For many of us, it can be challenging to keep up with the volume of documents that arrive in our inboxes every day: reports, reviews, briefs, policies and the list goes on. When a new document is received, readers often wish it included a brief summary of the main points in order to effectively prioritize it. However, composing a document summary can be cognitively challenging and time-consuming, especially when a document writer is starting from scratch.
To help with this, we recently announced that Google Docs now automatically generates suggestions to aid document writers in creating content summaries, when they are available. Today we describe how this was enabled using a machine learning (ML) model that comprehends document text and, when confident, generates a 1-2 sentence natural language description of the document content. However, the document writer maintains full control — accepting the suggestion as-is, making necessary edits to better capture the document summary or ignoring the suggestion altogether. Readers can also use this section, along with the outline, to understand and navigate the document at a high level. While all users can add summaries, auto-generated suggestions are currently only available to Google Workspace business customers. Building on grammar suggestions, Smart Compose, and autocorrect, we see this as another valuable step toward improving written communication in the workplace.
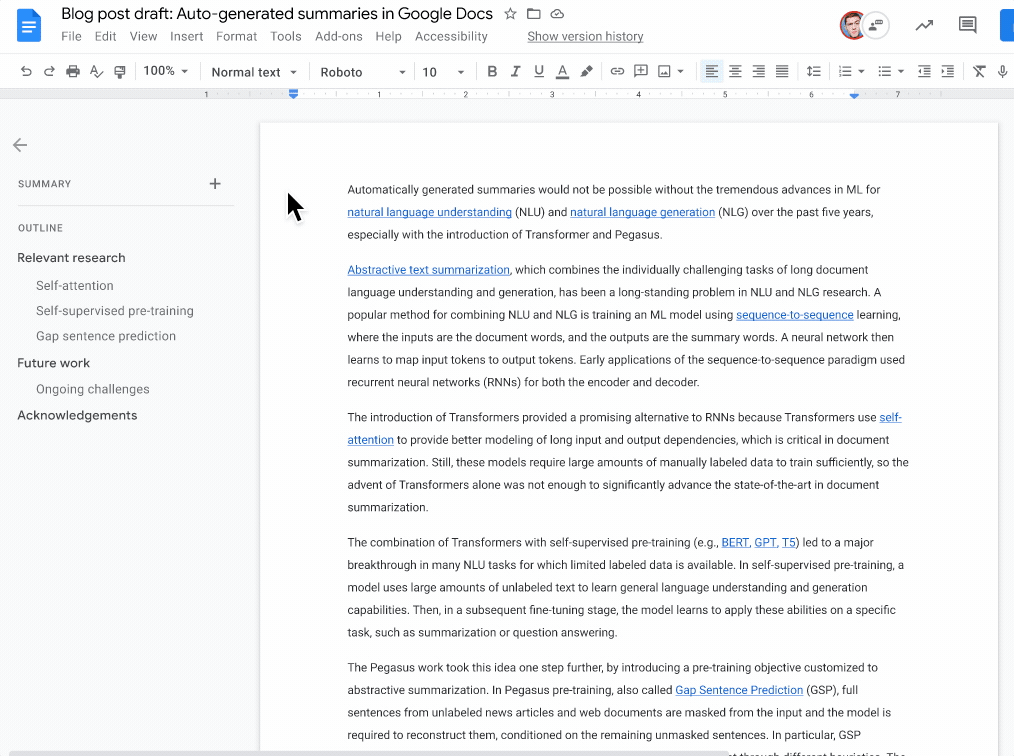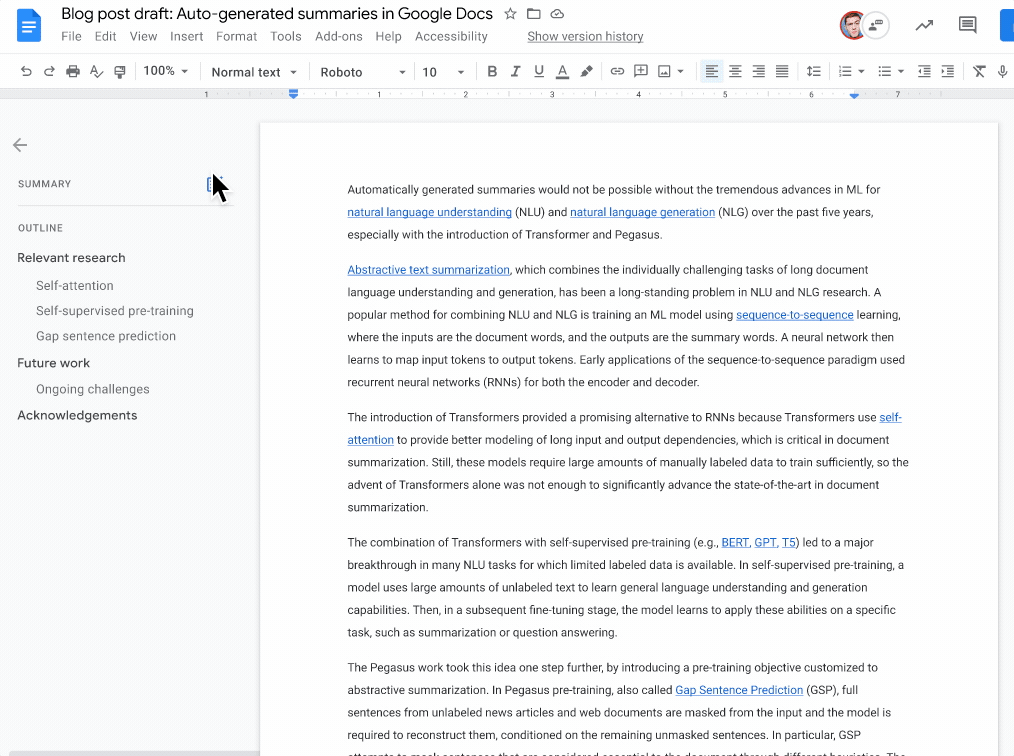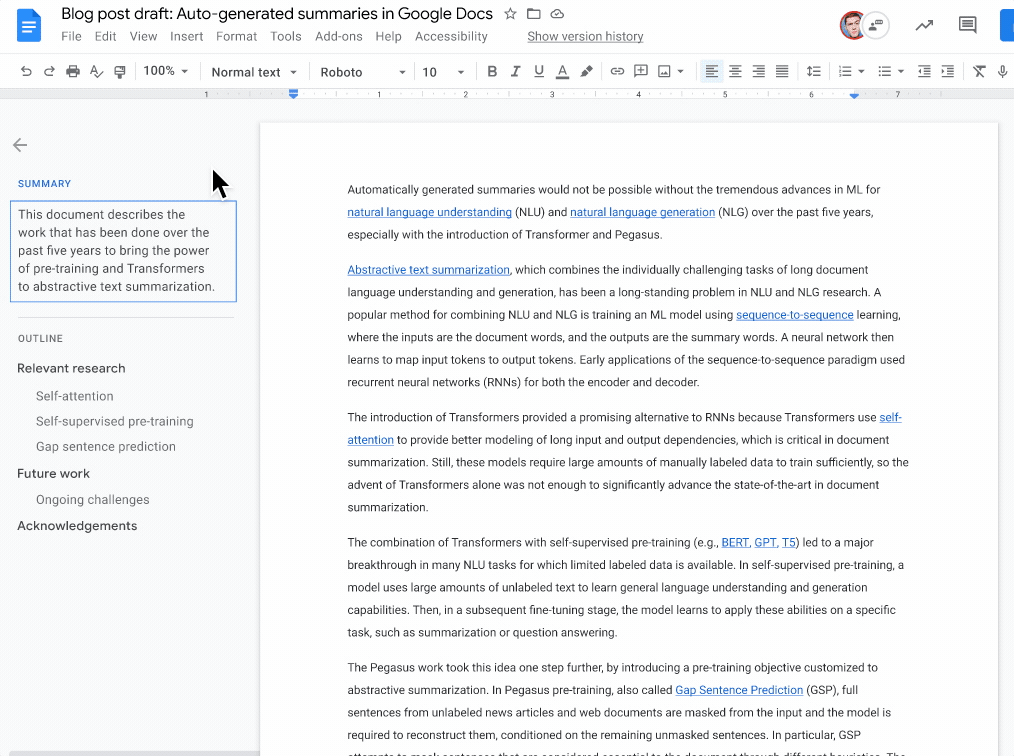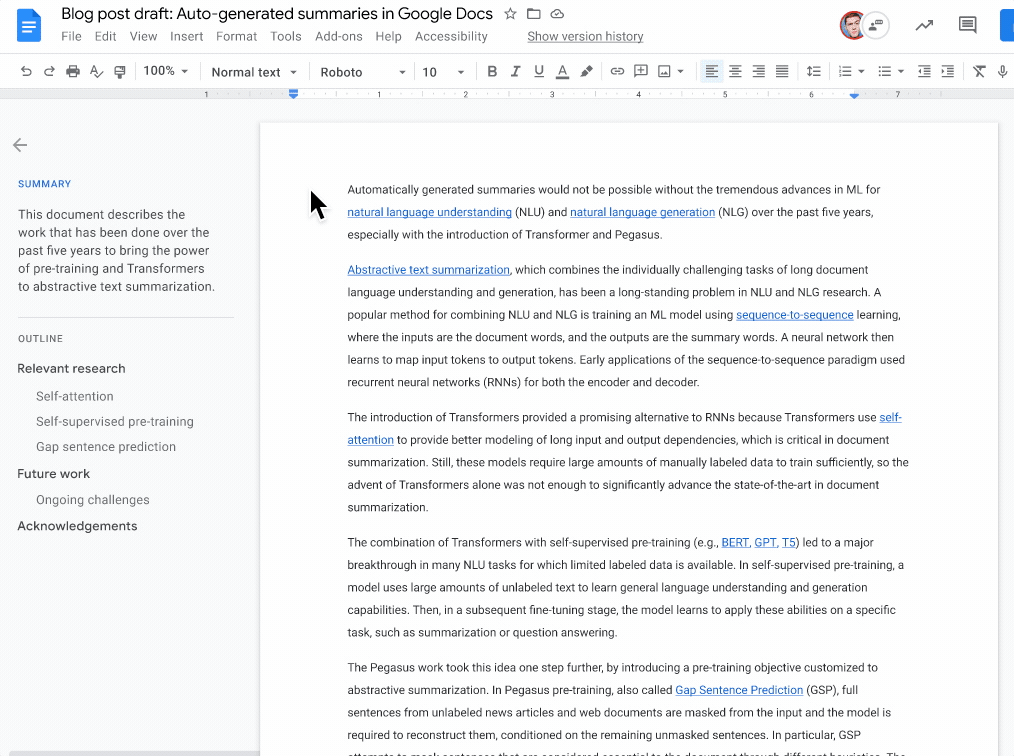 |
| A blue summary icon appears in the top left corner when a document summary suggestion is available. Document writers can then view, edit, or ignore the suggested document summary. |
Model Details
Automatically generated summaries would not be possible without the tremendous advances in ML for natural language understanding (NLU) and natural language generation (NLG) over the past five years, especially with the introduction of Transformer and Pegasus.
Abstractive text summarization, which combines the individually challenging tasks of long document language understanding and generation, has been a long-standing problem in NLU and NLG research. A popular method for combining NLU and NLG is training an ML model using sequence-to-sequence learning, where the inputs are the document words, and the outputs are the summary words. A neural network then learns to map input tokens to output tokens. Early applications of the sequence-to-sequence paradigm used recurrent neural networks (RNNs) for both the encoder and decoder.
The introduction of Transformers provided a promising alternative to RNNs because Transformers use self-attention to provide better modeling of long input and output dependencies, which is critical in document summarization. Still, these models require large amounts of manually labeled data to train sufficiently, so the advent of Transformers alone was not enough to significantly advance the state-of-the-art in document summarization.
The combination of Transformers with self-supervised pre-training (e.g., BERT, GPT, T5) led to a major breakthrough in many NLU tasks for which limited labeled data is available. In self-supervised pre-training, a model uses large amounts of unlabeled text to learn general language understanding and generation capabilities. Then, in a subsequent fine-tuning stage, the model learns to apply these abilities on a specific task, such as summarization or question answering.
The Pegasus work took this idea one step further, by introducing a pre-training objective customized to abstractive summarization. In Pegasus pre-training, also called Gap Sentence Prediction (GSP), full sentences from unlabeled news articles and web documents are masked from the input and the model is required to reconstruct them, conditioned on the remaining unmasked sentences. In particular, GSP attempts to mask sentences that are considered essential to the document through different heuristics. The intuition is to make the pre-training as close as possible to the summarization task. Pegasus achieved state-of-the-art results on a varied set of summarization datasets. However, a number of challenges remained to apply this research advancement into a product.
Applying Recent Research Advances to Google Docs
- Data
Self-supervised pre-training results in an ML model that has general language understanding and generation capabilities, but a subsequent fine-tuning stage is critical for the model to adapt to the application domain. We fine-tuned early versions of our model on a corpus of documents with manually-generated summaries that were consistent with typical use cases.
However, early versions of this corpus suffered from inconsistencies and high variation because they included many types of documents, as well as many ways to write a summary — e.g., academic abstracts are typically long and detailed, while executive summaries are brief and punchy. This led to a model that was easily confused because it had been trained on so many different types of documents and summaries that it struggled to learn the relationships between any of them.
Fortunately, one of the key findings in the Pegasus work was that an effective pre-training phase required less supervised data in the fine-tuning stage. Some summarization benchmarks required as few as 1,000 fine-tuning examples for Pegasus to match the performance of Transformer baselines that saw 10,000+ supervised examples — suggesting that one could focus on quality rather than quantity.
We carefully cleaned and filtered the fine-tuning data to contain training examples that were more consistent and represented a coherent definition of summaries. Despite the fact that we reduced the amount of training data, this led to a higher quality model. The key lesson, consistent with recent work in domains like dataset distillation, was that it was better to have a smaller, high quality dataset, than a larger, high-variance dataset.


- Serving
Once we trained the high quality model, we turned to the challenge of serving the model in production. While the Transformer version of the encoder-decoder architecture is the dominant approach to train models for sequence-to-sequence tasks like abstractive summarization, it can be inefficient and impractical to serve in real-world applications. The main inefficiency comes from the Transformer decoder where we generate the output summary token by token through autoregressive decoding. The decoding process becomes noticeably slow when summaries get longer since the decoder attends to all previously generated tokens at each step. RNNs are a more efficient architecture for decoding since there is no self-attention with previous tokens as in a Transformer model.
We used knowledge distillation, which is the process of transferring knowledge from a large model to a smaller more efficient model, to distill the Pegasus model into a hybrid architecture of a Transformer encoder and an RNN decoder. To improve efficiency we also reduced the number of RNN decoder layers. The resulting model had significant improvements in latency and memory footprint while the quality was still on par with the original model. To further improve the latency and user experience, we serve the summarization model using TPUs, which provide significant speed ups and allow more requests to be handled by a single machine.
Ongoing Challenges and Next Steps
While we are excited by the progress so far, there are a few challenges we are continuing to tackle:
- Document coverage: Developing a set of documents for the fine-tuning stage was difficult due to the tremendous variety that exists among documents, and the same challenge is true at inference time. Some of the documents our users create (e.g., meeting notes, recipes, lesson plans and resumes) are not suitable for summarization or can be difficult to summarize. Currently, our model only suggests a summary for documents where it is most confident, but we hope to continue broadening this set as our model improves.
- Evaluation: Abstractive summaries need to capture the essence of a document while being fluent and grammatically correct. A specific document may have many summaries that can be considered correct, and different readers may prefer different ones. This makes it hard to evaluate summaries with automatic metrics only, user feedback and usage statistics will be critical for us to understand and keep improving quality.
- Long documents: Long documents are some of the toughest documents for the model to summarize because it is harder to capture all the points and abstract them in a single summary, and it can also significantly increase memory usage during training and serving. However, long documents are perhaps most useful for the model to automatically summarize because it can help document writers get a head start on this tedious task. We hope we can apply the latest ML advancements to better address this challenge.
Conclusion
Overall, we are thrilled that we can apply recent progress in NLU and NLG to continue assisting users with reading and writing. We hope the automatic suggestions now offered in Google Workspace make it easier for writers to annotate their documents with summaries, and help readers comprehend and navigate documents more easily.
Acknowledgements
The authors would like to thank the many people across Google that contributed to this work: AJ Motika, Matt Pearson-Beck, Mia Chen, Mahdis Mahdieh, Halit Erdogan, Benjamin Lee, Ali Abdelhadi, Michelle Danoff, Vishnu Sivaji, Sneha Keshav, Aliya Baptista, Karishma Damani, DJ Lick, Yao Zhao, Peter Liu, Aurko Roy, Yonghui Wu, Shubhi Sareen, Andrew Dai, Mekhola Mukherjee, Yinan Wang, Mike Colagrosso, and Behnoosh Hariri. .
