 We’re announcing Gemini for Education, plus more AI tools for students and educators.
We’re announcing Gemini for Education, plus more AI tools for students and educators.
New Gemini tools for students and educators
We’re announcing Gemini for Education, plus more AI tools for students and educators.
We’re announcing Gemini for Education, plus more AI tools for students and educators.
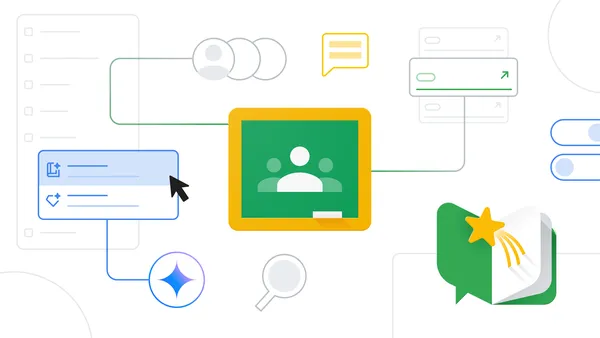 Along with Gemini in Classroom's new AI tools for education, we're announcing more than 50 new features in Google Classroom
Along with Gemini in Classroom's new AI tools for education, we're announcing more than 50 new features in Google Classroom
 The latest announcements from Google for Education at ISTE 2025.
The latest announcements from Google for Education at ISTE 2025.
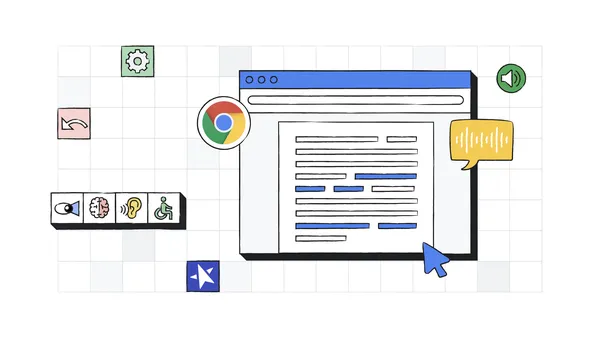 For Global Accessibility Awareness Day, we’re sharing Chromebook accessibility features and use cases.
For Global Accessibility Awareness Day, we’re sharing Chromebook accessibility features and use cases.
 2025 U.S. National Teacher of the Year Ashlie Crosson from Pennsylvania shares an open letter to her fellow educators.
2025 U.S. National Teacher of the Year Ashlie Crosson from Pennsylvania shares an open letter to her fellow educators.
 It’s U.S. Teacher Appreciation Week! Celebrate this week by joining a Google teacher community near you and check out related Search trends and how we’re supporting educ…
La Maestra Nacional del Año 2025 Ashlie Crosson, de Pensilvania, Estados Unidos, comparte una carta abierta para sus colegas de la educación.
It’s U.S. Teacher Appreciation Week! Celebrate this week by joining a Google teacher community near you and check out related Search trends and how we’re supporting educ…
La Maestra Nacional del Año 2025 Ashlie Crosson, de Pensilvania, Estados Unidos, comparte una carta abierta para sus colegas de la educación.
 Learning a language isn’t just about textbooks or exercises. It’s about curiosity, and seizing every tiny opportunity to learn—whether it’s ordering a coffee, catching a…
Learning a language isn’t just about textbooks or exercises. It’s about curiosity, and seizing every tiny opportunity to learn—whether it’s ordering a coffee, catching a…
 The Albuquerque Public Schools (APS) district, which serves 70,000 students and employs more than 5,000 educators, faced the challenge of providing engaging, personalize…
The Albuquerque Public Schools (APS) district, which serves 70,000 students and employs more than 5,000 educators, faced the challenge of providing engaging, personalize…
 This year’s wildfires in greater Los Angeles devastated communities, including students and teachers whose schools were shut down, who were displaced and who lost their …
This year’s wildfires in greater Los Angeles devastated communities, including students and teachers whose schools were shut down, who were displaced and who lost their …