
Posted by Wesley Chun (@wescpy), Developer Advocate, Google Cloud
Introduction and background
The Serverless Migration Station series is aimed at helping developers modernize their apps running one of Google Cloud's serverless platforms. The preceding (Migration Module 18) video demonstrates how to add use of App Engine's Task Queue pull tasks service to a Python 2 App Engine sample app. Today's Module 19 video picks up from where that leaves off, migrating that pull task usage to Cloud Pub/Sub.
Moving away from proprietary App Engine services like Task Queue makes apps more portable, giving them enough flexibility to:
- Run on 2nd generation App Engine runtimes
- Shift across to other serverless platforms, like Cloud Functions or Cloud Run (with or without Docker)
- Move to VM-based services like GKE or Compute Engine, or to other compute platforms
Understanding the migrations
Module 19 consists of implementing three different migrations on the Module 18 sample app:
- Migrate from App Engine NDB to Cloud NDB
- Migrate from App Engine Task Queue pull tasks to Cloud Pub/Sub
- Migrate from Python 2 to Python (2 and) 3
The NDB to Cloud NDB migration is identical to the Module 2 migration content, so it's not covered in-depth in Module 19. The original app was designed to be Python 2 and 3 compatible, so there's no work there either. Module 19 boils down to three key updates:
- Setup: Enable APIs and create Pub/Sub Topic & Subscription
- How work is created: Publish Pub/Sub messages instead of adding pull tasks
- How work is processed: Pull messages instead of leasing tasks
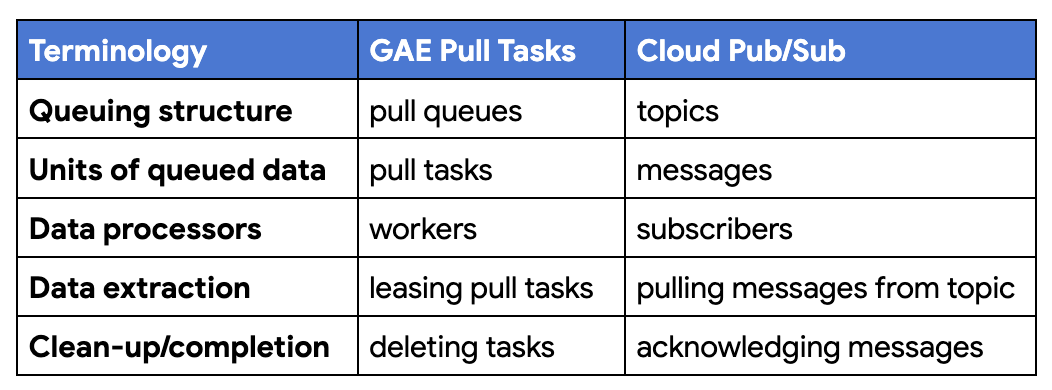 |
| Terminology differences between App Engine pull tasks and Cloud Pub/Sub |
- With Pull Queues, work is created in pull queues while work is sent to Pub/Sub topics
- Task Queue pull tasks are called messages in Pub/Sub
- With Task Queues, workers access pull tasks; with Pub/Sub, subscribers receive messages
- Leasing a pull task is the same as pulling a message from a Pub/Sub topic via a subscription
- Deleting a task from a pull queue when you're done is analogous to successfully acknowledging a Pub/Sub message
 |
| Migration from App Engine Task Queue pull tasks to Cloud Pub/Sub |
Wrap-up
Module 19 features a migration of App Engine pull tasks to Cloud Pub/Sub, but developers should note that Pub/Sub itself is not based on pull tasks. It is a fully-featured asynchronous, scalable messaging service that has many more features than the pull functionality provided by Task Queue. For example, Pub/Sub has other features like streaming to BigQuery and push functionality. Pub/Sub push operates differently than Task Queue push tasks, hence why we recommend push tasks be migrated to Cloud Tasks instead (see Module 8). For more information on all of its features, see the Pub/Sub documentation. Because Cloud Tasks doesn't support pull functionality, we turn to Pub/Sub instead for pull task users.
While we recommend users move to the latest offerings from Google Cloud, neither of those migrations are required, and should you opt to do so, can do them on your own timeline. In Fall 2021, the App Engine team extended support of many of the bundled services to 2nd generation runtimes (that have a 1st generation runtime), meaning you don't have to migrate to standalone Cloud services before porting your app to Python 3. You can continue using Task Queue in Python 3 so long as you retrofit your code to access bundled services from next-generation runtimes.
If you're using other App Engine legacy services be sure to check out the other Migration Modules in this series. All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, the Cloud team is working on covering other language runtimes, so stay tuned. For additional video content, check out our broader Serverless Expeditions series.


![Adding App Engine Task Queue pull task usage to sample app showing 'Before'[Module 1] on the left and 'After' [Module 18] with altered code on the right](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjRVGVYc9fl4xI9xUpOUaAwXup8p-wUf5nbKllG7OYJSVAYSPVCGw7DU8EbMoTE3kBBgVZiICFvsn_7fHP2oymA_1ASKBrAE2Qt8PzCGAAkK7_WnyvAIEMKQUrxP8FSz3tGykLrlu9nyluN5vgEPrWZrBqIAalCoRmos169g9m9NHz3cGqQyych9eEG/s1600/Screen%20Shot%202022-11-29%20at%205.19.28%20PM.png)




