Connected TV (CTV) and audio streams flow into people’s screens with hours of entertainment. So successful brands like Adidas and Nestlé turn to programmatic technology as a way to connect with their viewing and listening audiences while simplifying the execution of CTV and audio ad strategies.
Today, we’re spotlighting three additional features that will help you easily capture the attention of CTV and audio streamers and understand what encourages them to become customers.
Pick the right context for your CTV ads
Reaching viewers based on their interests and passions remains one of the most promising opportunities of CTV advertising. That's why we invest in features like similar audiences for CTV devices that help you find new connected TV viewers who share similar attributes with the audiences you already know.
But we’ve heard many of you want to combine these new tactics with best-in-class techniques inspired by traditional TV advertising that give you confidence that your ads are displayed in a safe and relevant context.
To help you do just that, we’re soon integrating new CTV contextual signals in Display & Video 360. This will allow you to pick inventory by genre, length or livestream content.
Let’s say you want to associate your ad message to some of the highly anticipated sports events of the summer, like the Olympics or the U.S. Open. Using Display & Video 360, you’ll easily select CTV live inventory that falls under the “Sports” genre. Then you’ll also be able to verify that your ads served against content that is suitable for your brand.
Measure the sales impact of your CTV ads
As pandemic restrictions ease in some parts of the world, ad spending is rebounding. But advertisers’ preference still goes to ads that can prove they’re effective at moving products off the shelves.
This fall, we’re introducing sales lift measurement for CTV ads using Nielsen Catalina Solutions (NCS) in the U.S. Harnessing sales data across NCS’s extensive retailer network, this feature will give you a chance to quantify how your CTV ad impressions led to offline sales. The report features useful metrics such as percentage sales lift, total incremental sales and return on ad spend that can inform future campaign optimization. This data will be available right in the Display & Video 360 interface, meaning that no pixel implementation or log file data crunching will be required.
And because the Display & Video 360 integration with NCS already covers all other digital environments, publishers and formats, you can now understand the incremental lift attributed to campaigns spanning across CTV apps, display, audio and more.
Create professional dynamic audio ads
On top of the big screen, people will also turn on their smart speakers and headphones this summer to enjoy live sports and music festivals, or to listen to a podcast while relaxing in a deck chair. Creating great audio ads can be a chicken-and-egg problem. How can you justify a big incremental creative investment if you haven’t yet proven you can run fantastic digital audio campaigns?
That’s where Display & Video 360 can help. With Audio Mixer, you could already assemble a multi-track audio ad using simple drag-and-drop editing features. Building on Audio Mixer, we’re adding new dynamic production capabilities so that you can build tailored audio ads, quickly and efficiently, at scale. This new dynamic production tool allows you to use various segmentation rules, like location, schedule or audience, to create customized, relevant ads, all from a single audio creative.
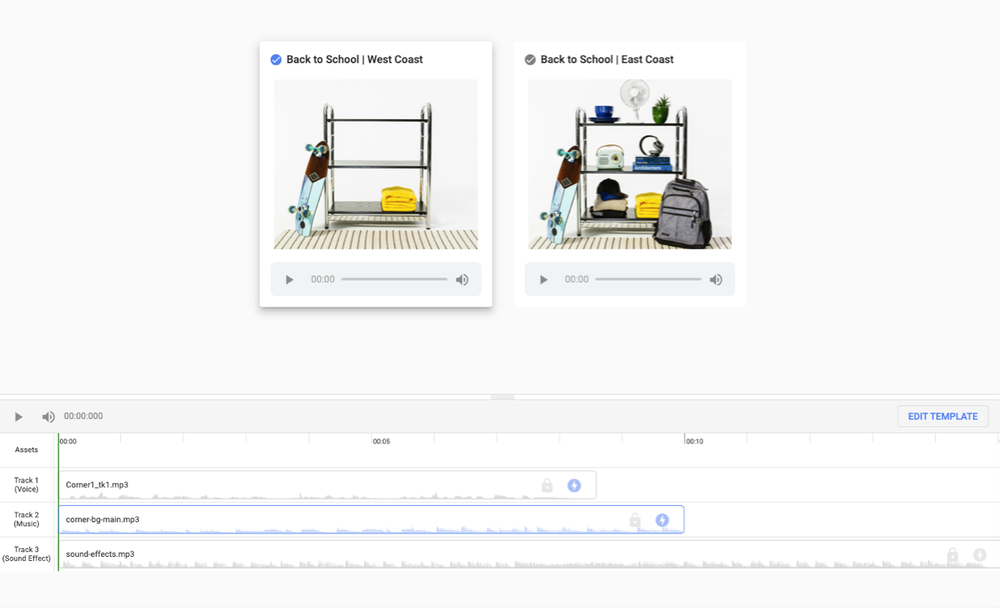
For example, you can create a back-to-school audio campaign that has customized offers for different markets. Once you record the audio asset, you can use the dynamic audio tool to create additional custom assets with local in-store promotions based on where the ads will run.
Dynamic Audio ads in Display & Video 360
Both Audio Mixer and the dynamic production tool will also be available in the recently announced Ads Creative Studio.
As people shift to on-demand ways of consuming TV and audio content, advertisers need on-demand ways of buying ads on these channels. Stay flexible and relevant by simplifying the execution and measurement of your CTV and audio campaigns with Display & Video 360’s new tools.
Connected TV (CTV) and audio streams flow into people’s screens with hours of entertainment. So successful brands like Adidas and Nestlé turn to programmatic technology as a way to connect with their viewing and listening audiences while simplifying the execution of CTV and audio ad strategies.
Today, we’re spotlighting three additional features that will help you easily capture the attention of CTV and audio streamers and understand what encourages them to become customers.
Pick the right context for your CTV ads
Reaching viewers based on their interests and passions remains one of the most promising opportunities of CTV advertising. That's why we invest in features like similar audiences for CTV devices that help you find new connected TV viewers who share similar attributes with the audiences you already know.
But we’ve heard many of you want to combine these new tactics with best-in-class techniques inspired by traditional TV advertising that give you confidence that your ads are displayed in a safe and relevant context.
To help you do just that, we’re soon integrating new CTV contextual signals in Display & Video 360. This will allow you to pick inventory by genre, length or livestream content.
Let’s say you want to associate your ad message to some of the highly anticipated sports events of the summer, like the Olympics or the U.S. Open. Using Display & Video 360, you’ll easily select CTV live inventory that falls under the “Sports” genre. Then you’ll also be able to verify that your ads served against content that is suitable for your brand.
Measure the sales impact of your CTV ads
As pandemic restrictions ease in some parts of the world, ad spending is rebounding. But advertisers’ preference still goes to ads that can prove they’re effective at moving products off the shelves.
This fall, we’re introducing sales lift measurement for CTV ads using Nielsen Catalina Solutions (NCS) in the U.S. Harnessing sales data across NCS’s extensive retailer network, this feature will give you a chance to quantify how your CTV ad impressions led to offline sales. The report features useful metrics such as percentage sales lift, total incremental sales and return on ad spend that can inform future campaign optimization. This data will be available right in the Display & Video 360 interface, meaning that no pixel implementation or log file data crunching will be required.
And because the Display & Video 360 integration with NCS already covers all other digital environments, publishers and formats, you can now understand the incremental lift attributed to campaigns spanning across CTV apps, display, audio and more.
Create professional dynamic audio ads
On top of the big screen, people will also turn on their smart speakers and headphones this summer to enjoy live sports and music festivals, or to listen to a podcast while relaxing in a deck chair. Creating great audio ads can be a chicken-and-egg problem. How can you justify a big incremental creative investment if you haven’t yet proven you can run fantastic digital audio campaigns?
That’s where Display & Video 360 can help. With Audio Mixer, you could already assemble a multi-track audio ad using simple drag-and-drop editing features. Building on Audio Mixer, we’re adding new dynamic production capabilities so that you can build tailored audio ads, quickly and efficiently, at scale. This new dynamic production tool allows you to use various segmentation rules, like location, schedule or audience, to create customized, relevant ads, all from a single audio creative.
For example, you can create a back-to-school audio campaign that has customized offers for different markets. Once you record the audio asset, you can use the dynamic audio tool to create additional custom assets with local in-store promotions based on where the ads will run.
Dynamic Audio ads in Display & Video 360
Both Audio Mixer and the dynamic production tool will also be available in the recently announced Ads Creative Studio.
As people shift to on-demand ways of consuming TV and audio content, advertisers need on-demand ways of buying ads on these channels. Stay flexible and relevant by simplifying the execution and measurement of your CTV and audio campaigns with Display & Video 360’s new tools.
If you monetize your websites and blogs with affiliate links or sponsored and guest posts,
it's very important to qualify these links. Learn more about commercial links and link spam
If you monetize your websites and blogs with affiliate links or sponsored and guest posts,
it's very important to qualify these links. Learn more about commercial links and link spam
Hi, everyone! We've just released Chrome 92 (92.0.4515.115) for Android: it'll become available on Google Play over the next few weeks.
This release includes stability and performance improvements. You can see a full list of the changes in the Git log. If you find a new issue, please let us know by filing a bug.
The Beta channel has been updated to 92.0.4515.111 (Platform version:13982.60.0) for most Chrome OS devices. This build contains a number of bug fixes, security updates and feature enhancements.
If you find issues, please let us know by visiting our forum or filing a bug. Interested in switching channels? Find out how. You can submit feedback using 'Report an issue...' in the Chrome menu (3 vertical dots in the upper right corner of the browser).
Unless otherwise indicated, the features below are fully launched or in the process of rolling out (rollouts should take no more than 15 business days to complete), launching to both Rapid and Scheduled Release at the same time (if not, each stage of rollout should take no more than 15 business days to complete), and available to all Google Workspace and G Suite customers.
Gmail now displays the latest emojis Now you can see all the latest emojis in Gmail, with emojis now rendered in the latest Unicode standard 13.1.
Improved Tabular Data Handling for Gmail DLP We are improving the way we handle Tabular data files like .csv or .xlsx to best account for the structure of these files. This will result in more accurate content scans. | Available to Google Workspace Enterprise, Education Fundamentals, Standard, Teaching and Learning Upgrade, and Plus customers. | Learn more.
Previous announcements
The announcements below were published on the Workspace Updates blog earlier this week. Please refer to the original blog posts for complete details.
Updates to Google Workspace Public Status Dashboard and service status alerts We're introducing a new Public Status Dashboard experience for Google Workspace. As part of this update, we’re enhancing the functionality of the existing Apps outage alert system-defined rule, which provides email notifications regarding service disruptions or outages via the Public Status Dashboard. | Learn more.
Hangouts to Google Chat upgrade beginning August 16th, with option to opt-out Beginning August 16, 2021, we will start upgrading users who have the “Chat and classic Hangouts” setting selected to “Chat preferred,” unless you explicitly opt out. Additionally, the “Chat and classic Hangouts'' setting will also be removed for all users in your domain unless you opt out of the upgrade. | Learn more.
Fundamental data regions now available to more Google Workspace customers Data regions give you the ability to choose where covered data for select Google Workspace apps is stored at rest. We’re introducing a more limited version of data regions, known as Fundamental data regions, which will be available to Google Workspace Enterprise Standard, Business Plus, Business Standard and Frontline customers. | Learn more.
Bulk convert Classic Sites to new Sites using the Classic Sites Manager Beginning today, you can now bulk convert Classic Sites to new Sites using the Classic Sites Manager. | Learn more.
Block shares from another user in Google Drive
We’re adding the ability to block another user in Google Drive. If blocked, the user will not be able to share any Drive items with you, and items owned by the user will not be able to be shared with you or be shown when you’re browsing Google Drive. In addition, your files will not be available to the user you’ve blocked, even if you’ve previously shared items with them. | Learn more.
Select multiple tabs in Google Sheets and perform basic actions on the selection
Now you can select multiple tabs in Google Sheets and perform basic actions on the selection (such as moving the tabs together, deleting, duplicating, copying, coloring, or hiding). | Learn more.
Image placeholders make it easy to work as a team with images in Slides themes and layouts
Now when you create a theme in Slides, you can add image placeholders to your layouts. | Learn more.
Easily collaborate and share Slide presentations with side-by-side viewing in Google Chat
In Google Chat, you can now open and edit a Slide presentation in a side-by-side view. | Learn more.
In Google Chat, you can now open and edit a Slide presentation in a side-by-side view. By enabling you and your collaborators to directly edit presentations without leaving Chat, we hope to make it easier to transform your ideas into impact.
Chat users can open a Slide presentation by clicking on the preview thumbnail image in the chat stream.
Getting started
Admins: There is no admin control for this feature.
End users: Use this feature by clicking on the document preview thumbnail image in the chat stream. To open the presentation directly in Google Slides, click on the blue link in the chat conversation. Visit the Help Center to learn more about how to Manage your files in Gmail rooms.
Posted by Samuel J. Yang, Research Scientist and Dick Lyon, Principal Scientist, Google Research
For the ~466 million people in the world who are deaf or hard of hearing, the lack of easy access to accessibility services can be a barrier to participating in spoken conversations encountered daily. While hearing aids can help alleviate this, simply amplifying sound is insufficient for many. One additional option that may be available is the cochlear implant (CI), which is an electronic device that is surgically inserted into a part of the inner ear, called the cochlea, and stimulates the auditory nerve electrically via external sound processors. While many individuals with these cochlear implants can learn to interpret these electrical stimulations as audible speech, the listening experience can be quite varied and particularly challenging in noisy environments.
Modern cochlear implants drive electrodes with pulsatile signals (i.e., discrete stimulation pulses) that are computed by external sound processors. The main challenge still facing the CI field is how to best process sounds — to convert sounds to pulses on electrodes — in a way that makes them more intelligible to users. Recently, to stimulate progress on this problem, scientists in industry and academia organized a CI Hackathon to open the problem up to a wider range of ideas.
In this post, we share exploratory research demonstrating that a speech enhancement preprocessor — specifically, a noise suppressor — can be used at the input of a CI’s processor to enhance users’ understanding of speech in noisy environments. We also discuss how we built on this work in our entry for the CI Hackathon and how we will continue developing this work.
Improving CIs with Noise Suppression In 2019, a small internal project demonstrated the benefits of noise suppression at the input of a CI’s processor. In this project, participants listened to 60 pre-recorded and pre-processed audio samples and ranked them by their listening comfort. CI users listened to the audio using their devices' existing strategy for generating electrical pulses.
As shown below, both listening comfort and intelligibility usually increased, sometimes dramatically, when speech with noise (the lightest bar) was processed with noise suppression.
CI users in an early research study have improved listening comfort — qualitatively scored from "very poor" (0.0) to "OK" (0.5) to "very good" (1.0) — and speech intelligibility (i.e., the fraction of words in a sentence correctly transcribed) when trying to listen to noisy audio samples of speech with noise suppression applied.
For the CI Hackathon, we built on the project above, continuing to leverage our use of a noise suppressor while additionally exploring an approach to compute the pulses too
Overview of the Processing Approach The hackathon considered a CI with 16 electrodes. Our approach decomposes the audio into 16 overlapping frequency bands, corresponding to the positions of the electrodes in the cochlea. Next, because the dynamic range of sound easily spans multiple orders of magnitude more than what we expect the electrodes to represent, we aggressively compress the dynamic range of the signal by applying "per-channel energy normalization" (PCEN). Finally, the range-compressed signals are used to create the electrodogram (i.e., what the CI displays on the electrodes).
In addition, the hackathon required a submission be evaluated in multiple audio categories, including music, which is an important but notoriously difficult category of sounds for CI users to enjoy. However, the speech enhancement network was trained to suppress non-speech sounds, including both noise and music, so we needed to take extra measures to avoid suppressing instrumental music (note that in general, music suppression might be preferred by some users in certain contexts). To do this, we created a “mix” of the original audio with the noise-suppressed audio so that enough of the music would pass through to remain audible. We varied in real-time the fraction of original audio mixed from 0% to 40% (0% if all of the input is estimated as speech, up to 40% as more of the input is estimated as non-speech) based on the estimate from the open-source YAMNet classifier on every ~1 second window of audio of whether the input is speech or non-speech.
The Conv-TasNet Speech Enhancement Model To implement a speech enhancement module that suppresses non-speech sounds, such as noise and music, we use the Conv-TasNet model, which can separate different kinds of sounds. To start, the raw audio waveforms are transformed and processed into a form that can be used by a neural network. The model transforms short, 2.5 millisecond frames of input audio with a learnable analysis transform to generate features optimized for sound separation. The network then produces two “masks” from those features: one mask for speech and one mask for noise. These masks indicate the degree to which each feature corresponds to either speech or noise. Separated speech and noise are reconstructed back to the audio domain by multiplying the masks with the analysis features, applying a synthesis transform back to audio-domain frames, and stitching the resulting short frames together. As a final step, the speech and noise estimates are processed by a mixture consistency layer, which improves the quality of the estimated waveforms by ensuring that they sum up to the original input mixture waveform.
Block diagram of the speech enhancement system, which is based on Conv-TasNet.
The model is both causal and low latency: for each 2.5 milliseconds of input audio, the model produces estimates of separated speech and noise, and thus could be used in real-time. For the hackathon, to demonstrate what could be possible with increased compute power in future hardware, we chose to use a model variant with 2.9 million parameters. This model size is too large to be practically implemented in a CI today, but demonstrates what kind of performance would be possible with more capable hardware in the future.
Listening to the Results As we optimized our models and overall solution, we used the hackathon-provided vocoder (which required a fixed temporal spacing of electrical pulses) to produce audio simulating what CI users might perceive. We then conducted blind A-B listening tests as typical hearing users.
Listening to the vocoder simulations below, the speech in the reconstructed sounds — from the vocoder processing the electrodograms — is reasonably intelligible when the input sound doesn't contain too much background noise, however there is still room to improve the clarity of the speech. Our submission performed well in the speech-in-noise category and achieved second place overall.
Simulated audio with fixed temporal spacing
Vocoder simulation of what CI users might perceive from audio from an electrodogram with fixed temporal spacing, with background noise and noise suppression applied.
A bottleneck on quality is that the fixed temporal spacing of stimulation pulses sacrifices fine-time structure in the audio. A change to the processing to produce pulses timed to peaks in the filtered sound waveforms captures more information about the pitch and structure of sound than is conventionally represented in implant stimulation patterns.
Simulated audio with adaptive spacing and fine time structure
Vocoder simulation, using the same vocoder as above, but on an electrodogram from the modified processing that synchronizes stimulation pulses to peaks of the sound waveform.
It's important to note that this second vocoder output is overly optimistic about how well it might sound to a real CI user. For instance, the simple vocoder used here does not model how current spread in the cochlea blurs the stimulus, making it harder to resolve different frequencies. But this at least suggests that preserving fine-time structure is valuable and that the electrodogram itself is not the bottleneck.
Ideally, all processing approaches would be evaluated by a broad range of CI users, with the electrodograms implemented directly on their CIs rather than relying upon vocoder simulations.
Conclusion and a Call to Collaborate We are planning to follow up on this experience in two main directions. First, we plan to explore the application of noise suppression to other hearing-accessibility modalities, including hearing aids, transcription, and vibrotactile sensory substitution. Second, we'll take a deeper dive into the creation of electrodogram patterns for cochlear implants, exploiting fine temporal structure that is not accommodated in the usual CIS (continous interleaved sampling) patterns that are standard in the industry. According to Louizou: “It remains a puzzle how some single-channel patients can perform so well given the limited spectral information they receive''. Therefore, using fine temporal structure might be a critical step towards achieving an improved CI experience.
Google is committed to building technology with and for people with disabilities. If you are interested in collaborating to improve the state of the art in cochlear implants (or hearing aids), please reach out to [email protected].
Acknowledgements We would like to thank the Cochlear Impact hackathon organizers for giving us this opportunity and partnering with us. The participating team within Google is Samuel J. Yang, Scott Wisdom, Pascal Getreuer, Chet Gnegy, Mihajlo Velimirović, Sagar Savla, and Richard F. Lyon with guidance from Dan Ellis and Manoj Plakal.
Posted by Samuel J. Yang, Research Scientist and Dick Lyon, Principal Scientist, Google Research
For the ~466 million people in the world who are deaf or hard of hearing, the lack of easy access to accessibility services can be a barrier to participating in spoken conversations encountered daily. While hearing aids can help alleviate this, simply amplifying sound is insufficient for many. One additional option that may be available is the cochlear implant (CI), which is an electronic device that is surgically inserted into a part of the inner ear, called the cochlea, and stimulates the auditory nerve electrically via external sound processors. While many individuals with these cochlear implants can learn to interpret these electrical stimulations as audible speech, the listening experience can be quite varied and particularly challenging in noisy environments.
Modern cochlear implants drive electrodes with pulsatile signals (i.e., discrete stimulation pulses) that are computed by external sound processors. The main challenge still facing the CI field is how to best process sounds — to convert sounds to pulses on electrodes — in a way that makes them more intelligible to users. Recently, to stimulate progress on this problem, scientists in industry and academia organized a CI Hackathon to open the problem up to a wider range of ideas.
In this post, we share exploratory research demonstrating that a speech enhancement preprocessor — specifically, a noise suppressor — can be used at the input of a CI’s processor to enhance users’ understanding of speech in noisy environments. We also discuss how we built on this work in our entry for the CI Hackathon and how we will continue developing this work.
Improving CIs with Noise Suppression In 2019, a small internal project demonstrated the benefits of noise suppression at the input of a CI’s processor. In this project, participants listened to 60 pre-recorded and pre-processed audio samples and ranked them by their listening comfort. CI users listened to the audio using their devices' existing strategy for generating electrical pulses.
As shown below, both listening comfort and intelligibility usually increased, sometimes dramatically, when speech with noise (the lightest bar) was processed with noise suppression.
CI users in an early research study have improved listening comfort — qualitatively scored from "very poor" (0.0) to "OK" (0.5) to "very good" (1.0) — and speech intelligibility (i.e., the fraction of words in a sentence correctly transcribed) when trying to listen to noisy audio samples of speech with noise suppression applied.
For the CI Hackathon, we built on the project above, continuing to leverage our use of a noise suppressor while additionally exploring an approach to compute the pulses too
Overview of the Processing Approach The hackathon considered a CI with 16 electrodes. Our approach decomposes the audio into 16 overlapping frequency bands, corresponding to the positions of the electrodes in the cochlea. Next, because the dynamic range of sound easily spans multiple orders of magnitude more than what we expect the electrodes to represent, we aggressively compress the dynamic range of the signal by applying "per-channel energy normalization" (PCEN). Finally, the range-compressed signals are used to create the electrodogram (i.e., what the CI displays on the electrodes).
In addition, the hackathon required a submission be evaluated in multiple audio categories, including music, which is an important but notoriously difficult category of sounds for CI users to enjoy. However, the speech enhancement network was trained to suppress non-speech sounds, including both noise and music, so we needed to take extra measures to avoid suppressing instrumental music (note that in general, music suppression might be preferred by some users in certain contexts). To do this, we created a “mix” of the original audio with the noise-suppressed audio so that enough of the music would pass through to remain audible. We varied in real-time the fraction of original audio mixed from 0% to 40% (0% if all of the input is estimated as speech, up to 40% as more of the input is estimated as non-speech) based on the estimate from the open-source YAMNet classifier on every ~1 second window of audio of whether the input is speech or non-speech.
The Conv-TasNet Speech Enhancement Model To implement a speech enhancement module that suppresses non-speech sounds, such as noise and music, we use the Conv-TasNet model, which can separate different kinds of sounds. To start, the raw audio waveforms are transformed and processed into a form that can be used by a neural network. The model transforms short, 2.5 millisecond frames of input audio with a learnable analysis transform to generate features optimized for sound separation. The network then produces two “masks” from those features: one mask for speech and one mask for noise. These masks indicate the degree to which each feature corresponds to either speech or noise. Separated speech and noise are reconstructed back to the audio domain by multiplying the masks with the analysis features, applying a synthesis transform back to audio-domain frames, and stitching the resulting short frames together. As a final step, the speech and noise estimates are processed by a mixture consistency layer, which improves the quality of the estimated waveforms by ensuring that they sum up to the original input mixture waveform.
Block diagram of the speech enhancement system, which is based on Conv-TasNet.
The model is both causal and low latency: for each 2.5 milliseconds of input audio, the model produces estimates of separated speech and noise, and thus could be used in real-time. For the hackathon, to demonstrate what could be possible with increased compute power in future hardware, we chose to use a model variant with 2.9 million parameters. This model size is too large to be practically implemented in a CI today, but demonstrates what kind of performance would be possible with more capable hardware in the future.
Listening to the Results As we optimized our models and overall solution, we used the hackathon-provided vocoder (which required a fixed temporal spacing of electrical pulses) to produce audio simulating what CI users might perceive. We then conducted blind A-B listening tests as typical hearing users.
Listening to the vocoder simulations below, the speech in the reconstructed sounds — from the vocoder processing the electrodograms — is reasonably intelligible when the input sound doesn't contain too much background noise, however there is still room to improve the clarity of the speech. Our submission performed well in the speech-in-noise category and achieved second place overall.
Simulated audio with fixed temporal spacing
Vocoder simulation of what CI users might perceive from audio from an electrodogram with fixed temporal spacing, with background noise and noise suppression applied.
A bottleneck on quality is that the fixed temporal spacing of stimulation pulses sacrifices fine-time structure in the audio. A change to the processing to produce pulses timed to peaks in the filtered sound waveforms captures more information about the pitch and structure of sound than is conventionally represented in implant stimulation patterns.
Simulated audio with adaptive spacing and fine time structure
Vocoder simulation, using the same vocoder as above, but on an electrodogram from the modified processing that synchronizes stimulation pulses to peaks of the sound waveform.
It's important to note that this second vocoder output is overly optimistic about how well it might sound to a real CI user. For instance, the simple vocoder used here does not model how current spread in the cochlea blurs the stimulus, making it harder to resolve different frequencies. But this at least suggests that preserving fine-time structure is valuable and that the electrodogram itself is not the bottleneck.
Ideally, all processing approaches would be evaluated by a broad range of CI users, with the electrodograms implemented directly on their CIs rather than relying upon vocoder simulations.
Conclusion and a Call to Collaborate We are planning to follow up on this experience in two main directions. First, we plan to explore the application of noise suppression to other hearing-accessibility modalities, including hearing aids, transcription, and vibrotactile sensory substitution. Second, we'll take a deeper dive into the creation of electrodogram patterns for cochlear implants, exploiting fine temporal structure that is not accommodated in the usual CIS (continous interleaved sampling) patterns that are standard in the industry. According to Louizou: “It remains a puzzle how some single-channel patients can perform so well given the limited spectral information they receive''. Therefore, using fine temporal structure might be a critical step towards achieving an improved CI experience.
Google is committed to building technology with and for people with disabilities. If you are interested in collaborating to improve the state of the art in cochlear implants (or hearing aids), please reach out to [email protected].
Acknowledgements We would like to thank the Cochlear Impact hackathon organizers for giving us this opportunity and partnering with us. The participating team within Google is Samuel J. Yang, Scott Wisdom, Pascal Getreuer, Chet Gnegy, Mihajlo Velimirović, Sagar Savla, and Richard F. Lyon with guidance from Dan Ellis and Manoj Plakal.