 Posted by Francesco Romano – Developer Relations Engineer on Android
Posted by Francesco Romano – Developer Relations Engineer on Android

App screen sharing improves privacy and productivity
Android 14 QPR2 brings exciting advancements in user privacy and streamlined multitasking with app screen sharing. No longer do users have to broadcast their entire screen while screen sharing or casting, ensuring they share exactly what they want to share.
Leverage the new MediaProjection APIs to customize the screen sharing experience and deliver even greater utility to your users.
What is app screen sharing?
Prior to Android 14, users could only share or record their entire screen on Android devices, which could expose private information in other apps or notifications.
App screen sharing is a new platform feature that lets users restrict sharing and recording to a single app window, mitigating the risk of oversharing private messages or notifications. With app screen sharing, the status bar, navigation bar, notifications, and other system UI elements are excluded from the shared display. Only the content of the selected app is shared.
This not only enhances security for screen sharing, but also enables new use cases on large screens. Users can improve multitasking productivity – such as screen sharing while attending a meeting – by taking advantage of extra screen space on these larger devices.
How does it work?
There are three different entry points for users to start app screen sharing:
- Start casting from Quick Settings
- Start screen recording from Quick Settings
- Launch from an app with screen sharing or recording capabilities via the MediaProjection API
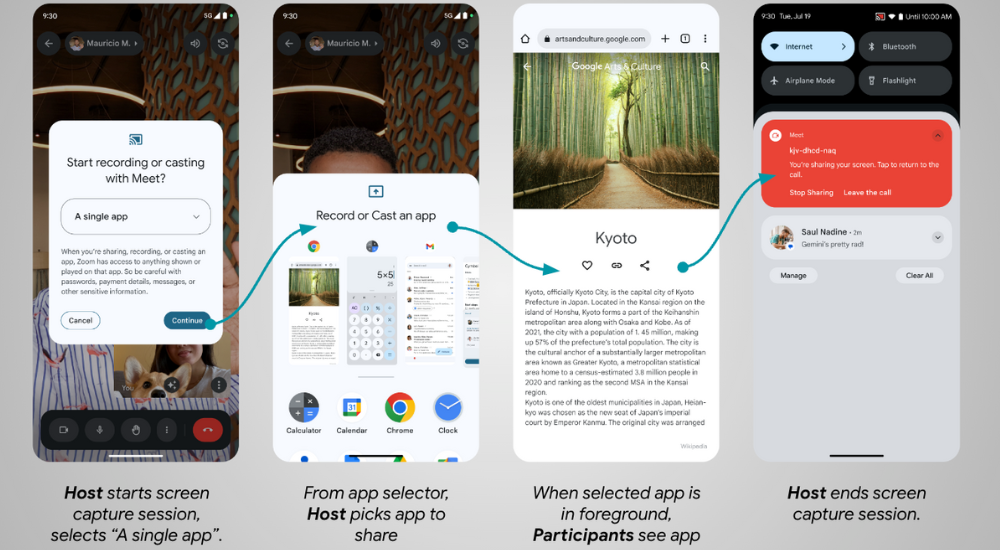
Let’s consider an example where a host user wants to share a single app to the participants of a video call.
The host user starts screen sharing as usual, but now in Android 14 they are presented with an updated dialog that allows them to choose whether to share a single app instead of their entire screen.
The host user decides to share a single app, and they select the app from the App Selector.
During screen sharing, the video call participants can see only the content from the selected app.
The host user can end the screen capture in a few ways: from the app where sharing started, in the notification shade, by closing the app being shared, or by ending the video call.
How to support app screen sharing?
Apps that use the MediaProjection APIs are capable of starting app screen sharing without any code changes. However, it’s important to test your app to ensure that the screen sharing experience works as intended, since the user flow changes with this new behavior. Previously, the user would stay in the host app after the permission dialog. With app screen sharing the user is not returned to the host app, but the target app to be shared is launched instead. If the target app was already running in foreground (e.g. in multi window mode), then it simply becomes the top focused app.
Android 14 also introduces two callback methods to empower you to customize the sharing experience:
MediaProjection.Callback#onCapturedContentResize(width, height) is invoked immediately after capture begins or when the size of the captured region changes. The method arguments provide the accurate sizing for the streamed capture.
Note: The given width and height correspond to the same width and height that would be returned from android.view.WindowMetrics#getBounds() of the captured region.
If the recorded content has a different aspect ratio from either the VirtualDisplay or output Surface, the captured stream has black bars around the recorded content. The application can avoid the black bars around the recorded content by updating the size of both the VirtualDisplay and output Surface:
override fun onCapturedContentResize(width: Int, height: Int): String { // VirtualDisplay instance from MediaProjection#createVirtualDisplay(). virtualDisplay.resize(width, height, dpi) // Create a new Surface with the updated size. val textureName: Int // the OpenGL texture object name val surfaceTexture = SurfaceTexture(textureName) surfaceTexture.setDefaultBufferSize(width, height) val surface = Surface(surfaceTexture) // Ensure the VirtualDisplay has the updated Surface to send the capture to. virtualDisplay.setSurface(surface) }
The other API is MediaProjection.Callback#onCapturedContentVisibilityChanged(isVisible), which is invoked after capture begins or when the visibility of the captured region changes. The method argument indicates the current visibility of the captured region.
The callback is triggered when:
- The captured region becomes invisible (isVisible==False).This may happen when the projected app is not topmost anymore, like when another app entirely covers it, or the user navigates away from the captured app.
- The captured region becomes visible again (isVisible==True).This may happen if the user moves the covering app to show at least some portion of the captured app (for example, the user has multiple apps visible in multi-window mode).
Applications can take advantage of this callback by showing or hiding the captured content from the output Surface based on whether the captured region is currently visible to the user. You should pause or resume the sharing accordingly in order to conserve resources.
How Google Meet is improving meeting productivity
“App screen sharing enables users to share specific information in a Meet call without oversharing private information on the screen like messages and notifications. Users can choose specific apps to share, or they can share the whole screen as before. Additionally, users can leverage split-screen mode on large screen devices to share content while still seeing the faces of friends, families, coworkers, and other meeting participants.” - Product Manager at Google Meet
Let’s see app screen sharing in action during a video call, in this coming-soon version of Google Meet!

Window on the world
App screen sharing opens doors (and windows) for more focused and secure app experiences within the Android ecosystem.
This new feature enhances several use cases:
- Collaboration apps can facilitate focused discussion on specific design elements, documents, or spreadsheets without including distracting background details.
- Tech support agents can remotely view the user's problem app without seeing potentially sensitive content in other areas.
- Video conferencing tools can share a presentation window selectively rather than the entire screen.
- Educational apps can demonstrate functionality without compromising student privacy, and students can share projects without fear of showing sensitive information.
By thoughtfully implementing app screen sharing, you can establish your app as a champion of user privacy and convenience.

















































{kind=link}
{kind=link}
{kind=link}
{kind=link}