Foundation Models learn from a diverse range of data sources to produce AI systems capable of adapting to a wide range of tasks, instead of being trained for a single narrow use case. Today, we announced Gemini, our most capable model yet. Gemini was designed for flexibility, so it can run on everything from data centers to mobile devices. It's been optimized for three different sizes: Ultra, Pro and Nano.
Gemini Nano, optimized for mobile
Gemini Nano, our most efficient model built for on-device tasks, runs directly on mobile silicon, opening support for a range of important use cases. Running on-device enables features where the data should not leave the device, such as suggesting replies to messages in an end-to-end encrypted messaging app. It also enables consistent experiences with deterministic latency, so features are always available even when there’s no network.
Gemini Nano is distilled down from the larger Gemini models and specifically optimized to run on mobile silicon accelerators. Gemini Nano enables powerful capabilities such as high quality text summarization, contextual smart replies, and advanced proofreading and grammar correction. For example, the enhanced language understanding of Gemini Nano enables the Pixel 8 Pro to concisely summarize content in the Recorder app, even when the phone’s network connection is offline.
Pixel 8 Pro using Gemini Nano in the Recorder app to summarize meeting audio, even without a network connection.
Gemini Nano is starting to power Smart Reply in Gboard on Pixel 8 Pro, ready to be enabled in settings as a developer preview. Available now to try with WhatsApp and coming to more apps next year, the on-device AI model saves you time by suggesting high-quality responses with conversational awareness1.
Smart Reply in Gboard within WhatsApp using Gemini Nano on Pixel 8 Pro.
Android AICore, a new system service for on-device foundation models
Android AICore is a new system service in Android 14 that provides easy access to Gemini Nano. AICore handles model management, runtimes, safety features and more, simplifying the work for you to incorporate AI into your apps.
AICore is private by design, following the example of Android’s Private Compute Core with isolation from the network via open-source APIs, providing transparency and auditability. As part of our efforts to build and deploy AI responsibly, we also built dedicated safety features to make it safer and more inclusive for everyone.
AICore manages model, runtime and safety features.
AICore enables Low Rank Adaptation (LoRA) fine tuning with Gemini Nano. This powerful concept enables app developers to create small LoRA adapters based on their own training data. The LoRA adapter is loaded by AICore, resulting in a powerful large language model fine tuned for the app’s own use-cases.
AICore takes advantage of new ML hardware like the latest Google Tensor TPU and NPUs in flagship Qualcomm Technologies, Samsung S.LSI and MediaTek silicon. AICore and Gemini Nano are rolling out to Pixel 8 Pro, with more devices and silicon partners to be announced in the coming months.
Build with Gemini
We're excited to bring together state-of-the-art AI research with easy-to-use tools and APIs for Android developers to build with Gemini on-device. If you are interested in building apps using Gemini Nano and AICore, please sign up for our Early Access Program.
1 Available globally, only using the United States English keyboard language. Read more for details.
Let’s try an experiment. We’ll show this picture to our multimodal model Gemini and ask it to describe what it sees:
Tell me what you see
Gemini: I see a person's right hand. The hand is open with the fingers spread apart.
Ok, let’s try this one:
Gemini: A person knocking on a wooden door.
How about this one?
Gemini: I see a hand with two fingers extended, which is a common symbol for the number two.
But wait … what if we asked Gemini to reason about all of these images together?
What do you think I'm doing? Hint: it's a game.
Gemini: You're playing rock, paper, scissors.
Nice. What else could we try? Let's see if Gemini can notice this pattern:
I’m playing rock paper scissors. Do you notice a pattern in my gameplay?
Gemini: You are alternating between rock and scissors.
Neat, it spotted the pattern! But does Gemini really know how this game works? Let’s try asking:
Hmm ... do you think it's a good strategy?
Gemini: No, it is not a good strategy. Your opponent will quickly learn your pattern and will be able to win every time. You should try to randomize your choices more.
Good advice, Gemini! Okay, for this last one, let’s put your multimodal reasoning capabilities to the test. Here’s your prompt:
This is a secret message. What does it say?
Can you figure it out? We have gotten Gemini to solve it, but we won’t spoil it by putting the answer in this post. 🙂
What is multimodal prompting?
Everything we did just now is an example of “multimodal prompting.” We’re basically giving Gemini combinations of different modalities — image and text in this case — and having Gemini respond by predicting what might come next. Gemini’s ability to seamlessly combine these modes together enables new possibilities for what you can do.
In this post, we’ll explore some of the prompting approaches we used in our Hands on with Gemini demo video. We’ll soon be rolling out Gemini for people to try in Google AI Studio, our free, web-based developer tool where you’ll be able to try your own multimodal prompts with Gemini. We’re hoping this guide of starter prompts and ideas helps inspire you to start exploring your own ideas.
🧮 Spatial reasoning and logic
Logic and puzzles are fun way to test Gemini. Let’s try one that requires both left-to-right spatial reasoning and knowledge about our solar system:
Is this the right order? Consider the distance from the sun and explain your reasoning.
Gemini: No, the correct order is Sun, Earth, Saturn. The Sun is the closest to the center of the solar system, followed by the Earth, and then Saturn.
Nice! Here’s another, inspired by pinewood derby challenges:
Which of these cars is more aerodynamic? The one on the left or the right? Explain why, using specific visual details.
Gemini: The car on the right is more aerodynamic. It has a lower profile and a more streamlined shape. The car on the left has a higher profile and a more boxy shape, which makes it less aerodynamic.
📷 Image sequences
Next, what if we showed Gemini a sequence of images? Let’s see we can show a few still frames from a game of charades and have Gemini guess the movie:
Guess what movie I'm acting out.
Gemini: The Matrix
Nice! But which part specifically? Look at my body movements.
Gemini: The part where Neo dodges bullets.
🪄 Magic tricks
Exploring image sequences really lets you dig into how Gemini reasons over time. Let’s try a classic magic trick.
Explain what I'm doing.
Gemini: You are holding a coin in your right hand.
Where do you think the coin is?
Gemini: The coin is in your right hand.
Sure, that’s a logical answer given what it’s seen. But let’s pull a sleight of hand as we reveal this next image to Gemini...
Look here, what happened?
Gemini: The coin is gone.
Gemini notices it’s gone. But can it summarize what may have happened?
Summarize what may have happened, step by step, starting with the first image.
Gemini:
1. You started with a coin in your right hand.
2. You then made a motion with your hands, and the coin disappeared. 3. You then showed that the coin was gone.
Gemini is leveraging the entire context of this conversation – both text and image – to summarize its answer. Finally, let’s ask:
Can you explain how it disappeared?
Gemini: The coin was palmed.
Gemini makes a really solid guess! But we won’t reveal our secret 🙂.
🔀 Cup shuffling
Let’s try a trick that requires memory and logic: the classic ball and cup shuffling game. For this one, we’ll break it down into steps for Gemini. First, let’s establish the basics with these instructions:
Instructions: There are three cups in position 1 (left), position 2 (middle), position 3 (right).
Next, we’ll need to tell Gemini where we’re placing the ball:
Starting position: The ball is in position 3.
Current state: empty, empty, ball
Notice how we came up with a simple format for remembering where the ball is with “empty, empty, ball.” Next, let’s show Gemini two example turns:
Images:
Swap: 2 and 3
Current state: empty, ball, empty
Images:
Swap: 1 and 2
Current state: ball, empty, empty
In these two example turns, we’re both showing it what a swap looks like, and how to update the ball position. Now, let’s see if Gemini can generalize to a swap it hasn't seen:
Images:
Swap:
Here's Gemini's response:
1 and 3
Current state: empty, empty, ball
Gemini got it! It looked at these images and correctly inferred that cups 1 and 3 are being swapped. And it reasoned correctly about how to update the ball position. Let’s ask:
Tell me where the ball is and summarize how it got there, in paragraph form.
Gemini: The ball is in cup 3.
Starting with the ball in cup 3, the first swap was cup 2 and 3. This put the ball in cup 2. The second swap was cup 1 and 2. This put the ball in cup 1. The third swap was cup 1 and 3. This put the ball in cup 3.
Not only did Gemini get the answer correctly, it accurately summarized the game history. Of course, it won’t always get this challenge right. Sometimes the fake out move (where you swap two empty cups) seems to trip it up, but sometimes it gets that too. But simple prompts like this make it really fun to rapidly test Gemini. You can change the variables in your prompt, including the order of swaps, and see how it does.
🔨 Tool use
If you want to use Gemini in your own apps, you’ll want it to be able to connect to other tools. Let’s try a simple idea where Gemini needs to combine multimodality with tool use: drawing a picture to search for music.
Step 1. Look at this drawing, describe everything in it, and come up with a fun, specific idea for a good musical soundtrack genre, mood, or soundtrack.
Step 2. Provide a search query in the form: "Search [insert query]"
Gemini:
The drawing is of a guitar, drums, and an amplifier. There is also a palm tree. The mood is fun, upbeat, and tropical. The genre is reggae. The soundtrack could be used for a movie or TV show set in a tropical location.
Search "Reggae music for a tropical vacation"
Nice! Gemini both reasons about what it sees and then generates a search query you can parse to do a search. It’s like Gemini is acting like a translator for you – but instead of translating between languages, it’s translating modalities – from drawing to music in this case. With multimodal prompting, you can use Gemini to invent your own entirely new translations between different inputs and outputs.
🕹️Game creation
What if we tried using Gemini to quickly prototype a multimodal game? Here’s an idea: a geography guessing game where you have to point at a map to make your guess. Let’s start by prompting Gemini with the core idea:
Instructions: Let's play a game. Think of a country and give me a clue. The clue must be specific enough that there is only one correct country. I will try pointing at the country on a map.
Next, let’s give Gemini an example turn of gameplay, showing it how we want it to handle both incorrect and correct answers:
Country: This country is huge island that is mostly covered in ice. (Answer: Greenland)
Guess:
I am pointing at the country of Canada *incorrect*
Guess:
I am pointing at the country of Greenland *correct*
Let’s give it a go and prompt Gemini to generate a clue:
Clue:
This country is known for its unique wildlife, including kangaroos and koalas. (Answer: Australia)
Ok, that’s a good clue. Let’s test out whether pointing will work. Just for fun, let’s try pointing at the wrong place first:
Guess:
I am pointing at the country of Brazil *incorrect*
Great! Gemini looked at my image and figured out I’m pointing at Brazil, and correctly reasoned that’s wrong. Now let’s point at the right place on the map:
I am pointing at the country of Australia *correct*
Nice! We’ve basically taught Gemini our game logic just by giving it an example. You'll also notice that it generalized from the illustrated hand in the examples.
⌨️ Coding
Of course, to bring your game idea to life, you’ll eventually have to write some executable code. Let’s see if Gemini can make a simple countdown timer for a game, but with a few fun twists:
Implement a simple timer in HTML/CSS/Javascript. Use a sans serif font and dark mode. Start it at 10 seconds and start counting down. When it reaches zero, replace the timer with a random emoji that is associated with excitement and motivation! Then go back to the timer at 10 seconds and start counting down again.
With just this single instruction, Gemini gives us a working timer that does what we asked for:
My favorite part is scrolling through Gemini’s source code to find the array of motivational emojis it picked for me:
Throughout this post, we’ve been giving Gemini an input, and having Gemini make predictions for what might come next. That's basically what prompting is. And our inputs have been multimodal – image and text, combined.
But so far we've only shown Gemini responding in text. Maybe you’re wondering, can Gemini also respond with a combination of image and text? It can! This is a capability of Gemini called “interleaved text and image generation.” While this feature won’t be ready in the first version of Gemini for people to try, we hope to roll it out soon. Here’s a sneak peek of what’s possible.
Let’s see if we could use Gemini to provide everyday creative inspiration. And let’s try it in a domain that requires a bit of multimodal reasoning ... knitting! 🧶. Similar to our map game above, let's provide one example turn of interaction:
Give me three ideas for crochet creations I could make with these two colors:
Colors: I see blue and yellow yarn.
Idea 1: How about a cute dog with one yellow ear?
Image 1:
Idea 2: Or how about a jellyfish with a few yellow tentacles?
Image 2:
Idea 3: Or how about a blue cat with a yellow nose?
Image 3:
We’re essentially teaching Gemini about how we want each interaction to go: “I’ll take a photo of two balls of yarn, and I expect you (Gemini) to both come up with an idea for something I could make, and generate an image of it.”
Now, let’s show it a new pair of yarn colors it hasn't yet seen, and see if it can generalize:
Give me three ideas for crochet creations I could make with these two colors:
Gemini:
Colors: I see blue and pink yarn.
Idea 1: How about a pig with blue ears?
Image 1:
Idea 2: Or an octopus with pink and blue tentacles?
Image 2:
Idea 3: Or a bunny with a pink nose?
Image 3:
Nice! Gemini correctly reasoned about the new colors (“I see blue and pink yarn”) and generated these ideas and the images in a single, interleaved output of text and image.
What Gemini did here is fundamentally different from today’s text-to-image models. It's not just passing an instruction to a separate text-to-image model. It sees the image of my actual yarn on my wooden table, truly doing multimodal reasoning about my text and image together.
What's Next?
We hope you found this a helpful starter guide to get a sense of what’s possible with Gemini. We’re very excited to roll it out to more people soon so you can explore your own ideas through prompting. Stay tuned!
Join us virtually from 9:30 am to 1:00 pm PT for an immersive and insightful set of deep dives for every level of Machine Learning experience.
The Women in ML Symposium is an inclusive event for anyone passionate about the transformative fields of Machine Learning (ML) and Artificial Intelligence (AI). Meet this year’s women in ML as they uncover practical applications across multiple industries and discuss the latest advancements in frameworks, generative AI, and more.
Joana Carrasqueira, presenter for “Enabling Anyone to Build with Google AI”
Joana is a Developer Relations Lead for AI/ML at Google and her mission is to empower individuals and organizations to harness the power of AI to address real-world challenges.
She is a business leader with a track record of bringing strategic vision and global cross-functional programs to life. She’s also the creator of Google’s Women in ML program and flagship symposium, a pioneering initiative that has equipped thousands of developers with knowledge and skills in AI/ML.
Prior to Google, she worked at the Silicon Valley Innovation Center on innovation consulting for Forbes top500, startups and Venture Capital firms. Served as Education Manager at the International Pharmaceutical Federation, working closely with WHO, UNESCO, the United Nations and started her career at the Portuguese Pharmaceutical Society.
Joana holds an MBA from IE Business School, a Master in Pharmaceutical Sciences and a Leadership Certificate from U.C. Berkeley in California.
Sharbani Roy, presenter for “What’s New in Machine Learning?”
Sharbani is Sr. Director in Google’s Core Machine Learning group.
Before joining Google, Sharbani led engineering and product teams in Amazon Alexa, focused on media streaming, real-time communication, and applied ML (e.g., NLU, CV, and AR) for 1P/3P developers and end consumers.
Sharbani holds degrees in physics and mathematics from the University of Chicago and an MBA from Stanford University, and lives in Seattle with her husband and three children.
Eve Phillips, presenter for “Future of Frameworks: Navigate the OSS Landscape"
Eve is a Director of Product Management at Google.
Currently, Eve leads the ML Frameworks product team, which includes responsibility for TensorFlow, JAX and Keras. Previously, she led product teams within Google for Clinicians and ChromeOS. Prior to Google, she served as CEO of Empower Interactive, delivering tech-enabled behavioral health.
Earlier, she held roles in leading technology companies and investors including Trilogy, Microsoft, and Greylock.
Eve earned a BS and M.Eng in EECS from MIT and an MBA from Stanford.
Meenu Gaba, presenter for “Data-Centric AI: A New Paradigm"
Meenu leads the Machine Learning infrastructure team at Google, with a mission to power AI innovation with world-class ML infrastructure and services.
She is a technology leader with years of experience launching new products and growing small teams into mature scalable, multi-tiered organizations that are poised to deliver high quality products. Meenu enjoys fast-paced, dynamic, highly iterative/innovative environments and has lots of experience in balancing these disciplines while fostering a people-first culture and forming solid grounds for cross-functional relationships.
Meenu holds a Master's degree in Computer Science. In her free time, she enjoys hiking, solving crosswords, and watching movies.
Kelly Shaefer, presenter for “Maximize Your Data Exploration”
Kelly leads product teams at Google Labs, building both entirely new AI products and AI-enabled features into Google's largest existing products.
In the past, she led the Growth team for Google Workspace, including Gmail, Drive, Docs, and many more.
Outside of Google, she led the Enterprise product team at Stripe and was the P&L owner for Stripe's multi-billion dollar Payments area.
Kelly has an undergraduate degree from Wharton at UPenn, and an MBA from Harvard Business School.
Divyashree Sreepathihalli, presenter for “Keras: Shortcut to AI Mastery”
Divya is a talented machine learning software engineer who is currently a part of the Keras team at Google.
In this role, she specializes in developing Keras core modeling APIs and KerasCV to improve the functionality of the software.
Prior to joining Google, Divya worked as a Deep Learning Scientist for Zazu Sensor, a startup group in Intel's Emerging Growth Incubation (EGI) group. Her work there focused on computer vision and deep learning algorithm development for object detection and tracking, resulting in significant advancements for the startup.
Divya completed her Masters in Computer Engineering from Texas A&M University where she focused on Artificial intelligence in 2017.
Na Li, presenter for “Prototype ML with Visual Blocks”
Na Li is a software engineer manager from Google CoreML.
She leads a team to build developer tools to support ML development journey, from prototyping to model visualization and benchmarking.
Prior to Google, she was a research scientist at Harvard, working in HCI domain.
Throughout her career, Na strives to make ML accessible for everyone.
Zoe Wang, presenter for “Deploying ML Models to Mobile Devices”
Zoe is a technical program manager at Google.
Her career has been focused on Machine Learning (ML) productionization.
Currently she works with her team bringing ML models to mobile devices that power some of AI features for Pixel and other edge devices.
Prior to Google, Zoe worked at Meta on ML Platforms for end-to-end ML lifecycles.
Yvonne Li, presenter for “New GenAI Products and Solutions on Google Cloud”
Yvonne Li is a software engineer on the Duet Platform team at Google, where she focuses on improving the quality of generative AI models.
As a machine learning engineer and developer advocate at IBM, she designed and developed language models and curated open source datasets.
She has over 3 years of experience in the big tech industry, and is passionate about using machine learning to solve real-world problems.
Yvonne is the author of two Coursera courses: Data Analysis with R, and, Data Visualization with R.
Nithya Natesan, presenter for “AI-powered Infrastructure: Cloud TPUs”
Nithya Natesan is a Group Product Manager in the Cloud ML Accelerators team focussing on GPU / TPU offerings for Google Cloud.
Prior to Google, she was head of product management at NVIDIA, launching several products like DGX Cloud, Base Command Platform.
She has ~14 years of experience in hyper convergence Data Center software products, with recent focus on ML / AI Infra and Platform products. She is passionate about building rock solid PM teams, and shipping high quality usable ML / AI products.
Andrada Vulpe, presenter for “Community Matters: 8 Reasons Why You Should Be Involved with Kaggle”
Andrada is a Data Scientist at Endava, a Notebooks Grandmaster on Kaggle, a Dev Expert at Weights and Biases and a proud Z by HP Data Science Global Ambassador.
She is highly passionate about Python, R, Machine and Deep Learning, powerful visualizations and everything in between.
Andrada finished her MSc in Data Science and Analytics in the UK and won 2 Kaggle Analytics competitions.
Jeehae Lee, presenter for “From Recovering Pro Golfer to AI Entrepreneur”
Jeehae Lee is a golf industry executive who has worked to create and build transformational sports technology businesses.
As the Co-Founder & CEO of Sportsbox AI, Jeehae is currently developing products using AI-enabled 3D motion analysis technology that will help participants of various sports and fitness activities learn and improve their skills.
Before founding Sportsbox, she spent five years between 2015 and 2020 at Topgolf Entertainment Group, leading strategy and new business development for various divisions including Toptracer. Between 2012 and 2013, she was at global sports and entertainment marketing agency, IMG, representing professional golfer icon Michelle Wie West. Prior to her career in sports business, she played professional golf at the highest level in the sport, competing on the LPGA tour for three years between 2009 and 2011.
Jeehae is a proud graduate of Phillips Academy in Andover, MA, and has a BA in Economics from Yale and an MBA from The Wharton School at University of Pennsylvania.
Jingwan (Cynthia) Lu, panelist for “The Impact of Generative AI in Different Industries”
Cynthia is a senior director from Adobe leading an applied research organization focusing on developing the Adobe Firefly family of GenAI models built from the ground up.
Her team started training Adobe’s first large-scale foundational model and helped rally together the rest of the company to roll out a new web-based product called Firefly featuring the image generation model as the first step in early 2023.
The same technology and its extension power Adobe Photoshop’s Generative Fill and Generative Expand features giving users intelligent image inpainting and outpainting experience. Time recognizes Adobe Photoshop Generative Fill and Generative Expand as best inventions of 2023 in the AI category.
Before Firefly, Jingwan was a computer vision research scientist and team lead who pioneered and led a large group effort to explore early generative models such as GANs within Adobe.
Wei Xiao, panelist for “The Impact of Generative AI in Different Industries”
Wei is the Director of Developer Relations at NVIDIA for the Middle East, Africa, and emerging regions. Her primary focus is to drive AI and accelerated computing integration within the ecosystem.
Before assuming her current role, Wei Xiao headed Ecosystem Engineering and Evangelism teams at both ARM and Samsung Semiconductor.
In addition to her professional endeavors, Wei dedicates her free time to teaching AI courses at the Graduate School of Computer Science at Santa Clara University.
Priya Mathur, panelist for “The Impact of Generative AI in Different Industries”
Priya is a Staff Data Science Manager at Google and she is the founder of Sparkle – GenAI Data Analyst.
At Google, she leads Data Science for Home Platform Monetization and GenAI efforts for DSPA.
Previously at Groupon, she led Data Science for App Push Notifications and TV Ads.
Katherine Chou, panelist for “The Impact of Generative AI in Different Industries”
Katherine is the Senior Director of Research and Innovations at Google with a specific focus on nurturing scientific and technical breakthroughs that can lead to global impact for science, health, climate, and advancement of platform technologies for our developers and researchers.
Katherine is focused on improving the availability and accuracy of healthcare using machine learning. She is a serial intrapreneur, particularly interested in removing health inequities and improving health and well-being outcomes across all populations.
She previously developed products within Google[x] Labs for Life Sciences (now Verily) and co-founded Medical Brain (now “Health AI'') at Google. She also headed up global teams to develop partner solutions and establish developer ecosystems for Mobile Payments, Mobile Search, GeoCommerce, YouTube, and Android.
Outside of Google, she is a Board member and Program Chair of Lewa Wildlife Conservancy, a Scientific Advisor to the ARCS Foundation, a fellow of the Zoological Society of London, and collaborates with other wildlife NGOs and the Cambridge Business Sustainability Programme in applying the Silicon Valley innovation mindset to new areas.
Katherine holds a double major in Computer Science and Economics at Stanford University and an M.S. in CS specialized in graphics.
Jaimie Hwang, presenter for “Take Action, Learn More, Start Building with Google AI”
Jaimie Hwang is a global product marketing leader with over a decade of experience, specifically in AI/ML.
She has built and led global product marketing teams at a number of AI companies, including an award-winning computer vision startup and tech giant Amazon.
She specializes in executive thought leadership, product storytelling, and integrated GTM strategy. She is passionate about promoting AI technology that is built responsibly and solves real-world problems in a human-centric way.
Jaimie holds a BS in Journalism and Integrated Marketing and Communications from Northwestern University. She lives in Seattle, Washington.
Save your spot at WiML Symposium 2023
The Women in ML Symposium offers sessions for all expertise levels, from beginners to advanced practitioners. RSVP today to secure your spot and explore our comprehensive agenda. We can’t wait to see you there!
Join us virtually from 9:30 am to 1:00 pm PT for an immersive and insightful set of deep dives for every level of Machine Learning experience.
The Women in ML Symposium is an inclusive event for anyone passionate about the transformative fields of Machine Learning (ML) and Artificial Intelligence (AI). Meet this year’s women in ML as they uncover practical applications across multiple industries and discuss the latest advancements in frameworks, generative AI, and more.
Joana Carrasqueira, presenter for “Enabling Anyone to Build with Google AI”
Joana is a Developer Relations Lead for AI/ML at Google and her mission is to empower individuals and organizations to harness the power of AI to address real-world challenges.
She is a business leader with a track record of bringing strategic vision and global cross-functional programs to life. She’s also the creator of Google’s Women in ML program and flagship symposium, a pioneering initiative that has equipped thousands of developers with knowledge and skills in AI/ML.
Prior to Google, she worked at the Silicon Valley Innovation Center on innovation consulting for Forbes top500, startups and Venture Capital firms. Served as Education Manager at the International Pharmaceutical Federation, working closely with WHO, UNESCO, the United Nations and started her career at the Portuguese Pharmaceutical Society.
Joana holds an MBA from IE Business School, a Master in Pharmaceutical Sciences and a Leadership Certificate from U.C. Berkeley in California.
Sharbani Roy, presenter for “What’s New in Machine Learning?”
Sharbani is Sr. Director in Google’s Core Machine Learning group.
Before joining Google, Sharbani led engineering and product teams in Amazon Alexa, focused on media streaming, real-time communication, and applied ML (e.g., NLU, CV, and AR) for 1P/3P developers and end consumers.
Sharbani holds degrees in physics and mathematics from the University of Chicago and an MBA from Stanford University, and lives in Seattle with her husband and three children.
Eve Phillips, presenter for “Future of Frameworks: Navigate the OSS Landscape"
Eve is a Director of Product Management at Google.
Currently, Eve leads the ML Frameworks product team, which includes responsibility for TensorFlow, JAX and Keras. Previously, she led product teams within Google for Clinicians and ChromeOS. Prior to Google, she served as CEO of Empower Interactive, delivering tech-enabled behavioral health.
Earlier, she held roles in leading technology companies and investors including Trilogy, Microsoft, and Greylock.
Eve earned a BS and M.Eng in EECS from MIT and an MBA from Stanford.
Meenu Gaba, presenter for “Data-Centric AI: A New Paradigm"
Meenu leads the Machine Learning infrastructure team at Google, with a mission to power AI innovation with world-class ML infrastructure and services.
She is a technology leader with years of experience launching new products and growing small teams into mature scalable, multi-tiered organizations that are poised to deliver high quality products. Meenu enjoys fast-paced, dynamic, highly iterative/innovative environments and has lots of experience in balancing these disciplines while fostering a people-first culture and forming solid grounds for cross-functional relationships.
Meenu holds a Master's degree in Computer Science. In her free time, she enjoys hiking, solving crosswords, and watching movies.
Kelly Shaefer, presenter for “Maximize Your Data Exploration”
Kelly leads product teams at Google Labs, building both entirely new AI products and AI-enabled features into Google's largest existing products.
In the past, she led the Growth team for Google Workspace, including Gmail, Drive, Docs, and many more.
Outside of Google, she led the Enterprise product team at Stripe and was the P&L owner for Stripe's multi-billion dollar Payments area.
Kelly has an undergraduate degree from Wharton at UPenn, and an MBA from Harvard Business School.
Divyashree Sreepathihalli, presenter for “Keras: Shortcut to AI Mastery”
Divya is a talented machine learning software engineer who is currently a part of the Keras team at Google.
In this role, she specializes in developing Keras core modeling APIs and KerasCV to improve the functionality of the software.
Prior to joining Google, Divya worked as a Deep Learning Scientist for Zazu Sensor, a startup group in Intel's Emerging Growth Incubation (EGI) group. Her work there focused on computer vision and deep learning algorithm development for object detection and tracking, resulting in significant advancements for the startup.
Divya completed her Masters in Computer Engineering from Texas A&M University where she focused on Artificial intelligence in 2017.
Na Li, presenter for “Prototype ML with Visual Blocks”
Na Li is a software engineer manager from Google CoreML.
She leads a team to build developer tools to support ML development journey, from prototyping to model visualization and benchmarking.
Prior to Google, she was a research scientist at Harvard, working in HCI domain.
Throughout her career, Na strives to make ML accessible for everyone.
Zoe Wang, presenter for “Deploying ML Models to Mobile Devices”
Zoe is a technical program manager at Google.
Her career has been focused on Machine Learning (ML) productionization.
Currently she works with her team bringing ML models to mobile devices that power some of AI features for Pixel and other edge devices.
Prior to Google, Zoe worked at Meta on ML Platforms for end-to-end ML lifecycles.
Yvonne Li, presenter for “New GenAI Products and Solutions on Google Cloud”
Yvonne Li is a software engineer on the Duet Platform team at Google, where she focuses on improving the quality of generative AI models.
As a machine learning engineer and developer advocate at IBM, she designed and developed language models and curated open source datasets.
She has over 3 years of experience in the big tech industry, and is passionate about using machine learning to solve real-world problems.
Yvonne is the author of two Coursera courses: Data Analysis with R, and, Data Visualization with R.
Nithya Natesan, presenter for “AI-powered Infrastructure: Cloud TPUs”
Nithya Natesan is a Group Product Manager in the Cloud ML Accelerators team focussing on GPU / TPU offerings for Google Cloud.
Prior to Google, she was head of product management at NVIDIA, launching several products like DGX Cloud, Base Command Platform.
She has ~14 years of experience in hyper convergence Data Center software products, with recent focus on ML / AI Infra and Platform products. She is passionate about building rock solid PM teams, and shipping high quality usable ML / AI products.
Andrada Vulpe, presenter for “Community Matters: 8 Reasons Why You Should Be Involved with Kaggle”
Andrada is a Data Scientist at Endava, a Notebooks Grandmaster on Kaggle, a Dev Expert at Weights and Biases and a proud Z by HP Data Science Global Ambassador.
She is highly passionate about Python, R, Machine and Deep Learning, powerful visualizations and everything in between.
Andrada finished her MSc in Data Science and Analytics in the UK and won 2 Kaggle Analytics competitions.
Jeehae Lee, presenter for “From Recovering Pro Golfer to AI Entrepreneur”
Jeehae Lee is a golf industry executive who has worked to create and build transformational sports technology businesses.
As the Co-Founder & CEO of Sportsbox AI, Jeehae is currently developing products using AI-enabled 3D motion analysis technology that will help participants of various sports and fitness activities learn and improve their skills.
Before founding Sportsbox, she spent five years between 2015 and 2020 at Topgolf Entertainment Group, leading strategy and new business development for various divisions including Toptracer. Between 2012 and 2013, she was at global sports and entertainment marketing agency, IMG, representing professional golfer icon Michelle Wie West. Prior to her career in sports business, she played professional golf at the highest level in the sport, competing on the LPGA tour for three years between 2009 and 2011.
Jeehae is a proud graduate of Phillips Academy in Andover, MA, and has a BA in Economics from Yale and an MBA from The Wharton School at University of Pennsylvania.
Jingwan (Cynthia) Lu, panelist for “The Impact of Generative AI in Different Industries”
Cynthia is a senior director from Adobe leading an applied research organization focusing on developing the Adobe Firefly family of GenAI models built from the ground up.
Her team started training Adobe’s first large-scale foundational model and helped rally together the rest of the company to roll out a new web-based product called Firefly featuring the image generation model as the first step in early 2023.
The same technology and its extension power Adobe Photoshop’s Generative Fill and Generative Expand features giving users intelligent image inpainting and outpainting experience. Time recognizes Adobe Photoshop Generative Fill and Generative Expand as best inventions of 2023 in the AI category.
Before Firefly, Jingwan was a computer vision research scientist and team lead who pioneered and led a large group effort to explore early generative models such as GANs within Adobe.
Wei Xiao, panelist for “The Impact of Generative AI in Different Industries”
Wei is the Director of Developer Relations at NVIDIA for the Middle East, Africa, and emerging regions. Her primary focus is to drive AI and accelerated computing integration within the ecosystem.
Before assuming her current role, Wei Xiao headed Ecosystem Engineering and Evangelism teams at both ARM and Samsung Semiconductor.
In addition to her professional endeavors, Wei dedicates her free time to teaching AI courses at the Graduate School of Computer Science at Santa Clara University.
Priya Mathur, panelist for “The Impact of Generative AI in Different Industries”
Priya is a Staff Data Science Manager at Google and she is the founder of Sparkle – GenAI Data Analyst.
At Google, she leads Data Science for Home Platform Monetization and GenAI efforts for DSPA.
Previously at Groupon, she led Data Science for App Push Notifications and TV Ads.
Katherine Chou, panelist for “The Impact of Generative AI in Different Industries”
Katherine is the Senior Director of Research and Innovations at Google with a specific focus on nurturing scientific and technical breakthroughs that can lead to global impact for science, health, climate, and advancement of platform technologies for our developers and researchers.
Katherine is focused on improving the availability and accuracy of healthcare using machine learning. She is a serial intrapreneur, particularly interested in removing health inequities and improving health and well-being outcomes across all populations.
She previously developed products within Google[x] Labs for Life Sciences (now Verily) and co-founded Medical Brain (now “Health AI'') at Google. She also headed up global teams to develop partner solutions and establish developer ecosystems for Mobile Payments, Mobile Search, GeoCommerce, YouTube, and Android.
Outside of Google, she is a Board member and Program Chair of Lewa Wildlife Conservancy, a Scientific Advisor to the ARCS Foundation, a fellow of the Zoological Society of London, and collaborates with other wildlife NGOs and the Cambridge Business Sustainability Programme in applying the Silicon Valley innovation mindset to new areas.
Katherine holds a double major in Computer Science and Economics at Stanford University and an M.S. in CS specialized in graphics.
Jaimie Hwang, presenter for “Take Action, Learn More, Start Building with Google AI”
Jaimie Hwang is a global product marketing leader with over a decade of experience, specifically in AI/ML.
She has built and led global product marketing teams at a number of AI companies, including an award-winning computer vision startup and tech giant Amazon.
She specializes in executive thought leadership, product storytelling, and integrated GTM strategy. She is passionate about promoting AI technology that is built responsibly and solves real-world problems in a human-centric way.
Jaimie holds a BS in Journalism and Integrated Marketing and Communications from Northwestern University. She lives in Seattle, Washington.
Save your spot at WiML Symposium 2023
The Women in ML Symposium offers sessions for all expertise levels, from beginners to advanced practitioners. RSVP today to secure your spot and explore our comprehensive agenda. We can’t wait to see you there!
As large screens become increasingly important within the Android app ecosystem, we are committed to enhance tools to help Android developers adapt their apps for these large screen form factors. In doing so, we strive to ensure that we can bring impactful tools to enhance the overall experience for building for all large screens such as foldables, tablets, and Chromebooks.
Over the last year, the team has worked on bringing Android 13 to the Desktop AVD, along with some additional enhancements to input support within the emulator. The Android 13 release of the Desktop AVD is now available within Android Studio. To test using this emulator, create a new virtual device.
What is the Desktop AVD?
Android Studio comes bundled with various virtual devices that run on different API levels and architectures. These emulators help developers test Android apps across a variety of devices, allowing for testing across different screen sizes, form factors, and APIs.
When an Android app runs on a Chromebook, it uses functionality that mirrors desktop behaviors, such as minimizing, maximizing, or resizing to a user-specified size. The Desktop Android Virtual Device (AVD) is an emulator that allows testing in a freeform windowing mode, similar to a Chromebook, to support this functionality.
What enhancements come with the Android 13 desktop AVD?
Most laptops use a keyboard—and it’s a common input device for increased productivity with tablets and foldables. Prior to Android 13, the Desktop AVD relied solely on uncustomizable input mapping built into Android Studio, which can cause friction points for users who rely on physical devices for mapped input and shortcuts. The Android 13 release of the Desktop AVD adds support for common keyboard interactions with Android apps. You can now test shortcuts, support keys, and mouse support to help you adhere to the large screen app quality guidelines.
Keyboard Shortcuts
The majority of apps within Google Play are designed for mobile usage and as such do not always support keyboard interactions. In Android 13, the Desktop AVD adds support for commonly used shortcuts, such as Ctrl+C (Copy) and Ctrl+V (Paste). These shortcuts can be used when copying text from a TextView/Text composable or pasting text into an EditText/TextField. These shortcuts are intercepted by the system and automatically applied.
Custom shortcuts (which are not intercepted by the system) are also included in this release. An example of this type of shortcut: a media player app that uses the Spacebar to play or pause media. You must use the new Hardware Input feature within Android Studio Hedgehog to use custom shortcuts. This will allow Android Studio to pass custom shortcuts directly to the emulator. If this is not enabled, Android Studio may consume the key combination.
Support keys
Android 13 supports additional keymappings for support keys. These keys are mapped to controls that are similar to experiences for keyboard shortcuts on a desktop. Some examples of these support keys include:
Esc: Dismisses pop-ups and notifications.
Delete / Backspace: Deletes text within an EditText or TextField
Arrow Keys: Provides in-app navigation (Arrow Up/Down to scroll).
Mouse support
In addition to enhanced keyboard support, there are additional mouse controls integrated into the Desktop AVD. Using the scroll wheel sends a mouse scroll event to the app that has input focus. Right-clicking the mouse sends a right-click event—which can be used to show context menus if the app supports it.
Where can you start?
Large screen app quality provides guidance around creating high quality large screen apps across all form factors, outlining a comprehensive set of quality requirements for most types of Android apps. Not all requirements need to be met, but it’s best practice for you to adhere to the requirements that make sense for your apps.
Create a desktop emulator today in Android Studio Hedgehog to see how your Android app responds to keyboard and mouse inputs and freeform window resizing.
In November 2020, we launched our Open Source MPW Shuttle Program to make it easier for researchers and developers to build custom silicon and to enable a thriving ecosystem around open source hardware. Working with our partner, SkyWater Technology, we released the first foundry-supported open source process design kit (PDK) for their 130nm mixed-signal CMOS technology (SKY130), then welcomed GlobalFoundries as a partner with the release of an open source PDK for their 180nm MCU process (GF180MCU).
Then, to give researchers and developers a way to validate and prove their designs made with the PDKs, we partnered with Efabless to fund a series of no-cost manufacturing shuttles for open source designs. In support of this program, Efabless released an end-to-end RTL to GDS design stack called OpenLane that is open source, freely available, and fully supported by their manufacturing platform. OpenLane is now being maintained as part of the OpenROAD Project. When combined with open source PDKs, a design’s verification results can now be freely shared and easily replicated by other researchers and developers, which has enabled a new collaborative model to evaluate and iterate on ideas.
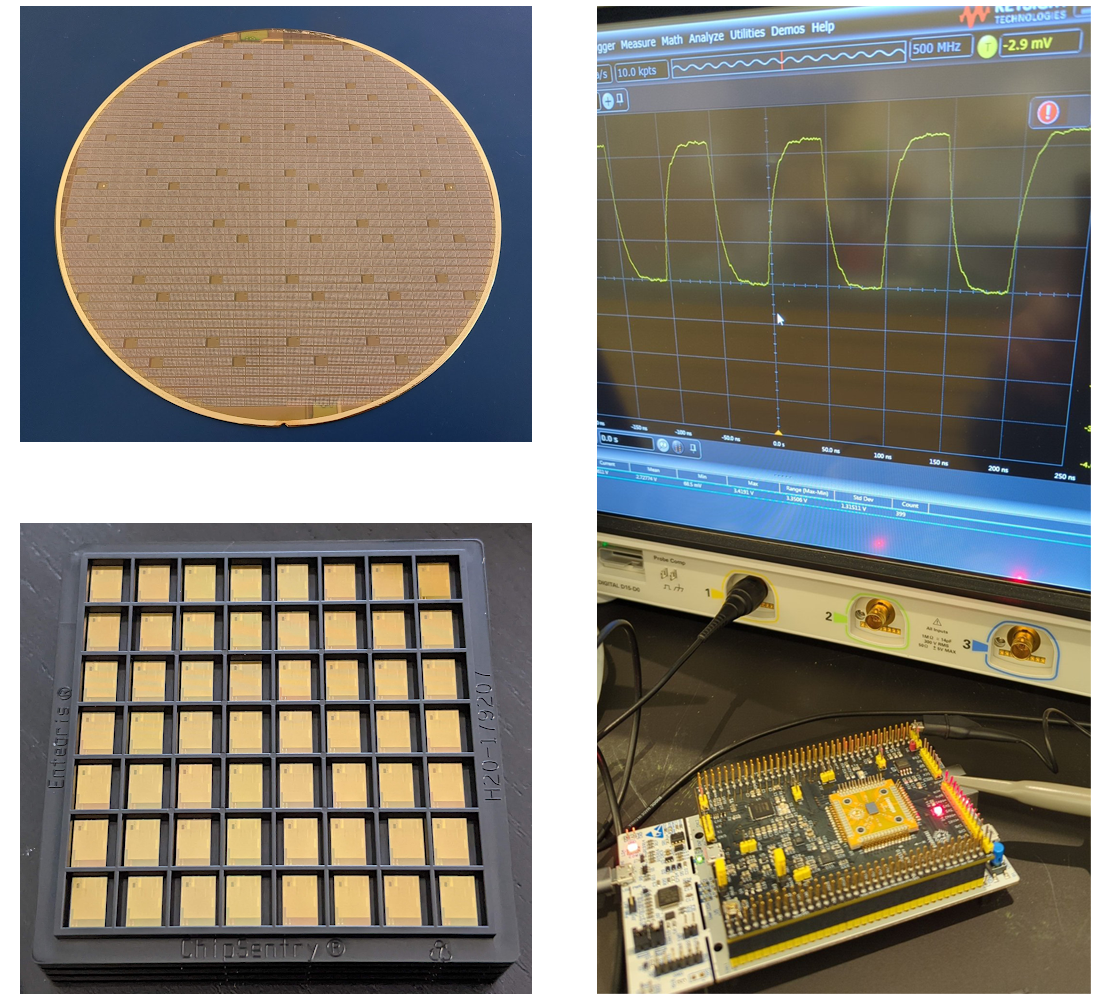
Pictures of a full wafer from the first SKY130 shuttle, a tray of bare dies, and a project bring-up from SKY130 MPW-2.
Results
The Open Source MPW Shuttle Program has been a success and we’re excited by the growth we’ve seen in this ecosystem. Since its inception, the program has launched eight shuttle runs on SKY130 and an initial test run on GF180MCU, the last of which are being packaged now. With 40 slots per shuttle, we’ve manufactured 360 designs out of over 600 submissions from 19 countries around the world.
The program has also fostered collaboration between the open source community and Google. We’ve learned valuable lessons from designers who participated in the program giving feedback and filing hundreds of bugs and pull requests. These have helped to improve each successive run and to make the platforms and tools more feature-complete.
We’ve just launched a new MPW-1 shuttle for GF180MCU in our partnership with Efabless. Submissions will be accepted until December 11th, targeting delivery in early 2024.
Next Steps
The open source silicon ecosystem is continuing to grow and evolve. After GF180 MPW-1 concludes, the open source SKY130 and GF180MCU PDKs will be joining the Linux Foundation’s CHIPS Alliance under a new working group to foster continued open source PDK development, and we expect future PDK releases will join as well. This will help with the transition to a broader governance model that enables more participation by industry, academia and the community, opening the possibility for larger shuttle programs with multiple sponsors as the ecosystem continues to grow.
Low-cost manufacturing options will continue to be available through this transition, both through commercial shuttle offerings like Efabless’ ChipIgnite program and also through educational efforts like TinyTapeout.
Thank you
Lastly, we’d like to thank the open source community. Your feedback has been invaluable to the success so far, and has helped to improve the tools and documentation to be more user-friendly. We have also seen contributions from the community in the form of hundreds of new and fully manufacturable designs, which have helped to expand the range and capabilities of open source hardware available to the community. We look forward to continuing partnerships to build a thriving ecosystem around open source silicon.
By Aaron Cunningham – Technical Program Manager, Core Hardware Tools
Posted by Dominik Mengelt – Developer Relations Engineer
During the last months we've been working hard to align the Google Pay user experience across Web and Android. We are committed to advancing all Google Pay surfaces progressively, and creating a more cohesive experience for your users. In addition, the Google Pay sheets for Android and Chrome on Android now use the latest Material 3 design system with Web to follow in early 2024.
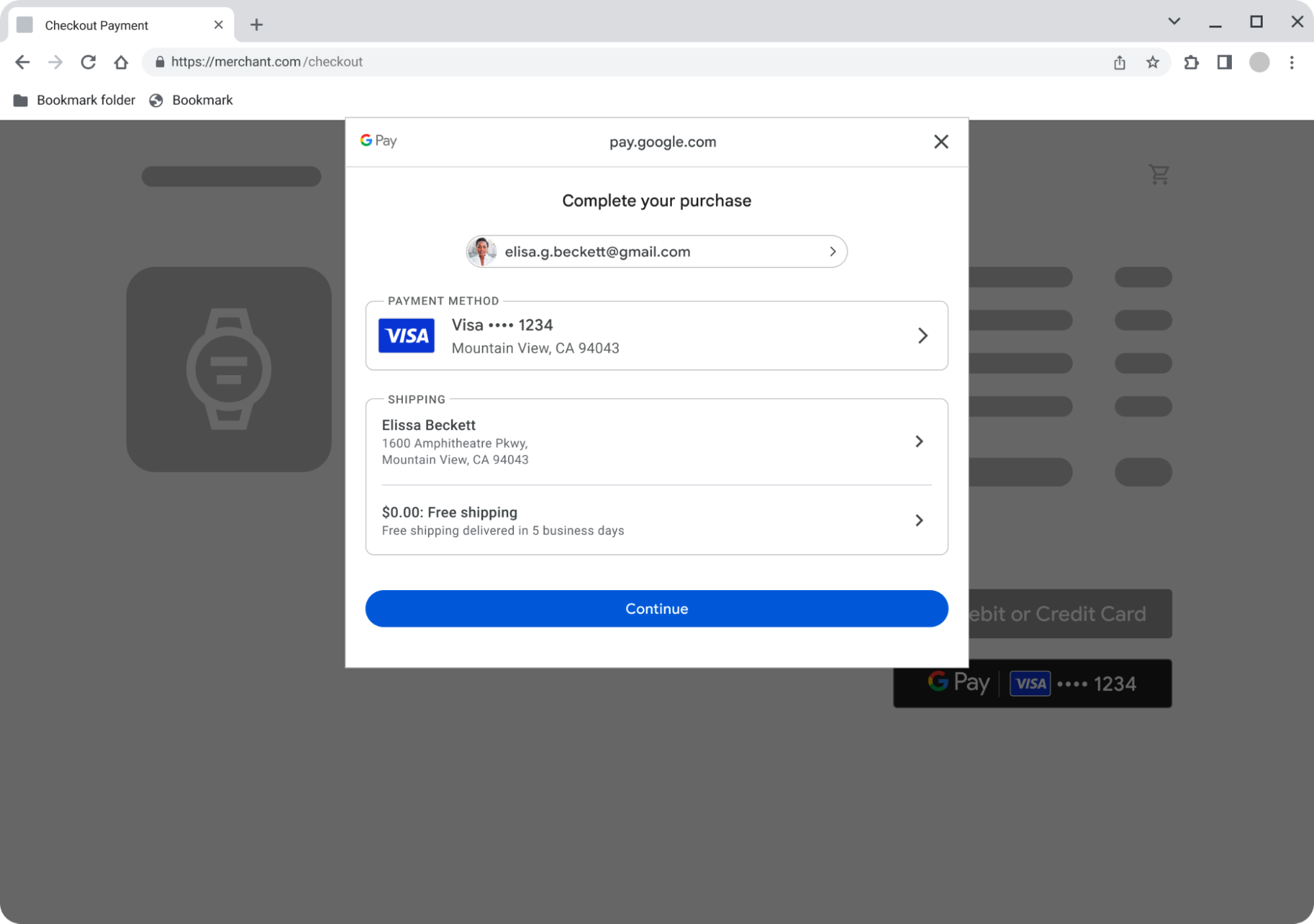
UX improvements on Android
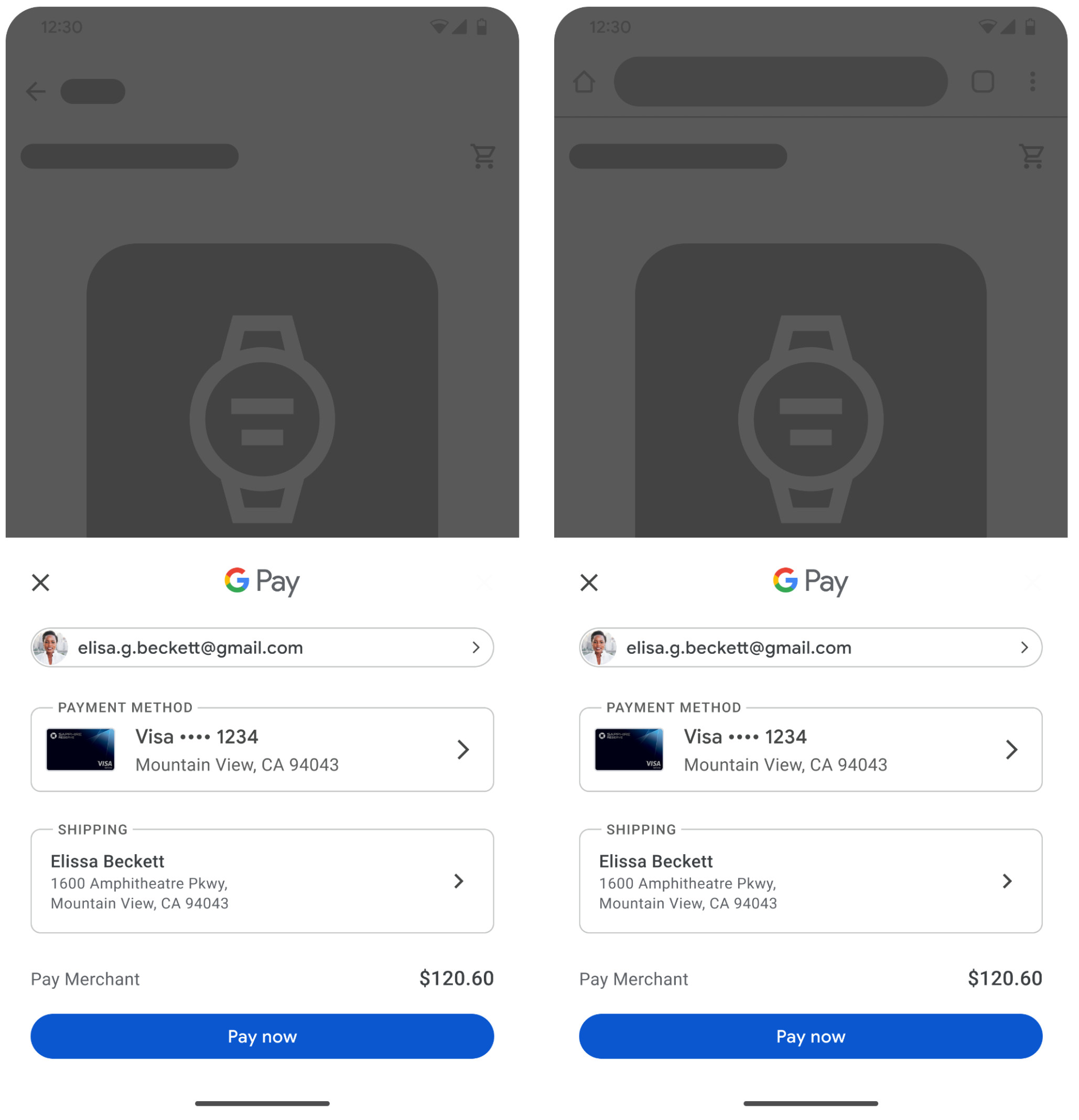
Aligning the bottom sheets on Android and Chrome for Android (Mobile Web) led to a ~2.5% increase in conversion rate and a ~39% reduction in errors for users using Google Pay with Chrome on Android[1].
Figure 1: The identical Google Pay bottom sheets for Android (left) and Chrome on Android (right)
A completely revamped Google Pay sheet on the Web
On the web we aligned the user experience to be the same as on Android. Additionally we gave the Payment Handler window a more minimalistic look. With these changes we are seeing a conversion rate increase of ~9%.[1]
Figure 2: Google Pay displayed inside the new minimalistic Payment Handler window
No changes required!
Whether you are a merchant integrating Google Pay on your own or through a PSP, you don’t need to make any changes. We've already rolled out these changes to most of our users. This means that your users are likely already benefiting from the new experience or will very soon. For certain features, for example dynamic price updates, Google Pay will temporarily show the previous user experience. We are actively working on migrating all features to benefit from the new updated design.
Getting started with Google Pay
Not yet using Google Pay? Take a look at the documentation to start integrating Google Pay today. Learn more about the integration by taking a look at our sample application for Android on GitHub or use one of our button components for your web integration. When you are ready, head over to the Google Pay & Wallet console and submit your integration for production access.
Follow @GooglePayDevs on X (formerly Twitter) for future updates. If you have questions, tag @GooglePayDevs and include #AskGooglePayDevs in your tweets.
Posted by Yasmine Evjen – Product Manager, and Florina Muntenescu – Developer Relations Engineer
Following its release in July of 2023, Meta’s Threads became the most rapidly downloaded app ever with over 100 million downloads in its first week. Meta created the new text-based social media platform as a place to build connections and have meaningful conversations. To ensure the app was set up for success at its release and into the future, Threads developers used Jetpack Compose, Android’s modern declarative toolkit for building UI.
An easier way to build UI with Jetpack Compose
Threads is built on top of existing code from its sister app Instagram, which uses Views for its UI development. After positive reports from other Android developers about Compose, and following internal testing and an assessment of the toolkit’s benefits, Threads engineers opted to build the all-new app from scratch using Compose. By using Compose, the team could move faster and better prepare the app for any future updates.
“We decided Jetpack Compose would be our target UI framework going forward,” said Richard Zadorozny, a software engineer at Threads. “We wanted to build the new app UI from scratch using Compose because it would enable us to move faster than refactoring a large application like Instagram.”
Even though most of Threads’ engineers had no prior experience using Compose, they found it easy to get started and learn the new toolkit. With Compose, Threads engineers built and shipped the app in only five months. This greatly exceeded the team’s speed expectations for developing a high-quality Android application — especially of this complexity and scale. The team attributes much of this speed to the flexibility and decoupling Compose provided.
Compose helped Threads engineers streamline the development of new product features. The modular nature of the toolkit let Threads developers iterate on the app as it evolved and teed up the app’s architecture for future development. Compose also helped engineers build user-friendly features that adhered to Material Design guidelines.
Going all in with Compose
Threads engineers developed almost all of the app’s surfaces using Compose. In the end, they built over 90% of Threads using Compose, including the app’s activity feed, navigation, search, profiles, onboarding page, shared element transitions, media viewer, settings, and more.
While Compose did mostly everything Threads engineers needed it to, it was still easy for them to interoperate with Views as necessary. They used Views for Threads’ videos and the media picker that’s available when creating a new post.
Compose provides modern APIs that ship directly with an app. Because of this, Threads engineers spent less time worrying about backward compatibility, missing features, or differing functionality between different versions of Android. Instead, they could focus their energy on developing a high-quality application.
“Compose’s design encourages a modular, plug-in approach to development,” said Richard. “Modifiers make all sorts of functionality inherently reusable, so you no longer have to subclass complicated ViewGroups or lump all sorts of logic into one place.”
The Threads team used Modifiers for the app’s custom click behaviors and its thread line illustration that appears on the left side of posts. Modifiers also allowed Threads developers to easily add the app’s branding to any elements and ensured they were properly aligned on-screen.
Threads engineers also ensured the app was ready for users across platforms at launch. That meant making sure Threads resizes to work on different devices, like large screens and foldables. The adaptive layouts Compose offers ensure an app responds properly to different screen sizes, orientations, and form factors. This made it easier for the Threads app to “just work” for configuration changes, according to Richard.
Compose is the ‘future’ of Android UI
Compose offered Threads developers an easier way to design and create UI while preparing the app’s architecture for the future. With its intuitive composables and modern declarative framework, Compose made end-to-end development smooth and gave Threads developers confidence that updating the app would be easy.
Given the positive results the team saw with the release of Threads, Meta plans to expand its use of Compose to some of Instagram’s most important surfaces, like the app’s main feed.
“It’s reached a point where Jetpack Compose can do almost everything you’ll need, and its modular nature makes it easy to make most of the changes you would need to fill the gaps,” said Richard. “I believe Compose is the future of Android UI development, and it’s just fun!”
Posted by Kateryna Semenova – Developer Relations Engineer, Diego Zavala and Gina Biernacki – Product Managers
Introducing Credential Manager
At Google, we are dedicated to improving the sign in experience across platforms for developers and users. For Android developers, we recently announced the public availability of Credential Manager as the future of authentication on Android. Credential Manager is a new Jetpack library designed to consolidate authentication types for Android developers into a single UI, reducing complexity for your applications while increasing usability. Credential Manager also supports passkeys, creating a unified interface for users and a single API for developers.
Instead of having to integrate with multiple identity providers, developers can now use Credential Manager as a single, unified authentication API. Credential Manager simplifies integration and makes it easier to develop authentication solutions that can work with all password managers, identity providers, and authentication methods.
Implementing Credential Manager with your Android applications will provide a single authentication experience for all Android users, integrated directly with the operating system and aligned with high-trust surfaces such as system login. We encourage all developers to migrate to Credential Manager.
Authentication APIs moving from Google Identity Services to Credential Manager on Android
Since these APIs are now generally available in Credential Manager, these individual APIs will be deprecated in Google Identity Services.
Removal of Smart Lock for Passwords
Smart Lock for Passwords, which was deprecated in 2022, will be removed from the Google Play Services SDK in November 2023. To minimize breaking changes that may impact existing integrations, all existing apps in the Play Store will continue to work. New app versions compiled with the new SDK will not be able to access the Smart Lock for Password API, so we encourage all developers to migrate to Credential Manager as soon as possible.
Get started with your migration to Credential Manager
All Android developers should plan their migration to the new Credential Manager API. To assist you in this process, read the following guides and resources:
UX guide for designing user experiences for passkeys on Android.
Share your feedback
We are excited to improve Android authentication with the launch of Credential Manager API, delivering a simple and streamlined UX for secure sign-in methods such as Sign in with Google.
We value your feedback and invite you to share your experience integrating with Credential Manager or any other feedback you might have:
Posted by Kateryna Semenova – Developer Relations Engineer, Diego Zavala and Gina Biernacki – Product Managers
Introducing Credential Manager
At Google, we are dedicated to improving the sign in experience across platforms for developers and users. For Android developers, we recently announced the public availability of Credential Manager as the future of authentication on Android. Credential Manager is a new Jetpack library designed to consolidate authentication types for Android developers into a single UI, reducing complexity for your applications while increasing usability. Credential Manager also supports passkeys, creating a unified interface for users and a single API for developers.
Instead of having to integrate with multiple identity providers, developers can now use Credential Manager as a single, unified authentication API. Credential Manager simplifies integration and makes it easier to develop authentication solutions that can work with all password managers, identity providers, and authentication methods.
Implementing Credential Manager with your Android applications will provide a single authentication experience for all Android users, integrated directly with the operating system and aligned with high-trust surfaces such as system login. We encourage all developers to migrate to Credential Manager.
Authentication APIs moving from Google Identity Services to Credential Manager on Android
Since these APIs are now generally available in Credential Manager, these individual APIs will be deprecated in Google Identity Services.
Removal of Smart Lock for Passwords
Smart Lock for Passwords, which was deprecated in 2022, will be removed from the Google Play Services SDK in November 2023. To minimize breaking changes that may impact existing integrations, all existing apps in the Play Store will continue to work. New app versions compiled with the new SDK will not be able to access the Smart Lock for Password API, so we encourage all developers to migrate to Credential Manager as soon as possible.
Get started with your migration to Credential Manager
All Android developers should plan their migration to the new Credential Manager API. To assist you in this process, read the following guides and resources:
UX guide for designing user experiences for passkeys on Android.
Share your feedback
We are excited to improve Android authentication with the launch of Credential Manager API, delivering a simple and streamlined UX for secure sign-in methods such as Sign in with Google.
We value your feedback and invite you to share your experience integrating with Credential Manager or any other feedback you might have:
 Posted by Dave Burke, VP of Engineering
Posted by Dave Burke, VP of Engineering




 Posted by
Posted by 




























 Posted by Sharbani Roy – Senior Director, Product Management, Google
Posted by Sharbani Roy – Senior Director, Product Management, Google


















 Posted by Joshua Hale – Software Engineer
Posted by Joshua Hale – Software Engineer






 Posted by Dominik Mengelt – Developer Relations Engineer
Posted by Dominik Mengelt – Developer Relations Engineer

 Posted by Yasmine Evjen – Product Manager, and Florina Muntenescu – Developer Relations Engineer
Posted by Yasmine Evjen – Product Manager, and Florina Muntenescu – Developer Relations Engineer



 Posted by Kateryna Semenova – Developer Relations Engineer, Diego Zavala and Gina Biernacki – Product Managers
Posted by Kateryna Semenova – Developer Relations Engineer, Diego Zavala and Gina Biernacki – Product Managers