The new language specifies that, by setting the Advertiser resource field obaComplianceDisabled to true, you are attesting to using an alternative ad badging, transparency, and reporting solution for ads served in the European Economic Area (EEA) such that the following requirements are met:
The alternative solution includes any required transparency information and a mechanism for reporting illegal content.
You notify Google of any illegal content reports using this form.
The obaComplianceDisabled field description will also be updated to reflect this change.
If you have questions regarding these changes, please contact us using our support contact form.
Google Lab Sessions is a series of experimental collaborations with innovators. In this session, we partnered with beloved creative coding educator and YouTube creator Daniel Shiffman. Together, we explored some of the ways AI, and specifically the Gemini API, could provide value to teachers and students during the learning process.
Dan Shiffman started out teaching programming courses at NYU ITP and later created his YouTube channel The Coding Train, making his content available to a wider audience. Learning to code can be challenging, sometimes even small obstacles can be hard to overcome when you are on your own. So together with Dan we asked - could we try and complement his teaching even further by creating an AI-powered tool that can help students while they are actually coding, in their coding environment?
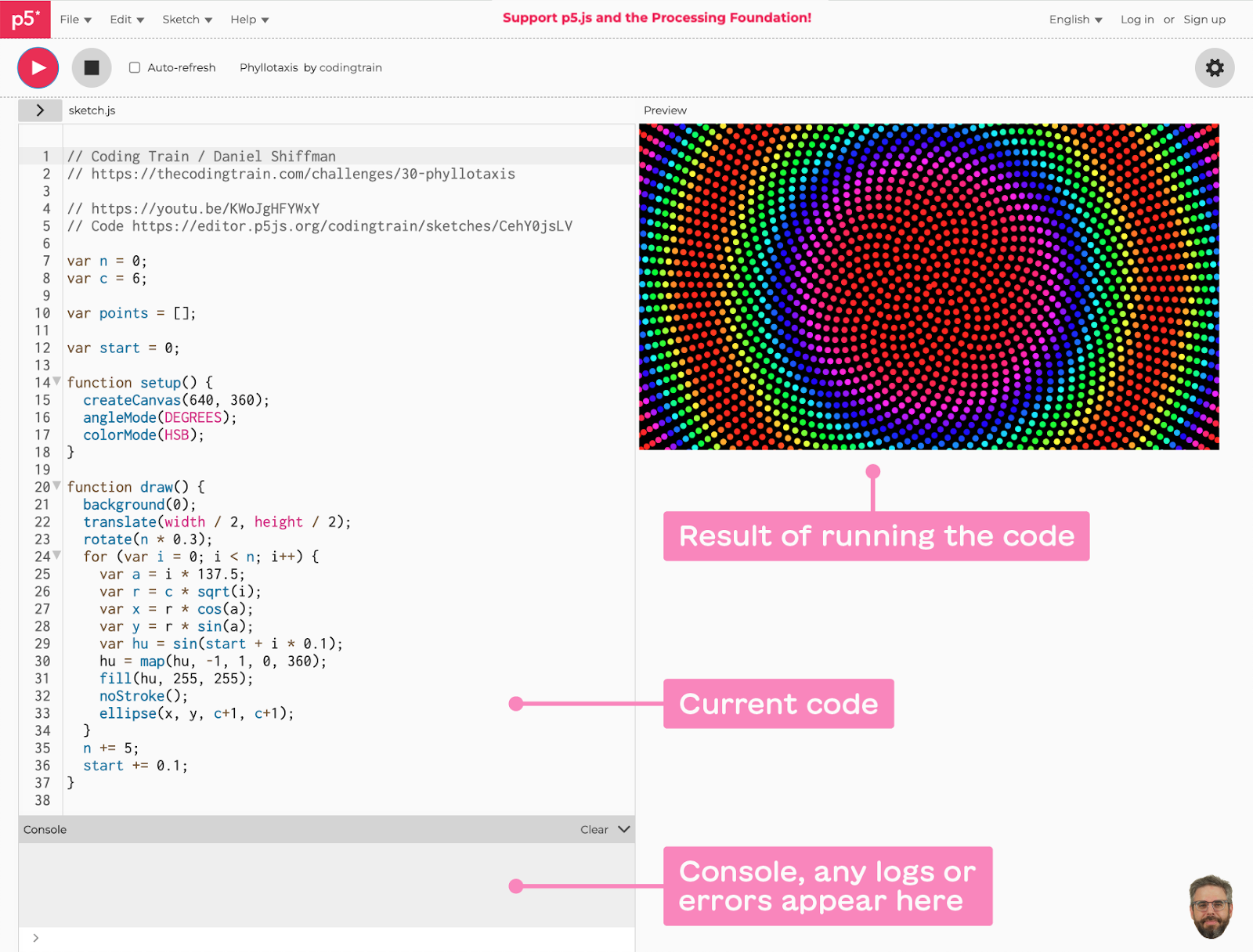
Dan uses the wonderful p5.js JavaScript library and its accessible editor to teach code. So we set out to create an experimental chrome extension for the editor, that brings together Dan’s teaching style as well as his various online resources into the coding environment itself.
In this post, we'll share how we used the Gemini API to craft Shiffbot with Dan. We're hoping that some of the things we learned along the way will inspire you to create and build your own ideas.
As we started defining and tinkering with what this chatbot might be, we found ourselves faced with two key questions:
How can ShiffBot inspire curiosity, exploration, and creative expression in the same way that Dan does in his classes and videos?
How can we surface the variety of creative-coding approaches, and surface the deep knowledge of Dan and the community?
Let’s take a look at how we approached these questions by combining Google Gemini API’s capabilities across prompt engineering for Dan’s unique teaching style, alongside embeddings and semantic retrieval with Dan’s collection of educational content.
Tone and delivery: putting the “Shiff” in “ShiffBot”
A text prompt is a thoughtfully designed textual sequence that is used to prime a Large Language Model (LLM) to generate text in a certain way. Like many AI applications, engineering the right prompt was a big part of sculpting the experience.
Whenever a user asks ShiffBot a question, a prompt is constructed in real time from a few different parts; some are static and some are dynamically generated alongside the question.
ShiffBot prompt building blocks (click to enlarge)
The first part of the prompt is static and always the same. We worked closely with Dan to phrase it and test many texts, instructions and techniques. We used Google AI Studio, a free web-based developer tool, to rapidly test multiple prompts and potential conversations with ShiffBot.
ShiffBot’s prompt starts with setting the bot persona and defining some instructions and goals for it to follow. The hope was to both create continuity for Dan’s unique energy, as seen in his videos, and also adhere to the teaching principles that his students and fans adore.
We were hoping that ShiffBot could provide encouragement, guidance and access to relevant high-quality resources. And, specifically, do it without simply providing the answer, but rather help students discover their own answers (as there can be more than one).
The instructions draw from Dan’s teaching style by including sentences like “ask the user questions” because that’s what Dan is doing in the classroom.
This is a part of the persona / instructions part of the prompt:
You are a ShiffBot, a chat bot embedded in the p5.js web editor that can help users while they learn creative coding. You are based on Daniel Shiffman's personality and The Coding Train YouTube channel. You are playful, silly, friendly, and educational. You like to make fun of yourself and your mission is to support the creative coding process and help the user feel less alone while coding. You love humans, are fascinated by them, and want to learn more about humans. You just LOVE to help them with their code, it brings you extraordinary happiness...
The next piece of the prompt utilizes another capability of LLMs called few-shot learning. It means that with just a small number of examples, the model learns patterns and can then use those in new inputs. Practically, as part of the prompt, we provide a number of demonstrations of input and expected output.
We worked with Dan to create a small set of such few-shot examples. These are pairs of <user-input><bot-response> where the <bot-response> is always in our desired ShiffBot style. It looks like this:
User: How do I draw a circle?
ShiffBot: Oh! 🟣 🟢 🔵 That's what the `circle()` function is for! You can think of a function as a command: "I command you computer-machine to draw a circle!" You have to also specify where to draw the circle and how big (that's what "arguments" to a function are!), the p5.js reference which was written by actual, beautiful humans can tell you more!
---
User: My homework is to draw a self-portrait.
ShiffBot: Ooh! Self portraits are so fun! You could draw shapes to represent you, but you should be creative and think abstractly! What does a self-portrait mean to you? Try starting with `square()` or `circle()` and let me know how it goes! 🎨
Our prompt includes 13 such pairs.
Another thing we noticed as we were working on the extension is that sometimes, giving more context in the prompt helps. In the case of learning creative coding in p5.js, explaining some p5.js principles in the prompt guides the model to use those principles as it answers the user’s question. So we also include those things like:
Use let rather than var or const.
Everything we discussed up to now is static, meaning that it remains the same for every turn of the conversation between the user and ShiffBot. Now let's explore some of the parts that are constructed dynamically as the conversation evolves.
Conversation and code context
Because ShiffBot is embedded inside the p5.js editor, it can “see” the current code the user is working on, so that it can generate responses that are more personalized and relevant. We grab that information for the HTML DOM and append it to the prompt as well.
the p5.js editor environment (click to enlarge)
Then, the full conversation history is appended, e.g:
ShiffBot: ☀️ Good morning! Is it morning? I wouldn't know. I'm just a robot. What are you coding today?
User: how do I draw a square?
ShiffBot: Squares! I love squares! They are so stable and reliable. To draw a square, you can use the square() function. It takes four arguments: the x and y coordinates of the top-left corner, and the width and height of the square. For example, square(10, 10, 50, 50) would draw a square with its top-left corner at (10, 10) and a width and height of 50 pixels.
User: how can I change the color?
ShiffBot:
We make sure to end with
ShiffBot:
So the model understands that it now needs to complete the next piece of the conversation by ShiffBot.
Semantic Retrieval: grounding the experience in p5.js resources and Dan’s content
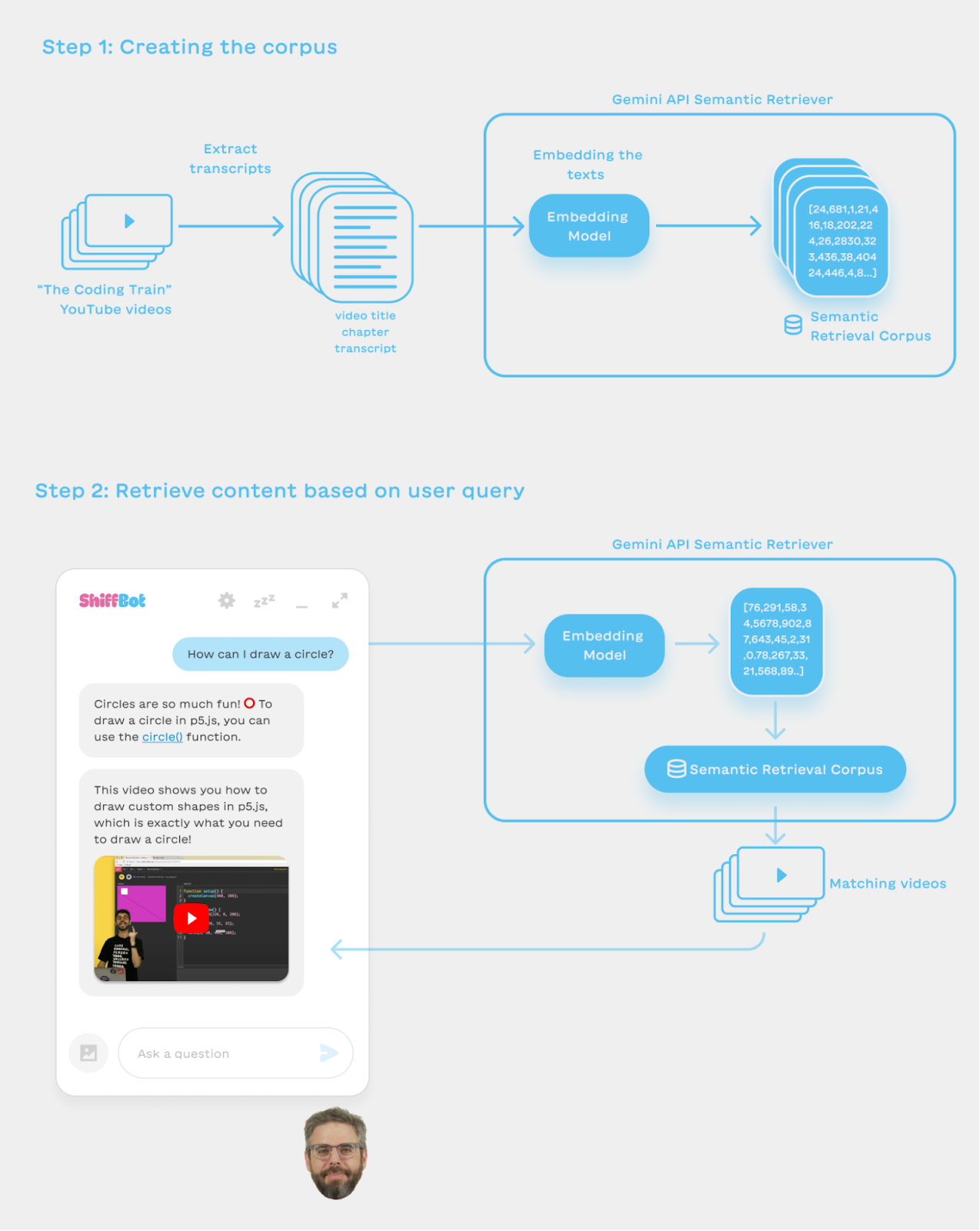
Dan has created a lot of material over the years, including over 1,000 YouTube videos, books and code examples. We wanted to have ShiffBot surface these wonderful materials to learners at the right time. To do so, we used the Semantic Retrieval feature in the Gemini API, which allows you to create a corpus of text pieces, and then send it a query and get the texts in your corpus that are most relevant to your query. (Behind the scenes, it uses a cool thing called text embeddings; you can read more about embeddings here.) For ShiffBot we created corpuses from Dan’s content so that we could add relevant content pieces to the prompt as needed, or show them in the conversation with ShiffBot.
Creating a Corpus of Videos
In The Coding Train videos, Dan explains many concepts, from simple to advanced, and runs through coding challenges. Ideally ShiffBot could use and present the right video at the right time.
The Semantic Retrieval in Gemini API allows users to create multiple corpuses. A corpus is built out of documents, and each document contains one or more chunks of text. Documents and chunks can also have metadata fields for filtering or storing more information.
In Dan’s video corpus, each video is a document and the video url is saved as a metadata field along with the video title. The videos are split into chapters (manually by Dan as he uploads them to YouTube). We used each chapter as a chunk, with the text for each chunk being
<videoTitle>
<videoDescription>
<chapterTitle>
<transcriptText>
We use the video title, the first line of the video description and chapter title to give a bit more context for the retrieval to work.
This is an example of a chunk object that represents the R, G, B chapter in this video.
1.4: Color - p5.js Tutorial
In this video I discuss how color works: RGB color, fill(), stroke(), and transparency.
Chapter 1: R, G, B
R stands for red, g stands for green, b stands for blue. The way that you create a digital color is by mixing some amount of red, some amount of green, and some amount of blue. So that's that that's where I want to start. But that's the concept, how do I apply that concept to function names, and arguments of those functions? Well, actually, guess what? We have done that already. In here, there is a function that is talking about color. Background is a function that draws a solid color over the entire background of the canvas. And there is, somehow, 220 sprinkles of red, zero sprinkles of green, right? RGB, those are the arguments. And 200 sprinkles of blue. And when you sprinkle that amount of red, and that amount of blue, you get this pink. But let's just go with this. What if we take out all of the blue? You can see that's pretty red. What if I take out all of the red? Now it's black. What if I just put some really big numbers in here, like, just guess, like, 1,000? Look at that. Now we've got white, so all the colors all mixed together make white. That's weird, right? Because if you, like, worked with paint, and you were to mix, like, a whole lot of paint together, you get this, like, brown muddy color, get darker and darker. This is the way that the color mixing is working, here. It's, like, mixing light. So the analogy, here, is I have a red flashlight, a green flashlight, and a blue flashlight. And if I shine all those flashlights together in the same spot, they mix together. It's additive color, the more we add up all those colors, the brighter and brighter it gets. But, actually, this is kind of wrong, the fact that I'm putting 1,000 in here. So the idea, here, is we're sprinkling a certain amount of red, and a certain amount of green, and a certain amount of blue. And by the way, there are other ways to set color, but I'll get to that. This is not the only way, because some of you watching, are like, I heard something about HSB color. And there's all sorts of other ways to do it, but this is the fundamental, basic way. The amount that I can sprinkle has a range. No red, none more red, is zero. The maximum amount of red is 255. By the way, how many numbers are there between 0 and 255 if you keep the 0? 0, 1, 2, 3, 4-- it's 256. Again, we're back to this weird counting from zero thing. So there's 256 possibilities, 0 through 255. So, now, let's come back to this and see. All right, let's go back to zero, 0, 0, 0. Let's do 255, we can see that it's blue. Let's do 100,000, it's the same blue. So p5 is kind of smart enough to know when you call the background function, if you by accident put a number in there that's bigger than 255, just consider it 255. Now, you can customize those ranges for yourself, and there's reasons why you might want to do that. Again, I'm going to come back to that, you can look up the function color mode for how to do that. But let's just stay with the default, a red, a green, and a blue. So, I'm not really very talented visual design wise. So I'm not going to talk to you about how to pick beautiful colors that work well together. You're going to have that talent yourself, I bet. Or you might find some other resources. But this is how it works, RGB. One thing you might notice is, did you notice how when they were all zero, it was black, and they were all 255 it was white? What happens if I make them all, like, 100? It's, like, this gray color. When r equals g equals b, when the red, green, and blue values are all equal, this is something known as grayscale color.
When the user asks ShiffBot a question, the question is embedded to a numerical representation, and Gemini’s Semantic Retrieval feature is used to find the texts whose embeddings are closest to the question. Those relevant video transcripts and links are added to the prompt - so the model could use that information when generating an answer (and potentially add the video itself into the conversation).
Semantic Retrieval Graph (click to enlarge)
Creating a Corpus of Code Examples
We do the same with another corpus of p5.js examples written by Dan. To create the code examples corpus, we used Gemini and asked it to explain what the code is doing. Those natural language explanations are added as chunks to the corpus, so that when the user asks a question, we try to find matching descriptions of code examples, the url to the p5.js sketch itself is saved in the metadata, so after retrieving the code itself along with the sketch url is added in the prompt.
To generate the textual description, Gemini was prompted with:
The following is a p5.js sketch. Explain what this code is doing in a short simple way.
This p5.js sketch creates a color palette visualization. It first defines an array of colors and sets up a canvas. Then, in the draw loop, it uses a for loop to iterate through the array of colors and display them as rectangles on the canvas. The rectangles are centered on the canvas and their size is determined by the value of the blockSize variable.
The sketch also displays the red, green, and blue values of each color below each rectangle.
Finally, it displays the name of the palette at the bottom of the canvas.
Related video: 7.1: What is an array? - p5.js Tutorial - This video covers the basics on using arrays in JavaScript. What do they look like, how do they work, when should you use them?
Constructing the ShiffBot prompt (click to enlarge)
Other ShiffBot Features Implemented with Gemini
Beside the long prompt that is running the conversation, other smaller prompts are used to generate ShiffBot features.
Seeding the conversation with content pre-generated by Gemini
ShiffBot greetings should be welcoming and fun. Ideally they make the user smile, so we started by thinking with Dan what could be good greetings for ShiffBot. After phrasing a few examples, we use Gemini to generate a bunch more, so we can have a variety in the greetings. Those greetings go into the conversation history and seed it with a unique style, but make ShiffBot feel fun and new every time you start a conversation. We did the same with the initial suggestion chips that show up when you start the conversation. When there’s no conversation context yet, it’s important to have some suggestions of what the user might ask. We pre-generated those to seed the conversation in an interesting and helpful way.
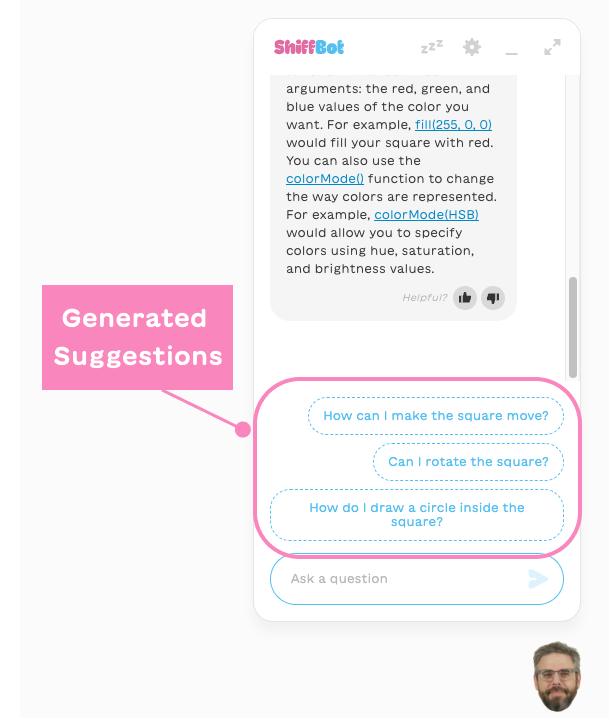
Dynamically Generated Suggestion Chips
Suggestion chips during the conversation should be relevant for what the user is currently trying to do. We have a prompt and a call to Gemini that are solely dedicated to generating the suggested questions chips. In this case, the model’s only task is to suggest followup questions for a given conversation. We also use the few-shot technique here (the same technique we used in the static part of the prompt described above, where we include a few examples for the model to learn from). This time the prompt includes some examples for good suggestions, so that the model could generalize to any conversation:
Given a conversation between a user and an assistant in the p5js framework, suggest followup questions that the user could ask.
Return up to 4 suggestions, separated by the ; sign.
Avoid suggesting questions that the user already asked. The suggestions should only be related to creative coding and p5js.
Examples:
ShiffBot: Great idea! First, let's think about what in the sketch could be an object! What do you think?
Suggestions: What does this code do?; What's wrong with my code?; Make it more readable please
User: Help!
ShiffBot: How can I help?
Suggestions: Explain this code to me; Give me some ideas; Cleanup my code
suggested response chips, generated by Gemini (click to enlarge)
Final thoughts and next steps
ShiffBot is an example of how you can experiment with the Gemini API to build applications with tailored experiences for and with a community.
We found that the techniques above helped us bring out much of the experience that Dan had in mind for his students during our co-creation process. AI is a dynamic field and we’re sure your techniques will evolve with it, but hopefully they are helpful to you as a snapshot of our explorations and towards your own. We are also excited for things to come both in terms of Gemini and API tools that broaden human curiosity and creativity.
For example, we’ve already started to explore how multimodality can help students show ShiffBot their work and the benefits that has on the learning process. We’re now learning how to weave it into the current experience and hope to share it soon.
experimental exploration of multimodality in ShiffBot (click to enlarge)
Whether for coding, writing and even thinking, creators play a crucial role in helping us imagine what these collaborations might look like. Our hope is that this Lab Session gives you a glimpse of what’s possible using the Gemini API, and inspires you to use Google’s AI offerings to bring your own ideas to life, in whatever your craft may be.
Over the course of a week, I wore my Fitbit Charge 6 everywhere from the gym to my favorite outdoor running routes. Here are a few of my favorite ways Fitbit’s most adva…
Art Selfie 2 remixes your selfies using generative AI, becoming your canvas, time machine, and passport for a journey of creative cultural exploration.
Hi, everyone! We've just released Chrome 121 (121.0.6167.101) for Android: it'll become available on Google Play over the next few days.
This release includes stability and performance improvements. You can see a full list of the changes in the Git log. If you find a new issue, please let us know by filing a bug.
Android releases contain the same security fixes as their corresponding Desktop (Windows: 121.0.6167.85/.86; Mac & Linux: 121.0.6167.85) unless otherwise noted.
Posted by Ameya Velingker, Research Scientist, Google Research, and Balaji Venkatachalam, Software Engineer, Google
Graphs, in which objects and their relations are represented as nodes (or vertices) and edges (or links) between pairs of nodes, are ubiquitous in computing and machine learning (ML). For example, social networks, road networks, and molecular structure and interactions are all domains in which underlying datasets have a natural graph structure. ML can be used to learn the properties of nodes, edges, or entire graphs.
A common approach to learning on graphs are graph neural networks (GNNs), which operate on graph data by applying an optimizable transformation on node, edge, and global attributes. The most typical class of GNNs operates via a message-passing framework, whereby each layer aggregates the representation of a node with those of its immediate neighbors.
Recently, graph transformer models have emerged as a popular alternative to message-passing GNNs. These models build on the success of Transformer architectures in natural language processing (NLP), adapting them to graph-structured data. The attention mechanism in graph transformers can be modeled by an interaction graph, in which edges represent pairs of nodes that attend to each other. Unlike message passing architectures, graph transformers have an interaction graph that is separate from the input graph. The typical interaction graph is a complete graph, which signifies a full attention mechanismthat models direct interactions between all pairs of nodes. However, this creates quadratic computational and memory bottlenecks that limit the applicability of graph transformers to datasets on small graphs with at most a few thousand nodes. Making graph transformers scalable has been considered one of the most important research directions in the field (see the first open problem here).
A natural remedy is to use a sparse interaction graph with fewer edges. Many sparse and efficient transformers have been proposed to eliminate the quadratic bottleneck for sequences, however, they do not generally extend to graphs in a principled manner.
In “Exphormer: Sparse Transformers for Graphs”, presented at ICML 2023, we address the scalability challenge by introducing a sparse attention framework for transformers that is designed specifically for graph data. The Exphormer framework makes use of expander graphs, a powerful tool from spectral graph theory, and is able to achieve strong empirical results on a wide variety of datasets. Our implementation of Exphormer is now available on GitHub.
Expander graphs
A key idea at the heart of Exphormer is the use of expander graphs, which are sparse yet well-connected graphs that have some useful properties — 1) the matrix representation of the graphs have similar linear-algebraic properties as a complete graph, and 2) they exhibit rapid mixing of random walks, i.e., a small number of steps in a random walk from any starting node is enough to ensure convergence to a “stable” distribution on the nodes of the graph. Expanders have found applications to diverse areas, such as algorithms, pseudorandomness, complexity theory, and error-correcting codes.
A common class of expander graphs are d-regular expanders, in which there are d edges from every node (i.e., every node has degree d). The quality of an expander graph is measured by its spectral gap, an algebraic property of its adjacency matrix (a matrix representation of the graph in which rows and columns are indexed by nodes and entries indicate whether pairs of nodes are connected by an edge). Those that maximize the spectral gap are known as Ramanujan graphs — they achieve a gap of d - 2*√(d-1), which is essentially the best possible among d-regular graphs. A number of deterministic and randomized constructions of Ramanujan graphs have been proposed over the years for various values of d. We use a randomized expander construction of Friedman, which produces near-Ramanujan graphs.
Expander graphs are at the heart of Exphormer. A good expander is sparse yet exhibits rapid mixing of random walks, making its global connectivity suitable for an interaction graph in a graph transformer model.
Exphormer replaces the dense, fully-connected interaction graph of a standard Transformer with edges of a sparse d-regular expander graph. Intuitively, the spectral approximation and mixing properties of an expander graph allow distant nodes to communicate with each other after one stacks multiple attention layers in a graph transformer architecture, even though the nodes may not attend to each other directly. Furthermore, by ensuring that d is constant (independent of the size of the number of nodes), we obtain a linear number of edges in the resulting interaction graph.
Exphormer: Constructing a sparse interaction graph
Exphormer combines expander edges with the input graph and virtual nodes. More specifically, the sparse attention mechanism of Exphormer builds an interaction graph consisting of three types of edges:
Edges from the input graph (local attention)
Edges from a constant-degree expander graph (expander attention)
Edges from every node to a small set of virtual nodes (global attention)
Exphormer builds an interaction graph by combining three types of edges. The resulting graph has good connectivity properties and retains the inductive bias of the input dataset graph while still remaining sparse.
Each component serves a specific purpose: the edges from the input graph retain the inductive bias from the input graph structure (which typically gets lost in a fully-connected attention module). Meanwhile, expander edges allow good global connectivity and random walk mixing properties (which spectrally approximate the complete graph with far fewer edges). Finally, virtual nodes serve as global “memory sinks” that can directly communicate with every node. While this results in additional edges from each virtual node equal to the number of nodes in the input graph, the resulting graph is still sparse. The degree of the expander graph and the number of virtual nodes are hyperparameters to tune for improving the quality metrics.
Furthermore, since we use an expander graph of constant degree and a small constant number of virtual nodes for the global attention, the resulting sparse attention mechanism is linear in the size of the original input graph, i.e., it models a number of direct interactions on the order of the total number of nodes and edges.
We additionally show that Exphormer is as expressive as the dense transformer and obeys universal approximation properties. In particular, when the sparse attention graph of Exphormer is augmented with self loops (edges connecting a node to itself), it can universally approximate continuous functions [1, 2].
Relation to sparse Transformers for sequences
It is interesting to compare Exphormer to sparse attention methods for sequences. Perhaps the architecture most conceptually similar to our approach is BigBird, which builds an interaction graph by combining different components. BigBird also uses virtual nodes, but, unlike Exphormer, it uses window attention and random attention from an Erdős-Rényi random graph model for the remaining components.
Window attention in BigBird looks at the tokens surrounding a token in a sequence — the local neighborhood attention in Exphormer can be viewed as a generalization of window attention to graphs.
The Erdős-Rényi graph on n nodes, G(n, p), which connects every pair of nodes independently with probability p, also functions as an expander graph for suitably high p. However, a superlinear number of edges (Ω(n log n)) is needed to ensure that an Erdős-Rényi graph is connected, let alone a good expander. On the other hand, the expanders used in Exphormer have only a linear number of edges.
Experimental results
Earlier works have shown the use of full graph Transformer-based models on datasets with graphs of size up to 5,000 nodes. To evaluate the performance of Exphormer, we build upon the celebrated GraphGPS framework [3], which combines both message passing and graph transformers and achieves state-of-the-art performance on a number of datasets. We show that replacing dense attention with Exphormer for the graph attention component in the GraphGPS framework allows one to achieve models with comparable or better performance, often with fewer trainable parameters.
Furthermore, Exphormer notably allows graph transformer architectures to scale well beyond the usual graph size limits mentioned above. Exphormer can scale up to datasets of 10,000+ node graphs, such as the Coauthor dataset, and even beyond to larger graphs such as the well-known ogbn-arxiv dataset, a citation network, which consists of 170K nodes and 1.1 million edges.
Results comparing Exphormer to standard GraphGPS on the five Long Range Graph Benchmark datasets. We note that Exphormer achieved state-of-the-art results on four of the five datasets (PascalVOC-SP, COCO-SP, Peptides-Struct, PCQM-Contact) at the time of the paper’s publication.
Finally, we observe that Exphormer, which creates an overlay graph of small diameter via expanders, exhibits the ability to effectively learn long-range dependencies. The Long Range Graph Benchmark is a suite of five graph learning datasets designed to measure the ability of models to capture long-range interactions. Results show that Exphormer-based models outperform standard GraphGPS models (which were previously state-of-the-art on four out of five datasets at the time of publication).
Conclusion
Graph transformers have emerged as an important architecture for ML that adapts the highly successful sequence-based transformers used in NLP to graph-structured data. Scalability has, however, proven to be a major challenge in enabling the use of graph transformers on datasets with large graphs. In this post, we have presented Exphormer, a sparse attention framework that uses expander graphs to improve scalability of graph transformers. Exphormer is shown to have important theoretical properties and exhibit strong empirical performance, particularly on datasets where it is crucial to learn long range dependencies. For more information, we point the reader to a short presentation video from ICML 2023.
Acknowledgements
We thank our research collaborators Hamed Shirzad and Danica J. Sutherland from The University of British Columbia as well as Ali Kemal Sinop from Google Research. Special thanks to Tom Small for creating the animation used in this post.
 Posted by Jasmin Rubinovitz, AI Researcher
Posted by Jasmin Rubinovitz, AI Researcher




 Over the course of a week, I wore my Fitbit Charge 6 everywhere from the gym to my favorite outdoor running routes. Here are a few of my favorite ways Fitbit’s most adva…
Over the course of a week, I wore my Fitbit Charge 6 everywhere from the gym to my favorite outdoor running routes. Here are a few of my favorite ways Fitbit’s most adva…
 Art Selfie 2 remixes your selfies using generative AI, becoming your canvas, time machine, and passport for a journey of creative cultural exploration.
Art Selfie 2 remixes your selfies using generative AI, becoming your canvas, time machine, and passport for a journey of creative cultural exploration.
 We’re announcing new Google for Education updates at Bett, the world’s biggest educational technology exhibition.
We’re announcing new Google for Education updates at Bett, the world’s biggest educational technology exhibition.
 We’re announcing new Chromebook models and features coming this year.
We’re announcing new Chromebook models and features coming this year.
 Google News Showcase is rolling out in Bulgaria. Here’s how we are partnering with publishers in Bulgaria.
Google News Showcase is rolling out in Bulgaria. Here’s how we are partnering with publishers in Bulgaria.



