Posted by Bryan Wang, Student Researcher, and Yang Li, Research Scientist, Google Research
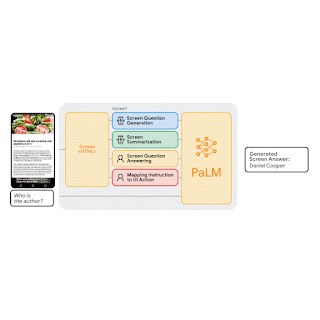
Intelligent assistants on mobile devices have significantly advanced language-based interactions for performing simple daily tasks, such as setting a timer or turning on a flashlight. Despite the progress, these assistants still face limitations in supporting conversational interactions in mobile user interfaces (UIs), where many user tasks are performed. For example, they cannot answer a user's question about specific information displayed on a screen. An agent would need to have a computational understanding of graphical user interfaces (GUIs) to achieve such capabilities.
Prior research has investigated several important technical building blocks to enable conversational interaction with mobile UIs, including summarizing a mobile screen for users to quickly understand its purpose, mapping language instructions to UI actions and modeling GUIs so that they are more amenable for language-based interaction. However, each of these only addresses a limited aspect of conversational interaction and requires considerable effort in curating large-scale datasets and training dedicated models. Furthermore, there is a broad spectrum of conversational interactions that can occur on mobile UIs. Therefore, it is imperative to develop a lightweight and generalizable approach to realize conversational interaction.
In “Enabling Conversational Interaction with Mobile UI using Large Language Models”, presented at CHI 2023, we investigate the viability of utilizing large language models (LLMs) to enable diverse language-based interactions with mobile UIs. Recent pre-trained LLMs, such as PaLM, have demonstrated abilities to adapt themselves to various downstream language tasks when being prompted with a handful of examples of the target task. We present a set of prompting techniques that enable interaction designers and developers to quickly prototype and test novel language interactions with users, which saves time and resources before investing in dedicated datasets and models. Since LLMs only take text tokens as input, we contribute a novel algorithm that generates the text representation of mobile UIs. Our results show that this approach achieves competitive performance using only two data examples per task. More broadly, we demonstrate LLMs’ potential to fundamentally transform the future workflow of conversational interaction design.
 |
| Animation showing our work on enabling various conversational interactions with mobile UI using LLMs. |
Prompting LLMs with UIs
LLMs support in-context few-shot learning via prompting — instead of fine-tuning or re-training models for each new task, one can prompt an LLM with a few input and output data exemplars from the target task. For many natural language processing tasks, such as question-answering or translation, few-shot prompting performs competitively with benchmark approaches that train a model specific to each task. However, language models can only take text input, while mobile UIs are multimodal, containing text, image, and structural information in their view hierarchy data (i.e., the structural data containing detailed properties of UI elements) and screenshots. Moreover, directly inputting the view hierarchy data of a mobile screen into LLMs is not feasible as it contains excessive information, such as detailed properties of each UI element, which can exceed the input length limits of LLMs.
To address these challenges, we developed a set of techniques to prompt LLMs with mobile UIs. We contribute an algorithm that generates the text representation of mobile UIs using depth-first search traversal to convert the Android UI's view hierarchy into HTML syntax. We also utilize chain of thought prompting, which involves generating intermediate results and chaining them together to arrive at the final output, to elicit the reasoning ability of the LLM.
 |
| Animation showing the process of few-shot prompting LLMs with mobile UIs. |
Our prompt design starts with a preamble that explains the prompt’s purpose. The preamble is followed by multiple exemplars consisting of the input, a chain of thought (if applicable), and the output for each task. Each exemplar’s input is a mobile screen in the HTML syntax. Following the input, chains of thought can be provided to elicit logical reasoning from LLMs. This step is not shown in the animation above as it is optional. The task output is the desired outcome for the target tasks, e.g., a screen summary or an answer to a user question. Few-shot prompting can be achieved with more than one exemplar included in the prompt. During prediction, we feed the model the prompt with a new input screen appended at the end.
Experiments
We conducted comprehensive experiments with four pivotal modeling tasks: (1) screen question-generation, (2) screen summarization, (3) screen question-answering, and (4) mapping instruction to UI action. Experimental results show that our approach achieves competitive performance using only two data examples per task.
Task 1: Screen question generation
Given a mobile UI screen, the goal of screen question-generation is to synthesize coherent, grammatically correct natural language questions relevant to the UI elements requiring user input.
We found that LLMs can leverage the UI context to generate questions for relevant information. LLMs significantly outperformed the heuristic approach (template-based generation) regarding question quality.
 |
| Example screen questions generated by the LLM. The LLM can utilize screen contexts to generate grammatically correct questions relevant to each input field on the mobile UI, while the template approach falls short. |
We also revealed LLMs' ability to combine relevant input fields into a single question for efficient communication. For example, the filters asking for the minimum and maximum price were combined into a single question: “What’s the price range?
 |
| We observed that the LLM could use its prior knowledge to combine multiple related input fields to ask a single question. |
In an evaluation, we solicited human ratings on whether the questions were grammatically correct (Grammar) and relevant to the input fields for which they were generated (Relevance). In addition to the human-labeled language quality, we automatically examined how well LLMs can cover all the elements that need to generate questions (Coverage F1). We found that the questions generated by LLM had almost perfect grammar (4.98/5) and were highly relevant to the input fields displayed on the screen (92.8%). Additionally, LLM performed well in terms of covering the input fields comprehensively (95.8%).
|
|
|
|
Template
|
|
|
2-shot LLM
|
|
|
| Grammar
|
|
|
3.6 (out of 5)
|
|
|
4.98 (out of 5)
|
|
|
| Relevance
|
|
|
84.1%
|
|
|
92.8%
|
|
|
| Coverage F1
|
|
|
100%
|
|
|
95.8%
|
|
|
Task 2: Screen summarization
Screen summarization is the automatic generation of descriptive language overviews that cover essential functionalities of mobile screens. The task helps users quickly understand the purpose of a mobile UI, which is particularly useful when the UI is not visually accessible.
Our results showed that LLMs can effectively summarize the essential functionalities of a mobile UI. They can generate more accurate summaries than the Screen2Words benchmark model that we previously introduced using UI-specific text, as highlighted in the colored text and boxes below.
 |
| Example summary generated by 2-shot LLM. We found the LLM is able to use specific text on the screen to compose more accurate summaries. |
Interestingly, we observed LLMs using their prior knowledge to deduce information not presented in the UI when creating summaries. In the example below, the LLM inferred the subway stations belong to the London Tube system, while the input UI does not contain this information.
 |
| LLM uses its prior knowledge to help summarize the screens. |
Human evaluation rated LLM summaries as more accurate than the benchmark, yet they scored lower on metrics like BLEU. The mismatch between perceived quality and metric scores echoes recent work showing LLMs write better summaries despite automatic metrics not reflecting it.
| Left: Screen summarization performance on automatic metrics. Right: Screen summarization accuracy voted by human evaluators. |
Task 3: Screen question-answering
Given a mobile UI and an open-ended question asking for information regarding the UI, the model should provide the correct answer. We focus on factual questions, which require answers based on information presented on the screen.
 |
| Example results from the screen QA experiment. The LLM significantly outperforms the off-the-shelf QA baseline model. |
We report performance using four metrics: Exact Matches (identical predicted answer to ground truth), Contains GT (answer fully containing ground truth), Sub-String of GT (answer is a sub-string of ground truth), and the Micro-F1 score based on shared words between the predicted answer and ground truth across the entire dataset.
Our results showed that LLMs can correctly answer UI-related questions, such as "what's the headline?". The LLM performed significantly better than baseline QA model DistillBERT, achieving a 66.7% fully correct answer rate. Notably, the 0-shot LLM achieved an exact match score of 30.7%, indicating the model's intrinsic question answering capability.
| Models
|
|
|
Exact Matches
|
|
|
Contains GT
|
|
|
Sub-String of GT
|
|
|
Micro-F1
|
|
|
| 0-shot LLM
|
|
|
30.7%
|
|
|
6.5%
|
|
|
5.6%
|
|
|
31.2%
|
|
|
| 1-shot LLM
|
|
|
65.8%
|
|
|
10.0%
|
|
|
7.8%
|
|
|
62.9%
|
|
|
| 2-shot LLM
|
|
|
66.7%
|
|
|
12.6%
|
|
|
5.2%
|
|
|
64.8%
|
|
|
| DistillBERT
|
|
|
36.0%
|
|
|
8.5%
|
|
|
9.9%
|
|
|
37.2%
|
|
|
Task 4: Mapping instruction to UI action
Given a mobile UI screen and natural language instruction to control the UI, the model needs to predict the ID of the object to perform the instructed action. For example, when instructed with "Open Gmail," the model should correctly identify the Gmail icon on the home screen. This task is useful for controlling mobile apps using language input such as voice access. We introduced this benchmark task previously.
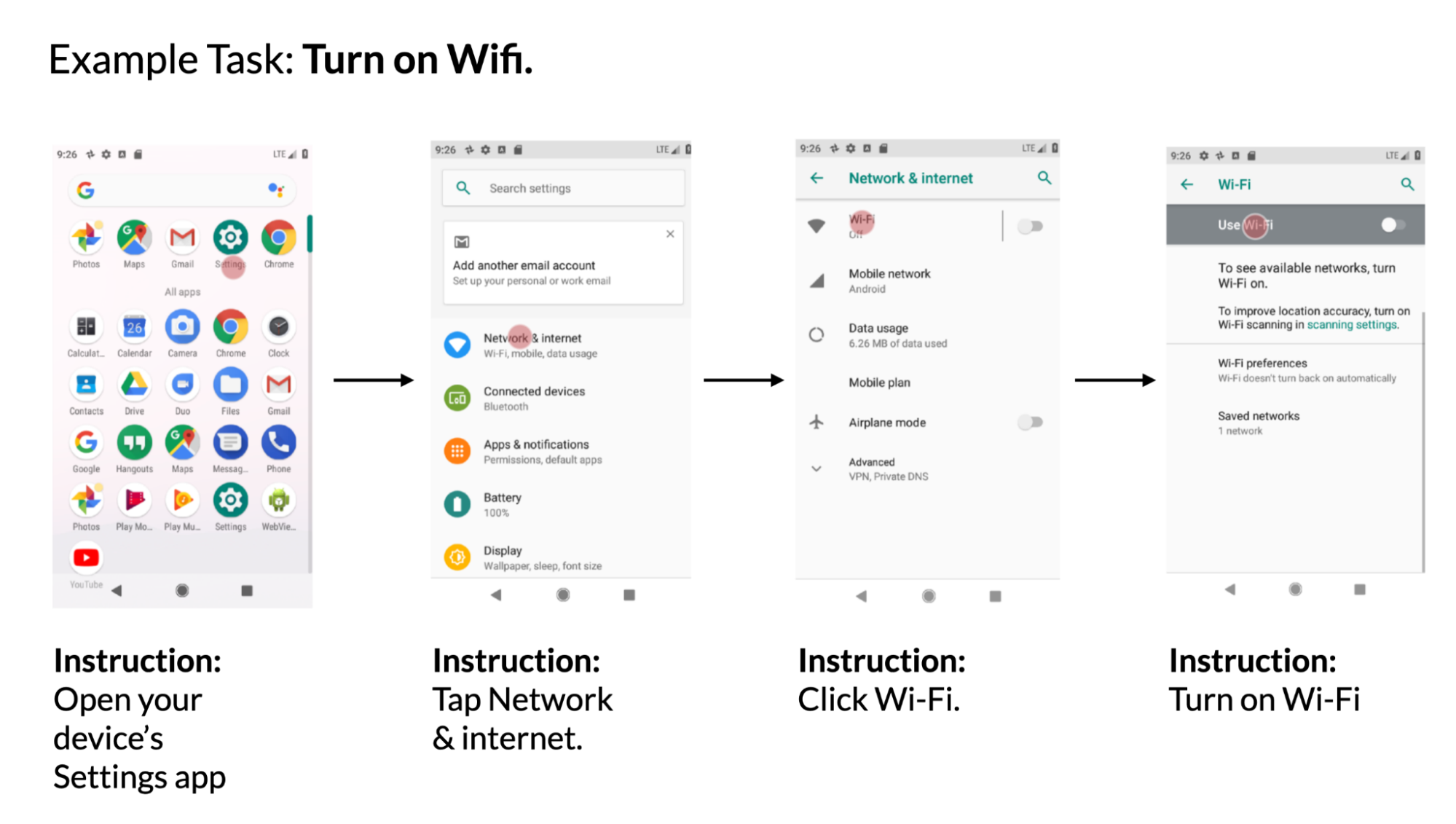 |
| Example using data from the PixelHelp dataset. The dataset contains interaction traces for common UI tasks such as turning on wifi. Each trace contains multiple steps and corresponding instructions. |
We assessed the performance of our approach using the Partial and Complete metrics from the Seq2Act paper. Partial refers to the percentage of correctly predicted individual steps, while Complete measures the portion of accurately predicted entire interaction traces. Although our LLM-based method did not surpass the benchmark trained on massive datasets, it still achieved remarkable performance with just two prompted data examples.
| Models
|
|
|
Partial
|
|
|
Complete
|
|
|
| 0-shot LLM
|
|
|
1.29
|
|
|
0.00
|
|
|
| 1-shot LLM (cross-app)
|
|
|
74.69
|
|
|
31.67
|
|
|
| 2-shot LLM (cross-app)
|
|
|
75.28
|
|
|
34.44
|
|
|
| 1-shot LLM (in-app)
|
|
|
78.35
|
|
|
40.00
|
|
|
| 2-shot LLM (in-app)
|
|
|
80.36
|
|
|
45.00
|
|
|
| Seq2Act
|
|
|
89.21
|
|
|
70.59
|
|
|
Takeaways and conclusion
Our study shows that prototyping novel language interactions on mobile UIs can be as easy as designing a data exemplar. As a result, an interaction designer can rapidly create functioning mock-ups to test new ideas with end users. Moreover, developers and researchers can explore different possibilities of a target task before investing significant efforts into developing new datasets and models.
We investigated the feasibility of prompting LLMs to enable various conversational interactions on mobile UIs. We proposed a suite of prompting techniques for adapting LLMs to mobile UIs. We conducted extensive experiments with the four important modeling tasks to evaluate the effectiveness of our approach. The results showed that compared to traditional machine learning pipelines that consist of expensive data collection and model training, one could rapidly realize novel language-based interactions using LLMs while achieving competitive performance.
Acknowledgements
We thank our paper co-author Gang Li, and appreciate the discussions and feedback from our colleagues Chin-Yi Cheng, Tao Li, Yu Hsiao, Michael Terry and Minsuk Chang. Special thanks to Muqthar Mohammad and Ashwin Kakarla for their invaluable assistance in coordinating data collection. We thank John Guilyard for helping create animations and graphics in the blog.
 Posted by
Posted by 

 Posted by
Posted by 

 Posted by
Posted by 

 Posted by
Posted by 

 Posted by
Posted by 


















 Posted by the Android team
Posted by the Android team