Posted by Shan Yang, Software Engineer and Angjoo Kanazawa, Research Scientist, Google Research Dancing is a universal language found in nearly all cultures, and is an outlet many people use to express themselves on contemporary media platforms today. The ability to dance by composing movement patterns that align to music beats is a fundamental aspect of human behavior. However, dancing is a form of art that requires practice. In fact, professional training is often required to equip a dancer with a rich repertoire of dance motions needed to create expressive choreography. While this process is difficult for people, it is even more challenging for a machine learning (ML) model, because the task requires the ability to generate a continuous motion with high kinematic complexity, while capturing the non-linear relationship between the movements and the accompanying music.
In “AI Choreographer: Music-Conditioned 3D Dance Generation with AIST++”, presented at ICCV 2021, we propose a full-attention cross-modal Transformer (FACT) model can mimic and understand dance motions, and can even enhance a person’s ability to choreograph dance. Together with the model, we released a large-scale, multi-modal 3D dance motion dataset, AIST++, which contains 5.2 hours of 3D dance motion in 1408 sequences, covering 10 dance genres, each including multi-view videos with known camera poses. Through extensive user studies on AIST++, we find that the FACT model outperforms recent state-of-the-art methods, both qualitatively and quantitatively.
|
| We present a novel full-attention cross-modal transformer (FACT) network that can generate realistic 3D dance motion (right) conditioned on music and a new 3D dance dataset, AIST++ (left). |
We generate the proposed 3D motion dataset from the existing AIST Dance Database — a collection of videos of dance with musical accompaniment, but without any 3D information. AIST contains 10 dance genres: Old School (Break, Pop, Lock and Waack) and New School (Middle Hip-Hop, LA-style Hip-Hop, House, Krump, Street Jazz and Ballet Jazz). Although it contains multi-view videos of dancers, these cameras are not calibrated.
For our purposes, we recovered the camera calibration parameters and the 3D human motion in terms of parameters used by the widely used SMPL 3D model. The resulting database, AIST++, is a large-scale, 3D human dance motion dataset that contains a wide variety of 3D motion, paired with music. Each frame includes extensive annotations:
- 9 views of camera intrinsic and extrinsic parameters;
- 17 COCO-format human joint locations in both 2D and 3D;
- 24 SMPL pose parameters along with the global scaling and translation.
The motions are equally distributed among all 10 dance genres, covering a wide variety of music tempos in beat per minute (BPM). Each genre of dance contains 85% basic movements and 15% advanced movements (longer choreographies freely designed by the dancers).
The AIST++ dataset also contains multi-view synchronized image data, making it useful for other research directions, such as 2D/3D pose estimation. To our knowledge, AIST++ is the largest 3D human dance dataset with 1408 sequences, 30 subjects and 10 dance genres, and with both basic and advanced choreographies.
 |
| An example of a 3D dance sequence in the AIST++ dataset. Left: Three views of the dance video from the AIST database. Right: Reconstructed 3D motion visualized in 3D mesh (top) and skeletons (bottom). |
Because AIST is an instructional database, it records multiple dancers following the same choreography for different music with varying BPM, a common practice in dance. This posits a unique challenge in cross-modal sequence-to-sequence generation as the model needs to learn the one-to-many mapping between audio and motion. We carefully construct non-overlapping train and test subsets on AIST++ to ensure neither choreography nor music is shared across the subsets.
Full Attention Cross-Modal Transformer (FACT) Model
Using this data, we train the FACT model to generate 3D dance from music. The model begins by encoding seed motion and audio inputs using separate motion and audio transformers. The embeddings are then concatenated and sent to a cross-modal transformer, which learns the correspondence between both modalities and generates N future motion sequences. These sequences are then used to train the model in a self-supervised manner. All three transformers are jointly learned end-to-end. At test time, we apply this model in an autoregressive framework, where the predicted motion serves as the input to the next generation step. As a result, the FACT model is capable of generating long range dance motion frame-by-frame.
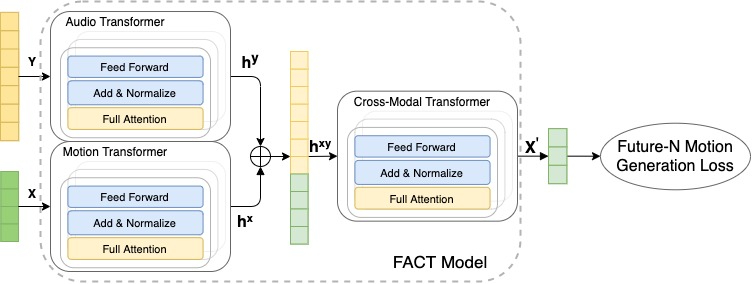 |
| The FACT network takes in a music piece (Y) and a 2-second sequence of seed motion (X), then generates long-range future motions that correlate with the input music. |
FACT involves three key design choices that are critical for producing realistic 3D dance motion from music.
- All of the transformers use a full-attention mask, which can be more expressive than typical causal models because internal tokens have access to all inputs.
- We train the model to predict N futures beyond the current input, instead of just the next motion. This encourages the network to pay more attention to the temporal context, and helps prevent the model from motion freezing or diverging after a few generation steps.
- We fuse the two embeddings (motion and audio) early and employ a deep 12-layer cross-modal transformer module, which is essential for training a model that actually pays attention to the input music.
Results
We evaluate the performance based on three metrics:
Motion Quality: We calculate the Frechet Inception Distance (FID) between the real dance motion sequences in the AIST++ test set and 40 model generated motion sequences, each with 1200 frames (20 secs). We denote the FID based on the geometric and kinetic features as FIDg and FIDk, respectively.
Generation Diversity: Similar to prior work, to evaluate the model’s ability to generate divers dance motions, we calculate the average Euclidean distance in the feature space across 40 generated motions on the AIST++ test set, again comparing geometric feature space (Distg) and in the kinetic feature space (Distk).
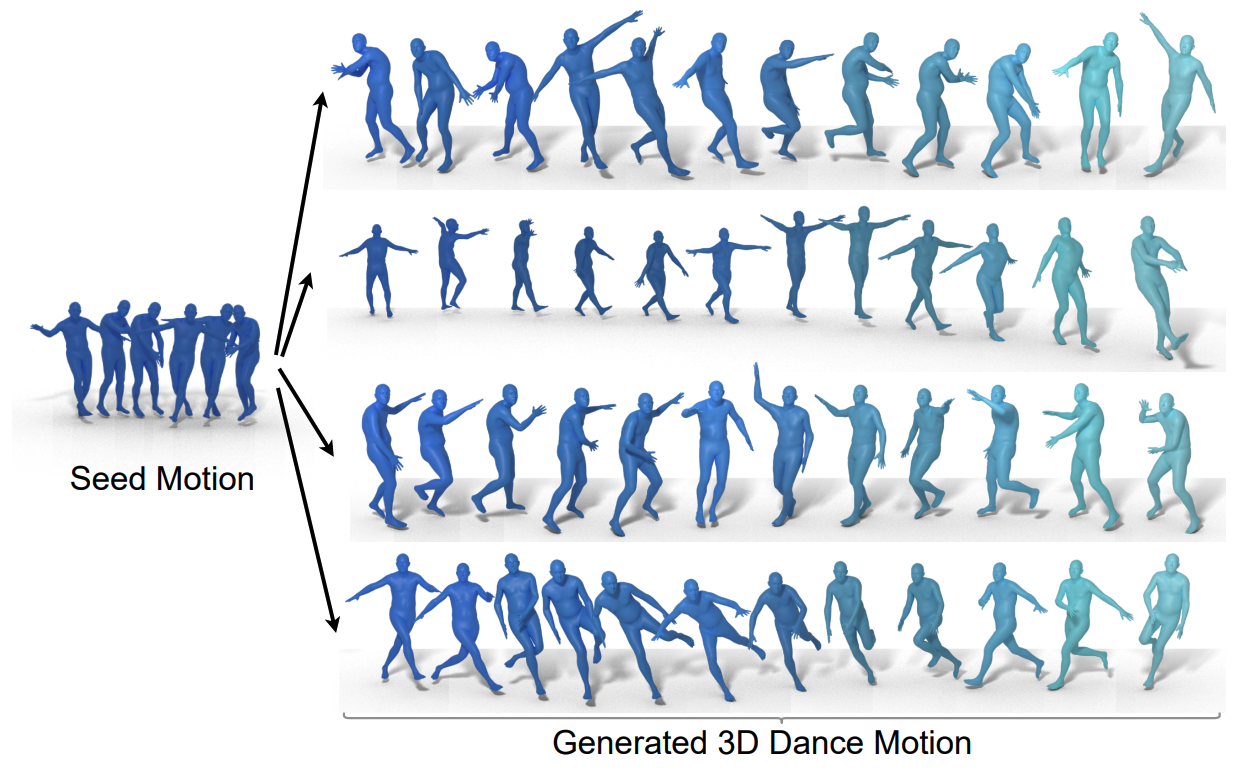 |
| Four different dance choreographies (right) generated using different music, but the same two second seed motion (left). The genres of the conditioning music are: Break, Ballet Jazz, Krump and Middle Hip-hop. The seed motion comes from hip-hop dance. |
Motion-Music Correlation: Because there is no well-designed metric to measure the correlation between input music (music beats) and generated 3D motion (kinematic beats), we propose a novel metric, called Beat Alignment Score (BeatAlign).
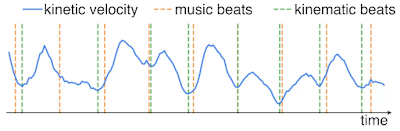 |
| Kinetic velocity (blue curve) and kinematic beats (green dotted line) of the generated dance motion, as well as the music beats (orange dotted line). The kinematic beats are extracted by finding local minima from the kinetic velocity curve. |
Quantitative Evaluation
We compare the performance of FACT on each of these metrics to that of other state-of-the-art methods.
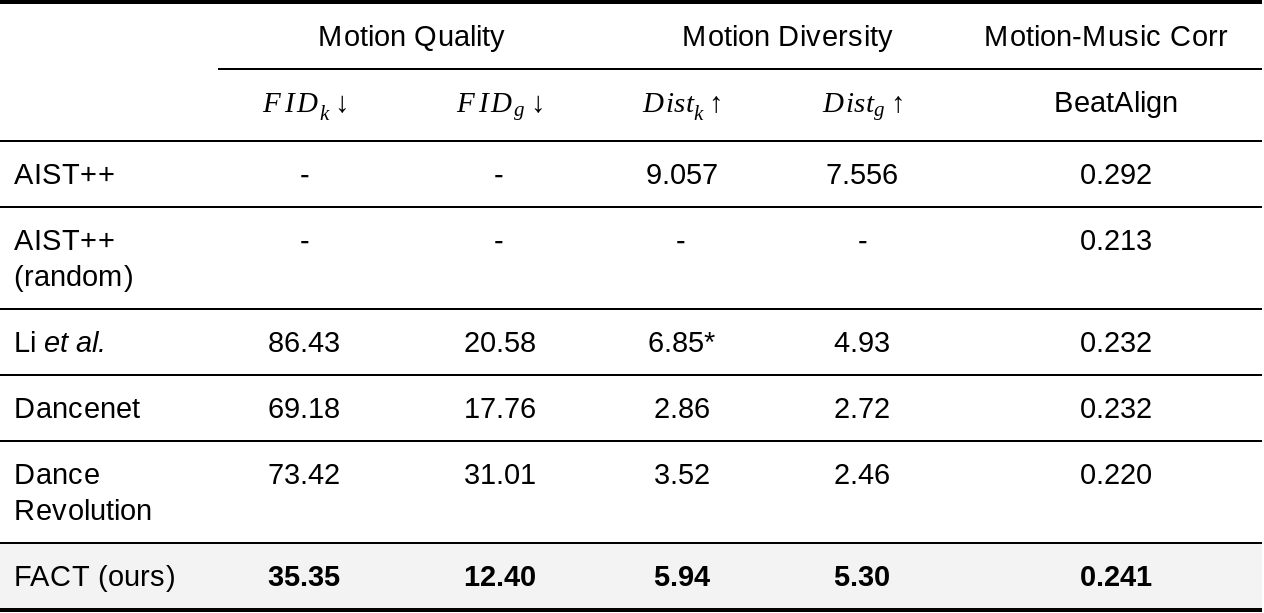 |
| Compared to three recent state-of-the-art methods (Li et al., Dancenet, and Dance Revolution), the FACT model generates motions that are more realistic, better correlated with input music, and more diversified when conditioned on different music. *Note that the Li et al. generated motions are discontinuous, making the average kinetic feature distance abnormally high. |
We also perceptually evaluate the motion-music correlation with a user study in which each participant is asked to watch 10 videos showing one of our results and one random counterpart, and then select which dancer is more in sync with the music. The study consisted of 30 participants, ranging from professional dancers to people who rarely dance. Compared to each baseline, 81% prefered the FACT model output to that of Li et al., 71% prefered FACT to Dancenet, and 77% prefered it Dance Revolution. Interestingly, 75% of participants preferred the unpaired AIST++ dance motion to that generated by FACT, which is unsurprising since the original dance captures are highly expressive.
Qualitative Results
Compared with prior methods like DanceNet (left) and Li et. al. (middle), 3D dance generated using the FACT model (right) is more realistic and better correlated with input music.
More generated 3D dances using the FACT model.
Conclusion and Discussion
We present a model that can not only learn the audio-motion correspondence, but also can generate high quality 3D motion sequences conditioned on music. Because generating 3D movement from music is a nascent area of study, we hope our work will pave the way for future cross-modal audio to 3D motion generation. We are also releasing AIST++, the largest 3D human dance dataset to date. This proposed, multi-view, multi-genre, cross-modal 3D motion dataset can not only help research in the conditional 3D motion generation research but also human understanding research in general. We are releasing the code in our GitHub repository and the trained model here.
While our results show a promising direction in this problem of music conditioned 3D motion generation, there are more to be explored. First, our approach is kinematic-based and we do not reason about physical interactions between the dancer and the floor. Therefore the global translation can lead to artifacts, such as foot sliding and floating. Second, our model is currently deterministic. Exploring how to generate multiple realistic dances per music is an exciting direction.
Acknowledgements
We gratefully acknowledge the contribution of other co-authors, including Ruilong Li and David Ross. We thank Chen Sun, Austin Myers, Bryan Seybold and Abhijit Kundu for helpful discussions. We thank Emre Aksan and Jiaman Li for sharing their code. We also thank Kevin Murphy for the early attempts in this direction, as well as Peggy Chi and Pan Chen for the help on user study experiments.














.png)