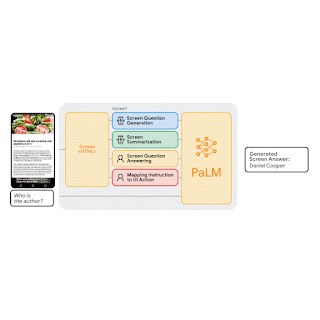
Screen user interfaces (UIs) and infographics, such as charts, diagrams and tables, play important roles in human communication and human-machine interaction as they facilitate rich and interactive user experiences. UIs and infographics share similar design principles and visual language (e.g., icons and layouts), that offer an opportunity to build a single model that can understand, reason, and interact with these interfaces. However, because of their complexity and varied presentation formats, infographics and UIs present a unique modeling challenge.
To that end, we introduce “ScreenAI: A Vision-Language Model for UI and Infographics Understanding”. ScreenAI improves upon the PaLI architecture with the flexible patching strategy from pix2struct. We train ScreenAI on a unique mixture of datasets and tasks, including a novel Screen Annotation task that requires the model to identify UI element information (i.e., type, location and description) on a screen. These text annotations provide large language models (LLMs) with screen descriptions, enabling them to automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale. At only 5B parameters, ScreenAI achieves state-of-the-art results on UI- and infographic-based tasks (WebSRC and MoTIF), and best-in-class performance on Chart QA, DocVQA, and InfographicVQA compared to models of similar size. We are also releasing three new datasets: Screen Annotation to evaluate the layout understanding capability of the model, as well as ScreenQA Short and Complex ScreenQA for a more comprehensive evaluation of its QA capability.
ScreenAI
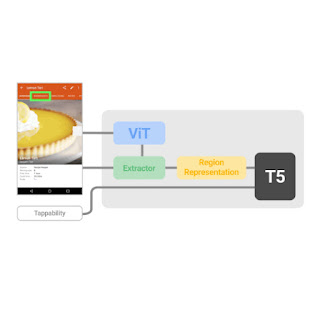
ScreenAI’s architecture is based on PaLI, composed of a multimodal encoder block and an autoregressive decoder. The PaLI encoder uses a vision transformer (ViT) that creates image embeddings and a multimodal encoder that takes the concatenation of the image and text embeddings as input. This flexible architecture allows ScreenAI to solve vision tasks that can be recast as text+image-to-text problems.
On top of the PaLI architecture, we employ a flexible patching strategy introduced in pix2struct. Instead of using a fixed-grid pattern, the grid dimensions are selected such that they preserve the native aspect ratio of the input image. This enables ScreenAI to work well across images of various aspect ratios.
The ScreenAI model is trained in two stages: a pre-training stage followed by a fine-tuning stage. First, self-supervised learning is applied to automatically generate data labels, which are then used to train ViT and the language model. ViT is frozen during the fine-tuning stage, where most data used is manually labeled by human raters.
 |
| ScreenAI model architecture. |
Data generation
To create a pre-training dataset for ScreenAI, we first compile an extensive collection of screenshots from various devices, including desktops, mobile, and tablets. This is achieved by using publicly accessible web pages and following the programmatic exploration approach used for the RICO dataset for mobile apps. We then apply a layout annotator, based on the DETR model, that identifies and labels a wide range of UI elements (e.g., image, pictogram, button, text) and their spatial relationships. Pictograms undergo further analysis using an icon classifier capable of distinguishing 77 different icon types. This detailed classification is essential for interpreting the subtle information conveyed through icons. For icons that are not covered by the classifier, and for infographics and images, we use the PaLI image captioning model to generate descriptive captions that provide contextual information. We also apply an optical character recognition (OCR) engine to extract and annotate textual content on screen. We combine the OCR text with the previous annotations to create a detailed description of each screen.
 |
A mobile app screenshot with generated annotations that include UI elements and their descriptions, e.g., TEXT elements also contain the text content from OCR, IMAGE elements contain image captions, LIST_ITEMs contain all their child elements. |
LLM-based data generation
We enhance the pre-training data's diversity using PaLM 2 to generate input-output pairs in a two-step process. First, screen annotations are generated using the technique outlined above, then we craft a prompt around this schema for the LLM to create synthetic data. This process requires prompt engineering and iterative refinement to find an effective prompt. We assess the generated data's quality through human validation against a quality threshold.
You only speak JSON. Do not write text that isn’t JSON.
You are given the following mobile screenshot, described in words. Can you generate 5 questions regarding the content of the screenshot as well as the corresponding short answers to them?
The answer should be as short as possible, containing only the necessary information. Your answer should be structured as follows:
questions: [
{{question: the question,
answer: the answer
}},
...
]
{THE SCREEN SCHEMA}
| A sample prompt for QA data generation. |
By combining the natural language capabilities of LLMs with a structured schema, we simulate a wide range of user interactions and scenarios to generate synthetic, realistic tasks. In particular, we generate three categories of tasks:
- Question answering: The model is asked to answer questions regarding the content of the screenshots, e.g., “When does the restaurant open?”
- Screen navigation: The model is asked to convert a natural language utterance into an executable action on a screen, e.g., “Click the search button.”
- Screen summarization: The model is asked to summarize the screen content in one or two sentences.
 |
| Block diagram of our workflow for generating data for QA, summarization and navigation tasks using existing ScreenAI models and LLMs. Each task uses a custom prompt to emphasize desired aspects, like questions related to counting, involving reasoning, etc. |
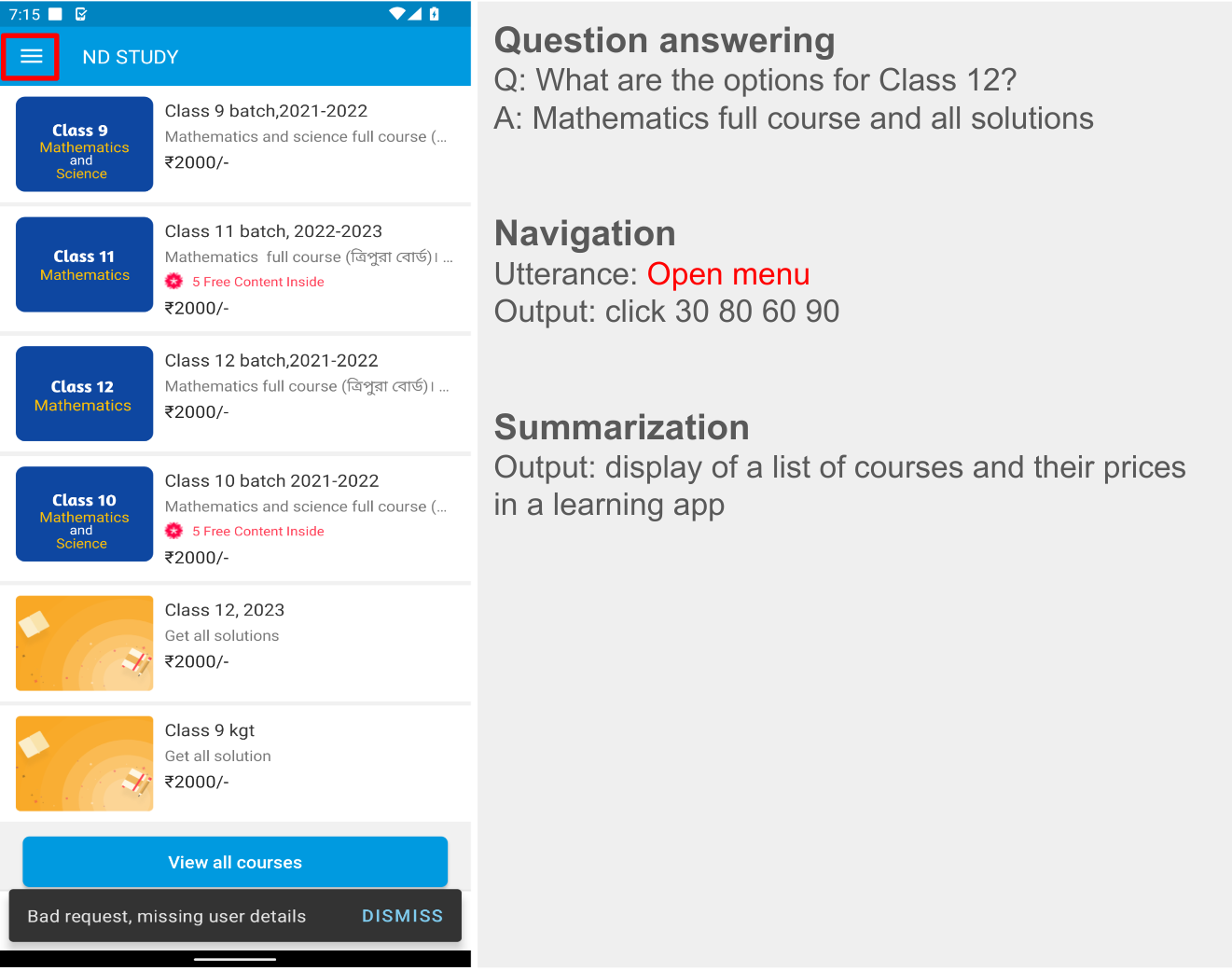 |
| LLM-generated data. Examples for screen QA, navigation and summarization. For navigation, the action bounding box is displayed in red on the screenshot. |
Experiments and results
As previously mentioned, ScreenAI is trained in two stages: pre-training and fine-tuning. Pre-training data labels are obtained using self-supervised learning and fine-tuning data labels comes from human raters.
We fine-tune ScreenAI using public QA, summarization, and navigation datasets and a variety of tasks related to UIs. For QA, we use well established benchmarks in the multimodal and document understanding field, such as ChartQA, DocVQA, Multi page DocVQA, InfographicVQA, OCR VQA, Web SRC and ScreenQA. For navigation, datasets used include Referring Expressions, MoTIF, Mug, and Android in the Wild. Finally, we use Screen2Words for screen summarization and Widget Captioning for describing specific UI elements. Along with the fine-tuning datasets, we evaluate the fine-tuned ScreenAI model using three novel benchmarks:
- Screen Annotation: Enables the evaluation model layout annotations and spatial understanding capabilities.
- ScreenQA Short: A variation of ScreenQA, where its ground truth answers have been shortened to contain only the relevant information that better aligns with other QA tasks.
- Complex ScreenQA: Complements ScreenQA Short with more difficult questions (counting, arithmetic, comparison, and non-answerable questions) and contains screens with various aspect ratios.
The fine-tuned ScreenAI model achieves state-of-the-art results on various UI and infographic-based tasks (WebSRC and MoTIF) and best-in-class performance on Chart QA, DocVQA, and InfographicVQA compared to models of similar size. ScreenAI achieves competitive performance on Screen2Words and OCR-VQA. Additionally, we report results on the new benchmark datasets introduced to serve as a baseline for further research.
 |
| Comparing model performance of ScreenAI with state-of-the-art (SOTA) models of similar size. |
Next, we examine ScreenAI’s scaling capabilities and observe that across all tasks, increasing the model size improves performances and the improvements have not saturated at the largest size.
 |
| Model performance increases with size, and the performance has not saturated even at the largest size of 5B params. |
Conclusion
We introduce the ScreenAI model along with a unified representation that enables us to develop self-supervised learning tasks leveraging data from all these domains. We also illustrate the impact of data generation using LLMs and investigate improving model performance on specific aspects with modifying the training mixture. We apply all of these techniques to build multi-task trained models that perform competitively with state-of-the-art approaches on a number of public benchmarks. However, we also note that our approach still lags behind large models and further research is needed to bridge this gap.
Acknowledgements
This project is the result of joint work with Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor Carbune, Jason Lin, Jindong Chen and Abhanshu Sharma. We thank Fangyu Liu, Xi Chen, Efi Kokiopoulou, Jesse Berent, Gabriel Barcik, Lukas Zilka, Oriana Riva, Gang Li,Yang Li, Radu Soricut, and Tania Bedrax-Weiss for their insightful feedback and discussions, along with Rahul Aralikatte, Hao Cheng and Daniel Kim for their support in data preparation. We also thank Jay Yagnik, Blaise Aguera y Arcas, Ewa Dominowska, David Petrou, and Matt Sharifi for their leadership, vision and support. We are very grateful toTom Small for helping us create the animation in this post.