 Posted by
Posted by 
Software development is undergoing a significant evolution, moving beyond reactive assistants to intelligent agents. These agents don't just offer suggestions; they can create execution plans, utilize external tools, and make complex, multi-file changes. This results in a more capable AI that can iteratively solve challenging problems, fundamentally changing how developers work.
At Google I/O 2025, we offered a glimpse into our work on agentic AI in Android Studio, the integrated development environment (IDE) focused on Android development. We showcased that by combining agentic AI with the built-in portfolio of tools inside of Android Studio, the IDE is able to assist you in developing Android apps in ways that were never possible before. We are now incredibly excited to announce the next frontier in Android development with the availability of 'Agent Mode' for Gemini in Android Studio.
These features are available in the latest Android Studio Narwhal Feature Drop Canary release, and will be rolled out to business tier subscribers in the coming days. As with all new Android Studio features, we invite developers to provide feedback to direct our development efforts and ensure we are creating the tools you need to build better apps, faster.
Agent Mode
Gemini in Android Studio's Agent Mode is a new experimental capability designed to handle complex development tasks that go beyond what you can experience by just chatting with Gemini.
With Agent Mode, you can describe a complex goal in natural language — from generating unit tests to complex refactors — and the agent formulates an execution plan that can span multiple files in your project and executes under your direction. Agent Mode uses a range of IDE tools for reading and modifying code, building the project, searching the codebase and more to help Gemini complete complex tasks from start to finish with minimal oversight from you.
To use Agent Mode, click Gemini in the sidebar, then select the Agent tab, and describe a task you'd like the agent to perform. Some examples of tasks you can try in Agent Mode include:
- Build my project and fix any errors
- Extract any hardcoded strings used across my project and migrate to strings.xml
- Add support for dark mode to my application
- Given an attached screenshot, implement a new screen in my application using Material 3
The agent then suggests edits and iteratively fixes bugs to complete tasks. You can review, accept, or reject the proposed changes along the way, and ask the agent to iterate on your feedback.
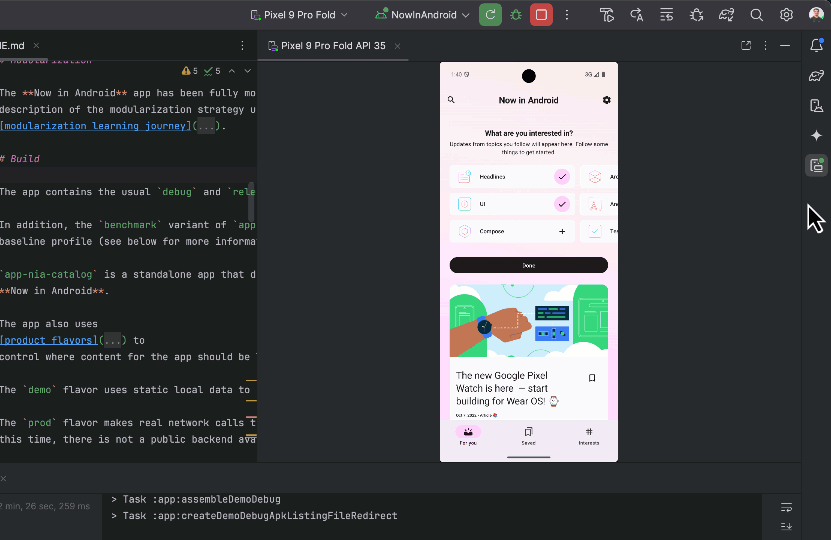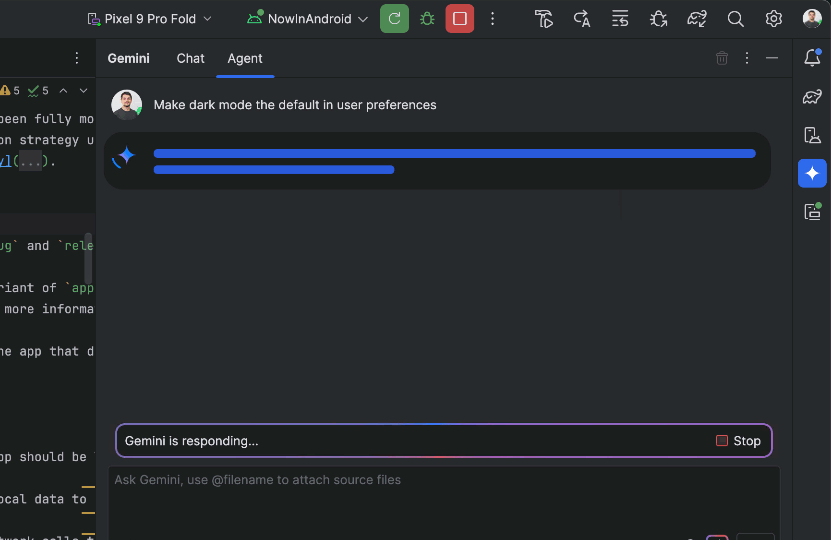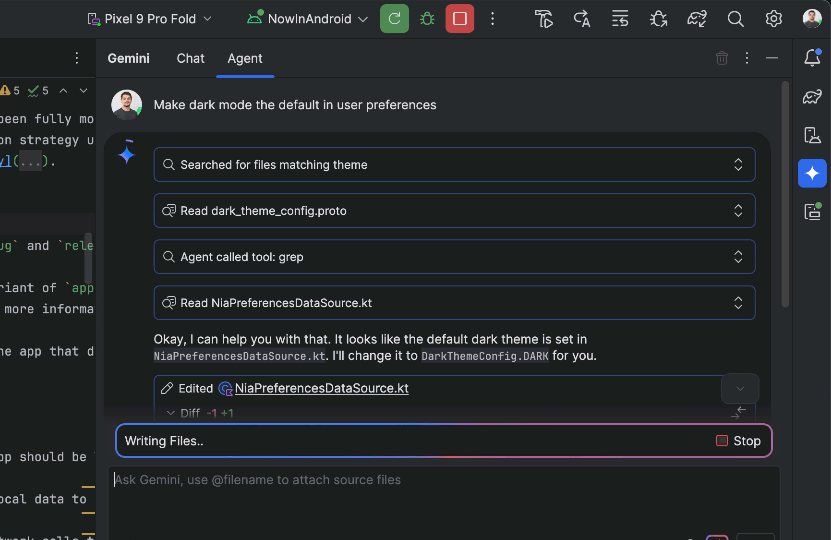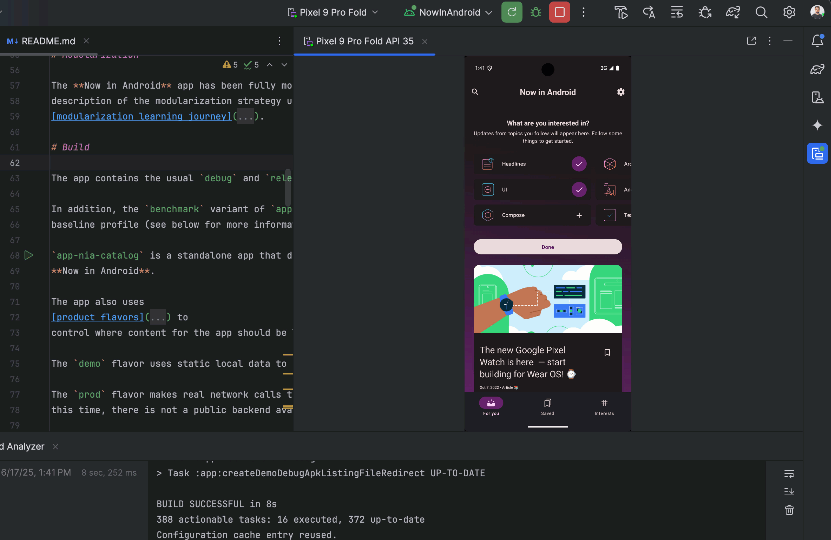
While powerful, you are firmly in control, with the ability to review, refine and guide the agent’s output at every step. When the agent proposes code changes, you can choose to accept or reject them.

Additionally, you can enable “Auto-approve” if you are feeling lucky 😎 — especially useful when you want to iterate on ideas as rapidly as possible.
You can delegate routine, time-consuming work to the agent, freeing up your time for more creative, high-value work. Try out Agent Mode in the latest preview version of Android Studio – we look forward to seeing what you build! We are investing in building more agentic experiences for Gemini in Android Studio to make your development even more intuitive, so you can expect to see more agentic functionality over the next several releases.

Supercharge Agent Mode with your Gemini API key

The default Gemini model has a generous no-cost daily quota with a limited context window. However, you can now add your own Gemini API key to expand Agent Mode's context window to a massive 1 million tokens with Gemini 2.5 Pro.
A larger context window lets you send more instructions, code and attachments to Gemini, leading to even higher quality responses. This is especially useful when working with agents, as the larger context provides Gemini 2.5 Pro with the ability to reason about complex or long-running tasks.

To enable this feature, get a Gemini API key by navigating to Google AI Studio. Sign in and get a key by clicking on the “Get API key” button. Then, back in Android Studio, navigate to the settings by going to File (Android Studio on macOS) > Settings > Tools > Gemini to enter your Gemini API key. Relaunch Gemini in Android Studio and get even better responses from Agent Mode.
Be sure to safeguard your Gemini API key, as additional charges apply for Gemini API usage associated with a personal API key. You can monitor your Gemini API key usage by navigating to AI Studio and selecting Get API key > Usage & Billing.
Note that business tier subscribers already get access to Gemini 2.5 Pro and the expanded context window automatically with their Gemini Code Assist license, so these developers will not see an API key option.
Model Context Protocol (MCP)
Gemini in Android Studio's Agent Mode can now interact with external tools via the Model Context Protocol (MCP). This feature provides a standardized way for Agent Mode to use tools and extend knowledge and capabilities with the external environment.
There are many tools you can connect to the MCP Host in Android Studio. For example you could integrate with the Github MCP Server to create pull requests directly from Android Studio. Here are some additional use cases to consider.
In this initial release of MCP support in the IDE you will configure your MCP servers through a mcp.json file placed in the configuration directory of Studio, using the following format:
{
"mcpServers": {
"memory": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-memory"
]
},
"sequential-thinking": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-sequential-thinking"
]
},
"github": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "<YOUR_TOKEN>"
}
}
}
}
For this initial release, we support interacting with external tools via the stdio transport as defined in the MCP specification. We plan to support the full suite of MCP features in upcoming Android Studio releases, including the Streamable HTTP transport, external context resources, and prompt templates.
For more information on how to use MCP in Studio, including the mcp.json configuration file format, please refer to the Android Studio MCP Host documentation.
By delegating routine tasks to Gemini through Agent Mode, you’ll be able to focus on more innovative and enjoyable aspects of app development. Download the latest preview version of Android Studio on the canary release channel today to try it out, and let us know how much faster app development is for you!
As always, your feedback is important to us – check known issues, report bugs, suggest improvements, and be part of our vibrant community on LinkedIn, Medium, YouTube, or X. Let's build the future of Android apps together!
 Posted by Mozart Louis – Developer Relations Engineer
Posted by Mozart Louis – Developer Relations Engineer

 Posted by
Posted by 







 Posted by Ben Trengrove - Developer Relations Engineer, Matt Dyor - Product Manager
Posted by Ben Trengrove - Developer Relations Engineer, Matt Dyor - Product Manager

 Posted by Ben Sagmoe - Developer Relations Engineer
Posted by Ben Sagmoe - Developer Relations Engineer



 Posted by Rebecca Franks – Developer Relations Engineer
Posted by Rebecca Franks – Developer Relations Engineer












 Posted by Caren Chang - Developer Relations Engineer, Chengji Yan - Software Engineer, Taj Darra - Product Manager
Posted by Caren Chang - Developer Relations Engineer, Chengji Yan - Software Engineer, Taj Darra - Product Manager


 Posted by Rebecca Franks - Developer Relations Engineer
Posted by Rebecca Franks - Developer Relations Engineer







 Posted by Dan Brown, Dina Gandal and Hadar Yanos – Product Managers, Google Play
Posted by Dan Brown, Dina Gandal and Hadar Yanos – Product Managers, Google Play




 Posted by Aurash Mahbod – VP and GM of Games on Google Play
Posted by Aurash Mahbod – VP and GM of Games on Google Play



