The history behind Google Webmasters
Merriam-Webster claims the first known use of the word "webmaster" was in 1993, years before Google even existed. However, the term is becoming archaic, and according to the data found in books, its use is in sharp decline. A user experience study we ran revealed that very few web professionals identify themselves as webmasters anymore. They're more likely to call themselves Search Engine Optimizer (SEO), online marketer, blogger, web developer, or site owner, but very few "webmasters".
We're changing our name
In brainstorming our new name, we realized that there's not one term that perfectly summarizes the work people do on websites. To focus more on the topic that we talk about (Google Search), we're changing our name from "Google Webmasters Central" to "Google Search Central", both on our websites and on social media. Our goal is still the same; we aim to help people improve the visibility of their website on Google Search.The change will happen on most platforms in the next couple days.
Centralizing help information to one site
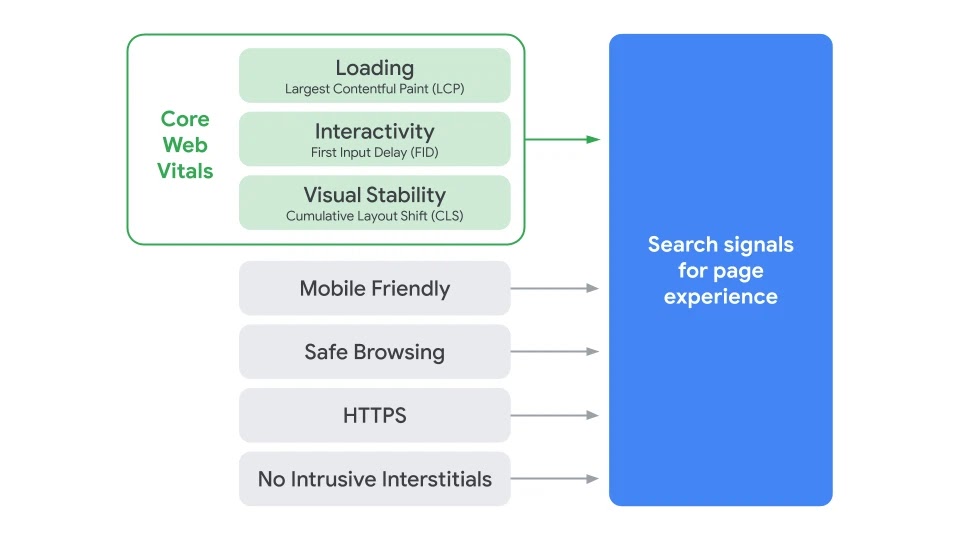
To help people learn how to improve their website's visibility on Google Search, we're also consolidating our help documentation and blogs to one site.
Moving forward, the Search Console Help Center will contain only documentation related to using Search Console. It's also still the home of our help forum, newly renamed from "Webmasters Help Community" to "Google Search Central Community". The information related to how Google Search works, crawling and indexing, Search guidelines, and other Search-related topics are moving to our new site, which previously focused only on web developer documentation. The content move will happen over the next few days.
We will continue to create content for anyone who wants their websites to show up on Google Search, whether you're just getting started with SEO or you're an experienced web professional.
Consolidating the blogs
The blog that you're reading right now is also moving to our main site. However, we will wait one week to allow subscribers to read this last post on the old platform. Moving this blog, including our other 13 localized blogs, to one place brings the following benefits:
- More discovery of related content (help documentation, localized blogs, event information, on one site)
- Easier to switch between languages (no longer have to find the localized blog URL)
- Better platform allows us to maintain content, localize blog post more easily, and format posts consistently
Going forward, all archived and new blog posts will appear on https://developers.google.com/search/blog. You don't need to take any action in order to keep getting updates from us; we will redirect the current set of RSS and email subscribers to the new blog URL.
Googlebot mascot gets a refresh
Our Googlebot mascot is also getting an upgrade. Googlebot's days of wandering the web solo come to a close as a new sidekick joins Googlebot in crawling the internet.

When we first met this curious critter, we wondered, "Is it really a spider?" After some observation, we noticed this spider bot hybrid can jump great distances and sees best when surrounded by green light. We think Googlebot's new best friend is a spider from the genus Phidippus, though it seems to also have bot-like characteristics. Googlebot's been trying out new nicknames for the little spider bot, but they haven't settled on anything yet. Maybe you can help?
As parting words, update your bookmarks and if you have any questions or comments, you can find us on Twitter and in our Google Search Central Help Community.