training instances and class labels. These formulations also provide a theoretical perspective on existing label smoothing–based methods for learning with noisy labels. We also propose ways for using the instance weights with mixup that results in further significant performance gains over instance and class reweighting. Our method operates solely at the level of mini-batches, which avoids the extra overhead of maintaining dataset-level weights as in some of the recent methods.
As a direction for future work, we would like to evaluate the method on realistic noisy labels that are encountered in large scale practical settings. We also believe that studying the interaction of our framework with label smoothing is an interesting direction that can result in a loss adaptive version of label smoothing. We are also excited to release the code for CICW, now available on Github.
Acknowledgements
We'd like to thank Kevin Murphy for providing constructive feedback during the course of the project.
Source: Google AI Blog
ML Olympiad: Globally Distributed ML Competitions by the Community
Posted by Hee Jung, DevRel Community Manager
We are happy to announce ML Olympiad, an associated Kaggle Community Competitions hosted by Machine Learning Google Developer Experts (ML GDE) and TensorFlow User Group (TFUG).
Kaggle recently announced "Community Competitions" allowing anyone to create and host a competition at no cost. And our proud members of ML communities decided to dive in and take advantage of the feature to solve critical issues of our time, providing opportunities to train developers.
Why the ML Olympiad?
To train ML for developers leveraging Kaggle’s community competition. This is an opportunity for the participants to practice ML. This is the first 2022 global campaign of the ML Ecosystem team and this helps build stronger communities.

ML Olympiad Community Competitions
Currently, 16 ML Olympiad community competitions are open, hosted by ML GDEs and TFUGs.
Arabic_Poems (in local language) link
- Predict the name of a poet for Arabic poems. Encourage people to practice on Arabic NLP using TF.
- Hosts: Ruqiya Bin Safi (ML GDE), Eyad Sibai, Hussain Alfayez / Saudi TFUG & Applied ML/AI group
Sky Survey link
- Stellar classification with the digital sky survey
- Hosts: Jieun Yoo, Michael Mellinger / NYTFUG
Análisis epidemiológico Guatemala (in local language) link
- Make an analysis and prediction of epidemiological cases in Guatemala and the relations.
- Hosts: Alvin Estrada, Julio Monterroso / TensorFlow User Group Guatemala
QUALITY EDUCATION (in local language) link
- Competition will be focused on the Enem (National High School Examination) data. Competitors will have to create models to predict student scores in multiple tests.
- Hosts: Vinicius Fernandes Caridá (ML GDE), Pedro Gengo, Alex Fernandes Mansano / Tensorflow User Group São Paulo
Landscape Image Classification link
- Classification of partially masked natural images of mountains, buildings, seas, etc.
- Hosts: Aditya Kane, Yogesh Kulkarni (ML GDE), Shashank Sane / TFUG Pune
Autism Prediction Challenge link
- Classifying whether individuals have Autism or not.
- Hosts: Usha Rengaraju, Vijayabharathi Karuppasamy, Samuel T / TFUG Mysuru and TFUG Chennai
Tamkeen Fund Granted link
- Predict the company funds based on the company's features
- Hosts: Mohammed buallay (ML GDE), Sayed Ali Alkamel (ML GDE)
Hausa Sentiment Analysis (in local language) link
- Classify the sentiment of sentences of Hausa Language
- Hosts: Nuruddeen Sambo, Dattijo Murtala Makama / TFUG Bauchi
TSA Classification (in local language) link
- We invite participants to develop a classification method to identify early autistic disorders.
- Hosts: Yannick Serge Obam (ML GDE), Arnold Junior Mve Mve
Let's Fight lung cancer (in local language) link
- Spotting factors that are link to lung cancer detection
- Hosts: abderrahman jaize, Sara EL-ATEIF / TFUG Casablanca
Genome Sequences classification (in local language) link
- Genome sequence classification based on NCBI's GenBank database
- Hosts: Taha Bouhsine, Said ElHachmey, Lahcen Ousayd / TensorFlow User Group Agadir
GOOD HEALTH AND WELL BEING link
- Using ML to predict heart disease - If a patient has heart disease or not
- Hosts: Ibrahim Olagoke, Ahmad Olanrewaju, Ernest Owojori / TensorFlow User Group Ibadan
Preserving North African Culture link
- We are tackling cultural preservation through a machine learning model capable of identifying the origin of a given item (food, clothing, building).
- Hosts: elyes manai (ML GDE), Rania Boughanmi, Kayoum Djedidi / IEEE ESSTHS + GDSC ENIT
Delivery Assignment Prediction link
- The aim of this competition is to build a multi-class classification model capable of accurately predicting the most suitable driver for one or several given orders based on the destination of the order and the paths covered by the deliverers.
- Host: Thierno Ibrahima DIOP (ML GDE)
Used car price link
- Predicting the price of an imported used car.
- Hosts: Armel Yara, Kimana Misago, Jordan Erifried / TFUG Abidjan
TensorFlow Malaysia User Group link
- Using AI/ML to solve Business Data problem
- Hosts: Poo Kuan Hoong (ML GDE), Yu Yong Poh, Lau Sian Lun / TensorFlow & Deep Learning Malaysia User Group
Navigating ML Olympiad
You can search “ML Olympiad” on Kaggle Community Competitions page to see them all. And for further info, look for #MLOlympiad on social media.
Google Developers support ML Olympiad by providing swag for top 3 winners of each competition. Find your interest among the competitions, join/share them, and get your part of the swag for competition winners!