Speech-to-speech translation (S2ST) is a type of machine translation that converts spoken language from one language to another. This technology has the potential to break down language barriers and facilitate communication between people from different cultures and backgrounds.
Previously, we introduced Translatotron 1 and Translatotron 2, the first ever models that were able to directly translate speech between two languages. However they were trained in supervised settings with parallel speech data. The scarcity of parallel speech data is a major challenge in this field, so much that most public datasets are semi- or fully-synthesized from text. This adds additional hurdles to learning translation and reconstruction of speech attributes that are not represented in the text and are thus not reflected in the synthesized training data.
Here we present Translatotron 3, a novel unsupervised speech-to-speech translation architecture. In Translatotron 3, we show that it is possible to learn a speech-to-speech translation task from monolingual data alone. This method opens the door not only to translation between more language pairs but also towards translation of the non-textual speech attributes such as pauses, speaking rates, and speaker identity. Our method does not include any direct supervision to target languages and therefore we believe it is the right direction for paralinguistic characteristics (e.g., such as tone, emotion) of the source speech to be preserved across translation. To enable speech-to-speech translation, we use back-translation, which is a technique from unsupervised machine translation (UMT) where a synthetic translation of the source language is used to translate texts without bilingual text datasets. Experimental results in speech-to-speech translation tasks between Spanish and English show that Translatotron 3 outperforms a baseline cascade system.
Translatotron 3
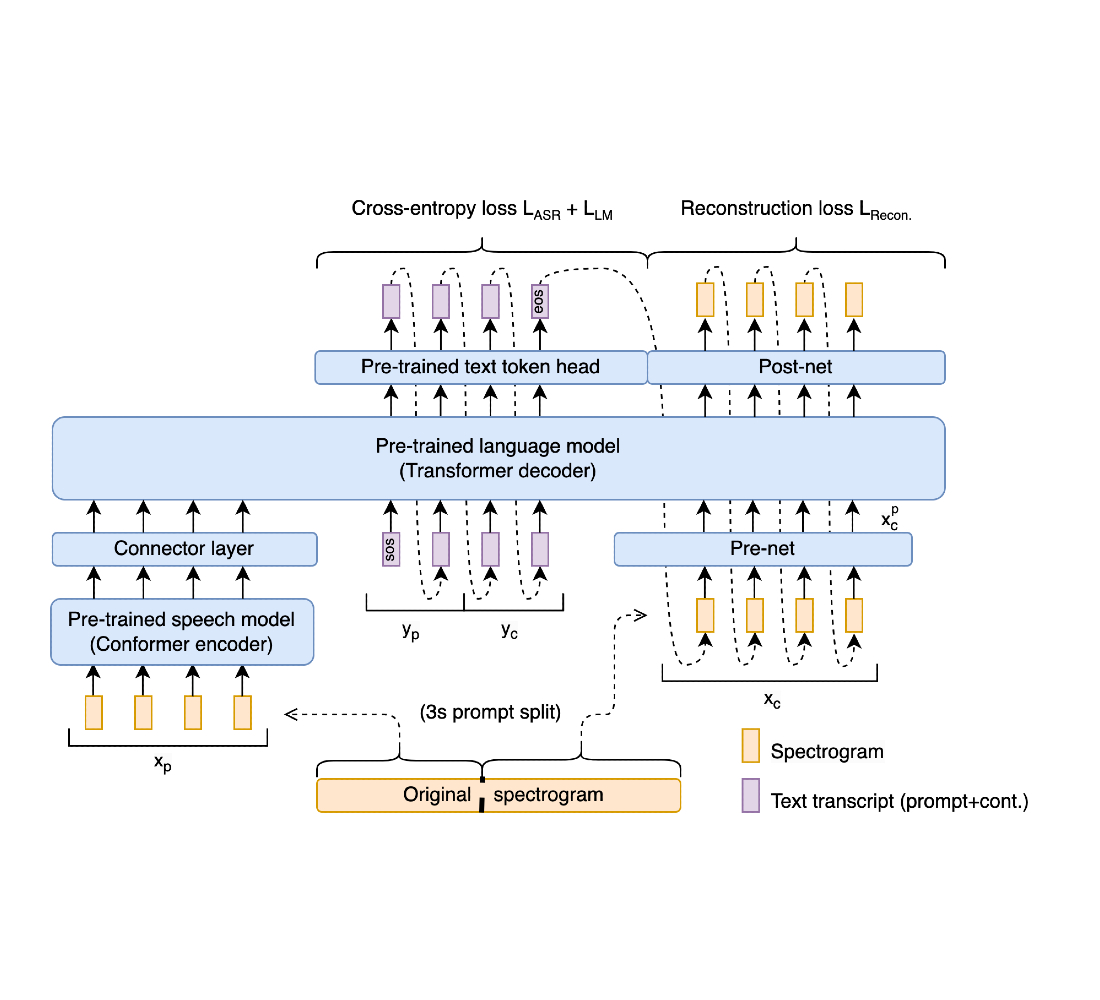
Translatotron 3 addresses the problem of unsupervised S2ST, which can eliminate the requirement for bilingual speech datasets. To do this, Translatotron 3’s design incorporates three key aspects:
- Pre-training the entire model as a masked autoencoder with SpecAugment, a simple data augmentation method for speech recognition that operates on the logarithmic mel spectogram of the input audio (instead of the raw audio itself) and is shown to effectively improve the generalization capabilities of the encoder.
- Unsupervised embedding mapping based on multilingual unsupervised embeddings (MUSE), which is trained on unpaired languages but allows the model to learn an embedding space that is shared between the source and target languages.
- A reconstruction loss based on back-translation, to train an encoder-decoder direct S2ST model in a fully unsupervised manner.
The model is trained using a combination of the unsupervised MUSE embedding loss, reconstruction loss, and S2S back-translation loss. During inference, the shared encoder is utilized to encode the input into a multilingual embedding space, which is subsequently decoded by the target language decoder.
Architecture
Translatotron 3 employs a shared encoder to encode both the source and target languages. The decoder is composed of a linguistic decoder, an acoustic synthesizer (responsible for acoustic generation of the translation speech), and a singular attention module, like Translatotron 2. However, for Translatotron 3 there are two decoders, one for the source language and another for the target language. During training, we use monolingual speech-text datasets (i.e., these data are made up of speech-text pairs; they are not translations).
Encoder
The encoder has the same architecture as the speech encoder in the Translatotron 2. The output of the encoder is split into two parts: the first part incorporates semantic information whereas the second part incorporates acoustic information. By using the MUSE loss, the first half of the output is trained to be the MUSE embeddings of the text of the input speech spectrogram. The latter half is updated without the MUSE loss. It is important to note that the same encoder is shared between source and target languages. Furthermore, the MUSE embedding is multilingual in nature. As a result, the encoder is able to learn a multilingual embedding space across source and target languages. This allows a more efficient and effective encoding of the input, as the encoder is able to encode speech from both languages into a common embedding space, rather than maintaining a separate embedding space for each language.
Decoder
Like Translatotron 2, the decoder is composed of three distinct components, namely the linguistic decoder, the acoustic synthesizer, and the attention module. To effectively handle the different properties of the source and target languages, however, Translatotron 3 has two separate decoders, for the source and target languages.
Two part training
The training methodology consists of two parts: (1) auto-encoding with reconstruction and (2) a back-translation term. In the first part, the network is trained to auto-encode the input to a multilingual embedding space using the MUSE loss and the reconstruction loss. This phase aims to ensure that the network generates meaningful multilingual representations. In the second part, the network is further trained to translate the input spectrogram by utilizing the back-translation loss. To mitigate the issue of catastrophic forgetting and enforcing the latent space to be multilingual, the MUSE loss and the reconstruction loss are also applied in this second part of training. To ensure that the encoder learns meaningful properties of the input, rather than simply reconstructing the input, we apply SpecAugment to encoder input at both phases. It has been shown to effectively improve the generalization capabilities of the encoder by augmenting the input data.
Training objective
During the back-translation training phase (illustrated in the section below), the network is trained to translate the input spectrogram to the target language and then back to the source language. The goal of back-translation is to enforce the latent space to be multilingual. To achieve this, the following losses are applied:
- MUSE loss: The MUSE loss measures the similarity between the multilingual embedding of the input spectrogram and the multilingual embedding of the back-translated spectrogram.
- Reconstruction loss: The reconstruction loss measures the similarity between the input spectrogram and the back-translated spectrogram.
In addition to these losses, SpecAugment is applied to the encoder input at both phases. Before the back-translation training phase, the network is trained to auto-encode the input to a multilingual embedding space using the MUSE loss and reconstruction loss.
MUSE loss
To ensure that the encoder generates multilingual representations that are meaningful for both decoders, we employ a MUSE loss during training. The MUSE loss forces the encoder to generate such a representation by using pre-trained MUSE embeddings. During the training process, given an input text transcript, we extract the corresponding MUSE embeddings from the embeddings of the input language. The error between MUSE embeddings and the output vectors of the encoder is then minimized. Note that the encoder is indifferent to the language of the input during inference due to the multilingual nature of the embeddings.
 |
| The training and inference in Translatotron 3. Training includes the reconstruction loss via the auto-encoding path and employs the reconstruction loss via back-translation. |
Audio samples
Following are examples of direct speech-to-speech translation from Translatotron 3:
Spanish-to-English (on Conversational dataset)
| Input (Spanish) | |
| TTS-synthesized reference (English) | |
| Translatotron 3 (English) |
Spanish-to-English (on CommonVoice11 Synthesized dataset)
| Input (Spanish) | |
| TTS-synthesized reference (English) | |
| Translatotron 3 (English) |
Spanish-to-English (on CommonVoice11 dataset)
| Input (Spanish) | |
| TTS reference (English) | |
| Translatotron 3 (English) |
Performance
To empirically evaluate the performance of the proposed approach, we conducted experiments on English and Spanish using various datasets, including the Common Voice 11 dataset, as well as two synthesized datasets derived from the Conversational and Common Voice 11 datasets.
The translation quality was measured by BLEU (higher is better) on ASR (automatic speech recognition) transcriptions from the translated speech, compared to the corresponding reference translation text. Whereas, the speech quality is measured by the MOS score (higher is better). Furthermore, the speaker similarity is measured by the average cosine similarity (higher is better).
Because Translatotron 3 is an unsupervised method, as a baseline we used a cascaded S2ST system that is combined from ASR, unsupervised machine translation (UMT), and TTS (text-to-speech). Specifically, we employ UMT that uses the nearest neighbor in the embedding space in order to create the translation.
Translatotron 3 outperforms the baseline by large margins in every aspect we measured: translation quality, speaker similarity, and speech quality. It particularly excelled on the conversational corpus. Moreover, Translatotron 3 achieves speech naturalness similar to that of the ground truth audio samples (measured by MOS, higher is better).
 |
| Translation quality (measured by BLEU, where higher is better) evaluated on three Spanish-English corpora. |
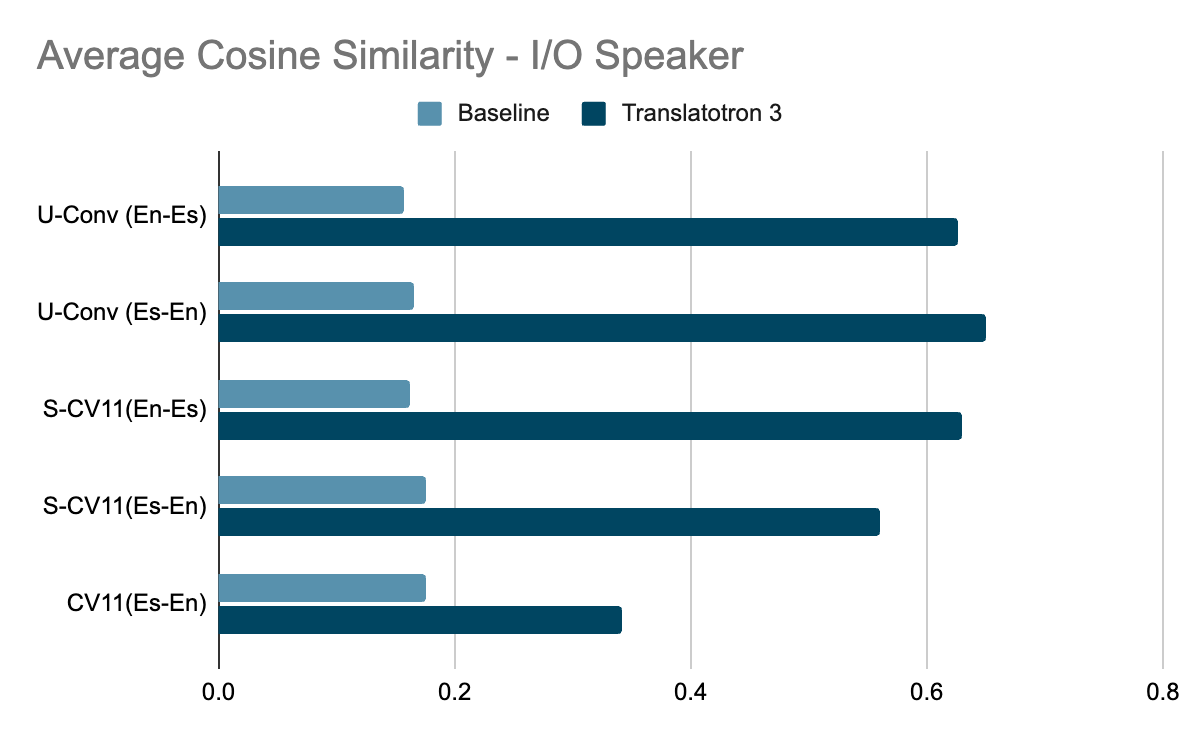 |
| Speech similarity (measured by average cosine similarity between input speaker and output speaker, where higher is better) evaluated on three Spanish-English corpora. |
 |
| Mean-opinion-score (measured by average MOS metric, where higher is better) evaluated on three Spanish-English corpora. |
Future work
As future work, we would like to extend the work to more languages and investigate whether zero-shot S2ST can be applied with the back-translation technique. We would also like to examine the use of back-translation with different types of speech data, such as noisy speech and low-resource languages.
Acknowledgments
The direct contributors to this work include Eliya Nachmani, Alon Levkovitch, Yifan Ding, Chulayutsh Asawaroengchai, Heiga Zhen, and Michelle Tadmor Ramanovich. We also thank Yu Zhang, Yuma Koizumi, Soroosh Mariooryad, RJ Skerry-Ryan, Neil Zeghidour, Christian Frank, Marco Tagliasacchi, Nadav Bar, Benny Schlesinger and Yonghui Wu.