
An astounding number of videos are available on the Web, covering a variety of content from everyday moments people share to historical moments to scientific observations, each of which contains a unique record of the world. The right tools could help researchers analyze these videos, transforming how we understand the world around us.
Videos offer dynamic visual content far more rich than static images, capturing movement, changes, and dynamic relationships between entities. Analyzing this complexity, along with the immense diversity of publicly available video data, demands models that go beyond traditional image understanding. Consequently, many of the approaches that best perform on video understanding still rely on specialized models tailor-made for particular tasks. Recently, there has been exciting progress in this area using video foundation models (ViFMs), such as VideoCLIP, InternVideo, VideoCoCa, and UMT). However, building a ViFM that handles the sheer diversity of video data remains a challenge.
With the goal of building a single model for general-purpose video understanding, we introduced “VideoPrism: A Foundational Visual Encoder for Video Understanding”. VideoPrism is a ViFM designed to handle a wide spectrum of video understanding tasks, including classification, localization, retrieval, captioning, and question answering (QA). We propose innovations in both the pre-training data as well as the modeling strategy. We pre-train VideoPrism on a massive and diverse dataset: 36 million high-quality video-text pairs and 582 million video clips with noisy or machine-generated parallel text. Our pre-training approach is designed for this hybrid data, to learn both from video-text pairs and the videos themselves. VideoPrism is incredibly easy to adapt to new video understanding challenges, and achieves state-of-the-art performance using a single frozen model.
| VideoPrism is a general-purpose video encoder that enables state-of-the-art results over a wide spectrum of video understanding tasks, including classification, localization, retrieval, captioning, and question answering, by producing video representations from a single frozen model. |
Pre-training data
A powerful ViFM needs a very large collection of videos on which to train — similar to other foundation models (FMs), such as those for large language models (LLMs). Ideally, we would want the pre-training data to be a representative sample of all the videos in the world. While naturally most of these videos do not have perfect captions or descriptions, even imperfect text can provide useful information about the semantic content of the video.
To give our model the best possible starting point, we put together a massive pre-training corpus consisting of several public and private datasets, including YT-Temporal-180M, InternVid, VideoCC, WTS-70M, etc. This includes 36 million carefully selected videos with high-quality captions, along with an additional 582 million clips with varying levels of noisy text (like auto-generated transcripts). To our knowledge, this is the largest and most diverse video training corpus of its kind.
 |
| Statistics on the video-text pre-training data. The large variations of the CLIP similarity scores (the higher, the better) demonstrate the diverse caption quality of our pre-training data, which is a byproduct of the various ways used to harvest the text. |
Two-stage training
The VideoPrism model architecture stems from the standard vision transformer (ViT) with a factorized design that sequentially encodes spatial and temporal information following ViViT. Our training approach leverages both the high-quality video-text data and the video data with noisy text mentioned above. To start, we use contrastive learning (an approach that minimizes the distance between positive video-text pairs while maximizing the distance between negative video-text pairs) to teach our model to match videos with their own text descriptions, including imperfect ones. This builds a foundation for matching semantic language content to visual content.
After video-text contrastive training, we leverage the collection of videos without text descriptions. Here, we build on the masked video modeling framework to predict masked patches in a video, with a few improvements. We train the model to predict both the video-level global embedding and token-wise embeddings from the first-stage model to effectively leverage the knowledge acquired in that stage. We then randomly shuffle the predicted tokens to prevent the model from learning shortcuts.
What is unique about VideoPrism’s setup is that we use two complementary pre-training signals: text descriptions and the visual content within a video. Text descriptions often focus on what things look like, while the video content provides information about movement and visual dynamics. This enables VideoPrism to excel in tasks that demand an understanding of both appearance and motion.
Results
We conducted extensive evaluation on VideoPrism across four broad categories of video understanding tasks, including video classification and localization, video-text retrieval, video captioning, question answering, and scientific video understanding. VideoPrism achieves state-of-the-art performance on 30 out of 33 video understanding benchmarks — all with minimal adaptation of a single, frozen model.
 |
| VideoPrism compared to the previous best-performing FMs. |
Classification and localization
We evaluate VideoPrism on an existing large-scale video understanding benchmark (VideoGLUE) covering classification and localization tasks. We found that (1) VideoPrism outperforms all of the other state-of-the-art FMs, and (2) no other single model consistently came in second place. This tells us that VideoPrism has learned to effectively pack a variety of video signals into one encoder — from semantics at different granularities to appearance and motion cues — and it works well across a variety of video sources.
 |
| VideoPrism outperforms state-of-the-art approaches (including CLIP, VATT, InternVideo, and UMT) on the video understanding benchmark. In this plot, we show the absolute score differences compared with the previous best model to highlight the relative improvements of VideoPrism. On Charades, ActivityNet, AVA, and AVA-K, we use mean average precision (mAP) as the evaluation metric. On the other datasets, we report top-1 accuracy. |
Combining with LLMs
We further explore combining VideoPrism with LLMs to unlock its ability to handle various video-language tasks. In particular, when paired with a text encoder (following LiT) or a language decoder (such as PaLM-2), VideoPrism can be utilized for video-text retrieval, video captioning, and video QA tasks. We compare the combined models on a broad and challenging set of vision-language benchmarks. VideoPrism sets the new state of the art on most benchmarks. From the visual results, we find that VideoPrism is capable of understanding complex motions and appearances in videos (e.g., the model can recognize the different colors of spinning objects on the window in the visual examples below). These results demonstrate that VideoPrism is strongly compatible with language models.
 |
| VideoPrism achieves competitive results compared with state-of-the-art approaches (including VideoCoCa, UMT and Flamingo) on multiple video-text retrieval (top) and video captioning and video QA (bottom) benchmarks. We also show the absolute score differences compared with the previous best model to highlight the relative improvements of VideoPrism. We report the Recall@1 on MASRVTT, VATEX, and ActivityNet, CIDEr score on MSRVTT-Cap, VATEX-Cap, and YouCook2, top-1 accuracy on MSRVTT-QA and MSVD-QA, and WUPS index on NExT-QA. |
| We show qualitative results using VideoPrism with a text encoder for video-text retrieval (first row) and adapted to a language decoder for video QA (second and third row). For video-text retrieval examples, the blue bars indicate the embedding similarities between the videos and the text queries. |
Scientific applications
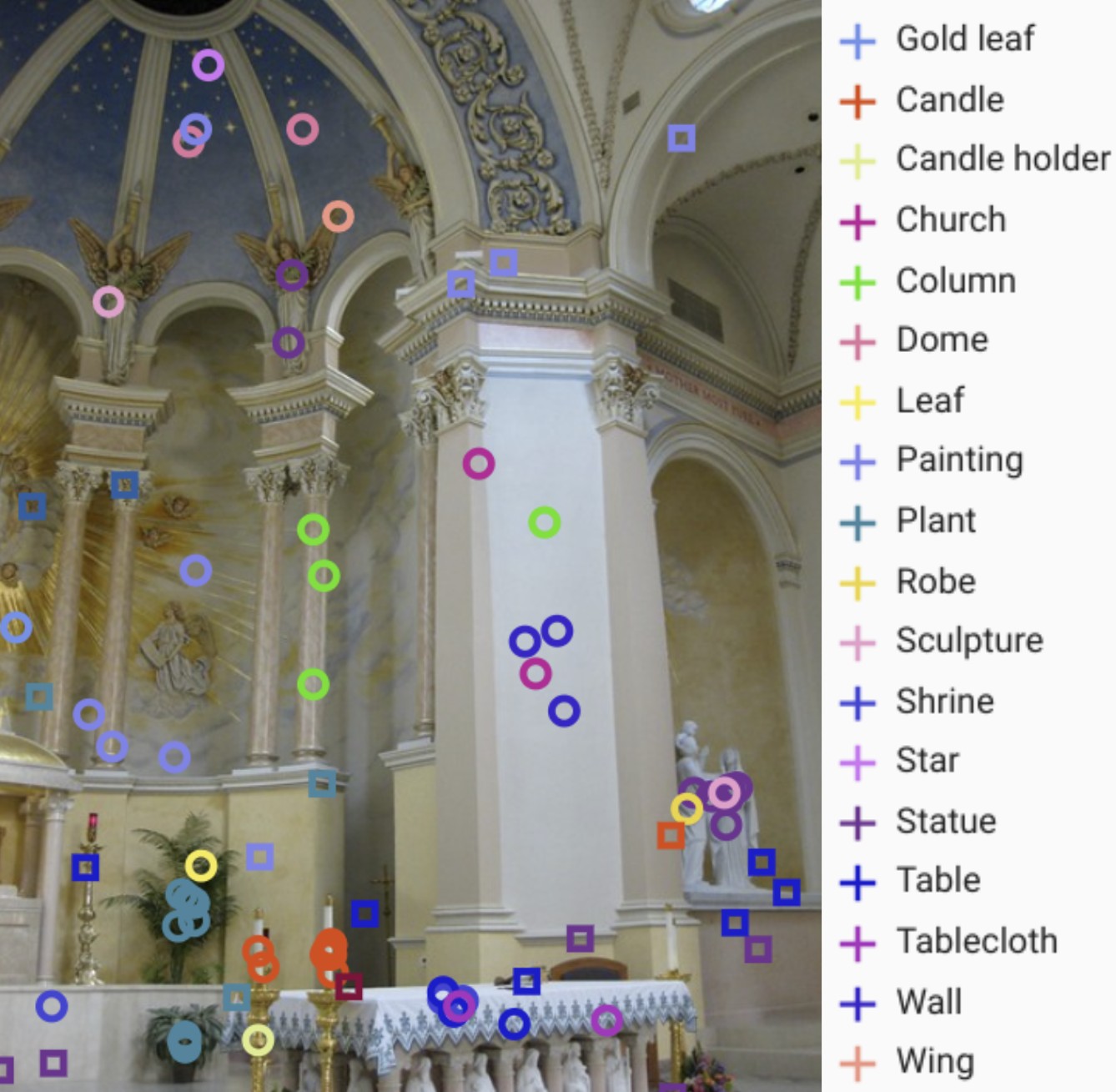
Finally, we tested VideoPrism on datasets used by scientists across domains, including fields such as ethology, behavioral neuroscience, and ecology. These datasets typically require domain expertise to annotate, for which we leverage existing scientific datasets open-sourced by the community including Fly vs. Fly, CalMS21, ChimpACT, and KABR. VideoPrism not only performs exceptionally well, but actually surpasses models designed specifically for those tasks. This suggests tools like VideoPrism have the potential to transform how scientists analyze video data across different fields.
 |
| VideoPrism outperforms the domain experts on various scientific benchmarks. We show the absolute score differences to highlight the relative improvements of VideoPrism. We report mean average precision (mAP) for all datasets, except for KABR which uses class-averaged top-1 accuracy. |
Conclusion
With VideoPrism, we introduce a powerful and versatile video encoder that sets a new standard for general-purpose video understanding. Our emphasis on both building a massive and varied pre-training dataset and innovative modeling techniques has been validated through our extensive evaluations. Not only does VideoPrism consistently outperform strong baselines, but its unique ability to generalize positions it well for tackling an array of real-world applications. Because of its potential broad use, we are committed to continuing further responsible research in this space, guided by our AI Principles. We hope VideoPrism paves the way for future breakthroughs at the intersection of AI and video analysis, helping to realize the potential of ViFMs across domains such as scientific discovery, education, and healthcare.
Acknowledgements
This blog post is made on behalf of all the VideoPrism authors: Long Zhao, Nitesh B. Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J. Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, Rachel Hornung, Florian Schroff, Ming-Hsuan Yang, David A. Ross, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko, Ting Liu, and Boqing Gong. We sincerely thank David Hendon for their product management efforts, and Alex Siegman, Ramya Ganeshan, and Victor Gomes for their program and resource management efforts. We also thank Hassan Akbari, Sherry Ben, Yoni Ben-Meshulam, Chun-Te Chu, Sam Clearwater, Yin Cui, Ilya Figotin, Anja Hauth, Sergey Ioffe, Xuhui Jia, Yeqing Li, Lu Jiang, Zu Kim, Dan Kondratyuk, Bill Mark, Arsha Nagrani, Caroline Pantofaru, Sushant Prakash, Cordelia Schmid, Bryan Seybold, Mojtaba Seyedhosseini, Amanda Sadler, Rif A. Saurous, Rachel Stigler, Paul Voigtlaender, Pingmei Xu, Chaochao Yan, Xuan Yang, and Yukun Zhu for the discussions, support, and feedback that greatly contributed to this work. We are grateful to Jay Yagnik, Rahul Sukthankar, and Tomas Izo for their enthusiastic support for this project. Lastly, we thank Tom Small, Jennifer J. Sun, Hao Zhou, Nitesh B. Gundavarapu, Luke Friedman, and Mikhail Sirotenko for the tremendous help with making this blog post.









































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}