 Posted by Brian Craft, Satish Shreenivasa, Huikun Zhang, Manisha Arora and Paul Cubre – gTech Data Science Team
Posted by Brian Craft, Satish Shreenivasa, Huikun Zhang, Manisha Arora and Paul Cubre – gTech Data Science Team

Introduction
Why analyze YouTube ads?
YouTube has billions of monthly logged-in users and every day people watch billions of hours of video and generate billions of views. Businesses can connect with YouTube users using YouTube ads, which are promotional videos that appear on YouTube's website and app, with a variety of video ad formats and goals.
 |
| A sample YouTube in-stream skippable video ad |
The Challenge
An effective video ad focuses on the ABCDs.
- Attention: Capturing the viewer's attention till the end.
- Branding: Helping them hear or visualize the brand.
- Connection: Making them feel something about the brand.
- Direction: Encouraging them to take action.
But each YouTube ad has a varying number of components, for instance, objects, background music or a logo. Each of these components affect the view through rate (which is referred to as VTR for the remainder of the post) of the video ad. Therefore, analyzing video ads through the lens of the components in the ad helps businesses understand what about the ad improves VTR. The insights from these analyses can be used to inform the creation of new creatives and to optimize existing creatives to improve VTR.
The Proposal
We propose a machine learning based approach for analyzing a company’s YouTube ads to assess which components affect VTR, for the purpose of optimizing a video ad’s performance. We illustrate how to:
- Use Google Cloud Video Intelligence API to extract the components of each video ad, using the underlying video files.
- Transform that extracted data to engineered features that map to actionable business questions.
- Use a machine learning model to isolate the effect on VTR of each engineered feature.
- Interpret and action on those insights to improve video ad performance, for instance altering existing creatives or create new creatives to be used in an AB test.
Approach
The Process
The proposed analysis has 5 steps, discussed below.
1. Define Business Questions2. Raw Component Extraction
3. Feature Engineering
4. Modeling
5. Interpretation
Feature Engineering
Data Extraction
Consider 2 different YouTube Video Ads for a web browser, each highlighting a different product feature. Ad A has text that says “Built In Virus Protection'', while Ad B has text that says “Automatic Password Saving”.
The raw text can be extracted from each video ad and allow for the creation of tabular datasets, such as the below. For brevity and simplicity, the example carried forward will deal with text features only and forgo the timestamp dimension.
|
Ad |
Detected Raw Text |
|
Ad A |
Built In Virus Protection |
|
Ad B |
Automatic Password Saving |
Preprocessing
After extracting the raw components in each ad, preprocessing may need to be applied, such as removing case sensitivity and punctuation.
|
Ad |
Detected Raw Text |
Processed Text |
|
Ad A |
Built In Virus Protection |
built in virus protection |
|
Ad B |
Automatic Password Saving |
automatic password saving |
Manual Feature Engineering
Consider a scenario where the goal is to answer the business question, “does having a textual reference to a product feature affect VTR?”
This feature could be built manually by exploring all the text in all the videos in the sample and creating a list of tokens or phrases that indicate a textual reference to a product feature. However, this approach can be time consuming and limits scaling.
 |
| Pseudo code for manual feature engineering |
AI Based Feature Engineering
Instead of manual feature engineering as described above, the text detected in each video ad creative can be passed to an LLM along with a prompt that performs the feature engineering automatically.
For example, if the goal is to explore the value of highlighting a product feature in a video ad, ask an LLM if the text “‘built in virus protection’ is a feature callout”, followed by asking the LLM if the text “‘automatic password saving’ is a feature callout”.
The answers can be extracted and transformed to a 0 or 1, to later be passed to a machine learning model.
|
Ad |
Raw Text |
Processed Text |
Has Textual Reference to Feature |
|
Ad A |
Built In Virus Protection |
built in virus protection |
Yes |
|
Ad B |
Automatic Password Saving |
automatic password saving |
Yes |
Modeling
Training Data
The result of the feature engineering step is a dataframe with columns that align to the initial business questions, which can be joined to a dataframe that has the VTR for each video ad in the sample.
|
Ad |
Has Textual Reference to Feature |
VTR* |
|---|---|---|
|
Ad A |
Yes |
10% |
|
Ad B |
Yes |
50% |
*Values are random and not to be interpreted in any way.
Modeling is done using fixed effects, bootstrapping and ElasticNet. More information can be found here in the post Introducing Discovery Ad Performance Analysis, written by Manisha Arora and Nithya Mahadevan.
Interpretation
The model output can be used to extract significant features, coefficient values, and standard deviation.
Coefficient Value (+/- X%)|
Feature |
Coefficient* |
Standard Deviation* |
Significant?* |
|
Has Textual Reference to Feature |
0.0222 |
0.000033 |
True |
*Values are random and not to be interpreted in any way.
In the above hypothetical example, the feature “Has Feature Callout” has a statistically significant, positive impact of VTR. This can be interpreted as “there is an observed 2.22% absolute uplift in VTR when an ad has a textual reference to a product feature.”
Challenges
Challenges of the above approach are:
- Interactions among the individual features input into the model are not considered. For example, if “has logo” and “has logo in the lower left” are individual features in the model, their interaction will not be assessed. However, a third feature can be engineered combining the above as “has large logo + has logo in the lower left”.
- Inferences are based on historical data and not necessarily representative of future ad creative performance. There is no guarantee that insights will improve VTR.
- Dimensionality can be a concern as given the number of components in a video ad.
Activation Strategies
Ads Creative Studio
Ads Creative Studio is an effective tool for businesses to create multiple versions of a video by quickly combining text, images, video clips or audio. Use this tool to create new videos quickly by adding/removing features in accordance with model output.
 |
| Sample video creation features in Ads creative studio |
Video Experiments
Design a new creative, varying a component based on the insights from the analysis, and run an AB test. For example, change the size of the logo and set up an experiment using Video Experiments.
Summary
Identifying which components of a YouTube Ad affect VTR is difficult, due to the number of components contained in the ad, but there is an incentive for advertisers to optimize their creatives to improve VTR. Google Cloud technologies, GenAI models and ML can be used to answer creative centric business questions in a scalable and actionable way. The resulting insights can be used to optimize YouTube ads and achieve business outcomes.
Acknowledgements
We would like to thank our collaborators at Google, specifically Luyang Yu, Vijai Kasthuri Rangan, Ahmad Emad, Chuyi Wang, Kun Chang, Mike Anderson, Yan Sun, Nithya Mahadevan, Tommy Mulc, David Letts, Tony Coconate, Akash Roy Choudhury, Alex Pronin, Toby Yang, Felix Abreu and Anthony Lui.
7 dos and don’ts of using ML on the web with MediaPipe
 Posted by
Posted by 
If you're a web developer looking to bring the power of machine learning (ML) to your web apps, then check out MediaPipe Solutions! With MediaPipe Solutions, you can deploy custom tasks to solve common ML problems in just a few lines of code. View the guides in the docs and try out the web demos on Codepen to see how simple it is to get started. While MediaPipe Solutions handles a lot of the complexity of ML on the web, there are still a few things to keep in mind that go beyond the usual JavaScript best practices. I've compiled them here in this list of seven dos and don'ts. Do read on to get some good tips!
❌ DON'T bundle your model in your app
As a web developer, you're accustomed to making your apps as lightweight as possible to ensure the best user experience. When you have larger items to load, you already know that you want to download them in a thoughtful way that allows the user to interact with the content quickly rather than having to wait for a long download. Strategies like quantization have made ML models smaller and accessible to edge devices, but they're still large enough that you don't want to bundle them in your web app. Store your models in the cloud storage solution of your choice. Then, when you initialize your task, the model and WebAssembly binary will be downloaded and initialized. After the first page load, use local storage or IndexedDB to cache the model and binary so future page loads run even faster. You can see an example of this in this touchless ATM sample app on GitHub.
✅ DO initialize your task early
Task initialization can take a bit of time depending on model size, connection speed, and device type. Therefore, it's a good idea to initialize the solution before user interaction. In the majority of the code samples on Codepen, initialization takes place on page load. Keep in mind that these samples are meant to be as simple as possible so you can understand the code and apply it to your own use case. Initializing your model on page load might not make sense for you. Just focus on finding the right place to spin up the task so that processing is hidden from the user.
After initialization, you should warm up the task by passing a placeholder image through the model. This example shows a function for running a 1x1 pixel canvas through the Pose Landmarker task:
function dummyDetection(poseLandmarker: PoseLandmarker) {
const width = 1;
const height = 1;
const canvas = document.createElement('canvas');
canvas.width = width;
canvas.height = height;
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'rgba(0, 0, 0, 1)';
ctx.fillRect(0, 0, width, height);
poseLandmarker.detect(canvas);
} |
✅ DO clean up resources
One of my favorite parts of JavaScript is automatic garbage collection. In fact, I can't remember the last time memory management crossed my mind. Hopefully you've cached a little information about memory in your own memory, as you'll need just a bit of it to make the most of your MediaPipe task. MediaPipe Solutions for web uses WebAssembly (WASM) to run C++ code in-browser. You don't need to know C++, but it helps to know that C++ makes you take out your own garbage. If you don't free up unused memory, you will find that your web page uses more and more memory over time. It can have performance issues or even crash.
When you're done with your solution, free up resources using the .close() method.
For example, I can create a gesture recognizer using the following code:
const createGestureRecognizer = async () => {
const vision = await FilesetResolver.forVisionTasks(
"https://cdn.jsdelivr.net/npm/@mediapipe/[email protected]/wasm"
);
gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath:
"https://storage.googleapis.com/mediapipe-models/gesture_recognizer/gesture_recognizer/float16/1/gesture_recognizer.task",
delegate: "GPU"
},
});
};
createGestureRecognizer(); |
Once I'm done recognizing gestures, I dispose of the gesture recognizer using the close() method:
gestureRecognizer.close(); |
Each task has a close method, so be sure to use it where relevant! Some tasks have close() methods for the returned results, so refer to the API docs for details.
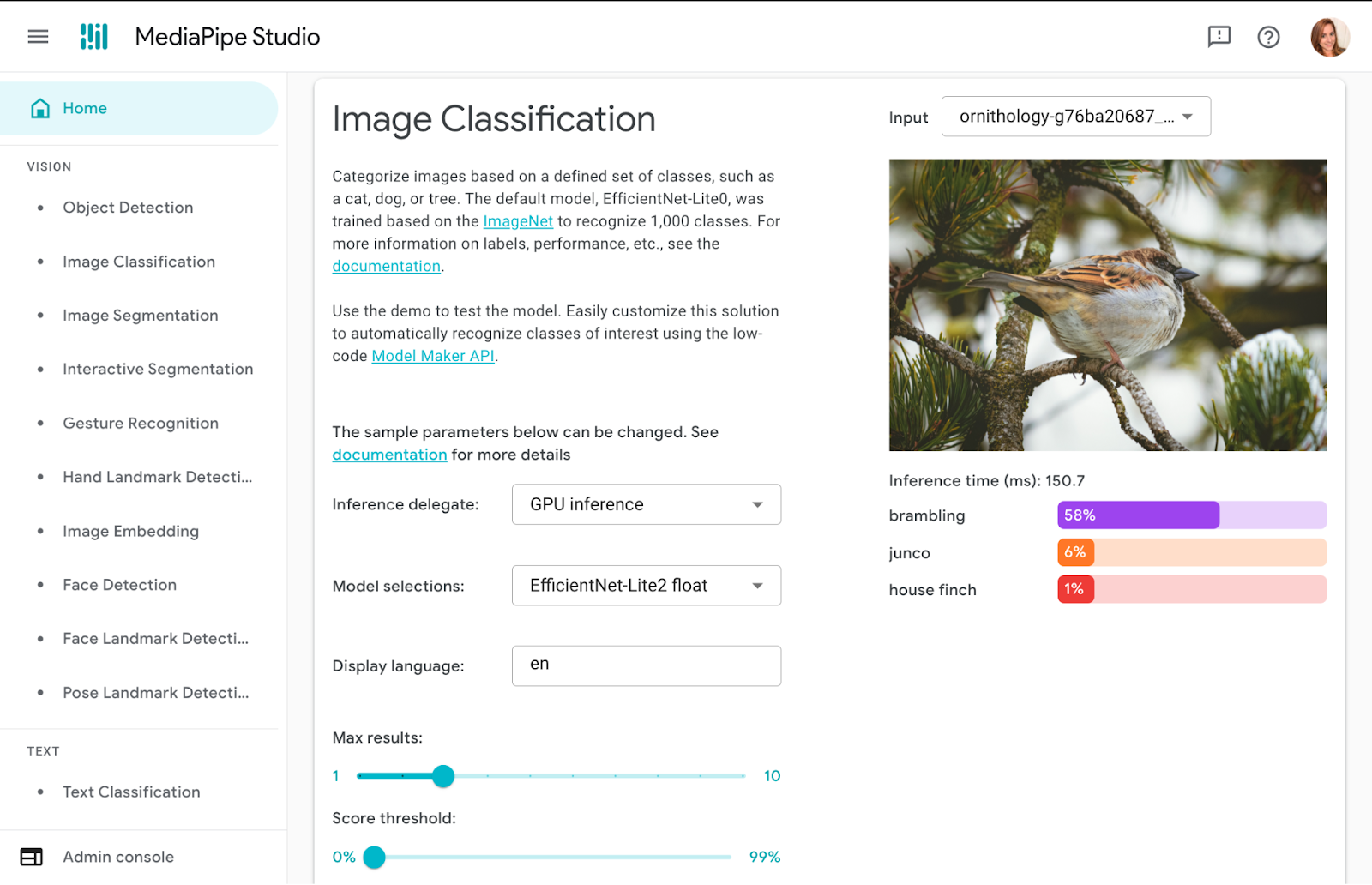
✅ DO try out tasks in MediaPipe Studio
When deciding on or customizing your solution, it's a good idea to try it out in MediaPipe Studio before writing your own code. MediaPipe Studio is a web-based application for evaluating and customizing on-device ML models and pipelines for your applications. The app lets you quickly test MediaPipe solutions in your browser with your own data, and your own customized ML models. Each solution demo also lets you experiment with model settings for the total number of results, minimum confidence threshold for reporting results, and more. You'll find this especially useful when customizing solutions so you can see how your model performs without needing to create a test web page.
✅ DO test on different devices
It's always important to test your web apps on various devices and browsers to ensure they work as expected, but I think it's worth adding a reminder here to test early and often on a variety of platforms. You can use MediaPipe Studio to test devices as well so you know right away that a solution will work on your users' devices.
❌ DON'T default to the biggest model
Each task lists one or more recommended models. For example, the Object Detection task lists three different models, each with benefits and drawbacks based on speed, size and accuracy. It can be tempting to think that the most important thing is to choose the model with the very highest accuracy, but if you do so, you will be sacrificing speed and increasing the size of your model. Depending on your use case, your users might benefit from a faster result rather than a more accurate one. The best way to compare model options is in MediaPipe Studio. I realize that this is starting to sound like an advertisement for MediaPipe Studio, but it really does come in handy here!

✅ DO reach out!
Do you have any dos or don'ts of ML on the web that you think I missed? Do you have questions about how to get started? Or do you have a cool project you want to share? Reach out to me on LinkedIn and tell me all about it!
Cirq Turns 1.0

Getting to Cirq 1.0 is the culmination of a large amount of hard work by hundreds of contributors from Google, industry, and academia. We have been running a weekly meeting, called the “Cirq Cync”, for over four years where community members gather to discuss work on Cirq, bugs, and to generally tell terrible but amusing quantum programming jokes. We’re proud of this inclusive community, and we’ve been particularly happy to see the growth of many software developers into quantum computing experts, and quantum computing experts into solid software developers. One of our contributors, Victory Omole, won the 2021 Witteck Quantum Prize for Open Source Software. Way to go Victory!
The first commit to Cirq on GitHub (an internal version of Cirq at Google existed prior to this) was on Dec 19, 2017 by Craig Gidney, and we publicly announced Cirq in July of 2018. 3,200+ commits later to the GitHub repo, in the hands of the team at Google and the Cirq community, we’ve seen Cirq help accomplish some amazing things:
- Cirq is the lingua franca that Google’s hardware team uses to write quantum programs that run on Google’s quantum computing hardware. Because of this, we have been able to post open source code in our ReCirq repo for these experiments for anyone to examine and extend. A few highlights of the past few years:
- “Realizing topologically ordered states on a quantum processor”, K. J. Satzinger et al., Science 374 6572, 1237-1241 (2021) [paper] [ReCirq code]
- “Information scrambling in quantum circuits”, X. Mi, P. Roushan, C. Quintana et al, Science 374, 6574 1479-1483 (2021) [paper] [ReCirq code]
- “Hartree-Fock on a superconducting qubit quantum computer”, F. Arute et al., Science 369, 6507 1084--1089 (2020) [paper] [ReCirq code]
- A healthy community of libraries have now been built on top of Cirq, enabling different quantum computing research areas. These libraries include:
- TensorFlow Quantum: a tool for exploring quantum machine learning. Using TensorFlow Quantum researchers trained a machine learning model on 30 qubits at a rate of 1.1 petaflops per second (1.1 x 1015 operations per second).
- OpenFermion: an open source tool for quantum computations involved in chemistry simulations.
- Pytket (pytkey-cirq): an open source Python tool for optimizing and manipulating quantum circuits.
- Mitiq: an open source library developed by the non-profit Unitary fund for error mitigation techniques developed by the non-profit Unitary fund.
- Qsim: a high performance state vector simulator written using AVX/FMA vectorized instructions with optional GPU acceleration. qsimcirq is the Cirq interface one can use to access qsim from Cirq.
- Numerous quantum computing cloud services from companies in the industry have also integrated/standardized Cirq. Programs written in Cirq can be used to run through AQT, IonQ, Pascal, Rigetti, and IQM vendors. In addition, Cirq can be used on Azure Quantum to run on the hardware supported by Azure Quantum. Finally, one can get realistic noise simulations of Google’s quantum computing hardware using our newly released Quantum Virtual Machine.
- Cirq is not just for stuffy research. Cirq has also been used to help develop Quantum Chess, a version of chess that uses superposition and entanglement. This notebook shows you how the game of Quantum Chess can be programmed using Cirq.
When we began working on Cirq, quantum computers consisted of only a few qubits and a few quantum gates on these qubits. Building Cirq and the supporting software for these custom systems and having them start to scale to hundreds of qubits over the past (nearly) five years has taught us many lessons. One key takeaway from these lessons is that: As quantum computing hardware continues to grow in scale and complexity, we expect that making software to support this growth will be essential to continue meaningful research and progress. In the next five years, with hardware expected to reach hundreds or even thousands of qubits, the software that is developed for quantum computing will need to have a careful eye set on supporting these bigger and bigger systems. Going forward we will need an ever wider set of frameworks, programming languages, and libraries to achieve quantum computing’s promise.
Acknowledgements
We are indebted to all 169 contributors to the Cirq github repo, and the many more who have filed issues and used Cirq in their own software. A particular shout out to the original lead of Cirq, Craig Gidney, to Cirq’s second lead, Bálint Pató who guided Cirq through its middle ages, and to Alan Ho and Catherine Vollgraff Heidweiller for product wisdom. A special thanks to the core Cirq contributors including Doug Strain, Matthew Neely, Tanuj Khatter, Dax Fohl, Adam Zalcman, Kevin Sung, Matt Harrigan, Casey Duckering, Orion Martin, Smit Sanghavi, Bryan O'Gorman, Wojciech Mruczkiewicz, Ryan LaRose, Tony Bruguier, Victory Omole, and Cheng Xing, and our documentarians Auguste Hirth and Abe Asfaw.
By Dave Bacon and Michael Broughton – Quantum AI Team
Source: Google Open Source Blog
Coral, Google’s platform for Edge AI, chooses ASUS as OEM partner for global scale

We launched Coral in 2019 with a mission to make edge AI powerful, private, and efficient, and also accessible to a wide variety of customers with affordable tools that reliably go from prototype to production. In these first few years, we’ve seen a strong growth in demand for our products across industries and geographies, and with that, a growing need for worldwide availability and support.
That’s why we're pleased to announce that we have signed an agreement with ASUS IoT, to help scale our manufacturing, distribution and support. With decades of experience in electronics manufacturing at a global scale, ASUS IoT will provide Coral with the resources to meet our growth demands while we continue to develop new products for edge computing.
ASUS IoT is a sub-brand of ASUS dedicated to the creation of solutions in the fields of AI and the internet of things (IoT). Their mission is to become a trusted provider of embedded systems and the wider AI and IoT ecosystem. ASUS IoT strives to deliver best-in-class products and services across diverse vertical markets, and to partner with customers in the development of fully-integrated and rapid-to-market applications that drive efficiency – providing convenient, efficient, and secure living and working environments for people everywhere.
ASUS IoT already has a long-standing history of collaboration with Coral, being the first partner to release a product using the Coral SoM when they launched the Tinker Edge T development board. ASUS IoT has also integrated Coral accelerators into their enterprise class intelligent edge computers and was the first to release a multi Edge TPU device with the award winning AI Accelerator PCIe Card. Because we have this history of collaboration, we know they share our strong commitment to new innovation in edge computing.
ASUS IoT also has an established manufacturing and distribution processes, and a strong reputation in enterprise-level sales and support. So we're excited to work with them to enable scale and long-term availability for Coral products.
With this agreement, the Coral brand and user experience will not change, as Google will maintain ownership of the brand and product portfolio. The Coral team will continue to work with our customers on partnership initiatives and case studies through our Coral Partnership Program. Those interested in joining our partner ecosystem can visit our website to learn more and apply.
Coral.ai will remain the home for all product information and documentation, and in the coming months ASUS IoT will become the primary channel for sales, distribution and support. With this partnership, our customers will gain access to dedicated teams for sales and technical support managed by ASUS IoT.
ASUS IoT will be working to expand the distribution network to make Coral available in more countries. Distributors interested in carrying Coral products will be able to contact ASUS IoT for consideration.
We continue to be impressed by the innovative ways in which our customers use Coral to explore new AI-driven solutions. And now with ASUS IoT bringing expanded sales, support and resources for long-term availability, our Coral team will continue to focus on building the next generation of privacy-preserving features and tools for neural computing at the edge.
We look forward to the continued growth of the Coral platform as it flourishes and we are excited to have ASUS IoT join us on our journey.
Source: Google Developers Blog
AI Fest in Spain: Exploring the Potential of Artificial Intelligence in Careers, Communities, and Commerce
Posted by Alessandro Palmieri, Regional Lead for Spain Developer Communities
Google Developer Groups (GDGs) around the world are in a unique position to organize events on technology topics that community members are passionate about. That’s what happened in Spain in July 2021, where two GDG chapters decided to put on an event called AI Fest after noticing a lack of conferences dedicated exclusively to artificial intelligence. “Artificial intelligence is everywhere, although many people do not know it,” says Irene Ruiz Pozo, the organizer of GDG Murcia and GDG Cartagena. While AI has the potential to transform industries from retail to real estate with products like Dialogflow and Lending DocAI, “there are still companies falling behind,” she notes.

Irene and her GDG team members recognized that creating a space for a diverse mix of people—students, academics, professional developers, and more—would not only enable them to share valuable knowledge about AI and its applications across sectors and industries, but it could also serve as a potential path for skill development and post-pandemic economic recovery in Spain. In addition, AI Fest would showcase GDGs in Spain as communities offering developer expertise, education, networking, and support.
Using the GDG network to find sponsors, partners, and speakers
The GDGs immediately got to work calling friends and contacts with experience in AI. “We started calling friends who were great developers and worked at various companies, we told them who we are, what we wanted to do, and what we wanted to achieve,” Irene says.
The GDG team found plenty of organizations eager to help: universities, nonprofit organizations, government entities, and private companies. The final roster included the Instituto de Fomento, the economic development agency of Spain’s Murcia region; the city council of Cartagena; Biyectiva Technology, which develops AI tools used in medicine, retail, and interactive marketing; and the Polytechnic University of Cartagena, where Irene founded and led the Google Developer Student Club in 2019 and 2020. Some partners also helped with swag and merchandising and even provided speakers. “The CEOs and different executives and developers of the companies who were speakers trusted this event from the beginning,” Irene says.
A celebration of AI and its potential
The event organizers lined up a total of 55 local and international speakers over the two-day event. Due to the ongoing COVID-10 pandemic, in-person attendance was limited to 50 people in a room at El Batel Auditorium and Conference Center in Cartagena, but sessions—speakers, roundtables, and workshops—were also live-streamed on YouTube on three channels to a thousand viewers.
Some of the most popular sessions included economics professor and technology lab co-founder Andrés Pedreño on "Competing in the era of Artificial Intelligence," a roundtable on women in technology; Intelequa software developer Elena Salcedo on "Happy plants with IoT''; and Google Developer Expert and technology firm CEO Juantomás García on "Vertex AI and AutoML: Democratizing access to AI." The sessions were also recorded for later viewing, and in less than a week after the event, there were more than 1500 views in room A, over 1100 in room B and nearly 350 views in the Workshops room.
The event made a huge impact on the developer community in Spain, setting an example of what tech-focused gatherings can look like in the COVID-19 era and how they can support more education, collaboration, and innovation across a wide range of organizations, ultimately accelerating the adoption of AI. Irene also notes that it has helped generate more interest in GDGs and GDSCs in Spain and their value as a place to learn, teach, and grow. “We’re really happy that new developers have joined the communities and entrepreneurs have decided to learn how to use Google technologies,” she says.
The effect on the GDG team was profound as well. “I have remembered why I started creating events--for people: to discover the magic of technology,” Irene says.
Taking AI Fest into the future—and more
Irene and her fellow GDG members are already planning for a second installment of AI Fest in early 2022, where they hope to be able to expect more in-person attendance. The team would also like to organize events focused on topics such as Android, Cloud, AR /VR, startups, the needs of local communities, and inclusion. Irene, who serves as a Women Techmakers Ambassador, is particularly interested in using her newly expanded network to host events that encourage women to choose technology and other STEM areas as a career.
Finally, Irene hopes that AI Fest will become an inspiration for GDGs around the world to showcase the potential of AI and other technologies. It’s a lot of work, she admits, but the result is well worth it. “My advice is to choose the area of technology that interests you the most, get organized, relax, and have a good team,” she advises.
Source: Google Developers Blog
Developer updates from Coral
Posted by The Coral Team
We're always excited to share updates to our Coral platform for building edge ML applications. In this post, we have some interesting demos, interfaces, and tutorials to share, and we'll start by pointing you to an important software update for the Coral Dev Board.
Important update for the Dev Board / SoM
If you have a Coral Dev Board or Coral SoM, please install our latest Mendel update as soon as possible to receive a critical fix to part of the SoC power configuration. To get it, just log onto your board and install the update as follows:

This will install a patch from NXP for the Dev Board / SoM's SoC, without which it's possible the SoC will overstress and the lifetime of the device could be reduced. If you recently flashed your board with the latest system image, you might already have this fix (we also updated the flashable image today), but it never hurts to fetch all updates, as shown above.
Note: This update does not apply to the Dev Board Mini.Manufacturing demo
We recently published the Coral Manufacturing Demo, which demonstrates how to use a single Coral Edge TPU to simultaneously accomplish two common manufacturing use-cases: worker safety and visual inspection.
The demo is designed for two specific videos and tasks (worker keepout detection and apple quality grading) but it is designed to be easily customized with different inputs and tasks. The demo, written in C++, requires OpenGL and is primarily targeted at x86 systems which are prevalent in manufacturing gateways – although ARM Cortex-A systems, like the Coral Dev Board, are also supported.

Web Coral
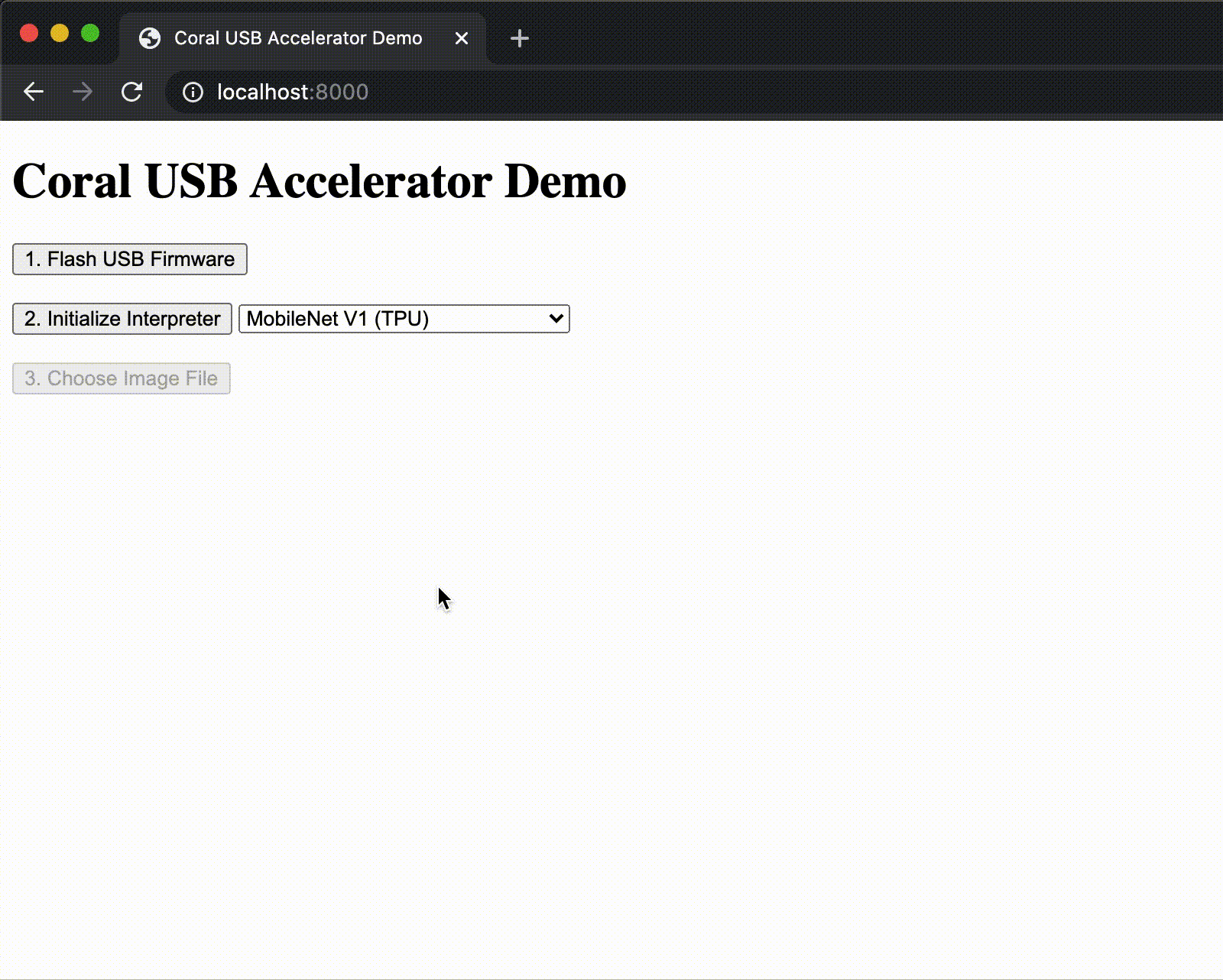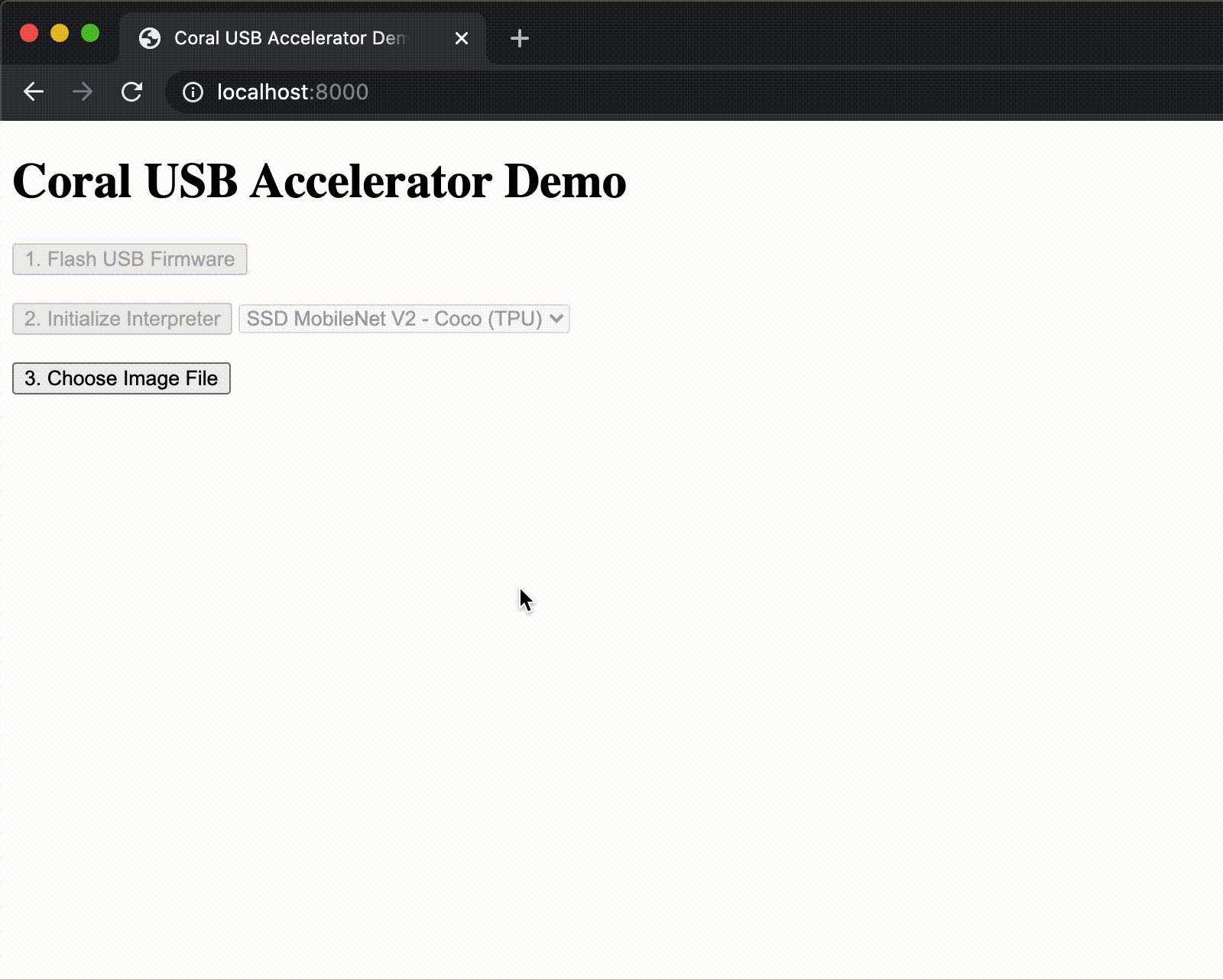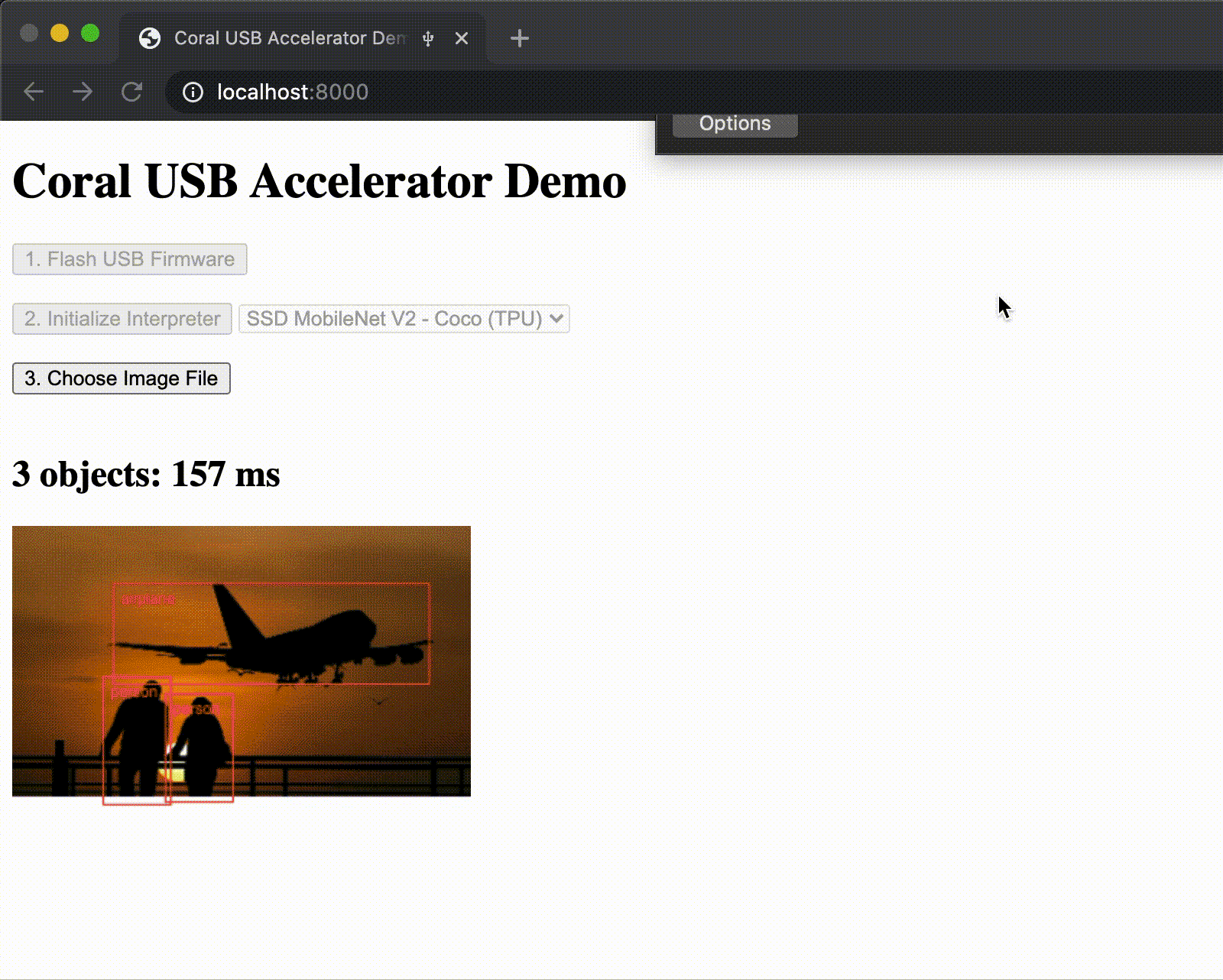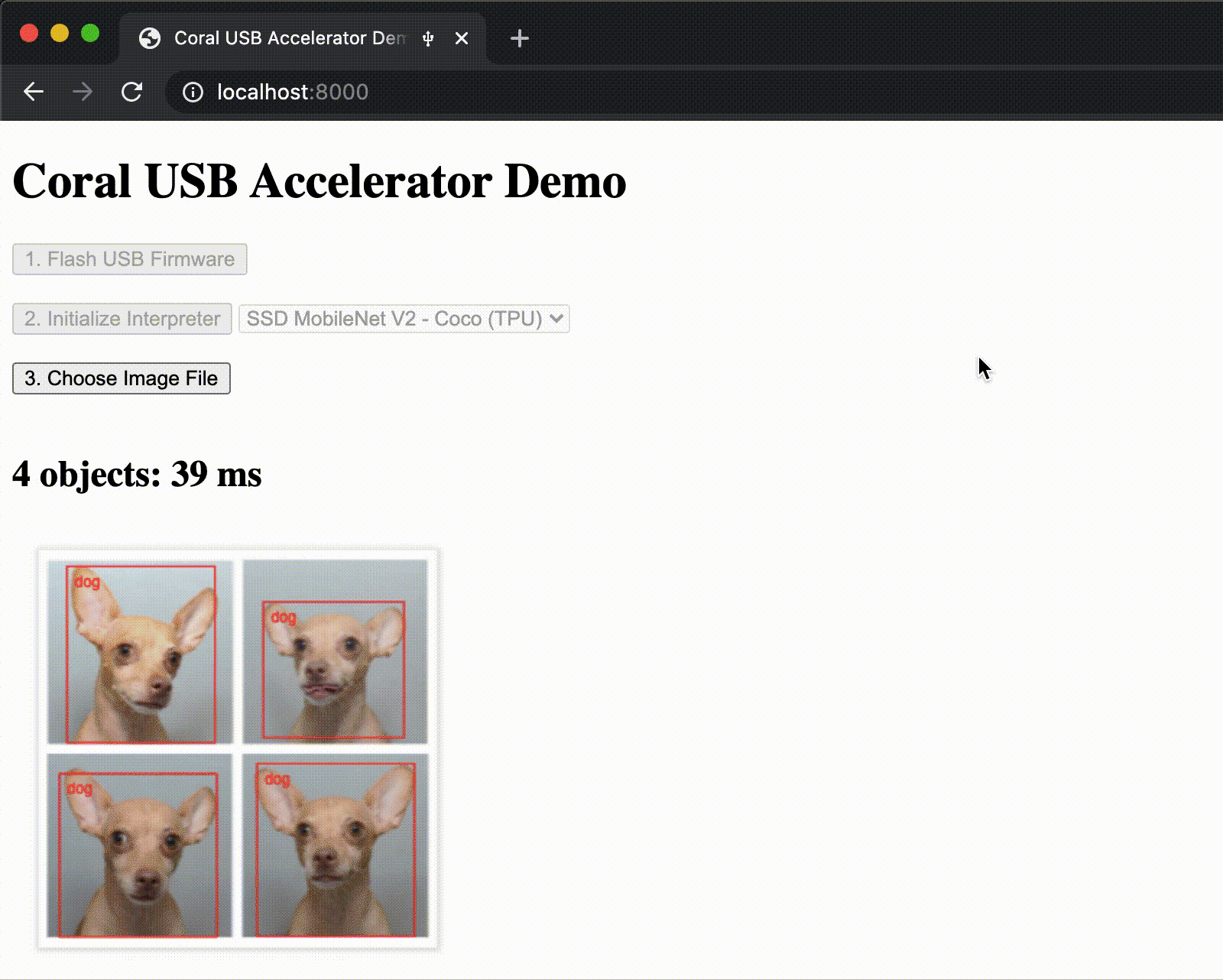
We've been working hard to make ML acceleration with the Coral Edge TPU available for most popular systems. So we're proud to announce support for WebUSB, allowing you to use the Coral USB Accelerator directly from Chrome. To get started, check out our WebCoral demo, which builds a webpage where you can select a model and run an inference accelerated by the Edge TPU.
New models repository
We recently released a new models repository that makes it easier to explore the various trained models available for the Coral platform, including image classification, object detection, semantic segmentation, pose estimation, and speech recognition. Each family page lists the various models, including details about training dataset, input size, latency, accuracy, model size, and other parameters, making it easier to select the best fit for the application at hand. Lastly, each family page includes links to training scripts and example code to help you get started. Or for an overview of all our models, you can see them all on one page.
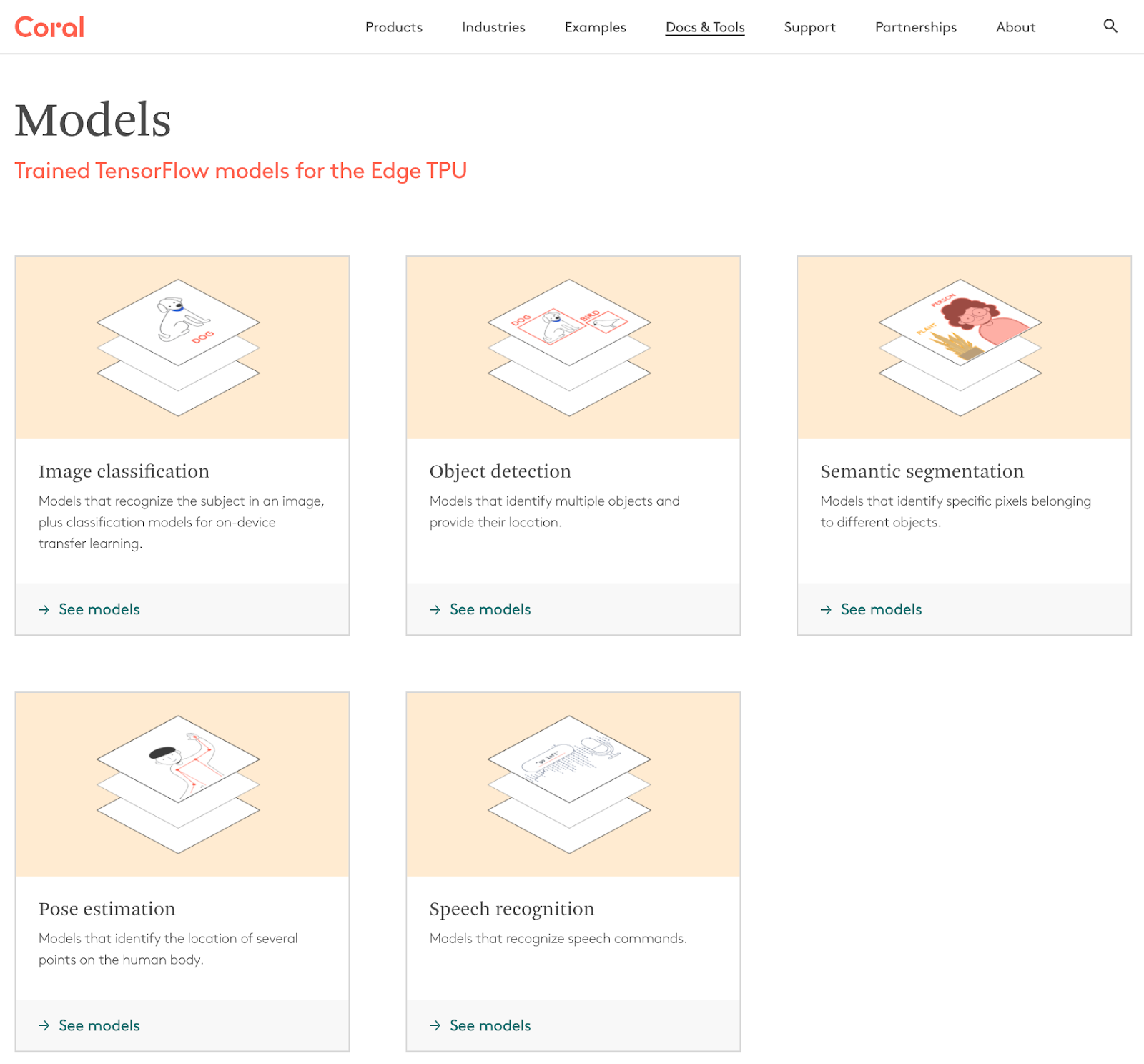
Transfer learning tutorials
Even with our collection of pre-trained models, it can sometimes be tricky to create a task-specific model that's compatible with our Edge TPU accelerator. To make this easier, we've released some new Google Colab tutorials that allow you to perform transfer learning for object detection, using MobileDet and EfficientDet-Lite models. You can find these and other Colabs in our GitHub Tutorials repo.
We are excited to share all that Coral has to offer as we continue to evolve our platform. Keep an eye out for more software and platform related news coming this summer. To discover more about our edge ML platform, please visit Coral.ai and share your feedback at [email protected].
Source: Google Developers Blog
Machine Learning GDEs: Q1 2021 highlights, projects and achievements
Posted by HyeJung Lee and MJ You, Google ML Ecosystem Community Managers. Reviewed by Soonson Kwon, Developer Relations Program Manager.
Google Developers Experts is a community of passionate developers who love to share their knowledge with others. Many of them specialize in Machine Learning (ML). Despite many unexpected changes over the last months and reduced opportunities for various in person activities during the ongoing pandemic, their enthusiasm did not stop.
Here are some highlights of the ML GDE’s hard work during the Q1 2021 which contributed to the global ML ecosystem.
ML GDE YouTube channel
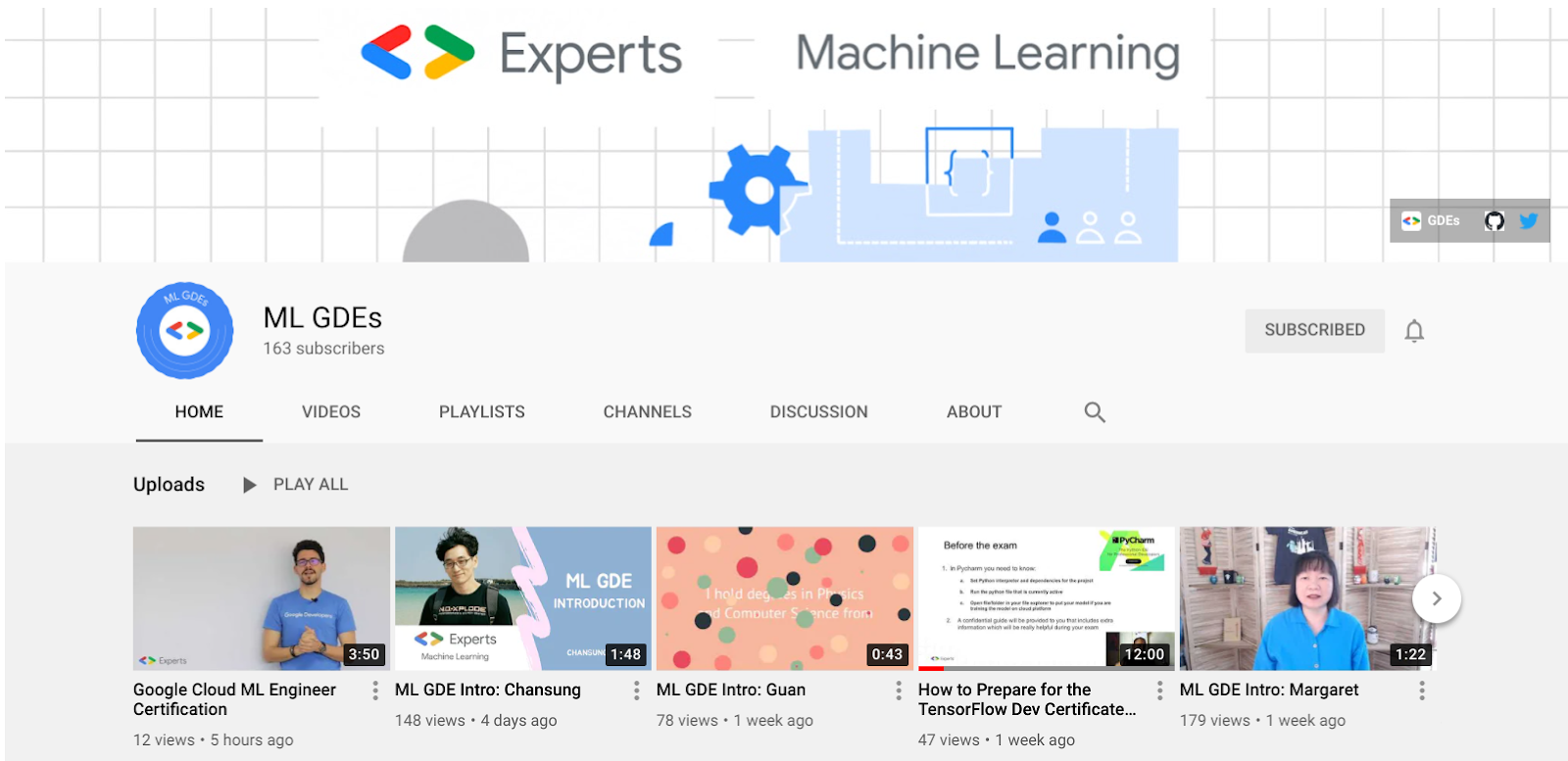
With the initiative and lead of US-based GDE Margaret Maynard-Reid, we launched the ML GDEs YouTube channel. It is a great way for GDEs to reach global audiences, collaborate as a community, create unique content and promote each other's work. It will contain all kinds of ML related topics: talks on technical topics, tutorials, interviews with another (ML) GDE, a Googler or anyone in the ML community etc. Many videos have already been uploaded, including: ML GDE’s intro from all over the world, tips for TensorFlow & GCP Certification and how to use Google Cloud Platform etc. Subscribe to the channel now!!
TensorFlow Everywhere

17 ML GDEs presented at TensorFlow Everywhere (a global community-led event series for TensorFlow and Machine Learning enthusiasts and developers around the world) hosted by local TensorFlow user groups. You can watch the recorded sessions in the TensorFlow Everywhere playlist on the ML GDE Youtube channel. Most of the sessions cover new features in Tensorflow.
International Women’s Day
Many ML GDEs participated in activities to celebrate International Women’s Day (March 8th). GDE Ruqiya Bin Safi (based in Saudi Arabia) cooperated with WTM Saudi Arabia to organize “Socialthon” - social development hackathons and gave a talk “Successful Experiences in Social Development", which reached 77K viervers live and hit 10K replays. India-based GDE Charmi Chokshi participated in GirlScript's International Women's Day event and gave a talk: “Women In Tech and How we can help the underrepresented in the challenging world”. If you’re looking for more inspiring materials, check out the “Women in AI” playlist on our ML GDE YouTube channel!
ML GDEs are also very active in mentoring community developers, students in the Google Developer Student Clubs and startups in the Google for Startups Accelerator program. Among many, GDE Arnaldo Gualberto (Brazil) conducted mentorship sessions for startups in the Google Fast Track program, discussing how to solve challanges using Machine Learning/Deep Learning with TensorFlow.
TensorFlow


Meanwhile in Europe, GDEs Alexia Audevart (based in France) and Luca Massaron (based in Italy) released “Machine Learning using TensorFlow Cookbook”. It provides simple and effective ideas to successfully use TensorFlow 2.x in computer vision, NLP and tabular data projects. Additionally, Luca published the second edition of the Machine Learning For Dummies book, first published in 2015. Her latest edition is enhanced with product updates and the principal is a larger share of pages devoted to discussion of Deep Learning and TensorFlow / Keras usage.
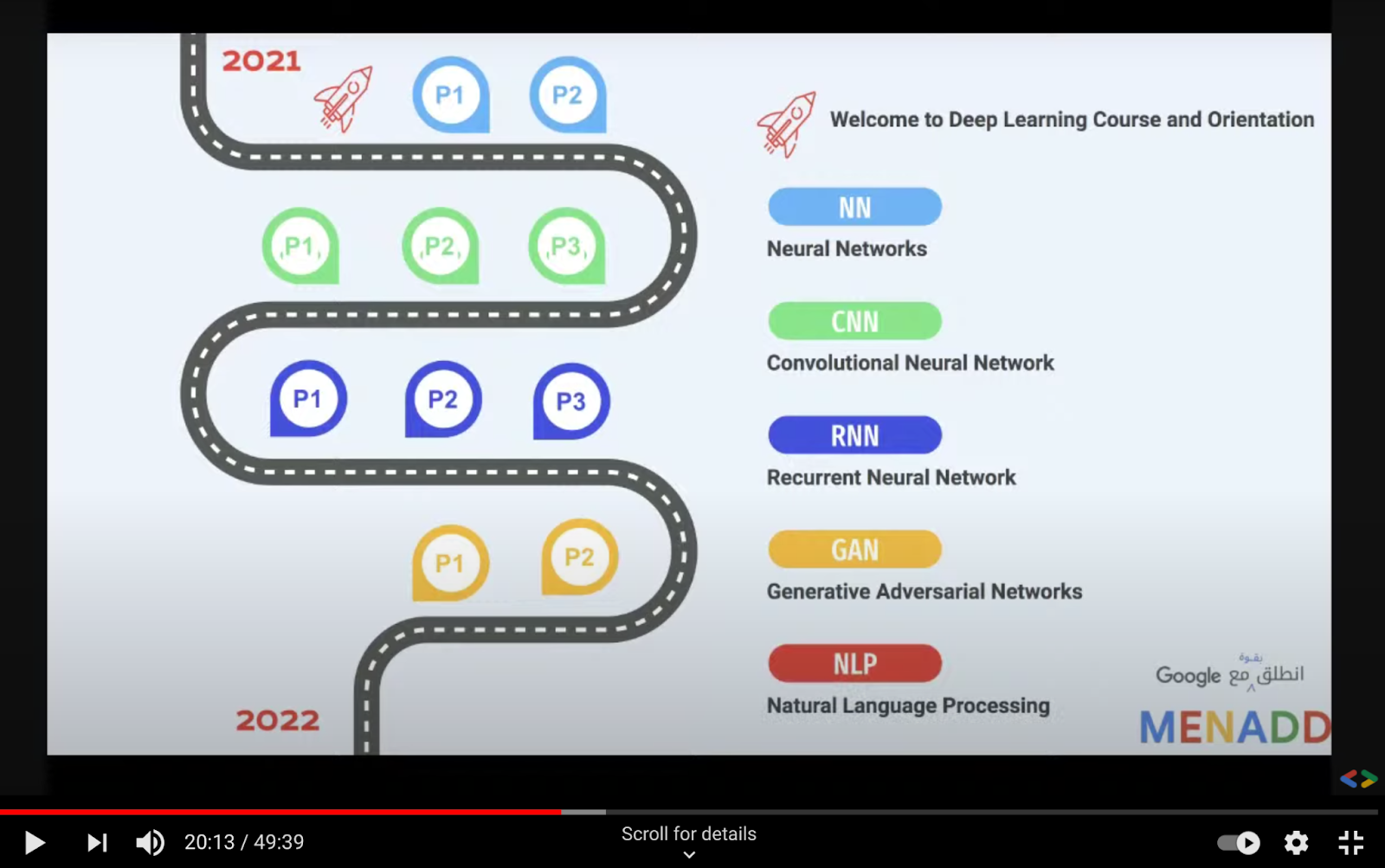
On top of her women-in-tech related activities, Ruqiya Bin Safi is also running a “Welcome to Deep Learning Course and Orientation” monthly workshop throughout 2021. The course aims to help participants gain foundational knowledge of deep learning algorithms and get practical experience in building neural networks in TensorFlow.

Nepal-based GDE Kshitiz Rimal gave a talk “TensorFlow Project Showcase: Cash Recognition for Visually Impaired" on his project which uses TensorFlow, Google Cloud AutoML and edge computing technologies to create a solution for the visually impaired community in Nepal.
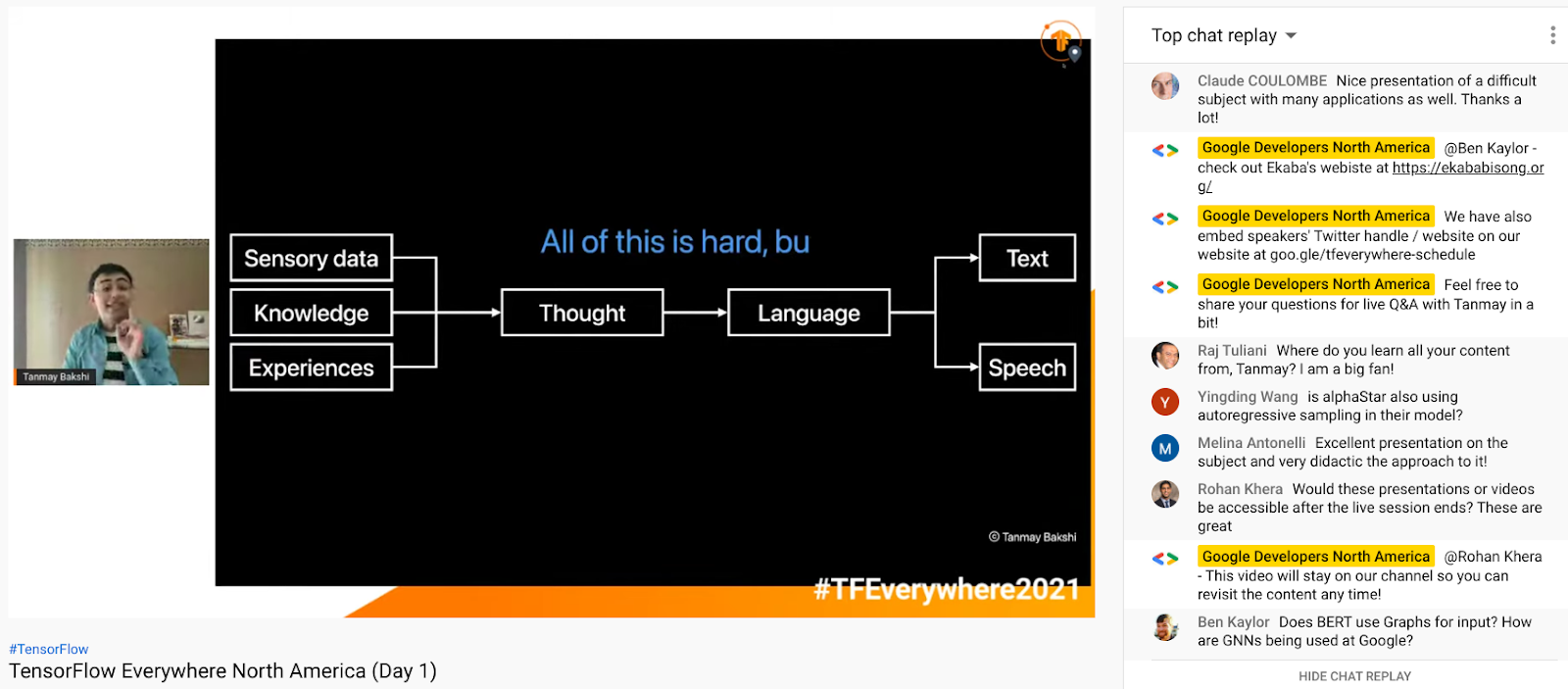
On the other side of the world, in Canada, GDE Tanmay Bakshi presented a talk “Machine Learning-powered Pipelines to Augment Human Specialists” during TensorFlow Everywhere NA. It covered the world of NLP through Deep Learning, how it's historically been done, the Transformer revolution, and how using the TensorFlow & Keras to implement use cases ranging from small-scale name generation to large-scale Amazon review quality ranking.
Google Cloud Platform
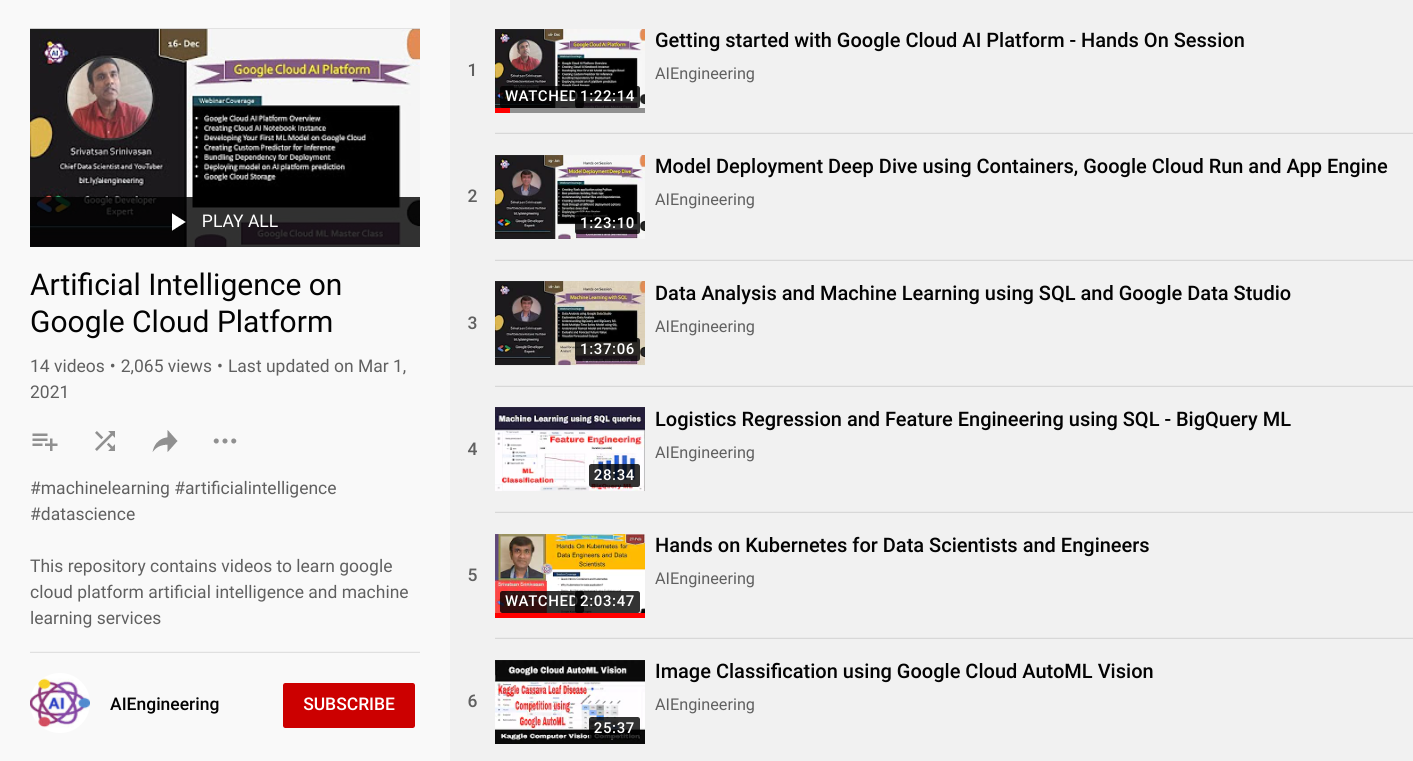
We have been equally busy on the GCP side as well. In the US, GDE Srivatsan Srinivasan created a series of videos called “Artificial Intelligence on Google Cloud Platform”, with one of the episodes, "Google Cloud Products and Professional Machine Learning Engineer Certification Deep Dive", getting over 3,000 views.

Korean GDE Chansung Park contributed to TensorFlow User Group Korea with his “Machine Learning Pipeline (CI/CD for ML Products in GCP)” analysis, focused on about machine learning pipeline in Google Cloud Platform.
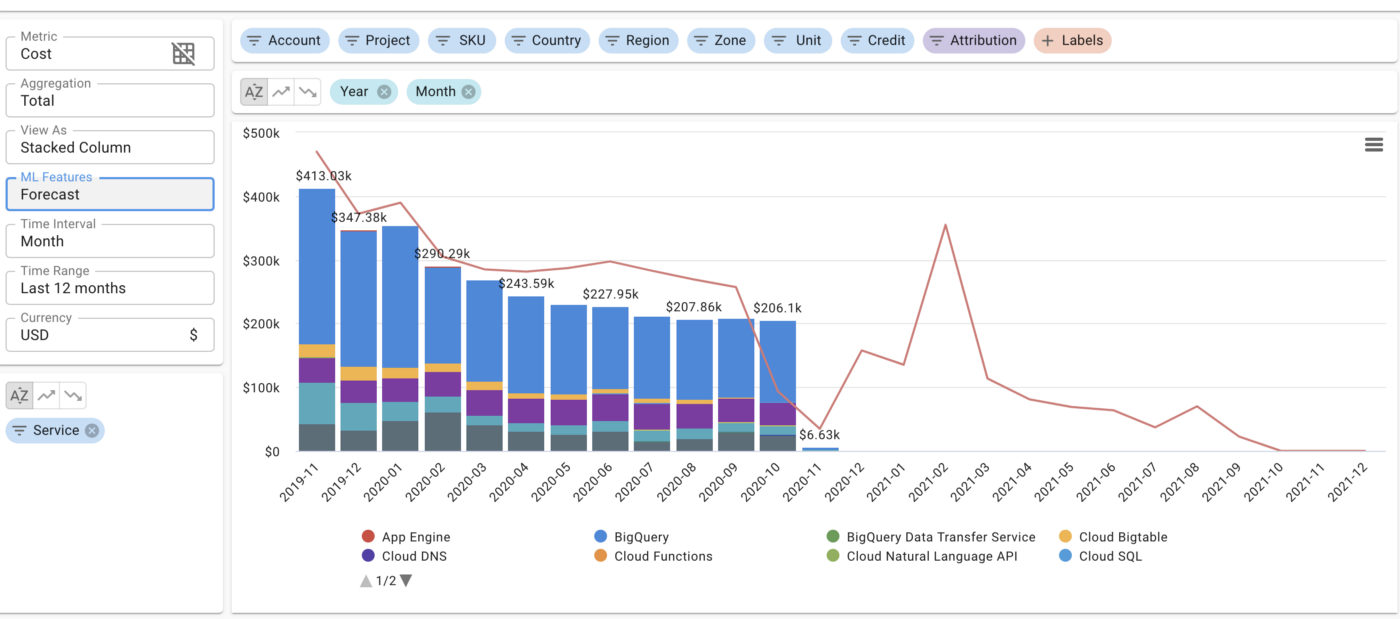
Last but not least, GDE Gad Benram based in Israel wrote an article on “Seven Tips for Forecasting Cloud Costs”, where he explains how to build and deploy ML models for time series forecasting with Google Cloud Run. It is linked with his solution of building a cloud-spend control system that helps users more-easily analyze their cloud costs.
If you want to know more about the Google Experts community and all their global open-source ML contributions, visit the GDE Directory and connect with GDEs on Twitter and LinkedIn. You can also meet them virtually on the ML GDE’s YouTube Channel!
Source: Google Developers Blog
Irem from Turkey shares her groundbreaking work in TensorFlow and advice for the community
Posted by Jennifer Kohl, Global Program Manager, Google Developer Groups

Irem presenting at a Google Developer Group event
We recently caught up with Irem Komurcu, a TensorFlow developer and researcher at Istanbul Technical University in Turkey. Irem has been a long-serving member of Google Developer Groups (GDG) Düzce and also serves as a Women Techmakers (WTM) ambassador. Her work with TensorFlow has received several accolades, including being named a Hamdi Ulukaya Girişimi fellow. As one one of twenty-four young entrepreneurs selected, she was flown to New York City last year to learn more about business and receive professional development.
With all this experience to share, we wanted you to hear how she approaches pursuing a career in tech, hones her TensorFlow skills with the GDG community, and thinks about how upcoming programmers can best position themselves for success. Check out the full interview below for more.
What inspired you to pursue a career in technology?I first became interested in tech when I was in high school and went on to study computer engineering. At university, I had an eye-opening experience when I traveled from Turkey to the Google Developer Day event in India. It was here where I observed various code languages, products, and projects that were new to me.
In particular, I saw TensorFlow in action for the first time. Watching the powerful machine learning tool truly sparked my interest in deep learning and project development.
Can you describe your work with TensorFlow and Machine Learning?I have studied many different aspects of Tensorflow and ML. My first work was on voice recognition and deep learning. However, I am now working as a computer vision researcher conducting various segmentation, object detection, and classification processes with Tensorflow. In my free time, I write various articles about best practices and strategies to leverage TensorFlow in ML.
What has been a useful learning resource you have used in your career?I kicked off my studies on deep learning on tensorflow.org. It’s a basic first step, but a powerful one. There were so many blogs, codes, examples, and tutorials for me to dive into. Both the Google Developer Group and TensorFlow communities also offered chances to bounce questions and ideas off other developers as I learned.
Between these technical resources and the person-to-person support, I was lucky to start working with the GDG community while also taking the first steps of my career. There were so many opportunities to meet people and grow all around.
What is your favorite part of the Google Developer Group community?I love being in a large community with technology-oriented people. GDG is a network of professionals who support each other, and that enables people to develop. I am continuously sharing my knowledge with other programmers as they simultaneously mentor me. The chance for us to collaborate together is truly fulfilling.
What is unique about being a developer in your country/region?The number of women supported in science, technology, engineering, and mathematics (STEM) is low in Turkey. To address this, I partner with Women Techmakers (WTM) to give educational talks on TensorFlow and machine learning to women who want to learn how to code in my country. So many women are interested in ML, but just need a friendly, familiar face to help them get started. With WTM, I’ve already given over 30 talks to women in STEM.
What advice would you give to someone who is trying to grow their career as a developer?Keep researching new things. Read everything you can get your eyes on. Technology has been developing rapidly, and it is necessary to make sure your mind can keep up with the pace. That’s why I recommend communities like GDG that help make sure you’re up to date on the newest trends and learnings.
Want to work with other developers like Irem? Then find the right Google Developer Developer Group for you, here.
Source: Google Developers Blog
MediaPipe 3D Face Transform
Posted by Kanstantsin Sokal, Software Engineer, MediaPipe team
Earlier this year, the MediaPipe Team released the Face Mesh solution, which estimates the approximate 3D face shape via 468 landmarks in real-time on mobile devices. In this blog, we introduce a new face transform estimation module that establishes a researcher- and developer-friendly semantic API useful for determining the 3D face pose and attaching virtual objects (like glasses, hats or masks) to a face.
The new module establishes a metric 3D space and uses the landmark screen positions to estimate common 3D face primitives, including a face pose transformation matrix and a triangular face mesh. Under the hood, a lightweight statistical analysis method called Procrustes Analysis is employed to drive a robust, performant and portable logic. The analysis runs on CPU and has a minimal speed/memory footprint on top of the original Face Mesh solution.

Figure 1: An example of virtual mask and glasses effects, based on the MediaPipe Face Mesh solution.
Introduction
The MediaPipe Face Landmark Model performs a single-camera face landmark detection in the screen coordinate space: the X- and Y- coordinates are normalized screen coordinates, while the Z coordinate is relative and is scaled as the X coordinate under the weak perspective projection camera model. While this format is well-suited for some applications, it does not directly enable crucial features like aligning a virtual 3D object with a detected face.
The newly introduced module moves away from the screen coordinate space towards a metric 3D space and provides the necessary primitives to handle a detected face as a regular 3D object. By design, you'll be able to use a perspective camera to project the final 3D scene back into the screen coordinate space with a guarantee that the face landmark positions are not changed.
Metric 3D Space
The Metric 3D space established within the new module is a right-handed orthonormal metric 3D coordinate space. Within the space, there is a virtual perspective camera located at the space origin and pointed in the negative direction of the Z-axis. It is assumed that the input camera frames are observed by exactly this virtual camera and therefore its parameters are later used to convert the screen landmark coordinates back into the Metric 3D space. The virtual camera parameters can be set freely, however for better results it is advised to set them as close to the real physical camera parameters as possible.

Figure 2: A visualization of multiple key elements in the metric 3D space. Created in Cinema 4D
Canonical Face Model
The Canonical Face Model is a static 3D model of a human face, which follows the 3D face landmark topology of the MediaPipe Face Landmark Model. The model bears two important functions:
- Defines metric units: the scale of the canonical face model defines the metric units of the Metric 3D space. A metric unit used by the default canonical face model is a centimeter;
- Bridges static and runtime spaces: the face pose transformation matrix is - in fact - a linear map from the canonical face model into the runtime face landmark set estimated on each frame. This way, virtual 3D assets modeled around the canonical face model can be aligned with a tracked face by applying the face pose transformation matrix to them.
Face Transform Estimation
The face transform estimation pipeline is a key component, responsible for estimating face transform data within the Metric 3D space. On each frame, the following steps are executed in the given order:
- Face landmark screen coordinates are converted into the Metric 3D space coordinates;
- Face pose transformation matrix is estimated as a rigid linear mapping from the canonical face metric landmark set into the runtime face metric landmark set in a way that minimizes a difference between the two;
- A face mesh is created using the runtime face metric landmarks as the vertex positions (XYZ), while both the vertex texture coordinates (UV) and the triangular topology are inherited from the canonical face model.
Effect Renderer
The Effect Renderer is a component, which serves as a working example of a face effect renderer. It targets the OpenGL ES 2.0 API to enable a real-time performance on mobile devices and supports the following rendering modes:
- 3D object rendering mode: a virtual object is aligned with a detected face to emulate an object attached to the face (example: glasses);
- Face mesh rendering mode: a texture is stretched on top of the face mesh surface to emulate a face painting technique.
In both rendering modes, the face mesh is first rendered as an occluder straight into the depth buffer. This step helps to create a more believable effect via hiding invisible elements behind the face surface.

Figure 3: An example of face effects rendered by the Face Effect Renderer.
Using Face Transform Module
The face transform estimation module is available as a part of the MediaPipe Face Mesh solution. It comes with face effect application examples, available as graphs and mobile apps on Android or iOS. If you wish to go beyond examples, the module contains generic calculators and subgraphs - those can be flexibly applied to solve specific use cases in any MediaPipe graph. For more information, please visit our documentation.
Follow MediaPipe
We look forward to publishing more blog posts related to new MediaPipe pipeline examples and features. Please follow the MediaPipe label on Google Developers Blog and Google Developers twitter account (@googledevs).
Acknowledgements
We would like to thank Chuo-Ling Chang, Ming Guang Yong, Jiuqiang Tang, Gregory Karpiak, Siarhei Kazakou, Matsvei Zhdanovich and Matthias Grundman for contributing to this blog post.
Source: Google Developers Blog
Doubling down on the edge with Coral’s new accelerator
Posted by The Coral Team
Moving into the fall, the Coral platform continues to grow with the release of the M.2 Accelerator with Dual Edge TPU. Its first application is in Google’s Series One room kits where it helps to remove interruptions and makes the audio clearer for better video meetings. To help even more folks build products with Coral intelligence, we’re dropping the prices on several of our products. And for those folks that are looking to level up their at home video production, we’re sharing a demo of a pose based AI director to make multi-camera video easier to make.
Coral M.2 Accelerator with Dual Edge TPU
The newest addition to our product family brings two Edge TPU co-processors to systems in an M.2 E-key form factor. While the design requires a dual bus PCIe M.2 slot, it brings enhanced ML performance (8 TOPS) to tasks such as running two models in parallel or pipelining one large model across both Edge TPUs.
The ability to scale across multiple edge accelerators isn’t limited to only two Edge TPUs. As edge computing expands to local data centers, cell towers, and gateways, multi-Edge TPU configurations will be required to help process increasingly sophisticated ML models. Coral allows the use of a single toolchain to create models for one or more Edge TPUs that can address many different future configurations.
A great example of how the Coral M.2 Accelerator with Dual Edge TPU is being used is in the Series One meeting room kits for Google Meet.
The new Series One room kits for Google Meet run smarter with Coral intelligence

Google’s new Series One room kits use our Coral M.2 Accelerator with Dual Edge TPU to bring enhanced audio clarity to video meetings. TrueVoice®, a multi-channel noise cancellation technology, minimizes distractions to ensure every voice is heard with up to 44 channels of echo and noise cancellation, making distracting sounds like snacking or typing on a keyboard a concern of the past.
Enabling the clearest possible communication in challenging environments was the target for the Google Meet hardware team. The consideration of what makes a challenging environment was not limited to unusually noisy environments, such as lunchrooms doubling as conference rooms. Any conference room can present challenging acoustics that make it difficult for all participants to be heard.
The secret to clarity without expensive and cumbersome equipment is to use virtual audio channels and AI driven sound isolation. Read more about how Coral was used to enhance and future-proof the innovative design.
Expanding the AI edge
Earlier this year, we reduced the prices of our prototyping devices and sensors. We are excited to share further price drops on more of our products. Our System-on-Module is now available for $99.99, and our Mini PCIe Accelerator, M.2 Accelerator A+E Key, and M.2 Accelerator B+M key are now available at $24.99. We hope this lower price will make our edge AI more accessible to more creative minds around the world. Later, this month our SoM offering will also expand to include 2 and 4GB RAM options.
Multi-cam with AI
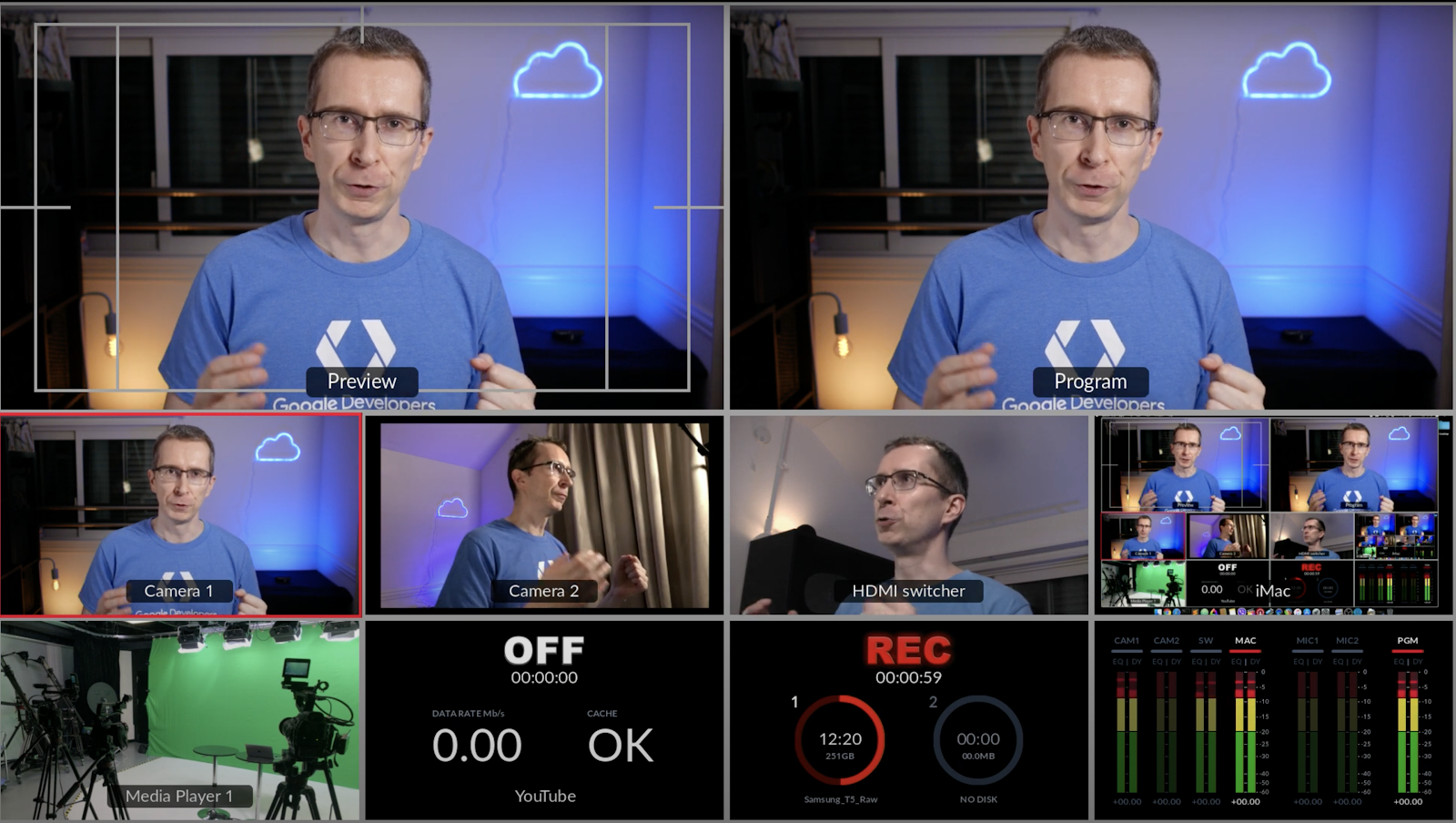
As we expand our platform and product family, we continue to keep new edge AI use cases in mind. We are continually inspired by our developer community’s experimentation and implementations. When recently faced with the challenges of multicam video production from home, Markku Lepistö, Solutions Architect at Google Cloud, created this real-time pose-based multicam tool he so aptly dubbed, AI Director.
We love seeing such unique implementations of on-device ML and invite you to share your own projects and feedback at [email protected].
For a list of worldwide distributors, system integrators and partners, visit the Coral partnerships page. Please visit Coral.ai to discover more about our edge ML platform.