Digital zoom using algorithms (rather than lenses) has long been the “ugly duckling” of mobile device cameras. As compared to the optical zoom capabilities of DSLR cameras, the quality of digitally zoomed images has not been competitive, and conventional wisdom is that the complex optics and mechanisms of larger cameras can't be replaced with much more compact mobile device cameras and clever algorithms.
With the new Super Res Zoom feature on the Pixel 3, we are challenging that notion.
The Super Res Zoom technology in Pixel 3 is different and better than any previous digital zoom technique based on upscaling a crop of a single image, because we merge many frames directly onto a higher resolution picture. This results in greatly improved detail that is roughly competitive with the 2x optical zoom lenses on many other smartphones. Super Res Zoom means that if you pinch-zoom before pressing the shutter, you’ll get a lot more details in your picture than if you crop afterwards.
 |
| Crops of 2x Zoom: Pixel 2, 2017 vs. Super Res Zoom on the Pixel 3, 2018. |
Digital zoom is tough because a good algorithm is expected to start with a lower resolution image and "reconstruct" missing details reliably — with typical digital zoom a small crop of a single image is scaled up to produce a much larger image. Traditionally, this is done by linear interpolation methods, which attempt to recreate information that is not available in the original image, but introduce a blurry- or “plasticy” look that lacks texture and details. In contrast, most modern single-image upscalers use machine learning (including our own earlier work, RAISR). These magnify some specific image features such as straight edges and can even synthesize certain textures, but they cannot recover natural high-resolution details. While we still use RAISR to enhance the visual quality of images, most of the improved resolution provided by Super Res Zoom (at least for modest zoom factors like 2-3x) comes from our multi-frame approach.
Color Filter Arrays and Demosaicing
Reconstructing fine details is especially difficult because digital photographs are already incomplete — they’ve been reconstructed from partial color information through a process called demosaicing. In typical consumer cameras, the camera sensor elements are meant to measure only the intensity of the light, not directly its color. To capture real colors present in the scene, cameras use a color filter array placed in front of the sensor so that each pixel measures only a single color (red, green, or blue). These are arranged in a Bayer pattern as shown in the diagram below.
 |
| A Bayer mosaic color filter. Every 2x2 group of pixels captures light filtered by a specific color — two green pixels (because our eyes are more sensitive to green), one red, and one blue. This pattern is repeated across the whole image. |
 |
| Demosaicing reconstructs missing color information by using neighboring neighboring pixels. |
The situation gets worse if you pinch-zoom on a mobile device; then algorithms are forced to make up even more information, again by interpolation from the nearby pixels. However, not all is lost. This is where burst photography and the fusion of multiple images can be used to allow for super-resolution, even when limited by mobile device optics.
From Burst Photography to Multi-frame Super-resolution
While a single frame doesn't provide enough information to fill in the missing colors , we can get some of this missing information from multiple images taken successively. The process of capturing and combining multiple sequential photographs is known as burst photography. Google’s HDR+ algorithm, successfully used in Nexus and Pixel phones, already uses information from multiple frames to make photos from mobile phones reach the level of quality expected from a much larger sensor; could a similar approach be used to increase image resolution?
It has been known for more than a decade, including in astronomy where the basic concept is known as “drizzle”, that capturing and combining multiple images taken from slightly different positions can yield resolution equivalent to optical zoom, at least at low magnifications like 2x or 3x and in good lighting conditions. In this process, called muti-frame super-resolution, the general idea is to align and merge low-resolution bursts directly onto a grid of the desired (higher) resolution. Here's an example of how an idealized multi-frame super-resolution algorithm might work:
 |
| As compared to the standard demosaicing pipeline that needs to interpolate the missing colors (top), ideally, one could fill some holes from multiple images, each shifted by one pixel horizontally or vertically. |
Over the years, the practical usage of this “super-res” approach to higher resolution imaging remained confined largely to the laboratory, or otherwise controlled settings where the sensor and the subject were aligned and the movement between them was either deliberately controlled or tightly constrained. For instance, in astronomical imaging, a stationary telescope sees a predictably moving sky. But in widely used imaging devices like the modern-day smartphone, the practical usage of super-res for zoom in applications like mobile device cameras has remained mostly out of reach.
This is in part due to the fact that in order for this to work properly, certain conditions need to be satisfied. First, and most important, is that the lens needs to resolve detail better than the sensor used (in contrast, you can imagine a case where the lens is so poorly-designed that adding a better sensor provides no benefit). This property is often observed as an unwanted artifact of digital cameras called aliasing.
Image Aliasing
Aliasing occurs when a camera sensor is unable to faithfully represent all patterns and details present in a scene. A good example of aliasing are Moiré patterns, sometimes seen on TV as a result of an unfortunate choice of wardrobe. Furthermore, the aliasing effect on a physical feature (such as an edge of a table) changes when things move in a scene. You can observe this in the following burst sequence, where slight motions of the camera during the burst sequence create time-varying alias effects:
 |
| Left: High-resolution, single image of a table edge against a high frequency patterned background, Right: Different frames from a burst. Aliasing and Moiré effects are visible between different frames — pixels seem to jump around and produce different colored patterns. |
Practical Super-resolution Using Hand Motion
As noted earlier, some DSLR cameras offer special tripod super-resolution modes that work in a way similar to what we described so far. These approaches rely on the physical movement of the sensors and optics inside the camera, but require a complete stabilization of the camera otherwise, which is impractical in mobile devices, since they are nearly always handheld. This would seem to create a catch-22 for super-resolution imaging on mobile platforms.
However, we turn this difficulty on its head, by using the hand-motion to our advantage. When we capture a burst of photos with a handheld camera or phone, there is always some movement present between the frames. Optical Image Stabilization (OIS) systems compensate for large camera motions - typically 5-20 pixels between successive frames spaced 1/30 second apart - but are unable to completely eliminate faster, lower magnitude, natural hand tremor, which occurs for everyone (even those with “steady hands”). When taking photos using mobile phones with a high resolution sensor, this hand tremor has a magnitude of just a few pixels.
 |
| Effect of hand tremor as seen in a cropped burst, after global alignment. |
When hand motion is not present because the device is completely stabilized (e.g. placed on a tripod), we can still achieve our goal of simulating natural hand motion by intentionally “jiggling” the camera, by forcing the OIS module to move slightly between the shots. This movement is extremely small and chosen such that it doesn’t interfere with normal photos - but you can observe it yourself on Pixel 3 by holding the phone perfectly still, such as by pressing it against a window, and maximally pinch-zooming the viewfinder. Look for a tiny but continuous elliptical motion in distant objects, like that shown below.

The description of the ideal process we gave above sounds simple, but super-resolution is not that easy — there are many reasons why it hasn’t widely been used in consumer products like mobile phones, and requires the development of significant algorithmic innovations. Challenges can include:
- A single image from a burst is noisy, even in good lighting. A practical super-resolution algorithm needs to be aware of this noise and work correctly despite it. We don’t want to get just a higher resolution noisy image - our goal is to both increase the resolution but also produce a much less noisy result.

Left: Single frame frame from a burst taken in good light conditions can still contain a substantial amount of noise due to underexposure. Right: Result of merging multiple frames after burst processing. - Motion between images in a burst is not limited to just the movement of the camera. There can be complex motions in the scene such as wind-blown leaves, ripples moving across the surface of water, cars, people moving or changing their facial expressions, or the flicker of a flame — even some movements that cannot be assigned a single, unique motion estimate because they are transparent or multi-layered, such as smoke or glass. Completely reliable and localized alignment is generally not possible, and therefore a good super-resolution algorithm needs to work even if motion estimation is imperfect.
- Because much of motion is random, even if there is good alignment, the data may be dense in some areas of the image and sparse in others. The crux of super-resolution is a complex interpolation problem, so the irregular spread of data makes it challenging to produce a higher-resolution image in all parts of the grid.


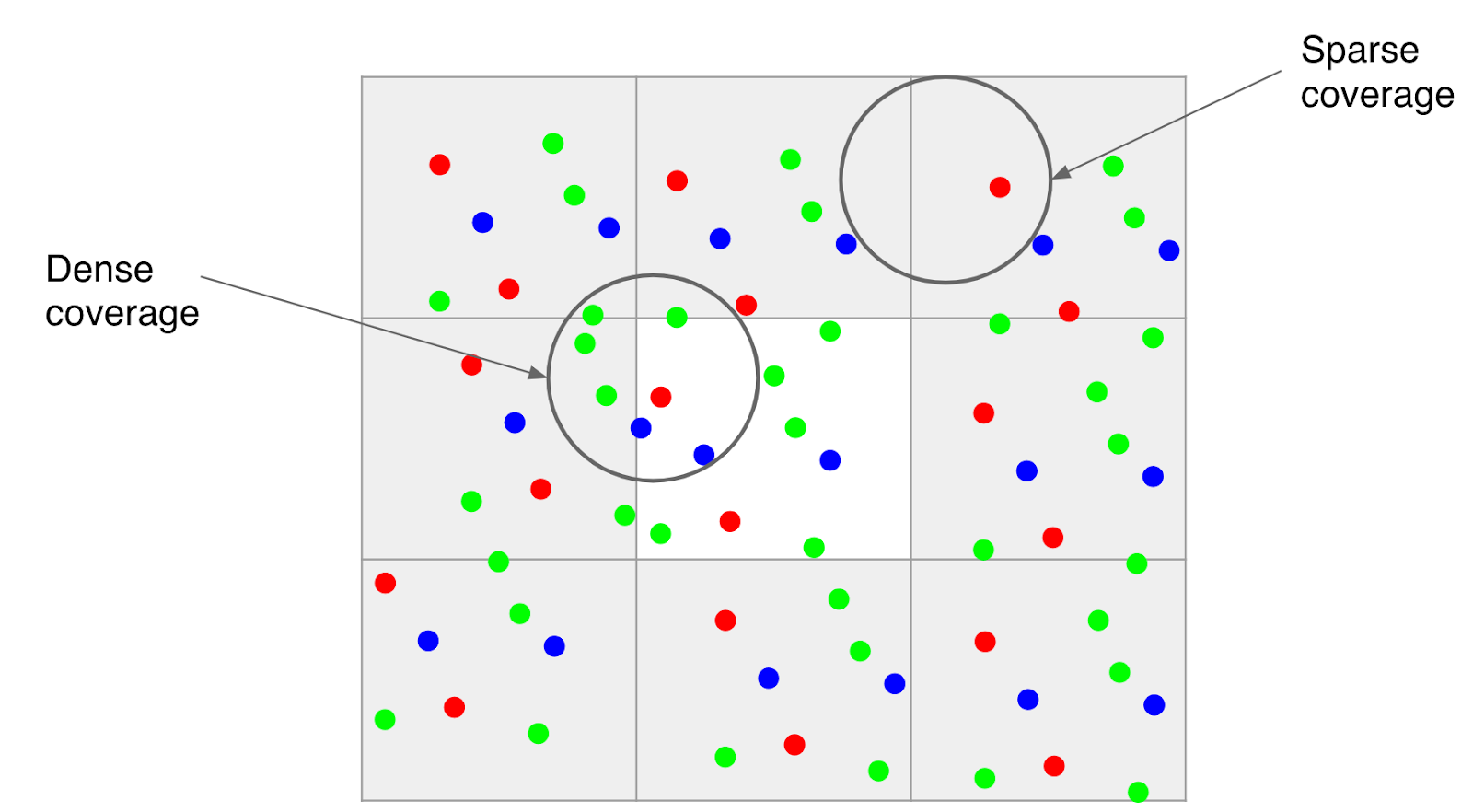
Here’s how we’ve addressed some of these challenges:
- To effectively merge frames in a burst, and to produce a red, green, and blue value for every pixel without the need for demosaicing, we developed a method of integrating information across the frames that takes into account the edges of the image, and adapts accordingly. Specifically, we analyze the input frames and adjust how we combine them together, trading off increase in detail and resolution vs. noise suppression and smoothing. We accomplish this by merging pixels along the direction of apparent edges, rather than across them. The net effect is that our multi-frame method provides the best practical balance between noise reduction and enhancement of details.

Left: Merged image with sub-optimal tradeoff of noise reduction and enhanced resolution. Right: The same merged image with a better tradeoff. - To make the algorithm handle scenes with complex local motion (people, cars, water or tree leaves moving) reliably, we developed a robustness model that detects and mitigates alignment errors. We select one frame as a “reference image”, and merge information from other frames into it only if we’re sure that we have found the correct corresponding feature. In this way, we can avoid artifacts like “ghosting” or motion blur, and wrongly merged parts of the image.

A fast moving bus in a burst of images. Left: Merge without robustness model. Right: Merge with robustness model.


The Portrait mode last year, and the HDR+ pipeline before it, showed how good mobile photography can be. This year, we set out to do the same for zoom. That’s another step in advancing the state of the art in computational photography, while shrinking the quality gap between mobile photography and DSLRs. Here is an album containing full FOV images, followed by Super Res Zoom images. Note that the Super Res Zoom images in this album are not cropped — they are captured directly on-device using pinch-zoom.
 |
| Left: Crop of 7x zoomed image on Pixel 2. Right: Same crop from Super Res Zoom on Pixel 3. |
An illustrative animation of Super Res Zoom. When the user takes a zoomed photo, the Pixel 3 takes advantage of the user’s natural hand motion and captures a burst of images at subtly different positions. These are then merged together to add detail to the final image.
AcknowledgementsSuper Res Zoom is the result of a collaboration across several teams at Google. The project would not have been possible without the joint efforts of teams managed by Peyman Milanfar, Marc Levoy, and Bill Freeman. The authors would like to thank Marc Levoy and Isaac Reynolds in particular for their assistance in the writing of this blog.
The authors wish to especially acknowledge the following key contributors to the Super Res Zoom project: Ignacio Garcia-Dorado, Haomiao Jiang, Manfred Ernst, Michael Krainin, Daniel Vlasic, Jiawen Chen, Pascal Getreuer, and Chia-Kai Liang. The project also benefited greatly from contributions and feedback by Ce Liu, Damien Kelly, and Dillon Sharlet.
How to get the most out of Super Res Zoom?
Here are some tips on getting the best of Super Res Zoom on a Pixel 3 phone:
- Pinch and zoom, or use the + button to increase zoom by discrete steps.
- Double-tap the preview to quickly toggle between zoomed in and zoomed out.
- Super Res works well at all zoom factors, though for performance reasons, it activates only above 1.2x. That’s about half way between no zoom and the first “click” in the zoom UI.
- There are fundamental limits to the optical resolution of a wide-angle camera. So to get the most out of (any) zoom, keep the magnification factor modest.
- Avoid fast moving objects. Super Res zoom will capture them correctly, but you will not likely get increased resolution.
* It’s worth noting that the situation is similar in some ways to how we see — in human (and other mammalian) eyes, different eye cone cells are sensitive to some specific colors, with the brain filling in the details to reconstruct the full image.↩


















{kind=link}
{kind=link}
{kind=link}
{kind=link}