Posted by Aditya Kumar – Software Engineer
Posted by Aditya Kumar – Software Engineer

Context
Binary layout using a symbol order file (also known as binary order file or linker order file) is a well-known link-time optimization. The linker uses the order of symbols in order file to lay out symbols in the binary. Order file based binary layout improves application launch time as well as other critical user journeys. Order file generation is typically a multi-step process where developers use different tools at every stage. We are providing a unified set of tools and documentation that will allow every native app developer to leverage this optimization. Both Android app developers and the AOSP community can benefit from the tools.
Background
Source code is typically structured to facilitate software development and comprehension. The layout of functions and variables in a binary is also impacted by their relative ordering in the source code. The binary layout impacts application performance as the operating system has no way of knowing which symbols will be required in future and typically uses spatial locality as one of the cost models for prefetching subsequent pages.
But the order of symbols in a binary may not reflect the program execution order. When an application executes, fetching symbols that are not present in memory would result in page faults. For example, consider the following program:
// Test.cpp
int foo() { /* */ }
int bar() { /* */ }
// Other functions...
int main() {
bar();
foo();
}
Which gets compiled into:
# Test.app
page_x: _foo
page_y: _bar
# Other symbols
page_z:_main
When Test.app starts, its entrypoint _main is fetched first then _bar followed by _foo. Executing Test.app can lead to page faults for fetching each function. Compare this to the following binary layout where all the functions are located in the same page (assuming the functions are small enough).
# Test.app
page_1: _main
page_1: _bar
page_1: _foo
# Other symbols
In this case when _main gets fetched, _bar and _foo can get fetched in the memory at the same time. In case these symbols are large and they are located in consecutive pages, there is a high chance the operating system may prefetch those pages resulting in less page faults.
Because execution order of functions during an application lifecycle may depend on various factors it is impossible to have a unique order of symbols that is most efficient. Fortunately, application startup sequence is fairly deterministic and stable in general. And it is also possible to build a binary having a desired symbol order with the help of linkers like lld which is the default linker for Android NDK toolchain.
Order file is a text file containing a list of symbols. The linker uses the order of symbols in order file to lay out symbols in the binary. An order file having functions that get called during the app startup sequence can reduce page faults resulting in improved launch time. Order files can improve the launch time of mobile applications by more than 2%. The benefits of order files are more meaningful on larger apps and lower end devices. A more mature order file generation system can improve other critical user journeys.
Design
The order file generation involves the following steps
- Collect app startup sequence using compiler instrumentation technique
- Use compiler instrumentation to report every function invocation
- Run the instrumented binary to collect launch sequence in a (binary) profraw file
- Generate order file from the profraw files
- Validate order file
- Merge multiple order files into one
- Recompile the app with the merged order file
Overview
The order file generation is based on LLVM’s compiler instrumentation process. LLVM has a stage to generate the order file then recompile the source code using the order file.
Collect app startup sequence
The source code is instrumented by passing -forder-file-instrumentation to the compiler. Additionally, the -orderfile-write-mapping flag is also required for the compiler to generate a mapping file. The mapping file is generated during compilation and it is used while processing the profraw file. The mapping file shows the mapping from MD5 hash to function symbol (as shown below).
# Mapping file
MD5 db956436e78dd5fa main
MD5 83bff1e88ac48f32 _GLOBAL__sub_I_main.cpp
MD5 c943255f95351375 _Z5mergePiiii
MD5 d2d2238cf08db816 _Z9mergeSortPiii
MD5 11ed18006e729e73 _Z4partPiii
MD5 3e897b5ee8bebbd1 _Z9quickSortPiii
The profile (profraw file) is generated every time the instrumented application is executed. The profile data in the profraw file contains the MD5 hash of the functions executed in chronological order. The profraw file does not have duplicate entries because each function only outputs its MD5 hash on first invocation. A typical run of binary containing the functions listed in the mapping file above can have the following profraw entries.
# Profraw file
00000000 32 8f c4 8a e8 f1 bf 83 fa d5 8d e7 36 64 95 db |2...........6d..|
00000010 16 b8 8d f0 8c 23 d2 d2 75 13 35 95 5f 25 43 c9 |.....#..u.5._%C.|
00000020 d1 bb be e8 5e 7b 89 3e 00 00 00 00 00 00 00 00 |....^{.>........|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
In order to find the function names corresponding to the MD5 hashes in a profraw file, a corresponding mapping file is used.
Note: The compiler instrumentation for order files (-forder-file-instrumentation) only works when an optimization flag (01, 02, 03, 0s, 0z) is passed. So, if -O0 (compiler flag typically used for debug builds) is passed, the compiler will not instrument the binary. In principle, one should use the same optimization flag for instrumentation that is used in shipping release binaries.
The Android NDK repository has scripts that automate the order file generation given a mapping file and an order file.
Recompiling with Order File
Once you have an order file, you provide the path of the order file to the linker using the --symbol-ordering-file flag.
Detailed design
Creating Order File Build Property
The Android Open Source Project (AOSP) uses a build system called soong so we can leverage this build system to pass the flags as necessary. The order file build property has four main fields:
- instrumentation
- load_order_file
- order_file_path
- cflags
The cflags are meant to add other necessary flags (like mapping flags) during compilation. The load_order_file and order_file_path tells the build system to recompile with the order file rather than set it to the profiling stage. The order files must be in saved in one of two paths:
- toolchain/pgo-profiles/orderfiles
- vendor/google_data/pgo_profile/orderfiles
# Profiling
orderfile: {
instrumentation: true,
load_order_file: false,
order_file_path: "",
cflags: [
"-mllvm",
"-orderfile-write-mapping=<filename>-mapping.txt",
],
}
#Recompiling with Order File
orderfile: {
instrumentation: true,
load_order_file: true,
order_file_path: "<filename>.orderfile",
}
Creating order files
We provide a python script to create an order file from a mapping file and a profraw file. The script also allows removing a particular symbol or creating an order file until a particular symbol.
Script Flags:
- Profile file (--profile-file):
- Description: The profile file generated by running a binary compiled with -forder-file-instrumentation
- Mapping file (--mapping-file):
- Description: The mapping file generated during compilation that maps MD5 hashes to symbol names
- Output file (--output):
- Description: The output file name for the order file. Default Name: default.orderfile
- Deny List (--denylist):
- Description: Symbols that you want to exclude from the order file
- Last symbol (--last-symbol):
- Description: The order file will end at the passed last symbol and ignore the symbols after it. If you want an order file only for startup, you should pass the last startup symbol. Last-symbol has priority over leftover so we will output until the last symbol and ignore the leftover flag.
- Leftover symbols (--leftover):
- Description: Some symbols (functions) might not have been executed so they will not appear in the profile file. If you want these symbols in your order file, you can use this flag and it will add them at the end.
Validating order files
Once we get an order file for a library or binary, we need to check if it is valid based on a set of criteria. Some order files may not be of good quality so they are better discarded. This can happen due to several reasons like application terminated unexpectedly, the runtime could not write the complete profraw file before exiting, an undesired code-sequence was collected in the profile, etc. To automate this process, we provide a python script that can help developers check for:
- Partial order that needs to be in the order file
- Symbols that have to be present in order file
- Symbols that should not be present in order file
- Minimum number of symbols to make an order file
Script Flags:
- Order file (--order-file):
- Description: The order file you are validating on the below criteria.
- Partial Order (--partial):
- Description: A partial order of symbols that must be held in the order file.
- Allowed Lists (--allowlist):
- Description: Symbols that must be present in the order file.
- Denied Lists (--denylist):
- Description: Symbols that should not be in the order file. Denylist flag has priority over allowlist.
- Minimum Number of Entries (--min):
- Description: Minimum number of symbols needed for an order file
Merging orderfiles
At a higher level, the order file symbols in a collection of order files approximate a partial order (poset) of function names with order defined by time of execution. Across different runs of an application, the order files might have variations. These variations could be due to OS, device class, build version, user configurations etc. However, the linker can only take one order file to build an application. In order to have one order file that provides the desired benefits, we need to merge these order files into a single order file. The merging algorithm also needs to be efficient so as to not slow down the build time. There are non-linear clustering algorithms that may not scale well for merging large numbers of order files, each having many symbols. We provide an efficient merging algorithm that converges quickly. The algorithm allows for customizable parameters, such that developers can tune the outcome.
Merging N partial order sets can be done either pessimistically (merging a selection of order files all the way until there is one order file left) or optimistically (merging all of them at once). The pessimistic approach can be inefficient as well as sub-optimal. As a result, it is better to work with all N partial order sets at once. In order to have an efficient implementation it helps to represent all N posets with a weighted directed Graph (V,E) where:
- V: Elements of partial order sets (symbols) and the number of times it appears in different partial order sets. Note that the frequency of vertices may be greater than the sum of all incoming edges because of invocations from uninstrumented parts of binary, dependency injection etc.
- E (V1 -> V2): An edge occurs if the element of V2 immediately succeeds V1 in any partial order set with its weight being the number of times this happens.
For a binary executable, there is one root (e.g., main) vertex, but shared libraries might have many roots based on which functions are called in the binary using them. The graph gets complicated if the application has threads as they frequently result in cycles. To have a topological order, cycles are removed by preferring the highest probability path over others. A Depth-First traversal that selects the highest weighted edge serves the purpose.
Removing Cycles:
- Mark back edges during a Depth-First traversal
- For each Cycle (c):
- Add the weights of all in-edges of each vertex (v) in the cycle excluding the edges in the cycle
- Remove the cycle edge pointing **to** the vertex with highest sum
After cycles are removed, the same depth first traversal gives a topological order (the order file) when all the forward edges are removed. Essentially, the algorithm computes a minimum-spanning-tree of maximal weights and traverses the tree in topological order.
Producing an order:
printOrderUtil(G, n, order):
- If n was visited:
- return
- Add n to the end of order
- Sort all out edges based on weight
- For every out_edge (n, v):
- printOrderUtil(G, v, order)
printOrder(G):
- Get all roots
- order = []
- For each root r:
- printOrderUtil(G, r, order)
- return order
Example:
Given the following order files:
- main -> b -> c -> d
- main -> a -> c
- main -> e -> f
- main -> b
- main -> b
- main -> c -> b
The graph to the right is obtained by removing cycles.
- DFS: main -> b-> c -> b
- Back edge: c -> b
- Cycle: b -> c-> b
- Cycle edges: [b -> c, c -> b]
- b’s sum of in-edges is 3
- c’s sum of in-edges is 2
- This implies b will be traversed from a higher frequency edge, so c -> b is removed
- Ignore forward edges a->c, main->c
- The DFS of the acyclic graph on the right will produce an order file main -> b -> c -> d -> a -> e -> f after ignoring the forward edges.
Collecting order files for Android Apps (Java, Kotlin)
The order file instrumentation and profile data collection is only enabled for C/C++ applications. As a result, it cannot benefit Java or Kotlin applications. However, Android apps that ship compiled C/C++ libraries can benefit from order file.
To generate order file for libraries that are used by Java/Kotlin applications, we need to invoke the runtime methods (called as part of order file instrumentation) at the right places. There are three functions that users have to call:
- __llvm_profile_set_filename(char *f): Set the name of the file where profraw data will be dumped.
- __llvm_profile_initialize_file: Initialize the file set by __llvm_profile_set_filename
- __llvm_orderfile_dump: Dumps the profile(order file data) collected while running instrumented binary
Similarly, the compiler and linker flags should be added to build configurations. We provide template build system files e.g, CMakeLists.txt to compile with the correct flags and add a function to dump the order files when the Java/Kotlin application calls it.
# CMakeLists.txt
set(GENERATE_PROFILES ON)
#set(USE_PROFILE "${CMAKE_SOURCE_DIR}/demo.orderfile")
add_library(orderfiledemo SHARED orderfile.cpp)
target_link_libraries(orderfiledemo log)
if(GENERATE_PROFILES)
# Generating profiles require any optimization flag aside from -O0.
# The mapping file will not generate and the profile instrumentation does not work without an optimization flag.
target_compile_options( orderfiledemo PRIVATE -forder-file-instrumentation -O2 -mllvm -orderfile-write-mapping=mapping.txt )
target_link_options( orderfiledemo PRIVATE -forder-file-instrumentation )
target_compile_definitions(orderfiledemo PRIVATE GENERATE_PROFILES)
elseif(USE_PROFILE)
target_compile_options( orderfiledemo PRIVATE -Wl,--symbol-ordering-file=${USE_PROFILE} -Wl,--no-warn-symbol-ordering )
target_link_options( orderfiledemo PRIVATE -Wl,--symbol-ordering-file=${USE_PROFILE} -Wl,--no-warn-symbol-ordering )
endif()
We also provide a sample app to dump order files from a Kotlin application. The sample app creates a shared library called “orderfiledemo” and invokes the DumpProfileDataIfNeeded function to dump the order file. This library can be taken out of this sample app and can be repurposed for other applications.
// Order File Library
#if defined(GENERATE_PROFILES)
extern "C" int __llvm_profile_set_filename(const char *);
extern "C" int __llvm_profile_initialize_file(void);
extern "C" int __llvm_orderfile_dump(void);
#endif
void DumpProfileDataIfNeeded(const char *temp_dir) {
#if defined(GENERATE_PROFILES)
char profile_location[PATH_MAX] = {};
snprintf(profile_location, sizeof(profile_location), "%s/demo.output",
temp_dir);
__llvm_profile_set_filename(profile_location);
__llvm_profile_initialize_file();
__llvm_orderfile_dump();
__android_log_print(ANDROID_LOG_DEBUG, kLogTag, "Wrote profile data to %s",
profile_location);
#else
__android_log_print(ANDROID_LOG_DEBUG, kLogTag,
"Did not write profile data because the app was not "
"built for profile generation");
#endif
}
extern "C" JNIEXPORT void JNICALL
Java_com_example_orderfiledemo_MainActivity_runWorkload(JNIEnv *env,
jobject /* this */,
jstring temp_dir) {
DumpProfileDataIfNeeded(env->GetStringUTFChars(temp_dir, 0));
}
# Kotlin Application
class MainActivity : AppCompatActivity() {
private lateinit var binding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = ActivityMainBinding.inflate(layoutInflater)
setContentView(binding.root)
runWorkload(applicationContext.cacheDir.toString())
binding.sampleText.text = "Hello, world!"
}
/**
* A native method that is implemented by the 'orderfiledemo' native library,
* which is packaged with this application.
*/
external fun runWorkload(tempDir: String)
companion object {
// Used to load the 'orderfiledemo' library on application startup.
init {
System.loadLibrary("orderfiledemo")
}
}
}
Limitation
order file generation only works for native binaries. The validation and merging scripts will work for any set of order files.
References
External References





 Posted by Dominik Mengelt– Developer Relations Engineer, Payments and Florin Modrea - Product Solutions Engineer, Google Pay
Posted by Dominik Mengelt– Developer Relations Engineer, Payments and Florin Modrea - Product Solutions Engineer, Google Pay
 Posted by
Posted by 


 Posted by Jasmin Rubinovitz, AI Researcher
Posted by Jasmin Rubinovitz, AI Researcher




 Posted by
Posted by 

 Posted by Chris Wailes - Senior Software Engineer
Posted by Chris Wailes - Senior Software Engineer

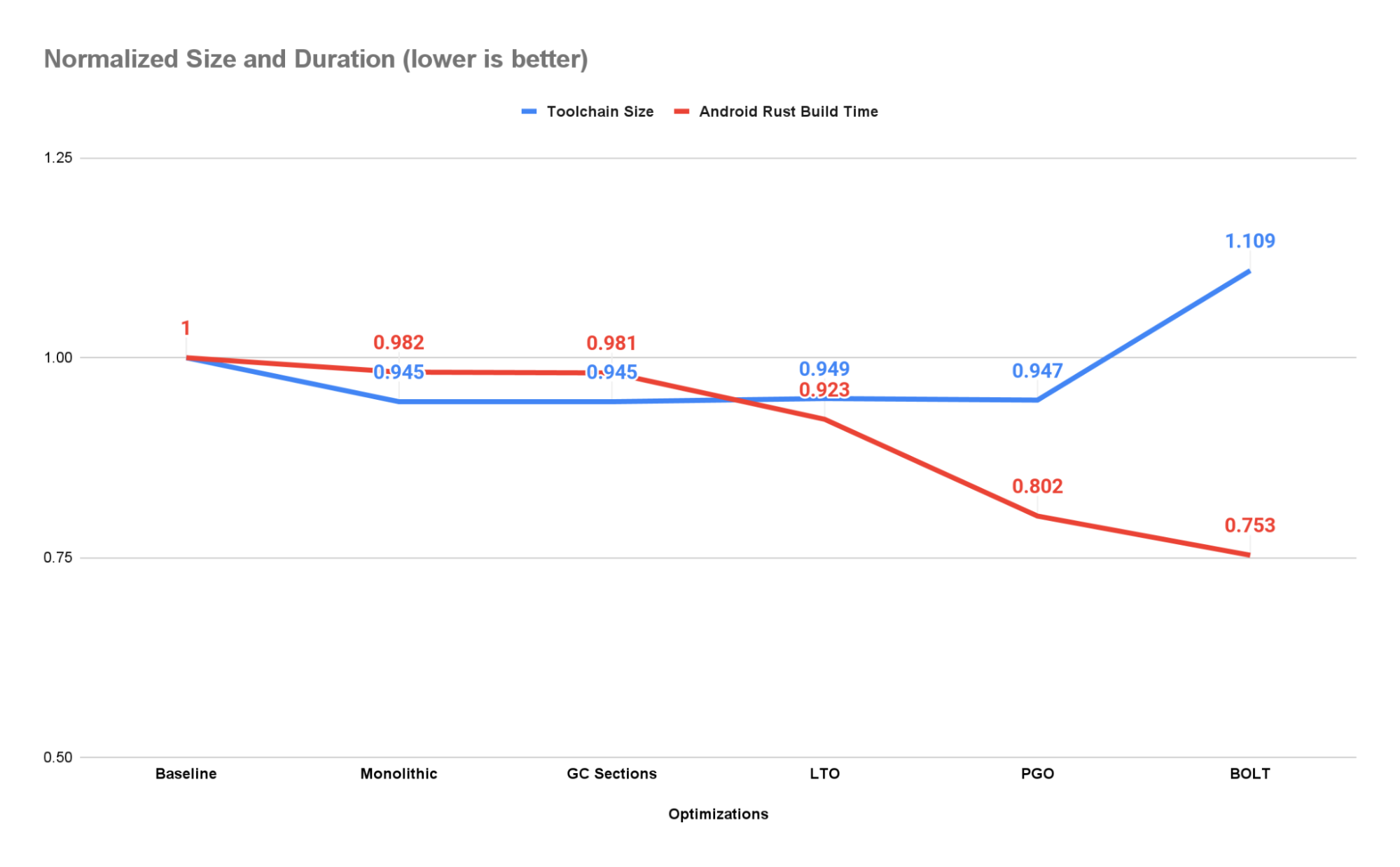

 Posted by Kaushik Sathupadi, Prakhar Srivastav, and Kristin Bi – Software Engineers; Alex Geboff – Technical Writer
Posted by Kaushik Sathupadi, Prakhar Srivastav, and Kristin Bi – Software Engineers; Alex Geboff – Technical Writer