 Posted by
Posted by 
If you're a web developer looking to bring the power of machine learning (ML) to your web apps, then check out MediaPipe Solutions! With MediaPipe Solutions, you can deploy custom tasks to solve common ML problems in just a few lines of code. View the guides in the docs and try out the web demos on Codepen to see how simple it is to get started. While MediaPipe Solutions handles a lot of the complexity of ML on the web, there are still a few things to keep in mind that go beyond the usual JavaScript best practices. I've compiled them here in this list of seven dos and don'ts. Do read on to get some good tips!
❌ DON'T bundle your model in your app
As a web developer, you're accustomed to making your apps as lightweight as possible to ensure the best user experience. When you have larger items to load, you already know that you want to download them in a thoughtful way that allows the user to interact with the content quickly rather than having to wait for a long download. Strategies like quantization have made ML models smaller and accessible to edge devices, but they're still large enough that you don't want to bundle them in your web app. Store your models in the cloud storage solution of your choice. Then, when you initialize your task, the model and WebAssembly binary will be downloaded and initialized. After the first page load, use local storage or IndexedDB to cache the model and binary so future page loads run even faster. You can see an example of this in this touchless ATM sample app on GitHub.
✅ DO initialize your task early
Task initialization can take a bit of time depending on model size, connection speed, and device type. Therefore, it's a good idea to initialize the solution before user interaction. In the majority of the code samples on Codepen, initialization takes place on page load. Keep in mind that these samples are meant to be as simple as possible so you can understand the code and apply it to your own use case. Initializing your model on page load might not make sense for you. Just focus on finding the right place to spin up the task so that processing is hidden from the user.
After initialization, you should warm up the task by passing a placeholder image through the model. This example shows a function for running a 1x1 pixel canvas through the Pose Landmarker task:
function dummyDetection(poseLandmarker: PoseLandmarker) {
const width = 1;
const height = 1;
const canvas = document.createElement('canvas');
canvas.width = width;
canvas.height = height;
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'rgba(0, 0, 0, 1)';
ctx.fillRect(0, 0, width, height);
poseLandmarker.detect(canvas);
} |
✅ DO clean up resources
One of my favorite parts of JavaScript is automatic garbage collection. In fact, I can't remember the last time memory management crossed my mind. Hopefully you've cached a little information about memory in your own memory, as you'll need just a bit of it to make the most of your MediaPipe task. MediaPipe Solutions for web uses WebAssembly (WASM) to run C++ code in-browser. You don't need to know C++, but it helps to know that C++ makes you take out your own garbage. If you don't free up unused memory, you will find that your web page uses more and more memory over time. It can have performance issues or even crash.
When you're done with your solution, free up resources using the .close() method.
For example, I can create a gesture recognizer using the following code:
const createGestureRecognizer = async () => {
const vision = await FilesetResolver.forVisionTasks(
"https://cdn.jsdelivr.net/npm/@mediapipe/[email protected]/wasm"
);
gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath:
"https://storage.googleapis.com/mediapipe-models/gesture_recognizer/gesture_recognizer/float16/1/gesture_recognizer.task",
delegate: "GPU"
},
});
};
createGestureRecognizer(); |
Once I'm done recognizing gestures, I dispose of the gesture recognizer using the close() method:
gestureRecognizer.close(); |
Each task has a close method, so be sure to use it where relevant! Some tasks have close() methods for the returned results, so refer to the API docs for details.
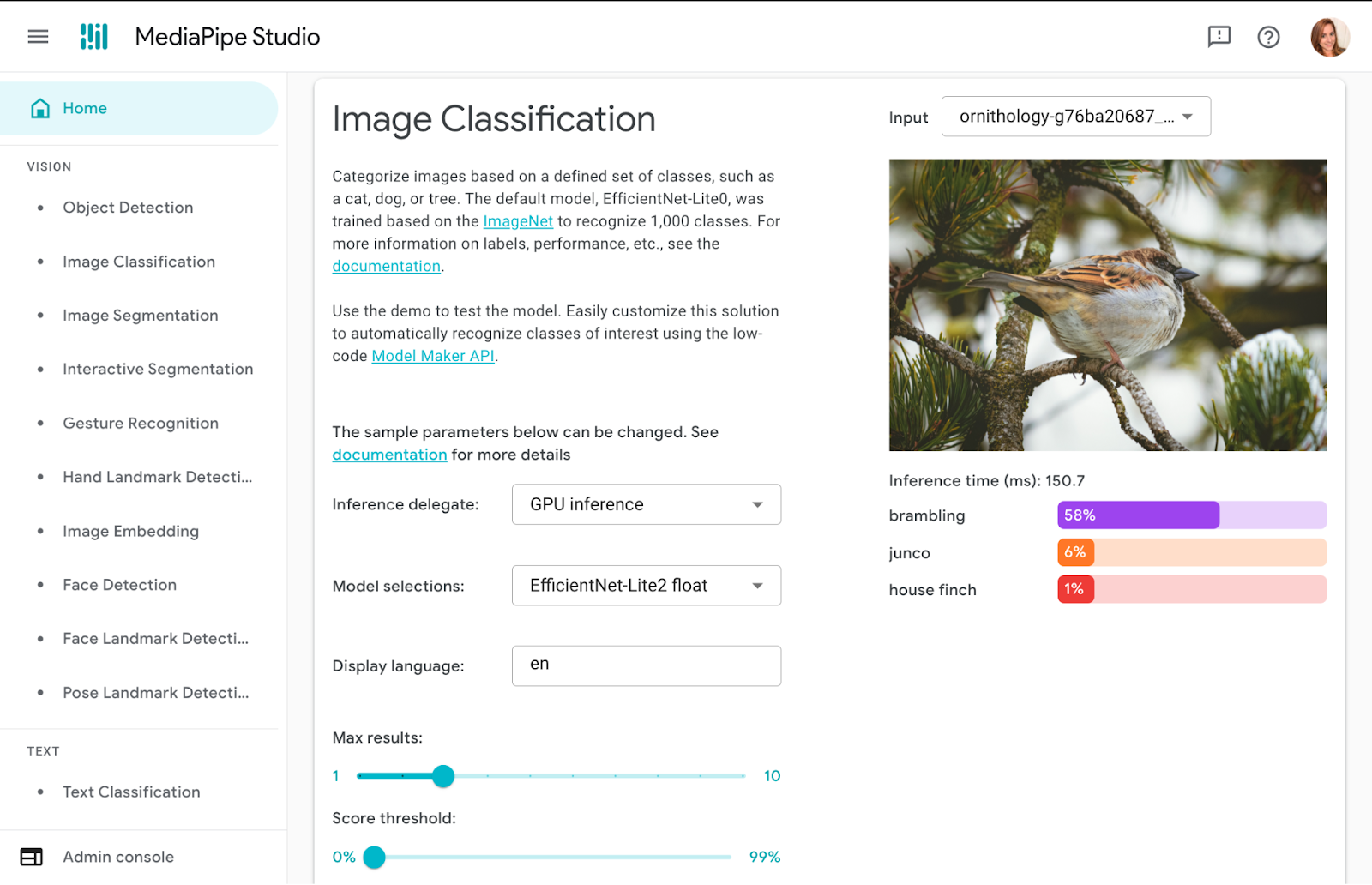
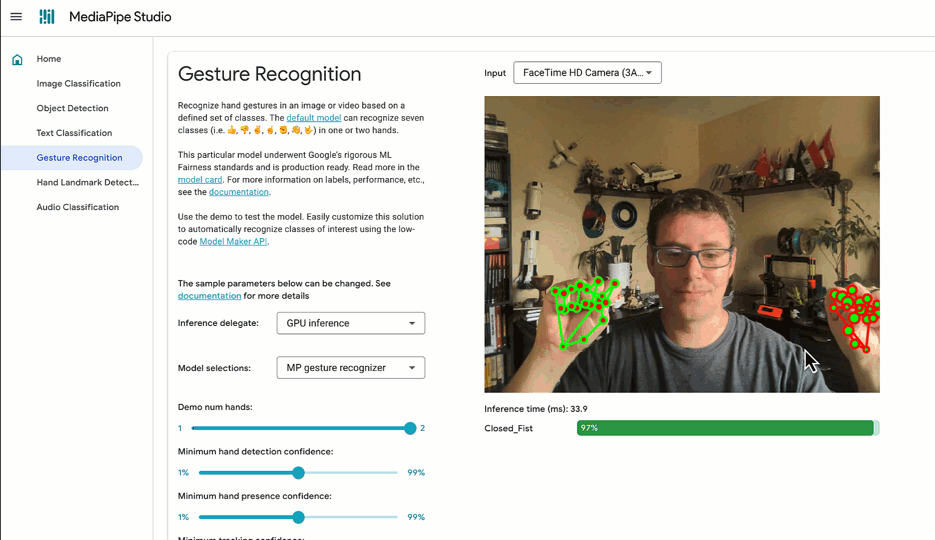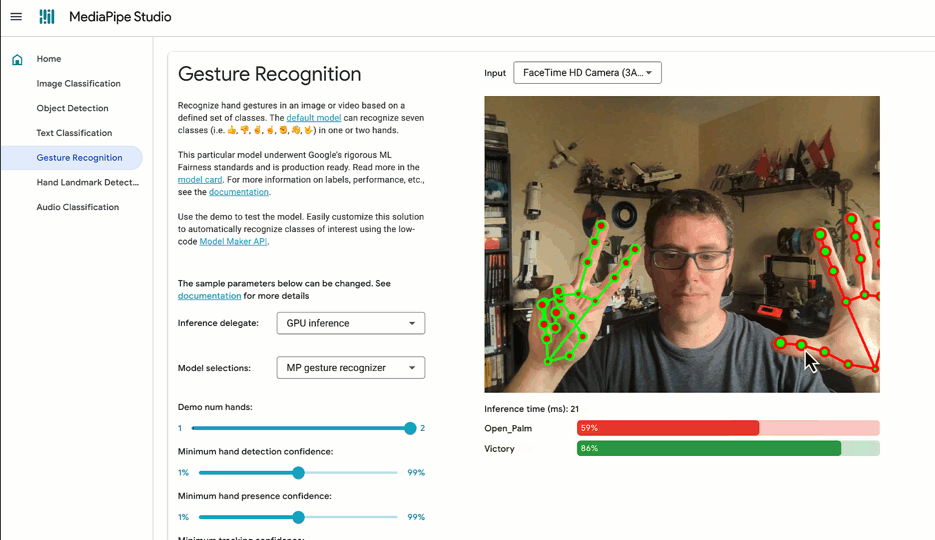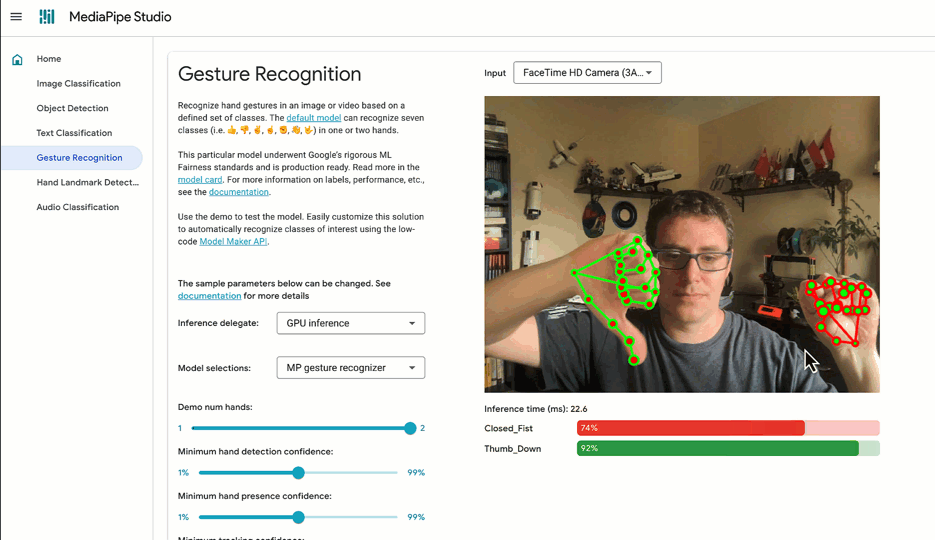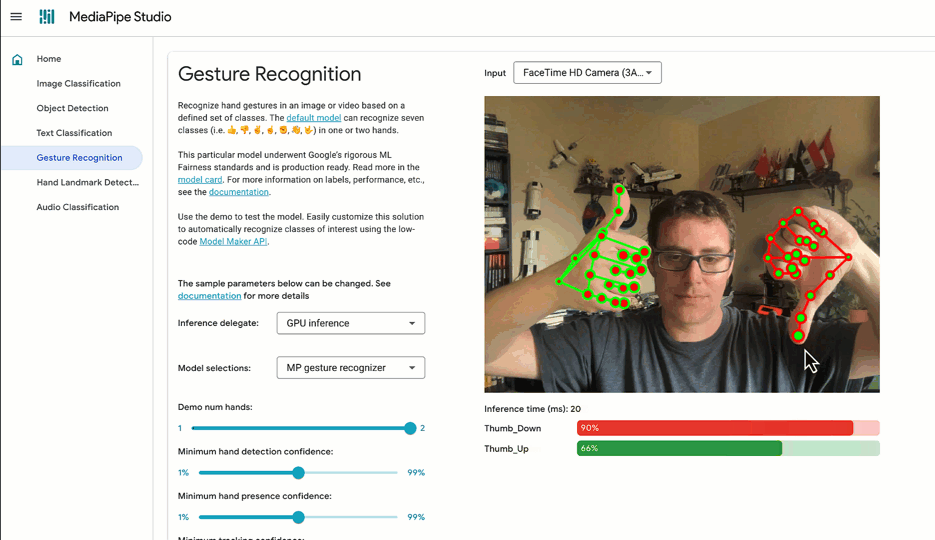
✅ DO try out tasks in MediaPipe Studio
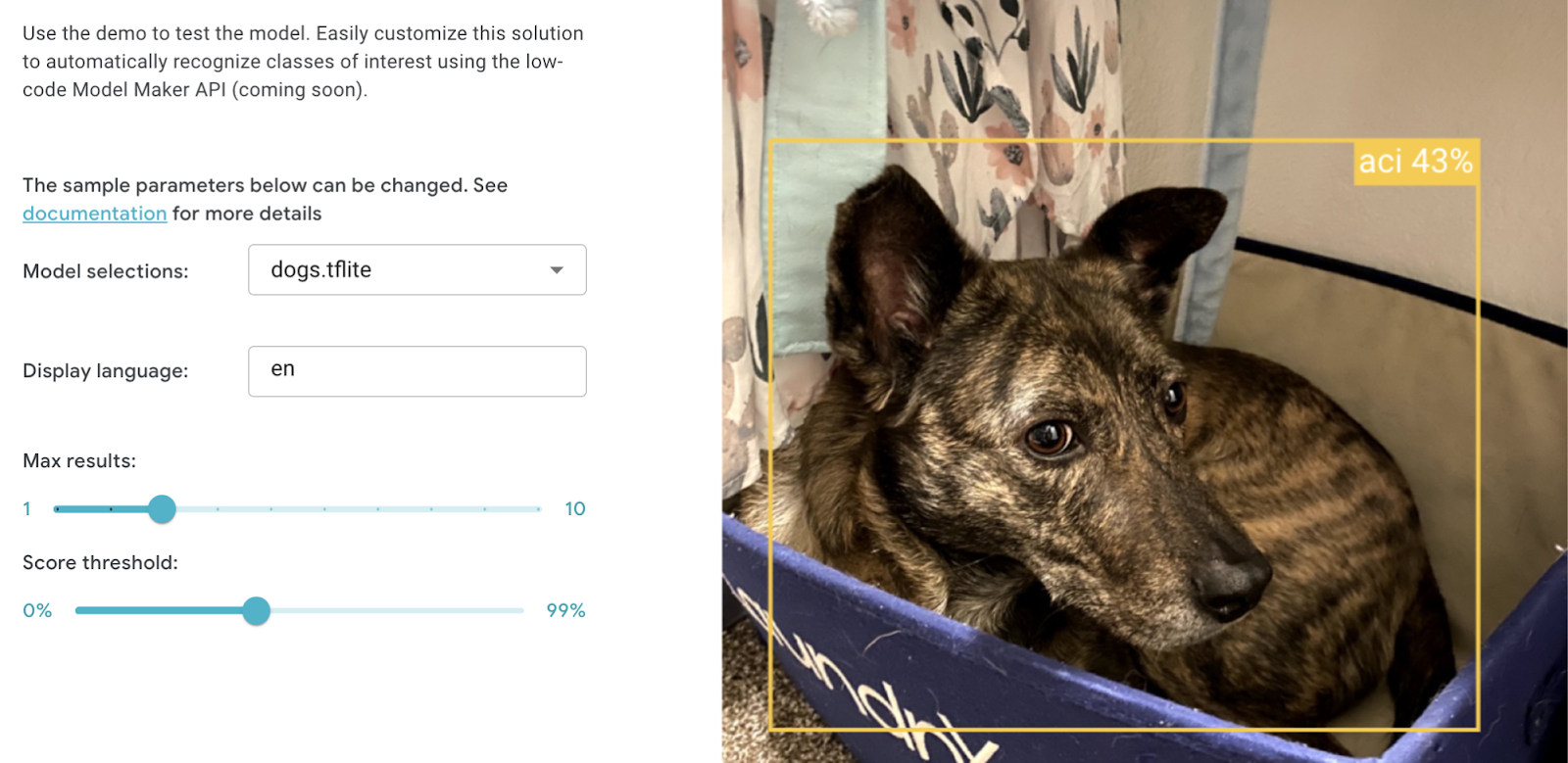
When deciding on or customizing your solution, it's a good idea to try it out in MediaPipe Studio before writing your own code. MediaPipe Studio is a web-based application for evaluating and customizing on-device ML models and pipelines for your applications. The app lets you quickly test MediaPipe solutions in your browser with your own data, and your own customized ML models. Each solution demo also lets you experiment with model settings for the total number of results, minimum confidence threshold for reporting results, and more. You'll find this especially useful when customizing solutions so you can see how your model performs without needing to create a test web page.
✅ DO test on different devices
It's always important to test your web apps on various devices and browsers to ensure they work as expected, but I think it's worth adding a reminder here to test early and often on a variety of platforms. You can use MediaPipe Studio to test devices as well so you know right away that a solution will work on your users' devices.
❌ DON'T default to the biggest model
Each task lists one or more recommended models. For example, the Object Detection task lists three different models, each with benefits and drawbacks based on speed, size and accuracy. It can be tempting to think that the most important thing is to choose the model with the very highest accuracy, but if you do so, you will be sacrificing speed and increasing the size of your model. Depending on your use case, your users might benefit from a faster result rather than a more accurate one. The best way to compare model options is in MediaPipe Studio. I realize that this is starting to sound like an advertisement for MediaPipe Studio, but it really does come in handy here!

✅ DO reach out!
Do you have any dos or don'ts of ML on the web that you think I missed? Do you have questions about how to get started? Or do you have a cool project you want to share? Reach out to me on LinkedIn and tell me all about it!
 Posted by
Posted by 





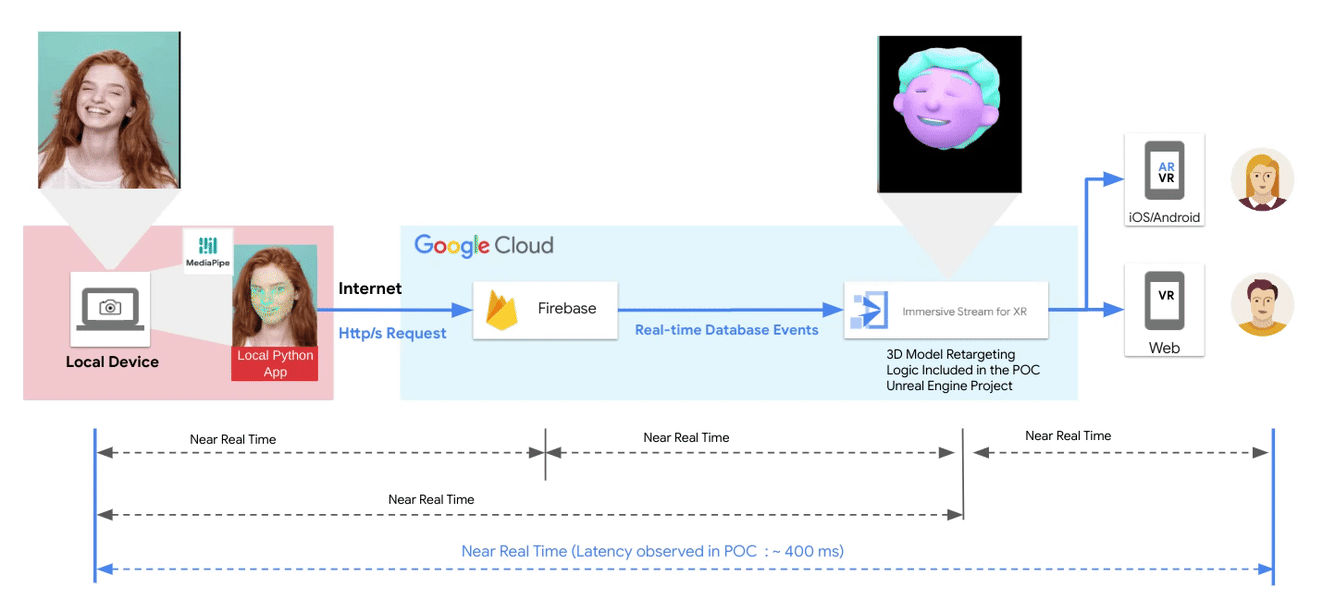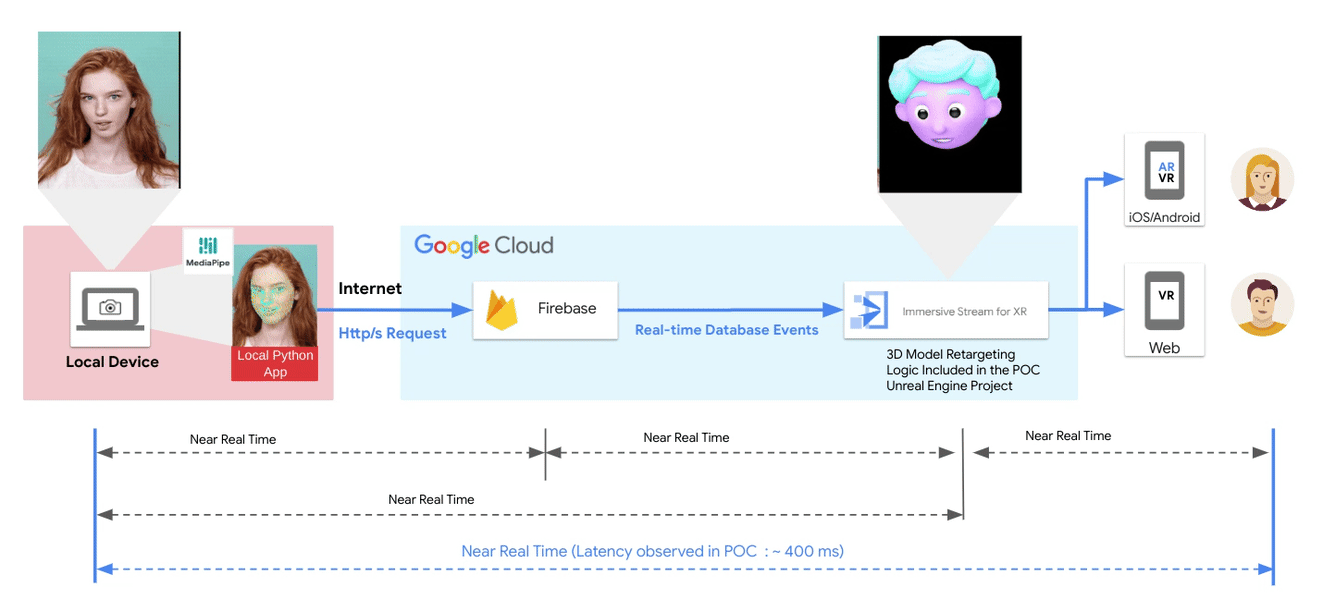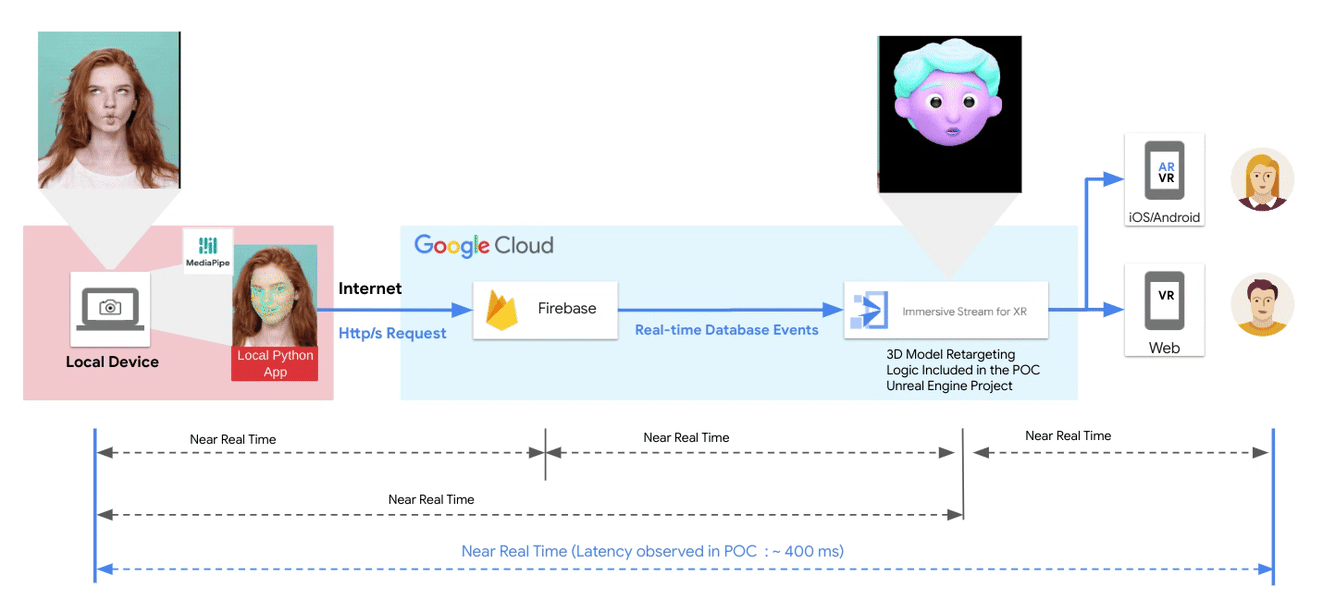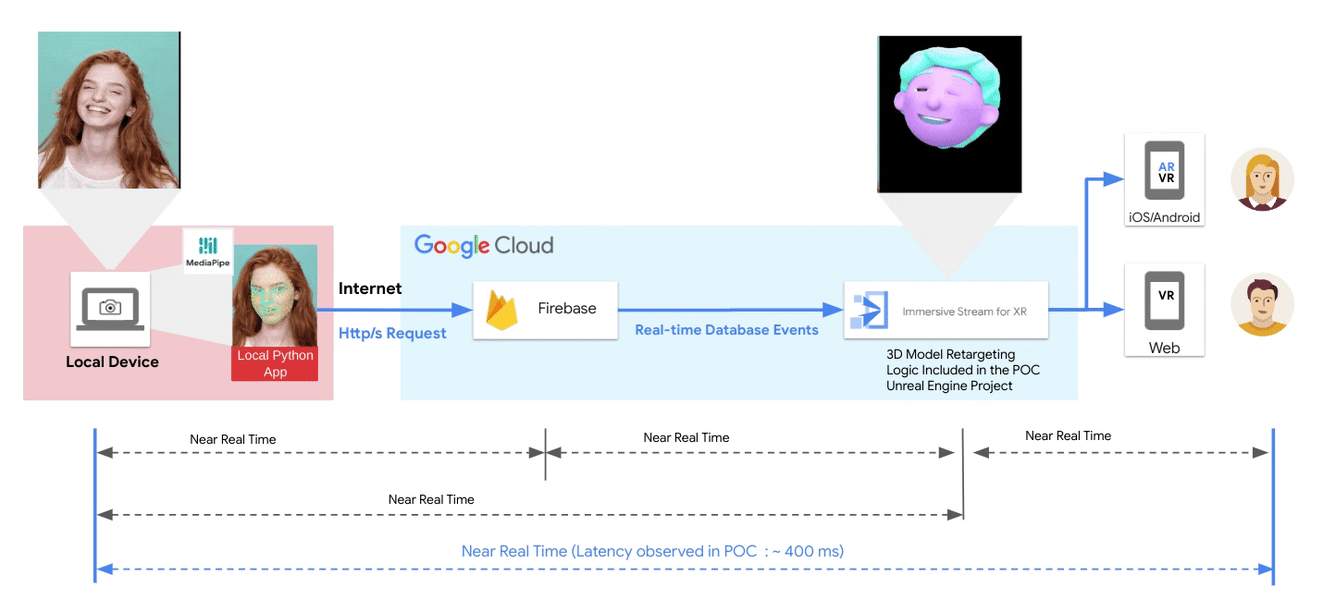








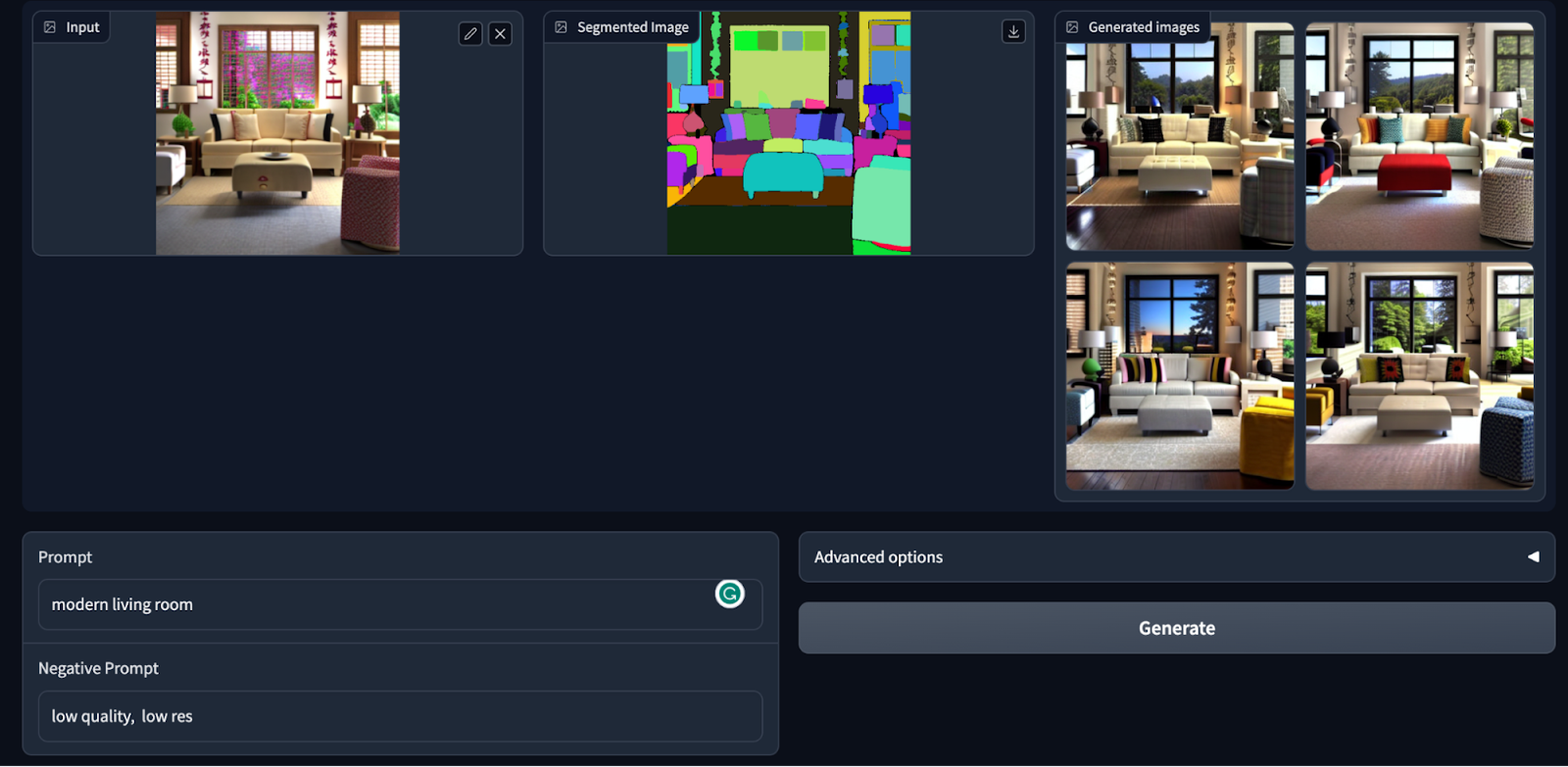

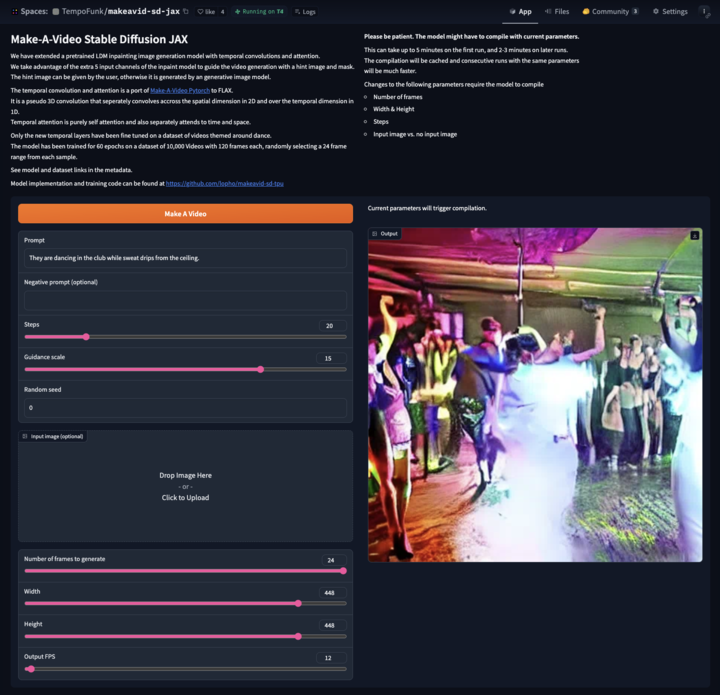


 Posted by Paul Ruiz, Developer Relations Engineer & Kris Tonthat, Technical Writer
Posted by Paul Ruiz, Developer Relations Engineer & Kris Tonthat, Technical Writer











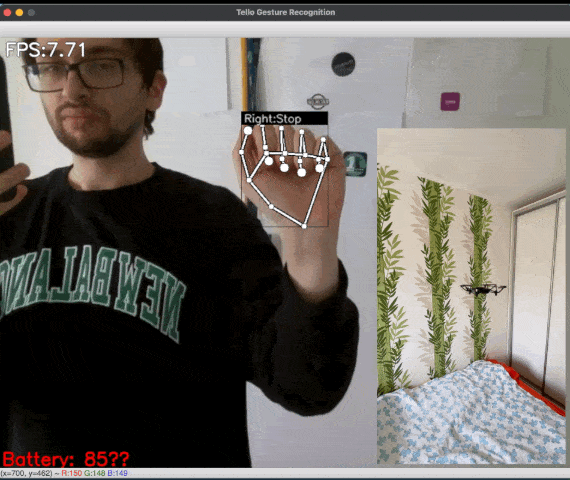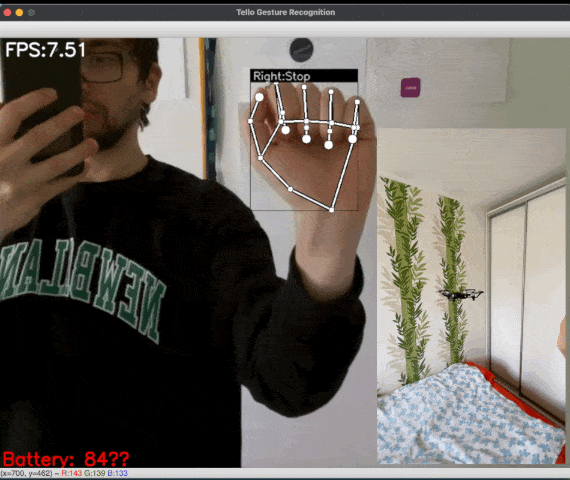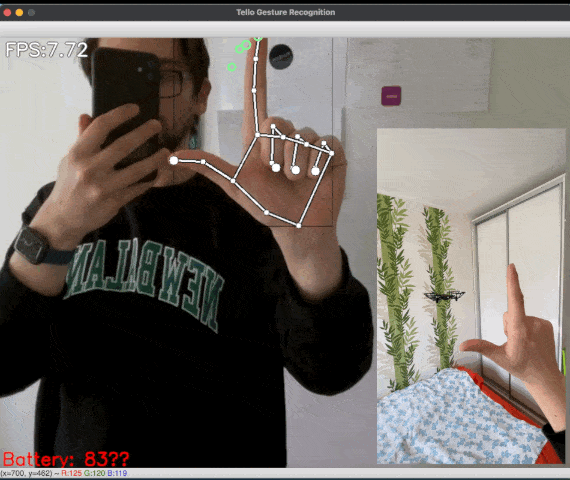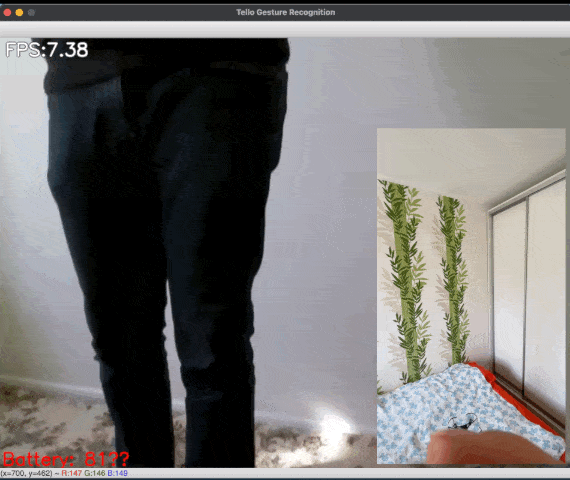

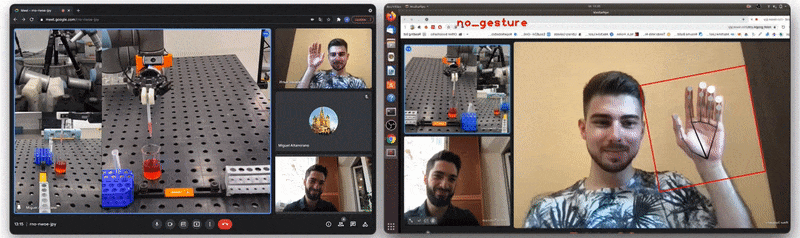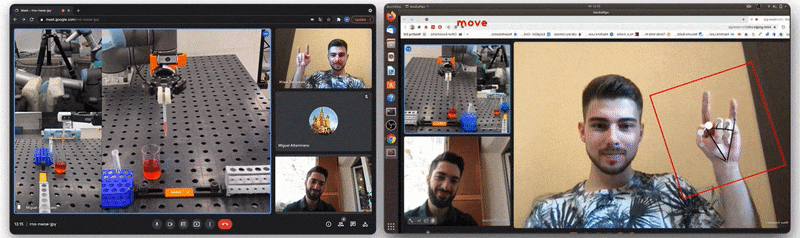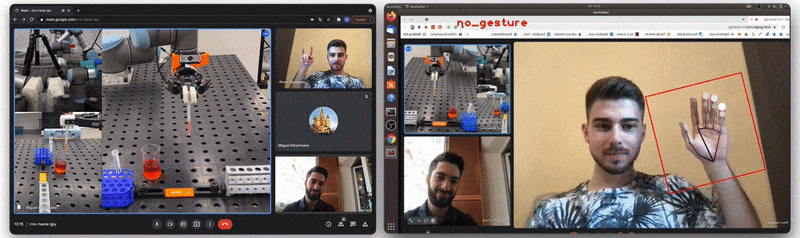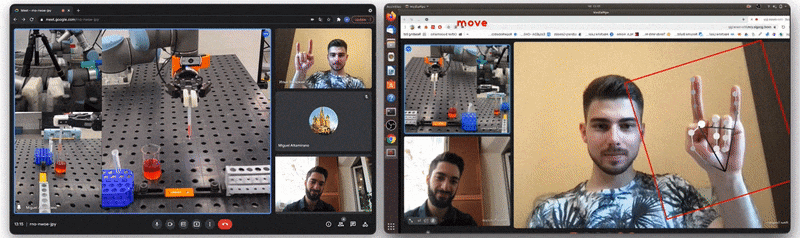
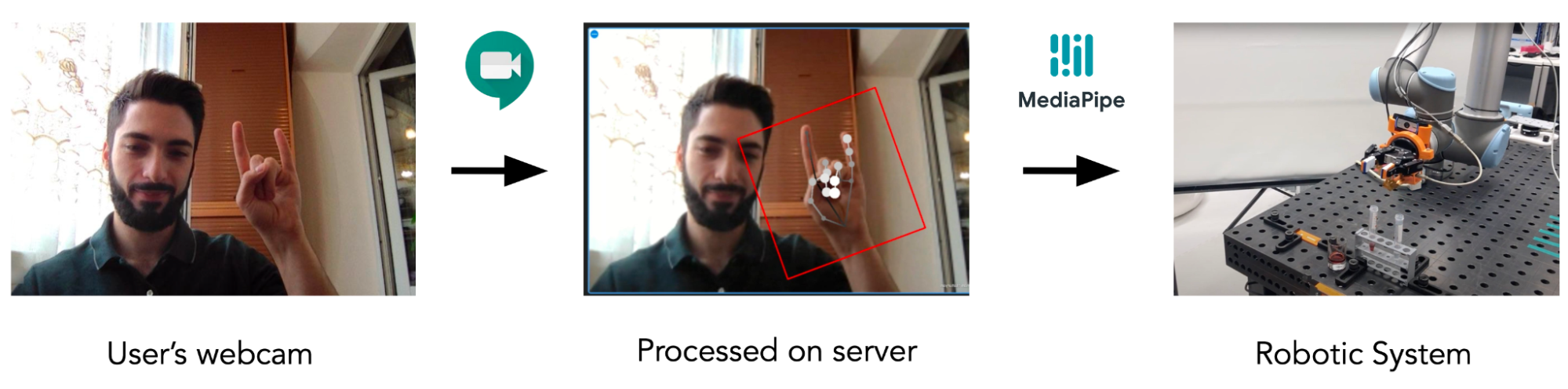
![Figure 5: [GIF] Test that demonstrates how fast classification network can distinguish newly trained gestures using the information from MediaPipe hand detector](https://1.bp.blogspot.com/-P79noq5JrSM/YTqBpNUHNJI/AAAAAAAAKwI/Xp1WqAMKAJckPIX1CPUDfGOVn8evY_djQCLcBGAsYHQ/s0/figure%2B5.gif)



{kind=link}