 Posted by
Posted by 
Android Studio provides you an integrated development environment (IDE) to develop, test, debug, and package Android apps that can reach billions of users across a diverse set of Android devices. Last month we reached a big milestone for the product: 10 years since the Android Studio 1.0 release reached the stable channel. You can hear a bit more about its history in the most recent episode of Android Developers Backstage, or watch some of the team’s favorite moments: 🎉
When we set out to develop Android Studio we started with these three principles:
First, we wanted to build and release a complete IDE, not just a plugin. Before Android Studio, users had to go download a JDK, then download Eclipse, then configure it with an update center to point to Android, install the Eclipse plugin for Android, and then configure that plugin to point to an Android SDK install. Not only did we want everything to work out-of-the-box, but we also wanted to be able to configure and improve everything: from having an integrated dependency management system to offering code inspections that were relevant to Android app developers to having a single place to report bugs.
Second, we wanted to build it on top of an actively maintained, open-sourced, and best-of-breed Java programing language IDE. Not too long before releasing Android Studio, we had all used IntelliJ and felt it was superior from a code editing perspective.
And third, we wanted to not only provide a build system that was better suited for Android app development, but to also enable this build system to work consistently from both from the command line and from inside the IDE. This was important because in the previous tool chain, we found that there were discrepancies in behavior and capability between the in-IDE builds with Eclipse, and CI builds with Ant.
This led to the release of Android Studio, including these highlights:
Here are some nostalgic screenshots from that first version of Android Studio:
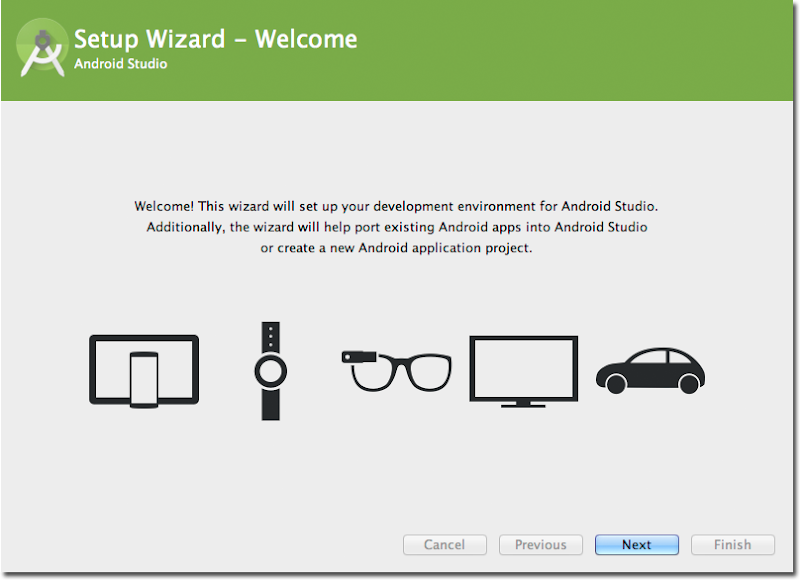
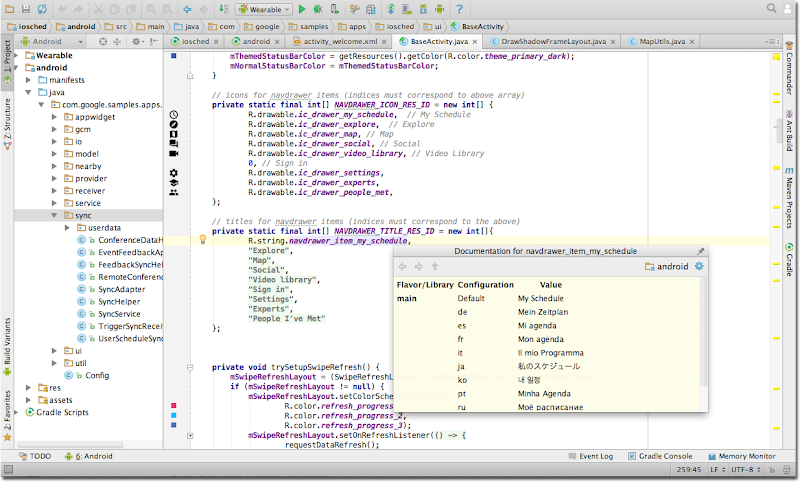
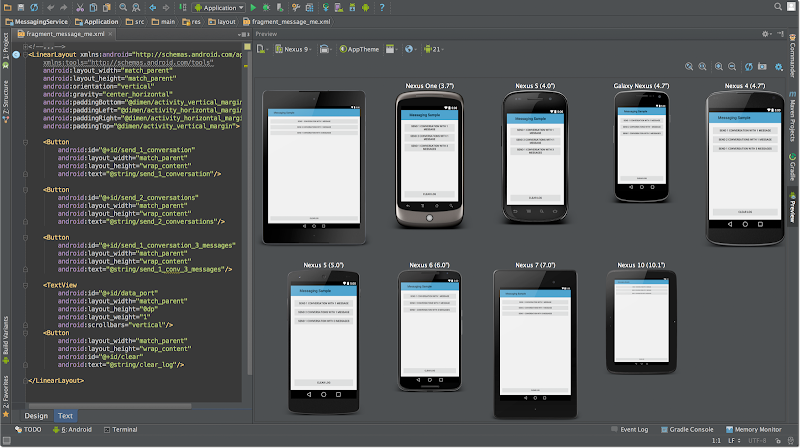
Android Studio has come a long way since those early days, but our mission of empowering Android developers with excellent tools continues to be our focus.
Let’s hear from some team members across Android, JetBrains, and Gradle as they reflect on this milestone and how far the ecosystem has come since then.
Android Studio team
“Inside the Android team, engineers who didn't work on apps had the choice between using Eclipse and using IntelliJ, and most of them chose IntelliJ. We knew that it was the gold standard for Java development (and still is, all these years later.) So we asked ourselves: if this is what developers prefer when given a choice, wouldn't this be for our users as well?
And the warm reception when we unveiled the alpha at I/O in 2013 made it clear that it was the right choice.”
- Tor Norbye, Engineering Director of Android Studio at Google
“We had a vision of creating a truly Integrated Development Environment for Android app development instead of a collection of related tools. In our previous working model, we had contributions of Android tools from a range of frameworks and UX flows that did not 100% work well end-to-end. The move to the open-sourced JetBrains IntelliJ platform enabled the Google team to tie tools together in a thoughtful way with Android Studio, plus it allowed others to contribute in a more seamless way. Lastly, looking back at the last 10 years, I’m proud of the partnership with Jetbrains and Gradle, plus the community of contributors to bring the best suite of tools to Android app developers.”
– Jamal Eason, Director of Product Management of Android Studio at Google
JetBrains
“Google choosing IntelliJ as the platform to build Android Studio was a very exciting moment for us at JetBrains. It allowed us to strengthen and build on the platform even further, and paved the way for further collaboration in other projects such as Kotlin.”
– Hadi Hariri, VP of Program Management at JetBrains
Gradle
“Android Studio's 10th anniversary marks a decade of incredible progress for Android developers. We are proud that Gradle Build Tool has continued to be a foundational part of the Android toolchain, enabling millions of Android developers to build their apps faster, more elegantly, and at scale.”
– Hans Dockter, creator of Gradle Build Tool and CEO/Founder of Gradle Inc.
“Our long-standing strategic partnership with Google and our mutual commitment to improving the developer experience continues to impact millions of developers. We look forward to continuing that journey for many years to come.”
– Piotr Jagielski, VP of Engineering, Gradle Build Tool
Last but not least, we want to thank you for your feedback and support over the last decade. Android Studio wouldn’t be where it is today without the active community of developers who are using it to build Android apps for their communities and the world and providing input on how we can make it better each day.
As we head into this new year, we’ll be bringing Gemini into more aspects of Android Studio to help you across the development lifecycle to build quality apps faster. We’ll strive to make it easier and more seamless to build, test, and deploy your apps with Jetpack Compose across the range of form factors. We are proud of what we launch, but we always have room to improve in the evolving mobile ecosystem. Therefore, quality and stability of the IDE is our top priority so that you can be as productive as possible.
We look forward to continuing to empower you with great tools and improvements as we take Android Studio forward into the next decade. 🚀 We also welcome you to be a part of our developer community on LinkedIn, Medium, YouTube, or X.






 Posted by
Posted by 










 Happy reporting!
Happy reporting!