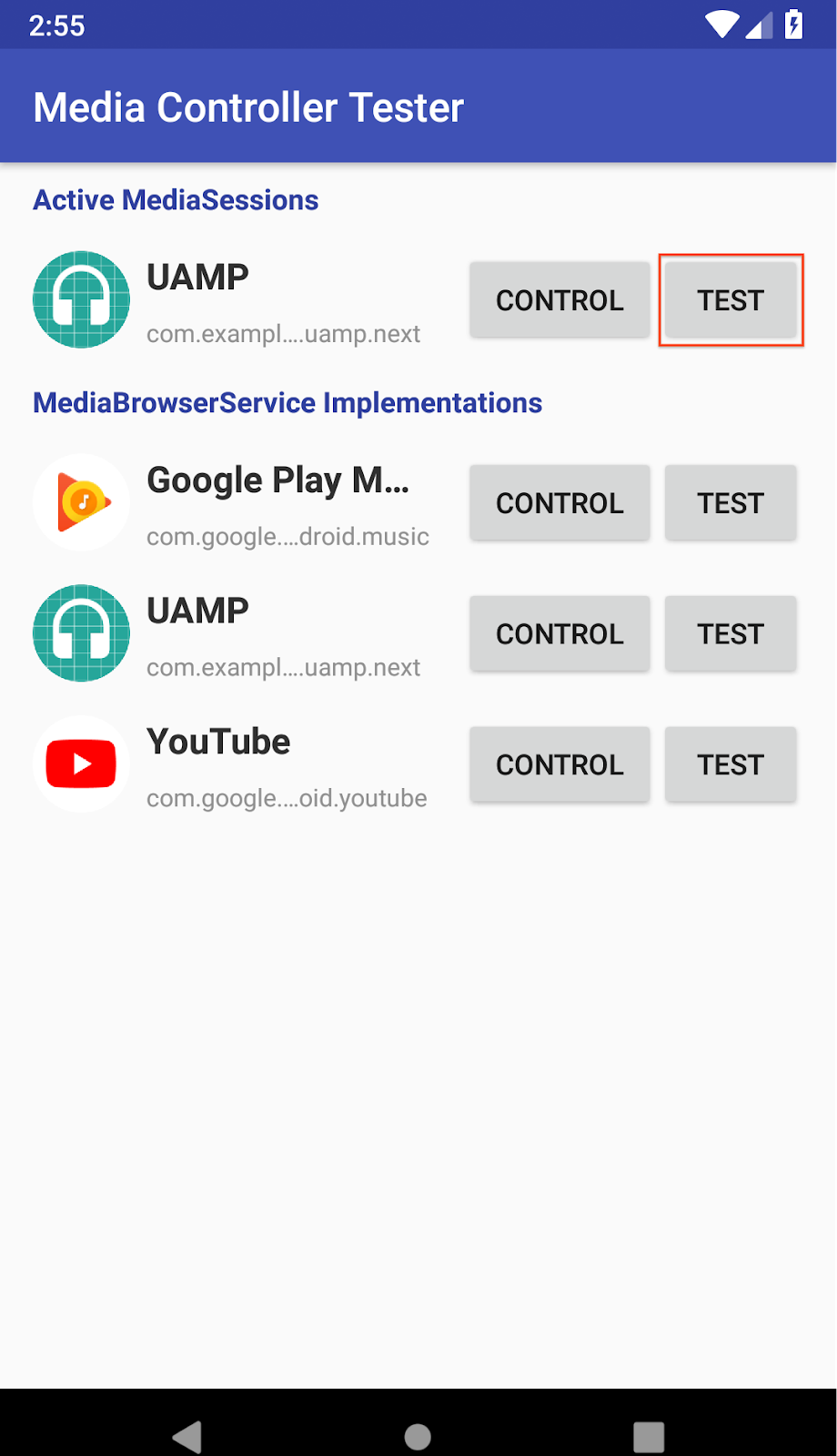
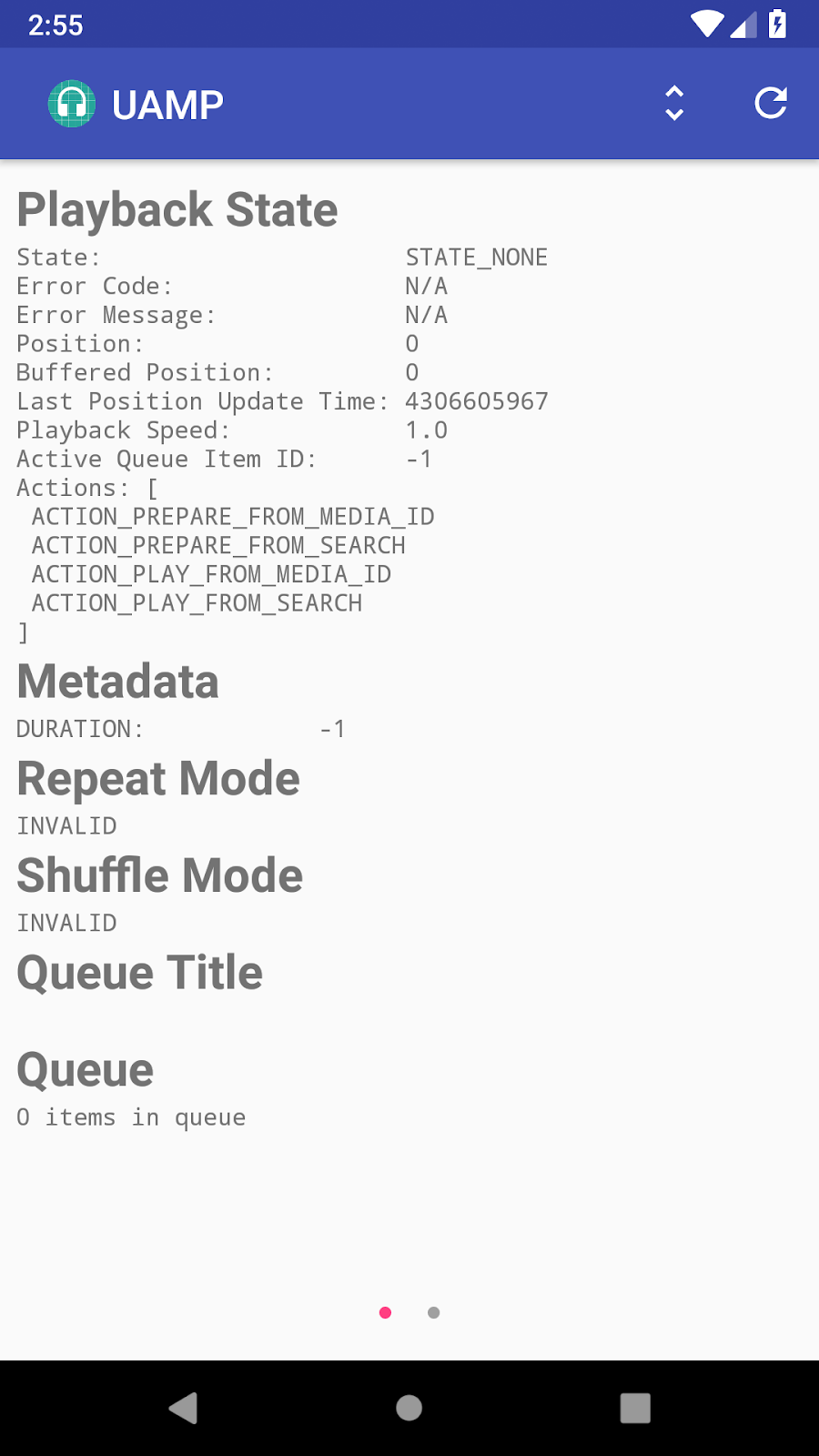
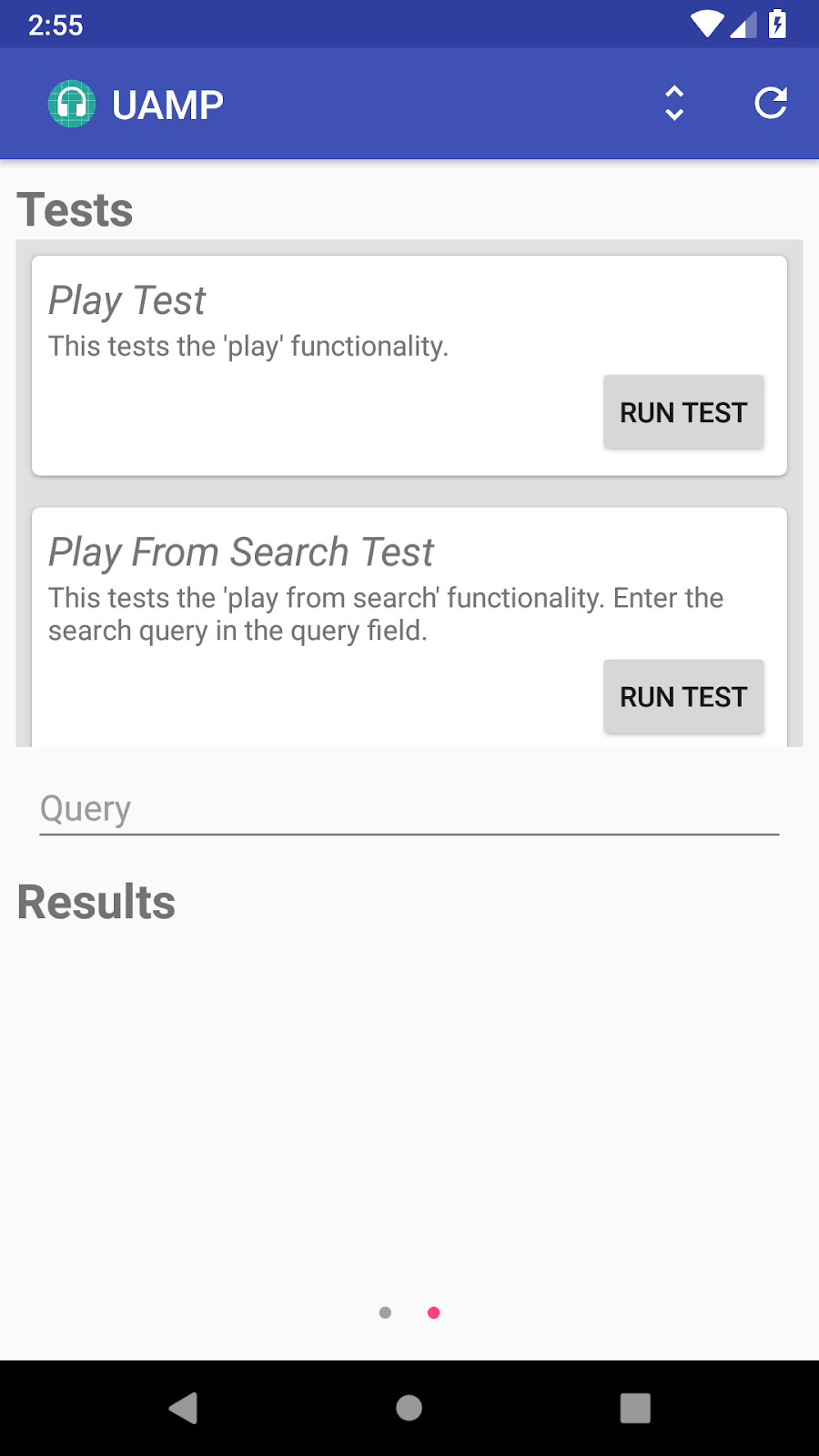
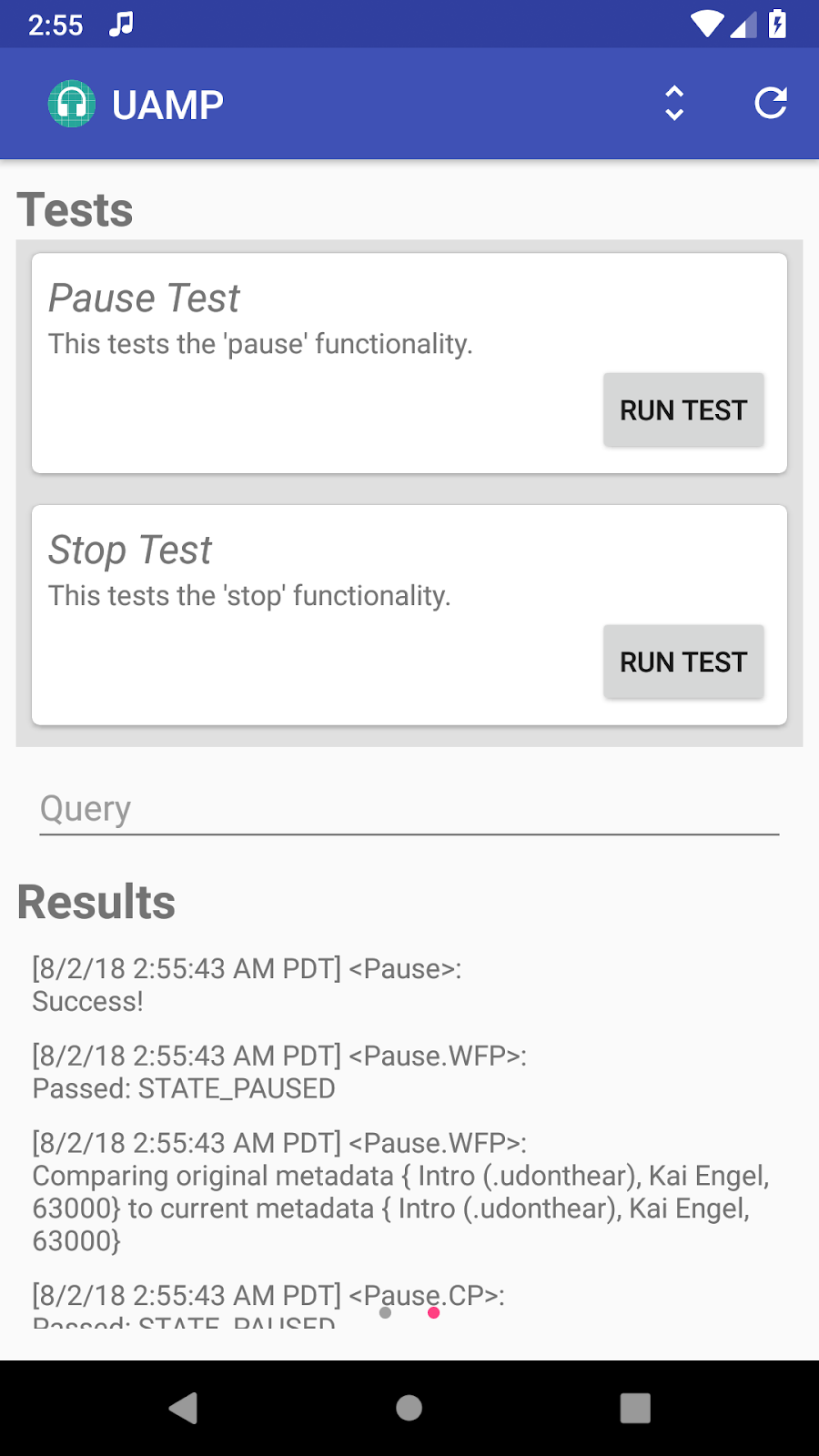
Ten years ago, Google planted the seeds for two foundational web media technologies, hoping they would provide the roots for a more vibrant internet. Two acquisitions, On2 Technologies and Global IP Solutions, led to a pair of open source projects: the WebM Project, a family of cutting edge video compression technologies (codecs) offered by Google royalty-free, and the WebRTC Project building APIs for real-time voice and video communication on the web.
These initiatives were major technical endeavors, essential infrastructure for enabling the promise of HTML5 with support for video conferencing and streaming. But this was also a philosophical evolution for media as Product Manager Mike Jazayeri noted in his blog post hailing the launch of the WebM Project:
A decade later, these principles have ensured compression and communication technologies capable of keeping pace with a web ecosystem characterized by exponential growth of media consumption, devices, and demand. Starting from VP8 in 2010, the WebM Project has delivered up to 50% video bitrate savings with VP9 in 2013 and an additional 30% with AV1 in 2018—with adoption by YouTube, Facebook, Netflix, Twitch, and more. Equally importantly, the WebM team co-founded the Alliance for Open Media which has brought the IP of over 40 major tech companies in support of open and free codecs. With Chrome, Edge, Firefox and Safari supporting WebRTC, more than 85% of all installed browsers globally have become a client for real-time communications on the Internet. WebRTC has become a stable standard and it is now the default solution for video calling on the Web. These technologies have succeeded together, as today over 90% of encoded WebRTC video in Chrome uses VP8 or VP9.
The need for these technologies has been highlighted by COVID-19, as people across the globe have found new ways to work, educate, and connect with loved ones via video chat. The compression of open codecs has been essential to keeping services running on limited bandwidth, with over a billion hours of VP9 and AV1 content viewed every day. WebRTC has allowed for an ecosystem of interoperable communications apps to flourish: since the beginning of March 2020, we have seen in Chrome a 13X increase in received video streams via WebRTC.
These successes would not have been possible without all the supporters that make an open source community. Thank you to all the code contributors, testers, bug filers, and corporate partners who helped make this ecosystem a reality. A decade in, Google remains as committed as ever to open media on the web. We look forward to continuing that work with all of you in the next decade and beyond.
These initiatives were major technical endeavors, essential infrastructure for enabling the promise of HTML5 with support for video conferencing and streaming. But this was also a philosophical evolution for media as Product Manager Mike Jazayeri noted in his blog post hailing the launch of the WebM Project:
“A key factor in the web’s success is that its core technologies such as HTML, HTTP, TCP/IP, etc. are open and freely implementable.”As emerging first-class participants in the web experience, media and communication components also had to be free and open.
A decade later, these principles have ensured compression and communication technologies capable of keeping pace with a web ecosystem characterized by exponential growth of media consumption, devices, and demand. Starting from VP8 in 2010, the WebM Project has delivered up to 50% video bitrate savings with VP9 in 2013 and an additional 30% with AV1 in 2018—with adoption by YouTube, Facebook, Netflix, Twitch, and more. Equally importantly, the WebM team co-founded the Alliance for Open Media which has brought the IP of over 40 major tech companies in support of open and free codecs. With Chrome, Edge, Firefox and Safari supporting WebRTC, more than 85% of all installed browsers globally have become a client for real-time communications on the Internet. WebRTC has become a stable standard and it is now the default solution for video calling on the Web. These technologies have succeeded together, as today over 90% of encoded WebRTC video in Chrome uses VP8 or VP9.
The need for these technologies has been highlighted by COVID-19, as people across the globe have found new ways to work, educate, and connect with loved ones via video chat. The compression of open codecs has been essential to keeping services running on limited bandwidth, with over a billion hours of VP9 and AV1 content viewed every day. WebRTC has allowed for an ecosystem of interoperable communications apps to flourish: since the beginning of March 2020, we have seen in Chrome a 13X increase in received video streams via WebRTC.
These successes would not have been possible without all the supporters that make an open source community. Thank you to all the code contributors, testers, bug filers, and corporate partners who helped make this ecosystem a reality. A decade in, Google remains as committed as ever to open media on the web. We look forward to continuing that work with all of you in the next decade and beyond.
By Matt Frost, Product Director Chrome Media and Niklas Blum, Senior Product Manager WebRTC






















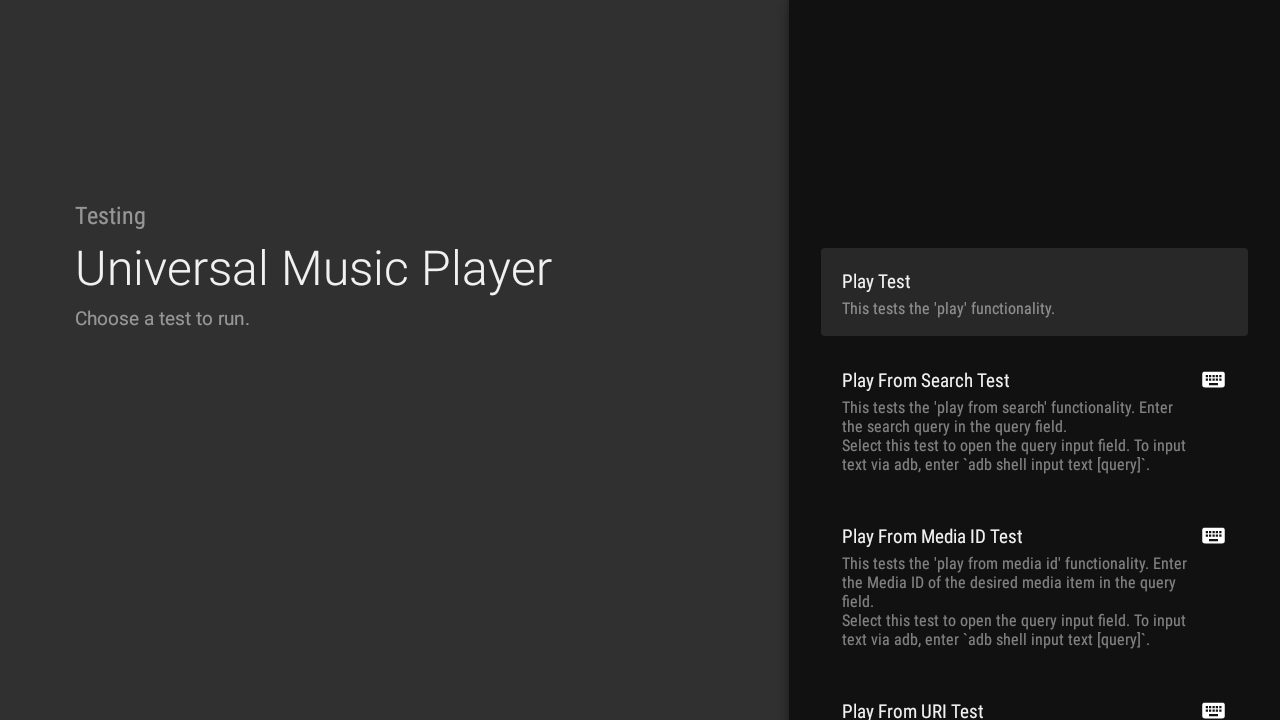
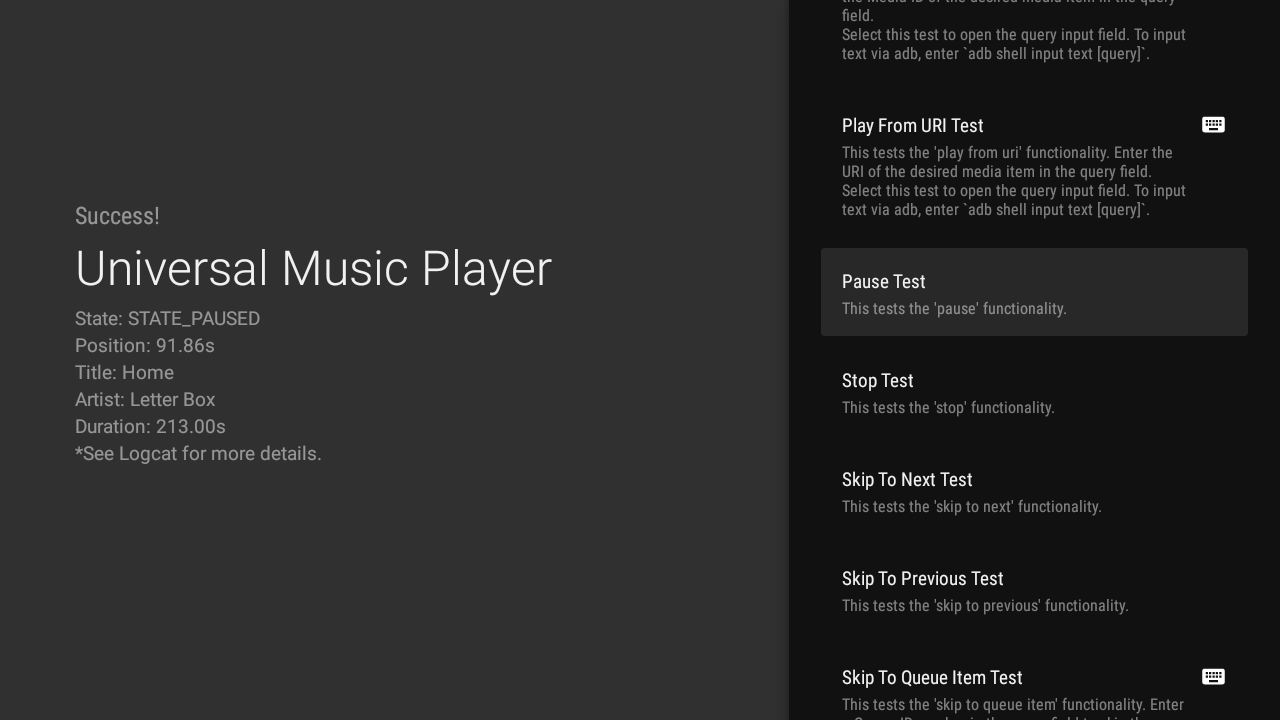
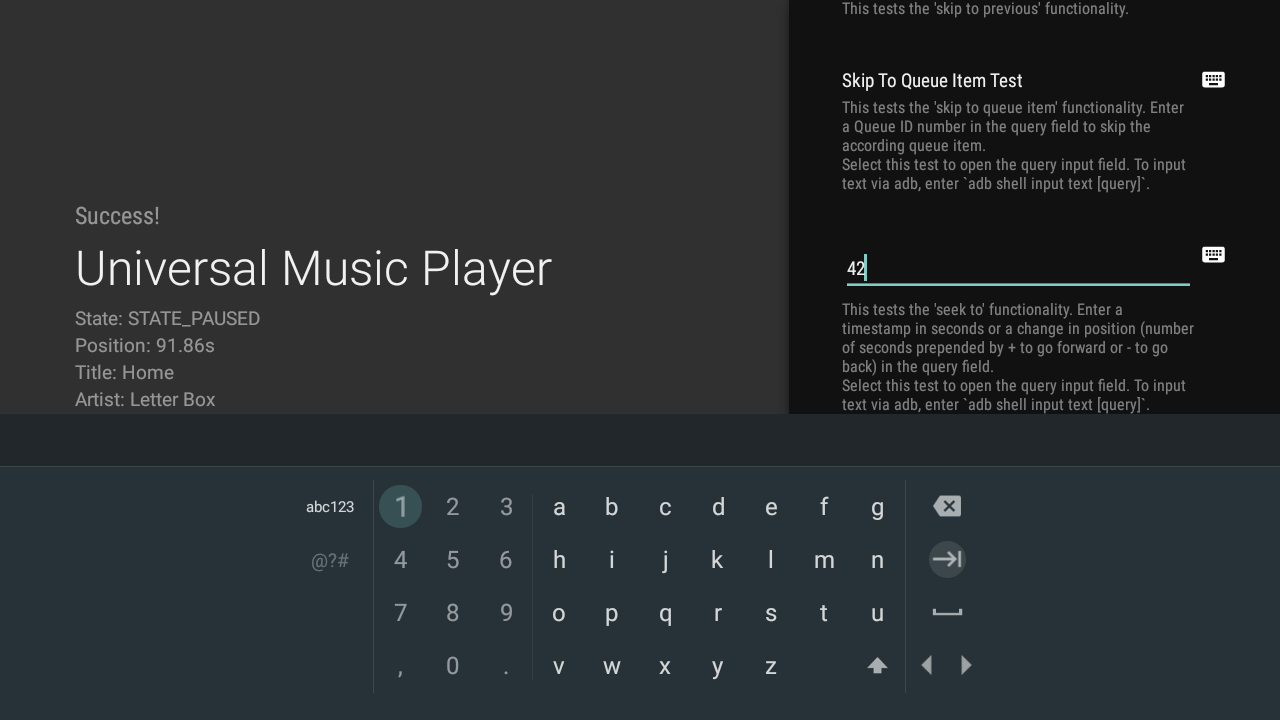
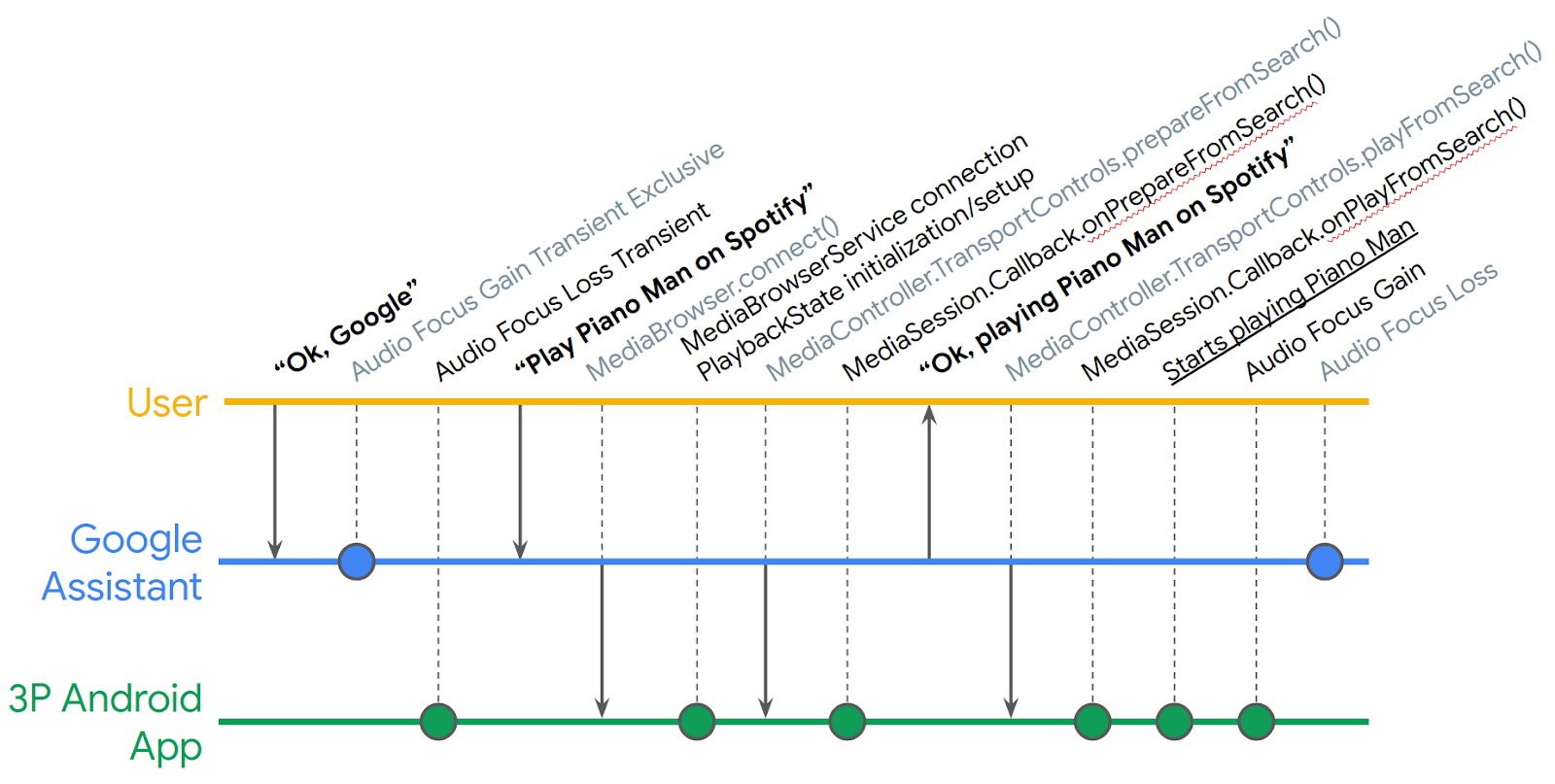 Posted by Nevin Mital, Partner Developer Relations
Posted by Nevin Mital, Partner Developer Relations