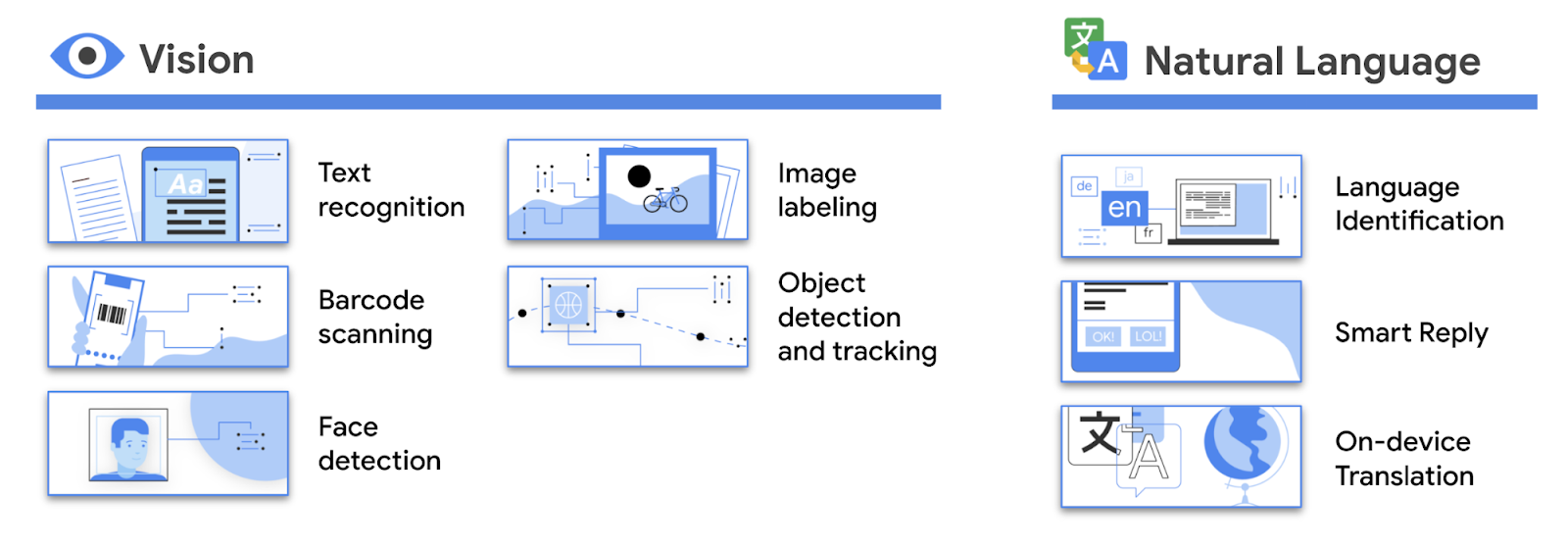
Posted by Hoi Lam, Android Machine Learning
Yesterday, we talked about turnkey machine learning (ML) solutions with ML Kit. But what if that doesn’t completely address your needs and you need to tweak it a little? Today, we will discuss how to find alternative models, and how to train and use custom ML models in your Android app.
Find alternative ML models

Crop disease models from the wider research community available on tfhub.dev
If the turnkey ML solutions don't suit your needs, TensorFlow Hub should be your first port of call. It is a repository of ML models from Google and the wider research community. The models on the site are ready for use in the cloud, in a web-browser or in an app on-device. For Android developers, the most exciting models are the TensorFlow Lite (TFLite) models that are optimized for mobile.
In addition to key vision models such as MobileNet and EfficientNet, the repository also boast models powered by the latest research such as:
- Wine classification for 400,000 popular wines
- US supermarket product classification for 100,000 products
- Landmark recognition on a per-continent basis
- CropNet model by Brain Accra for recognising Cassava leaf disease
- Plant disease recognition from AgriPredict that detects disease in maize and tomato plants
Many of these solutions were previously only available in the cloud, as the models are too large and too power intensive to run on-device. Today, you can run them on Android on-device, offline and live.
Train your own custom model
Besides the large repository of base models, developers can also train their own models. Developer-friendly tools are available for many common use cases. In addition to Firebase’s AutoML Vision Edge, the TensorFlow team launched TensorFlow Lite Model Maker earlier this year to give developers more choices over the base model that support more use cases. TensorFlow Lite Model Maker currently supports two common ML tasks:
The TensorFlow Lite Model Maker can run on your own developer machine or in Google Colab online machine learning notebooks. Going forward, the team plans to improve the existing offerings and to add new use cases.
Using custom model in your Android app
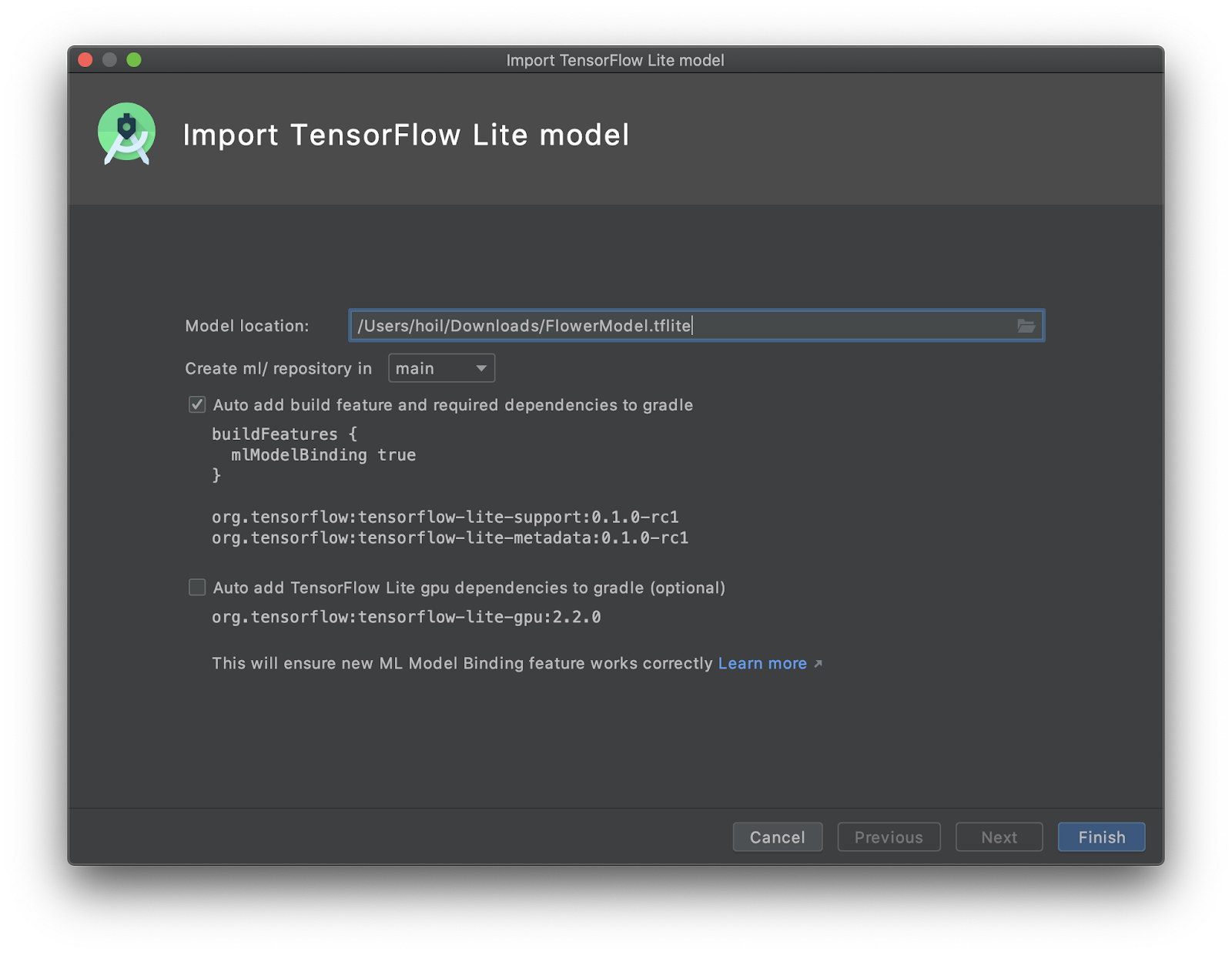
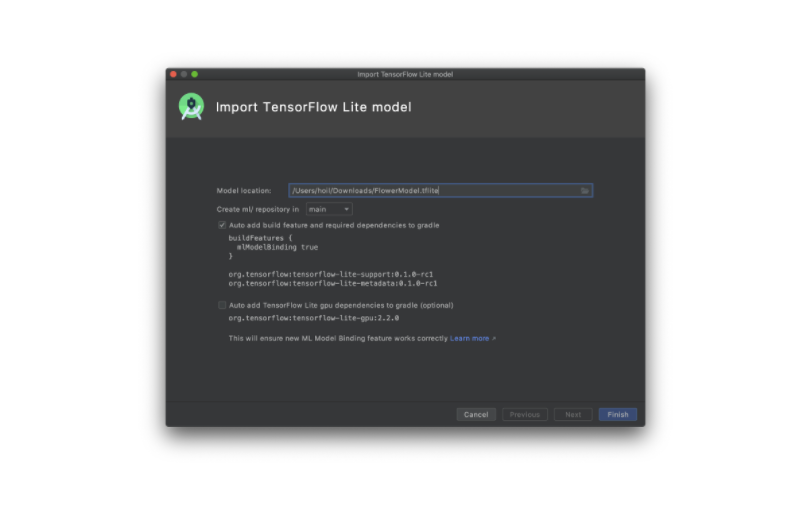
New TFLite Model import screen in Android Studio 4.1 beta
Once you have selected a model or trained your model there are new easy-to-use tools to help you integrate them into your Android app without having to convert everything into ByteArrays. The first new tool is ML Model binding with Android Studio 4.1. This lets developers import any TFLite model, read the input / output signature of the model, and use it with just a few lines of code that calls the open source TensorFlow Lite Android Support Library.
Another way to implement a TensorFlow Lite model is via ML Kit. Starting in June, ML Kit no longer requires a Firebase project for on-device functionality. In addition, the image classification and object detection and tracking (ODT) APIs support custom models. The latter ODT offering is especially useful in use-cases where you need to separate out objects from a busy scene.
So how should you choose between these three solutions? If you are trying to detect a product on a busy supermarket shelf, ML Kit object detection and tracking can help your user select a specific product for processing. The API then performs image classification on just the part of the image that contains the product, which results in better detection performance. On the other hand, if the scene or the object you are trying to detect takes up most of the input image, for example, a landmark such as Big Ben, using ML Model binding or the ML Kit image classification API might be more appropriate.

TensorFlow Hub bird detection model with ML Kit Object Detection & Tracking AP
Two examples of how these tools can fit together

- Codelab of the day: Recognize Flowers with TensorFlow Lite on Android (beta). This codelab utilizes the TensorFlow Lite Model Maker to produce the TFLite model and Android Studio 4.1’s ML Model binding to integrate the custom model into an Android app. Together with the TensorFlow team, we have also recorded a special screencast to run you through all the steps in this codelab. If you have any questions regarding this code lab, please raise them at StackOverflow and tag it with [Android-Studio] AND [Tensorflow-lite]. Our team will monitor these tags.
- TensorFlow Hub and ML Kit Screencast: In this video, we first go through how Android developers can get the most out of TensorFlow Hub: how to find and download a model. Then we explain the steps to integrate it with ML Kit’s Object Detection and Tracking API.
Customizing your model is easier than ever
Finding, building and using custom models on Android has never been easier. As both Android and TensorFlow teams increase the coverage of machine learning use cases, please let us know how we can improve these tools for your use cases by filing an enhancement request with TensorFlow Lite or ML Kit.
Tomorrow, we will take a step back and focus on how to appropriately use and design for a machine learning first Android app. The content will be appropriate for the entire development team, so bring your product manager and designers along. See you next time.