
Posted by Wesley Chun (@wescpy), Developer Advocate, Google Cloud
Introduction and background
In our ongoing Serverless Migration Station mini-series aimed at helping developers modernize their serverless applications, one of the key objectives for Google App Engine developers is to upgrade to the latest language runtimes, such as from Python 2 to 3 or Java 8 to 17. Another goal is to demonstrate how to move away from App Engine legacy APIs (now referred to as "bundled services") to Cloud standalone replacement services. Once this has been accomplished, apps are much more portable, making them flexible enough to:
- Run on the 2nd generation App Engine service
- Shift across to other serverless platforms, like Cloud Functions or Cloud Run (with or without Docker), or
- Move to VM-based services like GKE or Compute Engine, or to other compute platforms
Developers building web apps that provide for user uploads or serve large files like videos or audio clips can benefit from convenient "blob" storage backing such functionality, and App Engine's Blobstore serves this specific purpose. As mentioned above, moving away from proprietary App Engine services like Blobstore makes user apps more portable. The original underlying Blobstore infrastructure eventually merged with the Cloud Storage service anyway, so it's logical to move completely to Cloud Storage when convenient, and this content is inform on this process.
Blobstore for Python 2 has a dependency on webapp, the original App Engine micro framework replaced by webapp2 when the Python 2.5 runtime was deprecated in favor of 2.7. Because the Blobstore handlers were left "stuck" in webapp, it's better to start with a more generic webapp2 app prior to a Flask migration. This isn't an issue because we modernize this app completely in Module 16 by:
- Migrating from
webapp2(andwebapp) to Flask - Migrating from App Engine NDB to Cloud NDB
- Migrating from App Engine Blobstore to Cloud Storage
- Migrating from Python 2 to Python (2 and) 3
We'll go into more detail in Module 16, but it suffices to say that once those migrations are complete, the resulting app becomes portable enough for all the possibilities mentioned at the top.
Adding use of Blobstore
The original sample app registers individual web page "visits," storing visitor information such as the IP address and user agent, then displaying the most recent visits to the end-user. In today's video, we add one additional feature: allowing visitors to optionally augment their visits with a file artifact, like an image. Instead of registering a visit immediately, the visitor is first prompted to provide the artifact, as illustrated below.
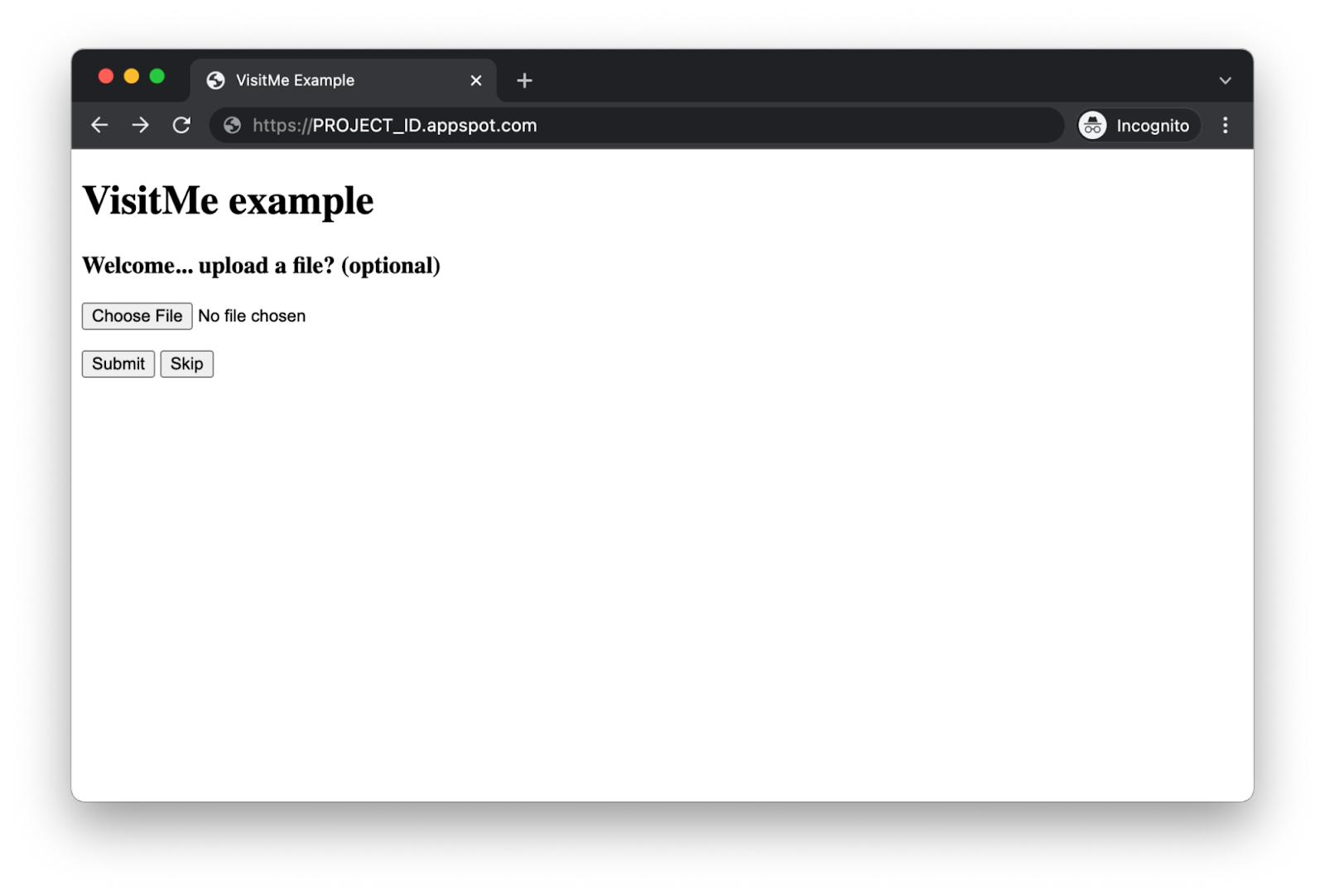 |
The updated sample app's new artifact prompt page |
The end-user can choose to do so or click a "Skip" button to opt-out. Once this process is complete, the same most recent visits page is then rendered, with one difference: an additional link to view a visit artifact if one's available.
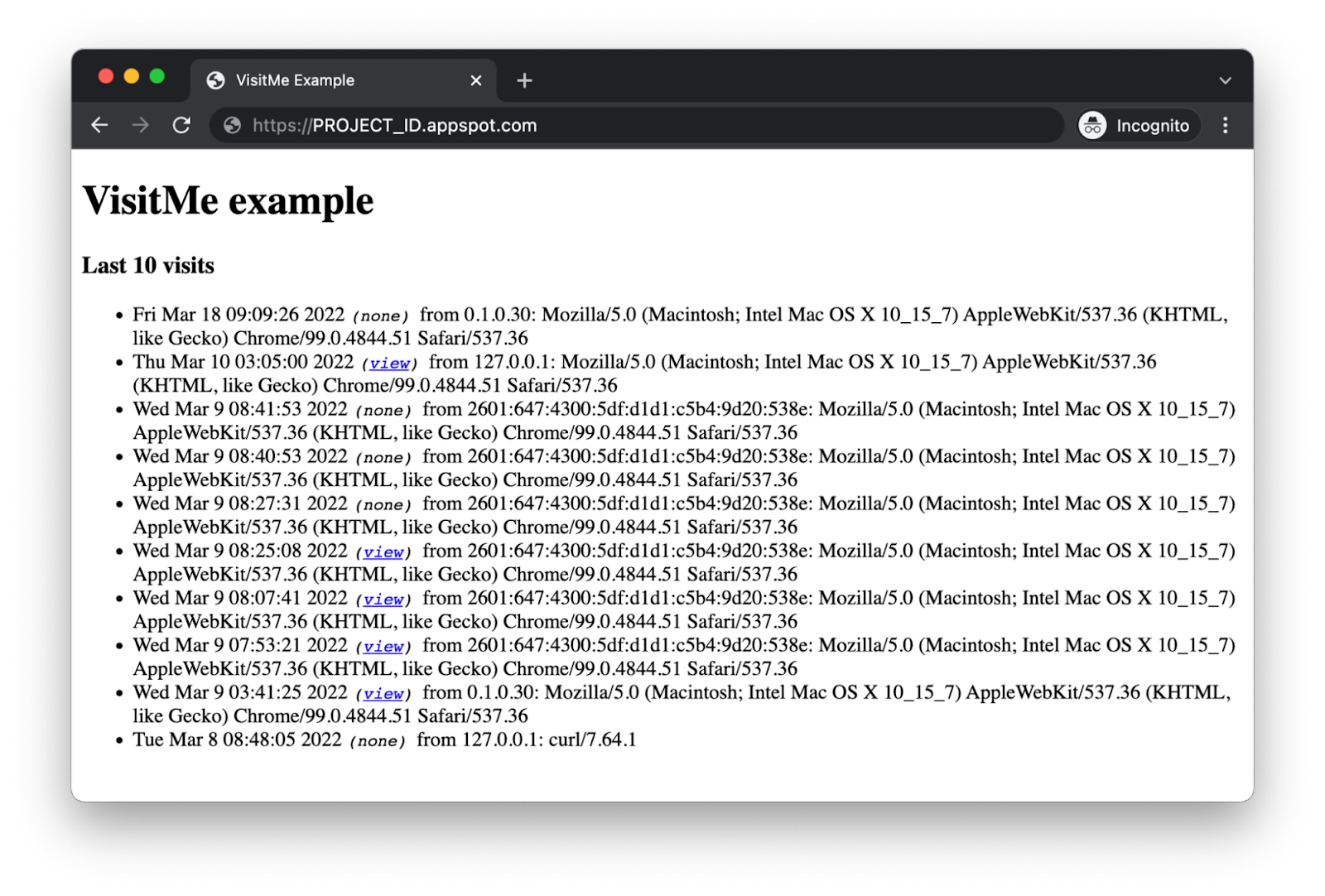 |
The sample app's updated most recent visits page |
Below is pseudocode representing the core part of the app that was altered to add Blobstore usage, namely new upload and download handlers as well as the changes required of the main handler. Upon the initial GET request, the artifact form is presented. When the user submits an artifact or skips, the upload handler POSTs back to home ("/") via an HTTP 307 to preserve the verb, and then the most recent visits page is rendered as expected. There, if the end-user wishes to view a visit artifact, they can click a "view" link where the download handler which fetches and returns the corresponding artifact from the Blobstore service, otherwise an HTTP 404 if the artifact wasn't found. The bolded lines represent the new or altered code.
 |
Adding App Engine Blobstore usage to sample app |
Wrap-up
In this "migration," we added Blobstore usage to support visit artifacts to the Module 0 baseline sample app and arrived at the finish line with the Module 15 sample app. To get hands-on experience doing it yourself, do the codelab by hand and follow along with the video. Then you'll be ready to upgrade to Cloud Storage should you choose to do so.
In Fall 2021, the App Engine team extended support of many of the bundled services to 2nd generation runtimes (that have a 1st generation runtime), meaning you are no longer required to migrate to Cloud Storage when porting your app to Python 3. You can continue using Blobstore in your Python 3 app so long as you retrofit the code to access bundled services from next-generation runtimes.
If you do want to move to Cloud Storage, Module 16 is next. You can also try its codelab to get a head start. All Serverless Migration Station content (codelabs, videos, source code [when available]) can be accessed at its open source repo. While our content initially focuses on Python users, the Cloud team is working on covering other language runtimes, so stay tuned. For additional video content, check out our broader Serverless Expeditions series.






