 Posted by Geoffrey Boullanger – Senior Software Engineer, Shandor Dektor – Sensors Algorithms Engineer, Martin Frassl and Benjamin Joseph – Technical Leads and Managers
Posted by Geoffrey Boullanger – Senior Software Engineer, Shandor Dektor – Sensors Algorithms Engineer, Martin Frassl and Benjamin Joseph – Technical Leads and Managers

Device orientation, or attitude, is used as an input signal for many use cases: virtual or augmented reality, gesture detection, or compass and navigation – any time the app needs the orientation of a device in relation to its surroundings. We’ve heard from developers that orientation is challenging to get right, with frequent user complaints when orientation is incorrect. A maps app should show the correct direction to walk towards when a user is navigating to an exciting restaurant in a foreign city!
The Fused Orientation Provider (FOP) is a new API in Google Play services that provides quality and consistent device orientation by fusing signals from accelerometer, gyroscope and magnetometer.
Although currently the Android Rotation Vector already provides device orientation (and will continue to do so), the new FOP provides more consistent behavior and high performance across devices. We designed the FOP API to be similar to the Rotation Vector to make the transition as easy as possible for developers.
In particular, the Fused Orientation Provider
- Provides a unified implementation across devices: an API in Google Play services means that there is no implementation variance across different manufacturers. Algorithm updates can be rolled out quickly and independent of Android platform updates;
- Directly incorporates local magnetic declination, if available;
- Compensates for lower quality sensors and OEM implementations (e.g., gyro bias, sensor timing).
In certain cases, the FOP returns values piped through from the AOSP Rotation Vector, adapted to incorporate magnetic declination.
How to use the FOP API
Device orientation updates can be requested by creating and sending a DeviceOrientationRequest object, which defines some specifics of the request like the update period.
The FOP then outputs a stream of the device’s orientation estimates as quaternions. The orientation is referenced to geographic north. In cases where the local magnetic declination is not known (e.g., location is not available), the orientation will be relative to magnetic north.
In addition, the FOP provides the device’s heading and accuracy, which are derived from the orientation estimate. This is the same heading that is shown in Google Maps, which uses the FOP as well. We recently added changes to better cope with magnetic disturbances, to improve the reliability of the cone for Google Maps and FOP clients.
The update rate can be set by requesting a specific update period. The FOP does not guarantee a minimum or maximum update rate. For example, the update rate can be faster than requested if another app has a faster parallel request, or it can be slower as requested if the device doesn’t support the high rate.
For full specification of the API, please consult the API documentation:
Example usage (Kotlin)
package ...
import android.content.Context
import com.google.android.gms.location.DeviceOrientation
import com.google.android.gms.location.DeviceOrientationListener
import com.google.android.gms.location.DeviceOrientationRequest
import com.google.android.gms.location.FusedOrientationProviderClient
import com.google.android.gms.location.LocationServices
import com.google.common.flogger.FluentLogger
import java.util.concurrent.Executors
class Example(context: Context) {
private val logger: FluentLogger = FluentLogger.forEnclosingClass()
// Get the FOP API client
private val fusedOrientationProviderClient: FusedOrientationProviderClient =
LocationServices.getFusedOrientationProviderClient(context)
// Create an FOP listener
private val listener: DeviceOrientationListener =
DeviceOrientationListener { orientation: DeviceOrientation ->
// Use the orientation object returned by the FOP, e.g.
logger.atFinest().log("Device Orientation: %s deg", orientation.headingDegrees)
}
fun start() {
// Create an FOP request
val request =
DeviceOrientationRequest.Builder(DeviceOrientationRequest.OUTPUT_PERIOD_DEFAULT).build()
// Create (or re-use) an Executor or Looper, e.g.
val executor = Executors.newSingleThreadExecutor()
// Register the request and listener
fusedOrientationProviderClient
.requestOrientationUpdates(request, executor, listener)
.addOnSuccessListener { logger.atInfo().log("FOP: Registration Success") }
.addOnFailureListener { e: Exception? ->
logger.atSevere().withCause(e).log("FOP: Registration Failure")
}
}
fun stop() {
// Unregister the listener
fusedOrientationProviderClient.removeOrientationUpdates(listener)
}
}
Technical background
The Android ecosystem has a wide variety of system implementations for sensors. Devices should meet the criteria in the Android compatibility definition document (CDD) and must have an accelerometer, gyroscope, and magnetometer available to use the fused orientation provider. It is preferable that the device vendor implements the high fidelity sensor portion of the CDD.
Even though Android devices adhere to the Android CDD, recommended sensor specifications are not tight enough to fully prevent orientation inaccuracies. Examples of this include magnetometer interference from internal sources, and delayed, inaccurate or nonuniform sensor sampling. Furthermore, the environment around the device usually includes materials that distort the geomagnetic field, and user behavior can vary widely. To deal with this, the FOP performs a number of tasks in order to provide a robust and accurate orientation:
- Synchronize sensors running on different clocks and delays;
- Compensate for the hard iron offset (magnetometer bias);
- Fuse accelerometer, gyroscope, and magnetometer measurements to determine the orientation of the device in the world;
- Compensate for gyro drift (gyro bias) while moving;
- Produce a realistic estimate of the compass heading accuracy.
We have validated our algorithms on comprehensive test data to provide a high quality result on a wide variety of devices.
Availability and limitations
The Fused Orientation Provider is available on all devices running Google Play services on Android 5 (Lollipop) and above. Developers need to add the dependency play-services-location:21.2.0 (or above) to access the new API.
Permissions
No permissions are required to use the FOP API. The output rate is limited to 200Hz on devices running API level 31 (Android S) or higher, unless the android.permissions.HIGH_SAMPLING_RATE_SENSORS permission was added to your Manifest.xml.
Power consideration
Always request the longest update period (lowest frequency) that is sufficient for your use case. While more frequent FOP updates can be required for high precision tasks (for example Augmented Reality), it comes with a power cost. If you do not know which update period to use, we recommend starting with DeviceOrientationRequest::OUTPUT_PERIOD_DEFAULT as it fits most client needs.
Foreground behavior
FOP updates are only available to apps running in the foreground.
Copyright 2023 Google LLC.
SPDX-License-Identifier: Apache-2.0

 Posted by Yafit Becher – Product Manager
Posted by Yafit Becher – Product Manager



 Posted by Max Saltonstall – Developer Relations Engineer
Posted by Max Saltonstall – Developer Relations Engineer

 Posted by
Posted by 



 Posted by Ali Satter – AI Lead, Roman Nurik – Design Lead
Posted by Ali Satter – AI Lead, Roman Nurik – Design Lead

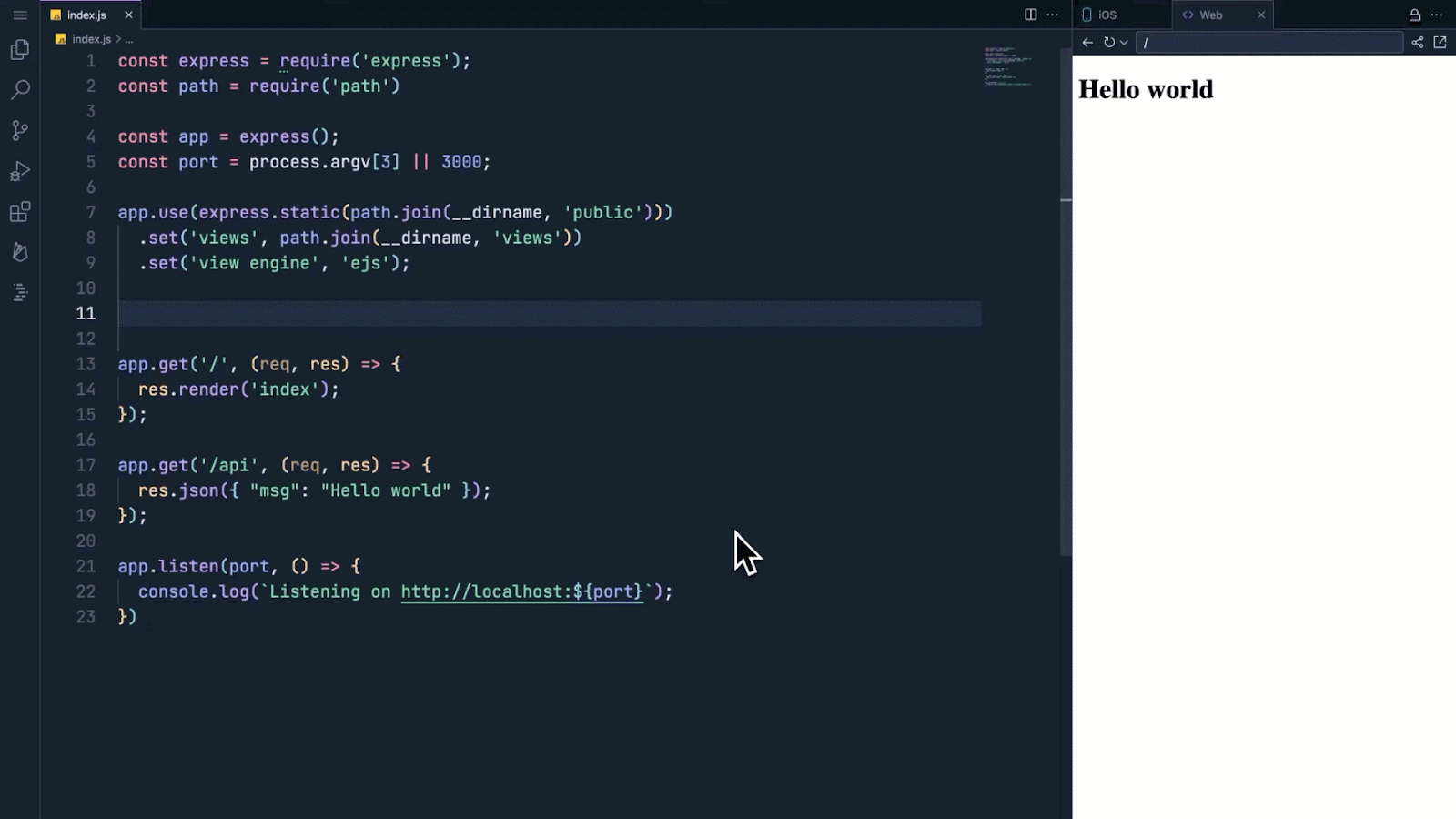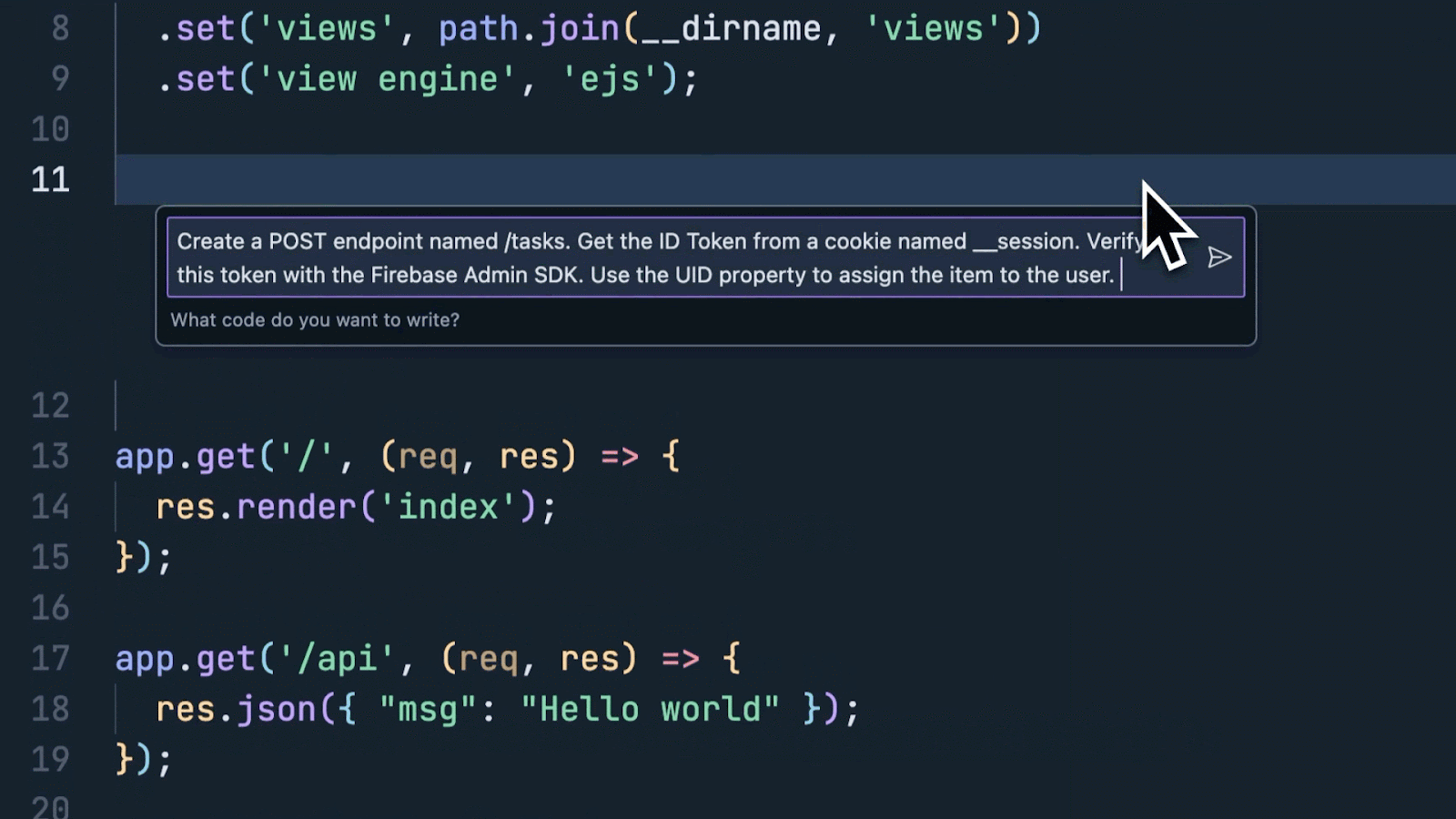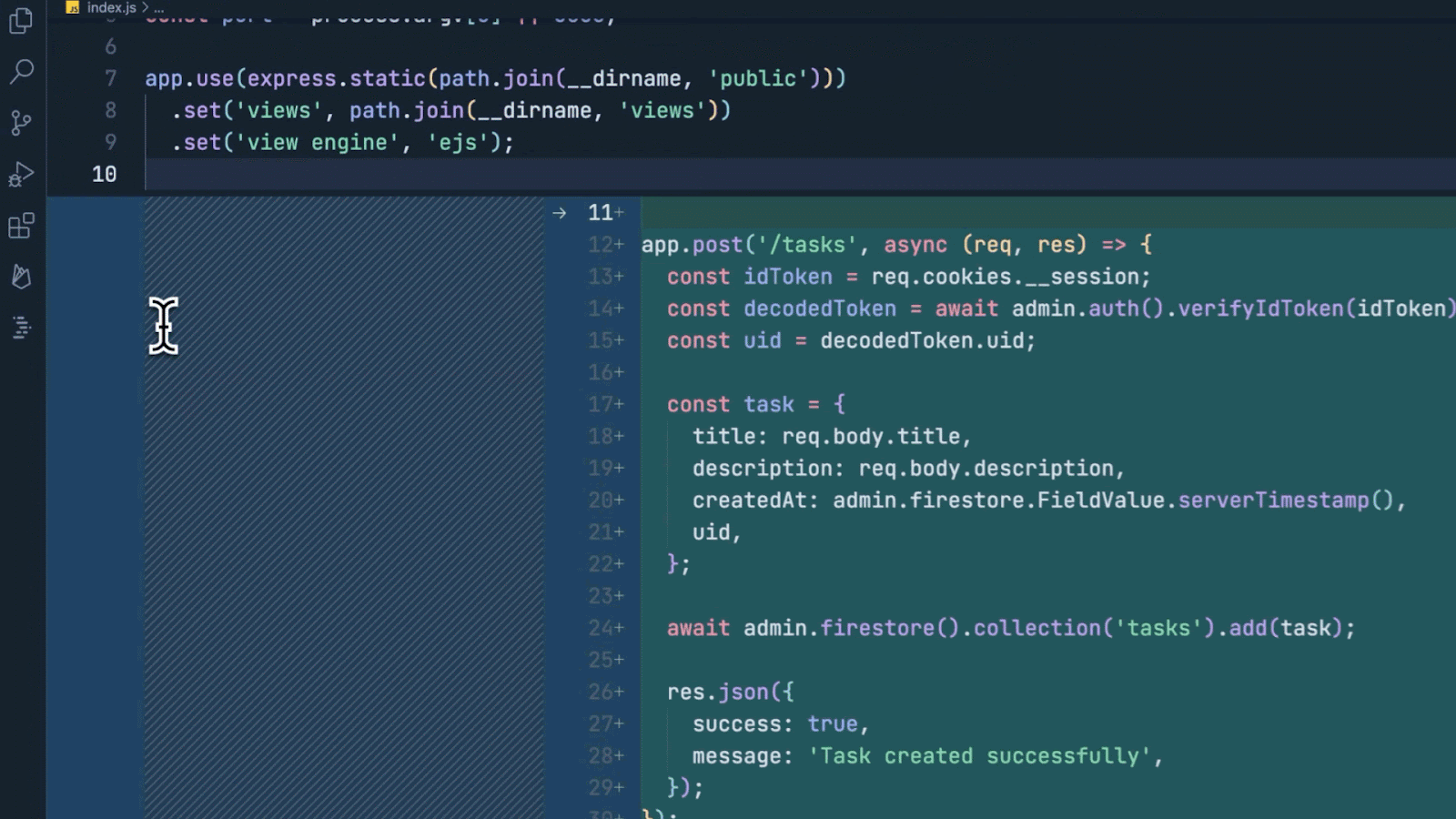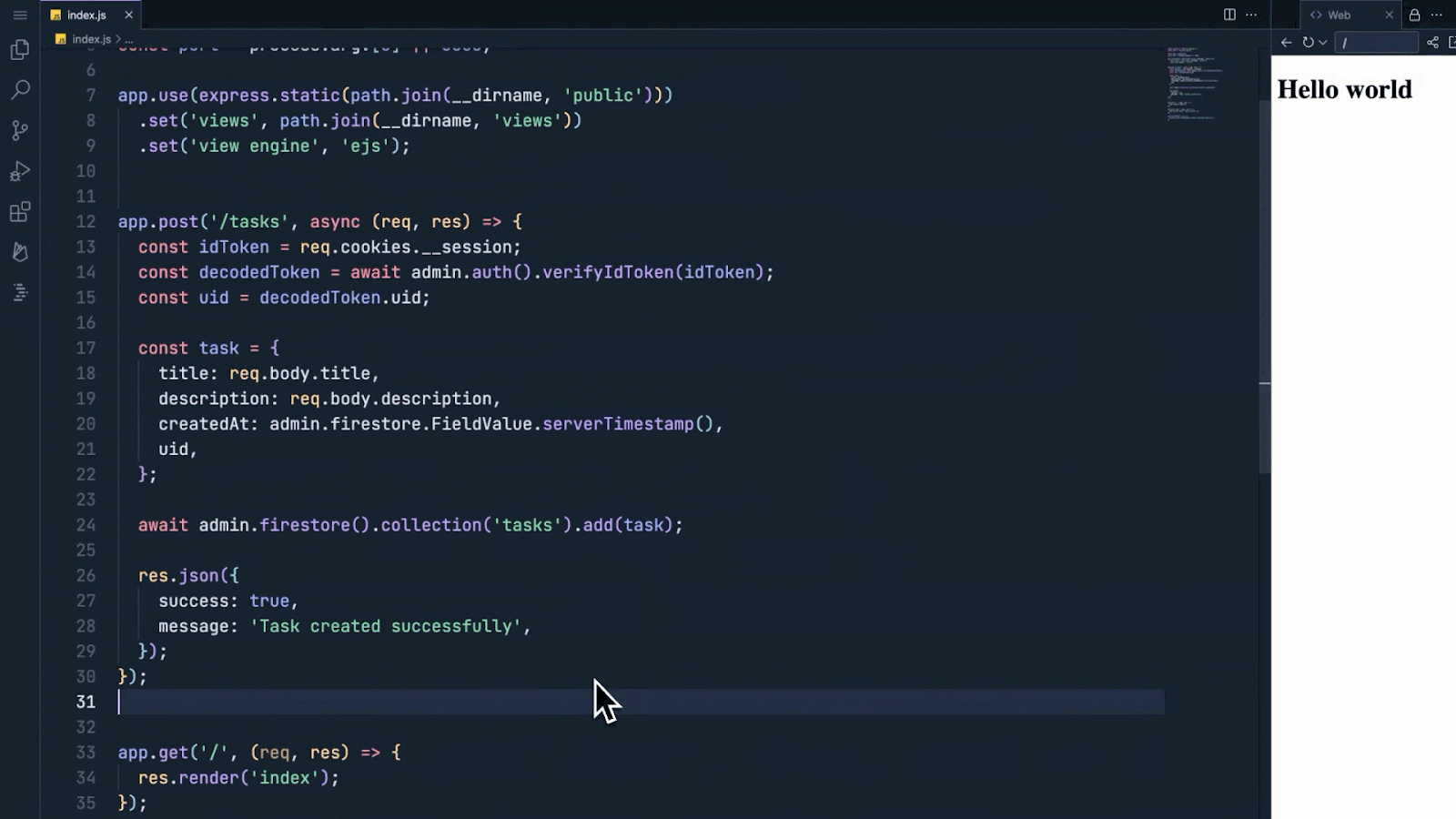

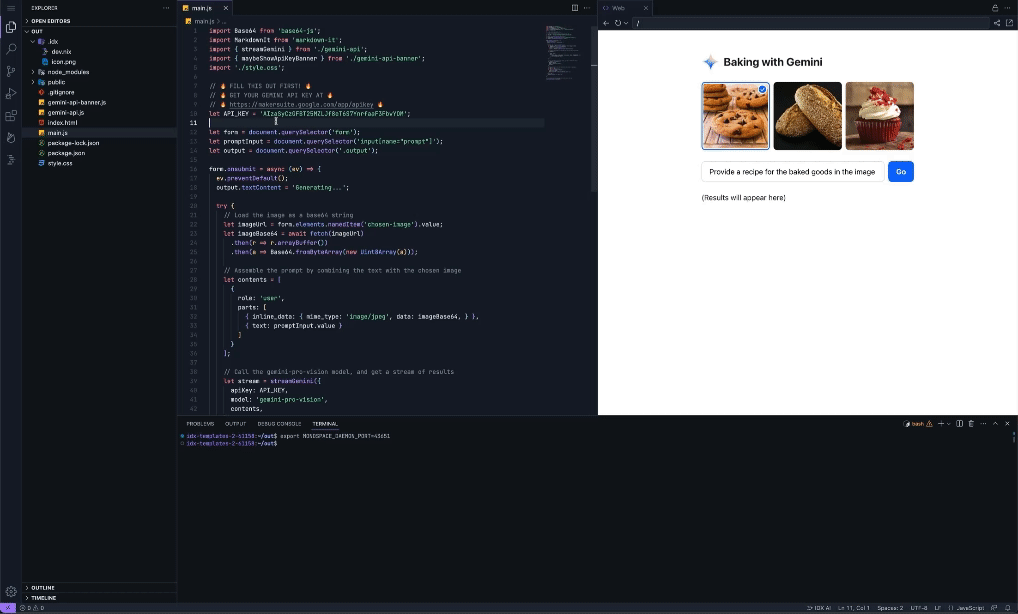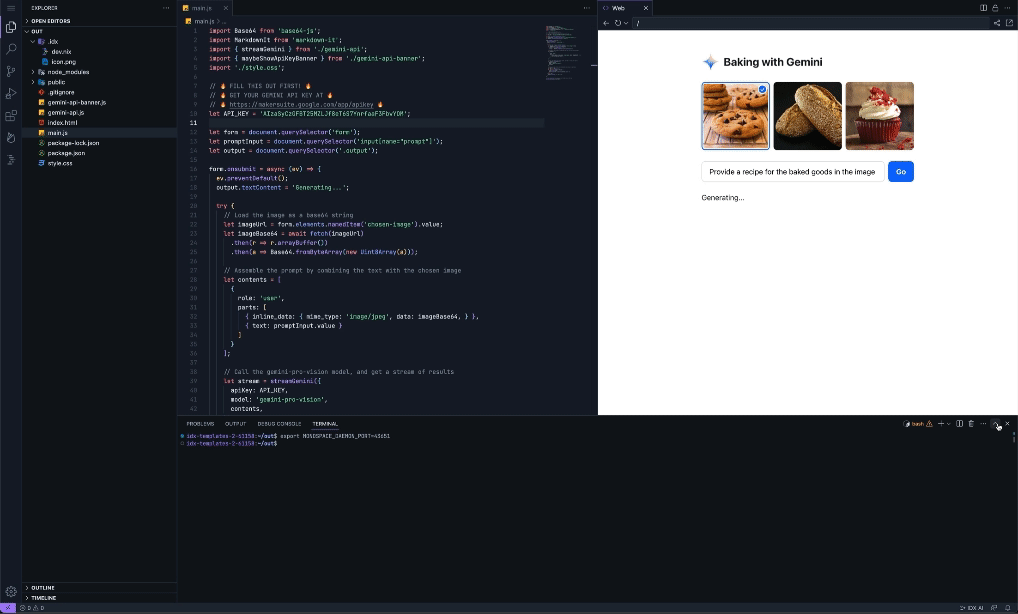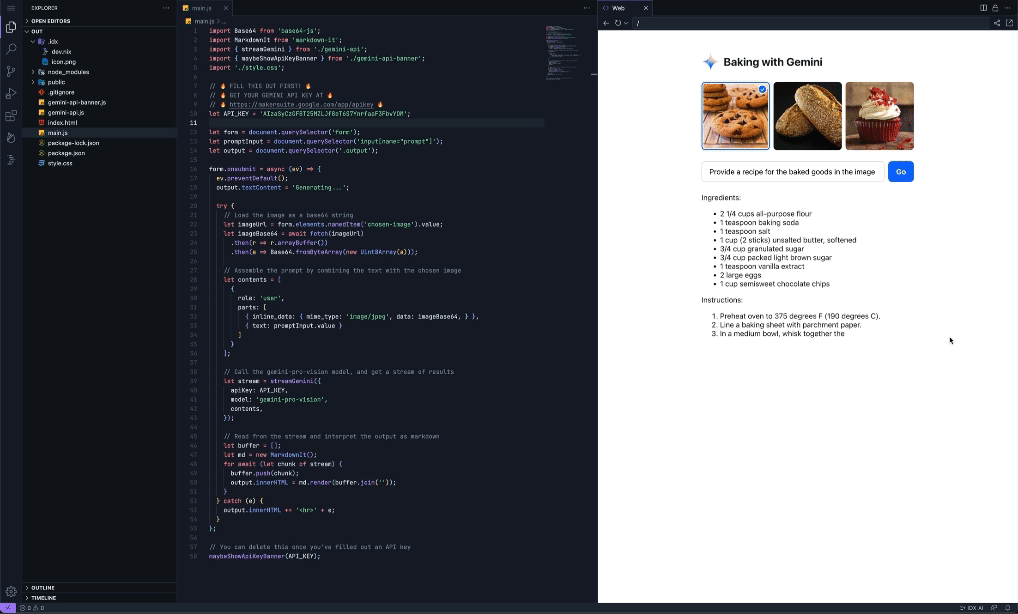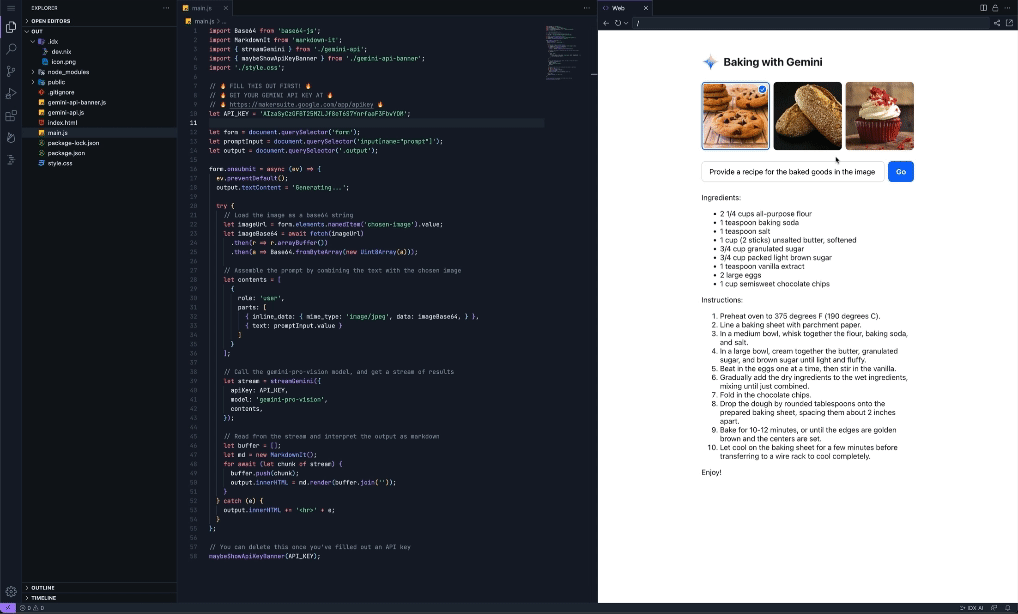
 Posted by Jaclyn Konzelmann and Wiktor Gworek – Google Labs
Posted by Jaclyn Konzelmann and Wiktor Gworek – Google Labs



 Posted by Rachel Francois, Global Program Manager, Google Developer Student Clubs
Posted by Rachel Francois, Global Program Manager, Google Developer Student Clubs




 Posted by Gina Biernacki, Product Manager
Posted by Gina Biernacki, Product Manager
