 Learn more about managing your stress with Fitbit and Google Pixel Watch.
Learn more about managing your stress with Fitbit and Google Pixel Watch.
How Fitbit can help you measure stress — and use it to your advantage
Learn more about managing your stress with Fitbit and Google Pixel Watch.
Learn more about managing your stress with Fitbit and Google Pixel Watch.
 On April 8, a total solar eclipse will cross parts of North America. Here’s what you need to know to capture it with your Pixel phone.
On April 8, a total solar eclipse will cross parts of North America. Here’s what you need to know to capture it with your Pixel phone.
 Learn how to get started with the Pixel 8 Pro’s camera’s Pro Controls.
Learn how to get started with the Pixel 8 Pro’s camera’s Pro Controls.
 The March Feature Drop brings productivity and health features to the Pixel portfolio, including new features for first-gen Pixel Watch.
The March Feature Drop brings productivity and health features to the Pixel portfolio, including new features for first-gen Pixel Watch.
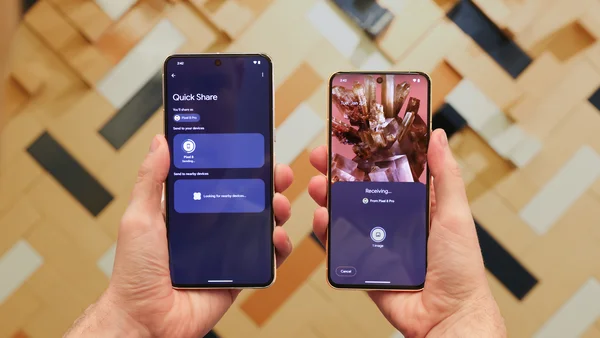 Want to send photos, links or text to a friend or family member? Quick Share lets you send content between nearby devices in just a few taps.
Want to send photos, links or text to a friend or family member? Quick Share lets you send content between nearby devices in just a few taps.
Helping Pixel owners upgrade to the easier, safer way to sign in
Your phone contains a lot of your personal information, from financial data to photos. Pixel phones are designed to help protect you and your data, and make security and privacy as easy as possible. This is why the Pixel team has been especially excited about passkeys—the easier, safer alternative to passwords.
Passkeys are safer because they’re unique to each account, and are more resistant against online attacks such as phishing. They’re easier to use because there’s nothing for you to remember: when it’s time to sign in, using a passkey is as simple as unlocking your device with your face or fingerprint, or your PIN/pattern/password.
Google is working to accelerate passkey adoption. We’ve launched support for passkeys on Google platforms such as Android and Chrome, and recently we announced that we’re making passkeys a default option across personal Google Accounts. We’re also working with our partners across the industry to make passkeys available on more websites and apps.
Recently, we took things a step further. As part of last December’s Pixel Feature Drop, we introduced a new feature to Google Password Manager: passkey upgrades. With this new feature, Google Password Manager will let you discover which of your accounts support passkeys, and help you upgrade with just a few taps.
This new passkey upgrade experience is now available on Pixel phones (starting from Pixel 5a) as well as Pixel Tablet. Google Password manager will incorporate these updates for other platforms in the future.


