world’s news media in nearly every country in over 100 languages to identify the events and narratives driving our global society.
This past September I published into Google BigQuery a massive new public dataset of metadata from 3.5 million digitized English-language books dating back more than two centuries (1800-2015), along with the full text of 1 million of these books. The archive, which draws from the English-language public domain book collections of the Internet Archive and HathiTrust, includes full publication details for every book, along with a wide array of computed content-based data. The entire archive is available as two public BigQuery datasets, and there’s a growing collection of sample queries to help users get started with the collection. You can even map two centuries of books with a single line of SQL.
What did it look like to process 3.5 million books? Data-mining and creating a public archive of 3.5 million books is an example of an application perfectly suited to the cloud, in which a large amount of specialized processing power is needed for only a brief period of time. Here are the five main steps that I took to make the invaluable learnings of millions of books more easily and speedily accessible in the cloud:
- The project began with a single 8-core Google Compute Engine (GCE) instance with a 2TB SSD persistent disk that was used to download the 3.5 million books. I downloaded the books to the instance’s local disk, unzipped them, converted them into a standardized file format, and then uploaded them to Google Cloud Storage (GCS) in large batches, using the composite objects and parallel upload capability of GCS. Unlike traditional UNIX file systems, GCS performance does not degrade with large numbers of small files in a single directory, so I could upload all 3.5 million files into a common set of directories.

Figure 1: Visualization of two centuries of books - Once all books had been downloaded and stored into GCS, I launched ten 16-core High Mem (100GB RAM) GCE instances (160 cores total) to process the books, each with a 50GB persistent SSD root disk to achieve faster IO over traditional persistent disks. To launch all ten instances quickly, I launched the first instance and configured that with all of the necessary software libraries and tools, then created and used a disk snapshot to rapidly clone the other nine with just a few clicks. Each of the ten compute instances would download a batch of 100 books at a time to process from GCS.
- Once the books had been processed, I uploaded back into GCS all of the computed metadata. In this way, GCS served as a central storage fabric connecting the compute nodes. Remarkably, even in worst-case scenarios when all 160 processors were either downloading new batches of books from GCS or uploading output files back to GCS in parallel, there was no measurable performance degradation.
- With the books processed, I deleted the ten compute instances and launched a single 32-core instance with 200GB of RAM, a 10TB persistent SSD disk, and four 375GB direct-attached Local SSD Disks. I used this to reassemble the 3.5 million per-book output files into single output files, tab-delimited with data available for each year, merging in publication metadata and other information about each book. Disk IO of more than 750MB/s was observed on this machine.
- I then uploaded the final per-year output files to a public GCS directory with web downloading enabled, allowing the public to download the files.

The entire project, from start to finish, took less than two weeks, a good portion of which consisted of human verification for issues with the publication metadata. This is significant because previous attempts to process even a subset of the collection on a modern HPC supercluster had taken over one month and completed only a fraction of the number of books examined here. The limiting factor was always the movement of data: transferring terabytes of books and their computed metadata across hundreds of processors.
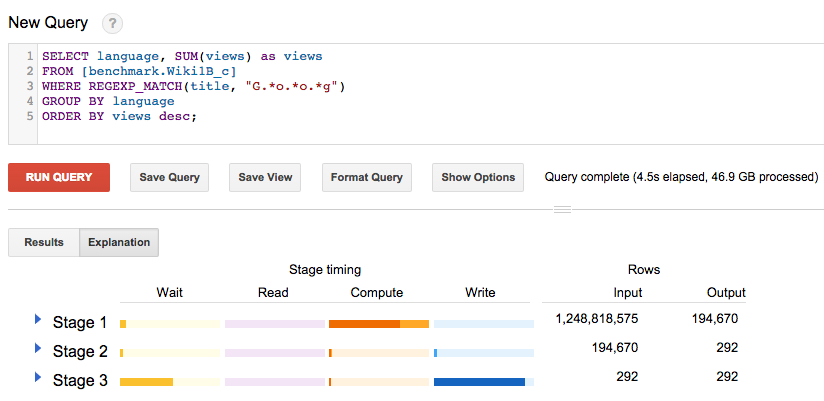
This is where Google’s cloud offerings shine, seemingly purpose-built for data-first computing. In just two weeks, I was able to process 3.5 million books, spinning up a cluster of 160 cores and 1TB of RAM, followed by a single machine with 32 cores, 200GB of RAM, 10TB of SSD disk and 1TB of direct-attached scratch SSD disk. I was able to make the final results publicly accessible through BigQuery at query speeds of over 45.5GB/s.
You can access the entire collection today in BigQuery, explore sample queries, and read more technical detail about the processing pipeline on the GDELT Blog.
I’d like to thank Google, Clemson University, the Internet Archive, HathiTrust, and OCLC in making this project possible, along with all of the contributing libraries and digitization sponsors that have made these digitized books available.
- Posted by Kalev Leetaru, founder of The GDELT Project