 Posted by Miguel Guevara, Product Manager, Privacy and Data Protection Office
Posted by Miguel Guevara, Product Manager, Privacy and Data Protection Office
 At Google, it’s our responsibility to keep users safe online and ensure they’re able to enjoy the products and services they love while knowing their personal information is private and secure. We’re able to do more with less data through the development of our privacy-enhancing technologies (PETs) like differential privacy and federated learning.
At Google, it’s our responsibility to keep users safe online and ensure they’re able to enjoy the products and services they love while knowing their personal information is private and secure. We’re able to do more with less data through the development of our privacy-enhancing technologies (PETs) like differential privacy and federated learning.And throughout the global tech industry, we’re excited to see that adoption of PETs is on the rise. The UK’s Information Commissioner’s Office (ICO) recently published guidance for how organizations including local governments can start using PETs to aid with data minimization and compliance with data protection laws. Consulting firm Gartner predicts that within the next two years, 60% of all large organizations will be deploying PETs in some capacity.
We’re on the cusp of mainstream adoption of PETs, which is why we also believe it’s our responsibility to share new breakthroughs and applications from our longstanding development and investment in this space. By open sourcing dozens of our PETs over the past few years, we’ve made them freely available for anyone – developers, researchers, governments, business and more – to use in their own work, helping unlock the power of data sets without revealing personal information about users.
As part of this commitment, we open-sourced a first-of-its-kind Fully Homomorphic Encryption (FHE) transpiler two years ago, and have continued to remove barriers to entry along the way. FHE is a powerful technology that allows you to perform computations on encrypted data without being able to access sensitive or personal information and we’re excited to share our latest developments that were born out of collaboration with our developer and research community to expand what can be done with FHE.
Furthering the adoption of Fully Homomorphic Encryption
Today, we are introducing additional tools to help the community apply FHE technologies to video files. This advancement is important because video adoption can often be expensive and incur long run times, limiting the ability to scale FHE use to larger files and new formats.
This will encourage developers to try out more complex applications with FHE. Historically, FHE has been thought of as an intractable technology for large-scale applications. Our results processing large video files show it is possible to do FHE in previously unimaginable domains.Say you’re a developer at a company and are thinking of processing a large file (in the TBs order of magnitude, can be a video, or a sequence of characters) for a given task (e.g., convolution around specific data points to do a blurry filter on a video or detect object movement), you can now try this task using FHE.
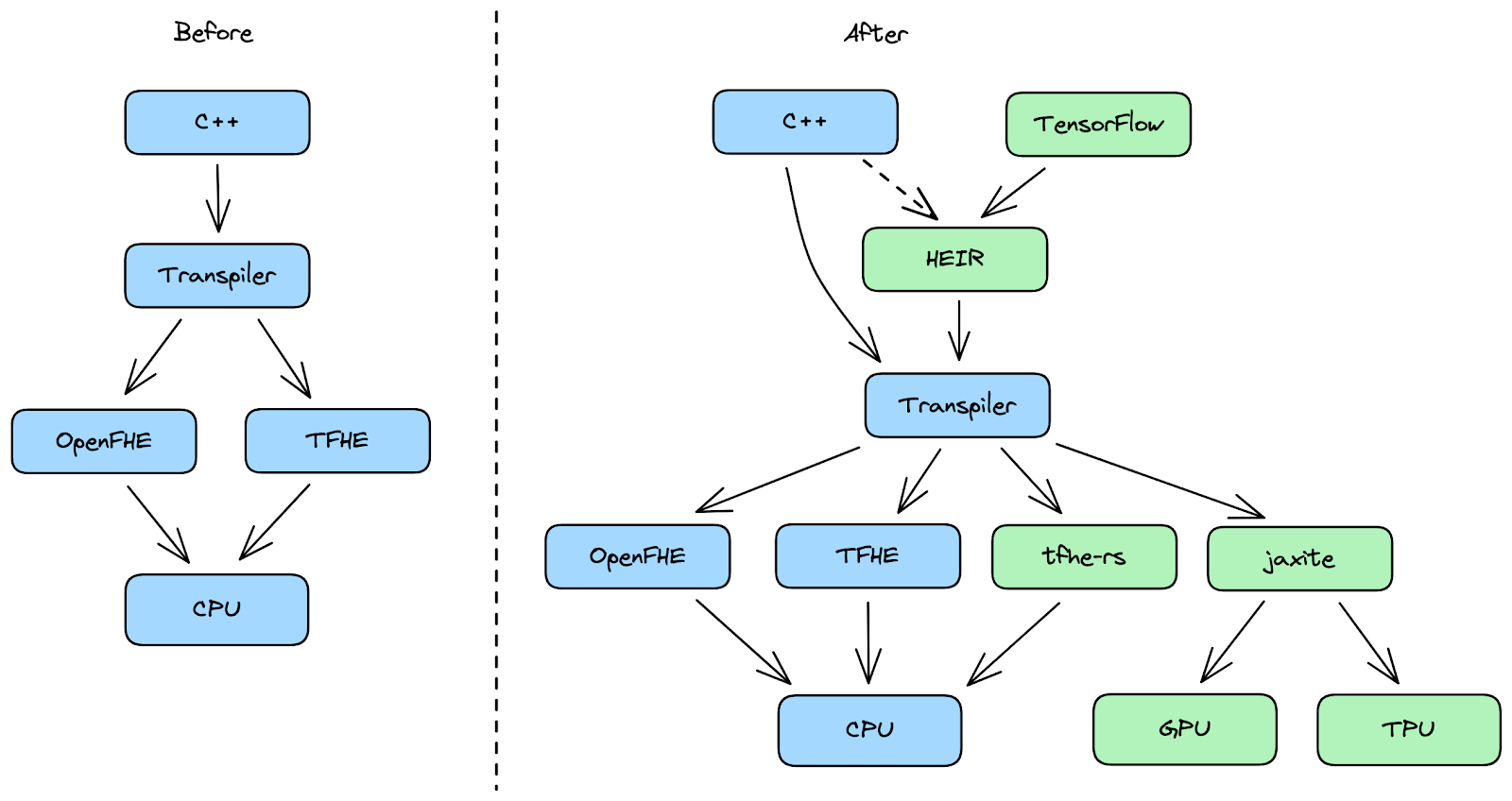
To do so, we are expanding our FHE toolkit in three new ways to make it easier for developers to use FHE for a wider range of applications, such as private machine learning, text analysis, and video processing. As part of our toolkit, we will release new hardware, a software crypto library and an open source compiler toolchain. Our goal is to provide these new tools to researchers and developers to help advance how FHE is used to protect privacy while simultaneously lowering costs.
Expanding our toolkit
We believe—with more optimization and specialty hardware — there will be a wider amount of use cases for a myriad of similar private machine learning tasks, like privately analyzing more complex files, such as long videos, or processing text documents. Which is why we are releasing a TensorFlow-to-FHE compiler that will allow any developer to compile their trained TensorFlow Machine Learning models into a FHE version of those models.
Once a model has been compiled to FHE, developers can use it to run inference on encrypted user data without having access to the content of the user inputs or the inference results. For instance, our toolchain can be used to compile a TensorFlow Lite model to FHE, producing a private inference in 16 seconds for a 3-layer neural network. This is just one way we are helping researchers analyze large datasets without revealing personal information.
In addition, we are releasing Jaxite, a software library for cryptography that allows developers to run FHE on a variety of hardware accelerators. Jaxite is built on top of JAX, a high-performance cross-platform machine learning library, which allows Jaxite to run FHE programs on graphics processing units (GPUs) and Tensor Processing Units (TPUs). Google originally developed JAX for accelerating neural network computations, and we have discovered that it can also be used to speed up FHE computations.
Finally, we are announcing Homomorphic Encryption Intermediate Representation (HEIR), an open-source compiler toolchain for homomorphic encryption. HEIR is designed to enable interoperability of FHE programs across FHE schemes, compilers, and hardware accelerators. Built on top of MLIR, HEIR aims to lower the barriers to privacy engineering and research. We will be working on HEIR with a variety of industry and academic partners, and we hope it will be a hub for researchers and engineers to try new optimizations, compare benchmarks, and avoid rebuilding boilerplate. We encourage anyone interested in FHE compiler development to come to our regular meetings, which can be found on the HEIR website.
 |
Building advanced privacy technologies and sharing them with others
Organizations and governments around the world continue to explore how to use PETs to tackle societal challenges and help developers and researchers securely process and protect user data and privacy. At Google, we’re continuing to improve and apply these novel data processing techniques across many of our products, and investing in democratizing access to the PETs we’ve developed. We believe that every internet user deserves world-class privacy, and we continue to partner with others to further that goal. We’re excited for new testing and partnerships on our open source PETs and will continue investing in innovations, aiming at releasing more updates in the future.
These principles are the foundation for everything we make at Google and we’re proud to be an industry leader in developing and scaling new privacy-enhancing technologies (PETs) that make it possible to create helpful experiences while protecting our users’ privacy.PETs are a key part of our Protected Computing effort at Google, which is a growing toolkit of technologies that transforms how, when and where data is processed to technically ensure its privacy and safety. And keeping users safe online shouldn’t stop with Google - it should extend to the whole of the internet. That’s why we continue to innovate privacy technologies and make them widely available to all.
 Posted by Danny Rozenblit, Developer Marketing
Posted by Danny Rozenblit, Developer Marketing



 Posted by Yiling Liu, Product Manager, Google Partner Innovation
Posted by Yiling Liu, Product Manager, Google Partner Innovation