Posted by Christiaan Prins and Max Gubin
Today we are announcing the release of two new features to ML Kit: Language Identification and Smart Reply.
You might notice that both of these features are different from our existing APIs that were all focused on image/video processing. Our goal with ML Kit is to offer powerful but simple-to-use APIs to leverage the power of ML, independent of the domain. As such, we are excited to expand ML Kit with solutions for Natural Language Processing (NLP)!
NLP is a category of ML that deals with analyzing and generating text, speech, and other kinds of natural language data. We're excited to start out with two APIs: one that helps you identify the language of text, and one that generates reply suggestions in chat applications. Both of these features work fully on-device and are available on the latest version of the ML Kit SDK, on iOS (9.0 and higher) and Android (4.1 and higher).
Generate reply suggestions based on previous messages
A new feature popping up in messaging apps is to provide the user with a selection of suggested responses, either as actions on a notification or inside the app itself. This can really help a user to quickly respond when they are busy or a handy way to initiate a longer message.
With the new Smart Reply API you can now quickly achieve the same in your own apps. The API provides suggestions based on the last 10 messages in a conversation, although it still works if only one previous message is available. It is a stateless API that fully runs on-device, so we don't keep message history in memory nor send it to a server.
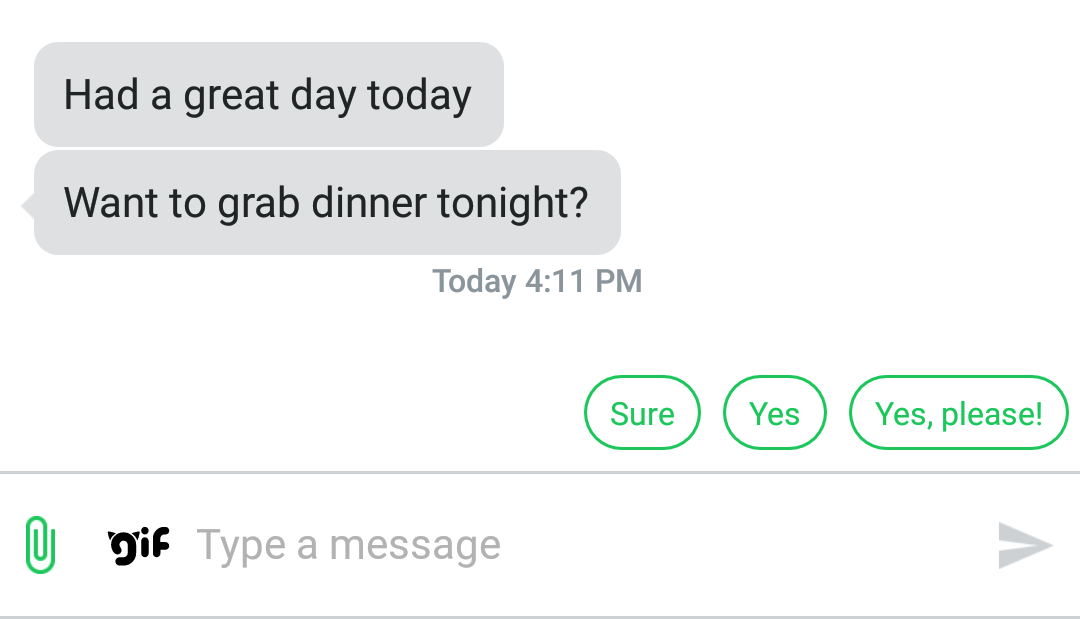
textPlus app providing response suggestions using Smart Reply
We have worked closely with partners like textPlus to ensure Smart Reply is ready for prime time and they have now implemented in-app response suggestions with the latest version of their app (screenshot above).
Adding Smart Reply to your own app is done with a simple function call (using Swift in this example):
let smartReply = NaturalLanguage.naturalLanguage().smartReply()
smartReply.suggestReplies(for: conversation) { result, error in
guard error == nil, let result = result else {
return
}
if (result.status == .success) {
for suggestion in result.suggestions {
print("Suggested reply: \(suggestion.text)")
}
}
}
After you initialize a Smart Reply instance, call suggestReplies with a list of recent messages. The callback provides the result which contains a list of suggestions.
For details on how to use the Smart Reply API, check out the documentation.
Tell me more ...
Although as a developer, you can just pick up this new API and easily get it integrated in your app, it may be interesting to reveal a bit on how it works under the hood. At the core of Smart Reply is a machine-learned model that is executed using TensorFlow Lite and has a state-of-the-art modern architecture based on SentencePiece text encoding[1] and Transformer[2].
However, as we realized when we started development of the API, the core suggestion model is not all that's needed to provide a solution that developers can use in their apps. For example, we added a model to detect sensitive topics, so that we avoid making suggestions in response to profanity or in cases of personal tragedy/hardship. Also, we included language identification, to ensure we do not provide suggestions for languages the core model is not trained on. The Smart Reply feature is launching with English support first.
Identify the language of a piece of text
The language of a given text string is a subtle but helpful piece of information. A lot of apps have functionality with a dependency on the language: you can think of features like spell checking, text translation or Smart Reply. Rather than asking a user to specify the language they use, you can use our new Language Identification API.
ML Kit recognizes text in 103 different languages and typically only requires a few words to make an accurate determination. It is fast as well, typically providing a response within 1 to 2 ms across iOS and Android phones.
Similar to the Smart Reply API, you can identify the language with a function call (using Swift in this example):
let languageId = NaturalLanguage.naturalLanguage().languageIdentification()
languageId.identifyLanguage(for: "¿Cómo estás?") { languageCode, error in
guard error == nil, let languageCode = languageCode else {
print("Failed to identify language with error: \(error!)")
return
}
print("Identified Language: \(languageCode)")
}
The identifyLanguage functions takes a piece of a text and its callback provides a BCP-47 language code. If no language can be confidently recognized, ML Kit returns a code of und for undetermined. The Language Identification API can also provide a list of possible languages and their confidence values.
For details on how to use the Language Identification API, check out the documentation.
Get started today
We're really excited to expand ML Kit to include Natural Language APIs. Give the two new NLP APIs a spin today and let us know what you think! You can always reach us in our Firebase Talk Google Group.
As ML Kit grows we look forward to adding more APIs and categories that enables you to provide smarter experiences for your users. With that, please keep an eye out for some exciting ML Kit announcements at Google I/O.