Posted by Kanstantsin Sokal, Software Engineer, MediaPipe team
Earlier this year, the MediaPipe Team released the Face Mesh solution, which estimates the approximate 3D face shape via 468 landmarks in real-time on mobile devices. In this blog, we introduce a new face transform estimation module that establishes a researcher- and developer-friendly semantic API useful for determining the 3D face pose and attaching virtual objects (like glasses, hats or masks) to a face.
The new module establishes a metric 3D space and uses the landmark screen positions to estimate common 3D face primitives, including a face pose transformation matrix and a triangular face mesh. Under the hood, a lightweight statistical analysis method called Procrustes Analysis is employed to drive a robust, performant and portable logic. The analysis runs on CPU and has a minimal speed/memory footprint on top of the original Face Mesh solution.

Figure 1: An example of virtual mask and glasses effects, based on the MediaPipe Face Mesh solution.
Introduction
The MediaPipe Face Landmark Model performs a single-camera face landmark detection in the screen coordinate space: the X- and Y- coordinates are normalized screen coordinates, while the Z coordinate is relative and is scaled as the X coordinate under the weak perspective projection camera model. While this format is well-suited for some applications, it does not directly enable crucial features like aligning a virtual 3D object with a detected face.
The newly introduced module moves away from the screen coordinate space towards a metric 3D space and provides the necessary primitives to handle a detected face as a regular 3D object. By design, you'll be able to use a perspective camera to project the final 3D scene back into the screen coordinate space with a guarantee that the face landmark positions are not changed.
Metric 3D Space
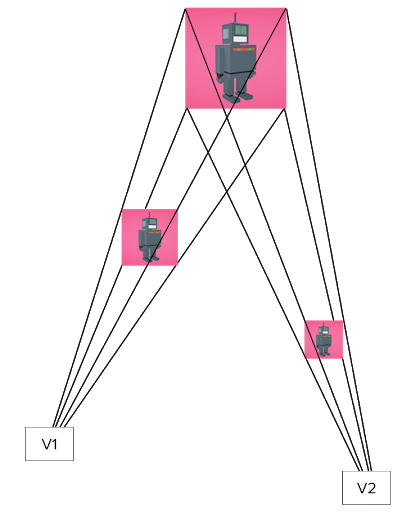
The Metric 3D space established within the new module is a right-handed orthonormal metric 3D coordinate space. Within the space, there is a virtual perspective camera located at the space origin and pointed in the negative direction of the Z-axis. It is assumed that the input camera frames are observed by exactly this virtual camera and therefore its parameters are later used to convert the screen landmark coordinates back into the Metric 3D space. The virtual camera parameters can be set freely, however for better results it is advised to set them as close to the real physical camera parameters as possible.

Figure 2: A visualization of multiple key elements in the metric 3D space. Created in Cinema 4D
Canonical Face Model
The Canonical Face Model is a static 3D model of a human face, which follows the 3D face landmark topology of the MediaPipe Face Landmark Model. The model bears two important functions:
- Defines metric units: the scale of the canonical face model defines the metric units of the Metric 3D space. A metric unit used by the default canonical face model is a centimeter;
- Bridges static and runtime spaces: the face pose transformation matrix is - in fact - a linear map from the canonical face model into the runtime face landmark set estimated on each frame. This way, virtual 3D assets modeled around the canonical face model can be aligned with a tracked face by applying the face pose transformation matrix to them.
Face Transform Estimation
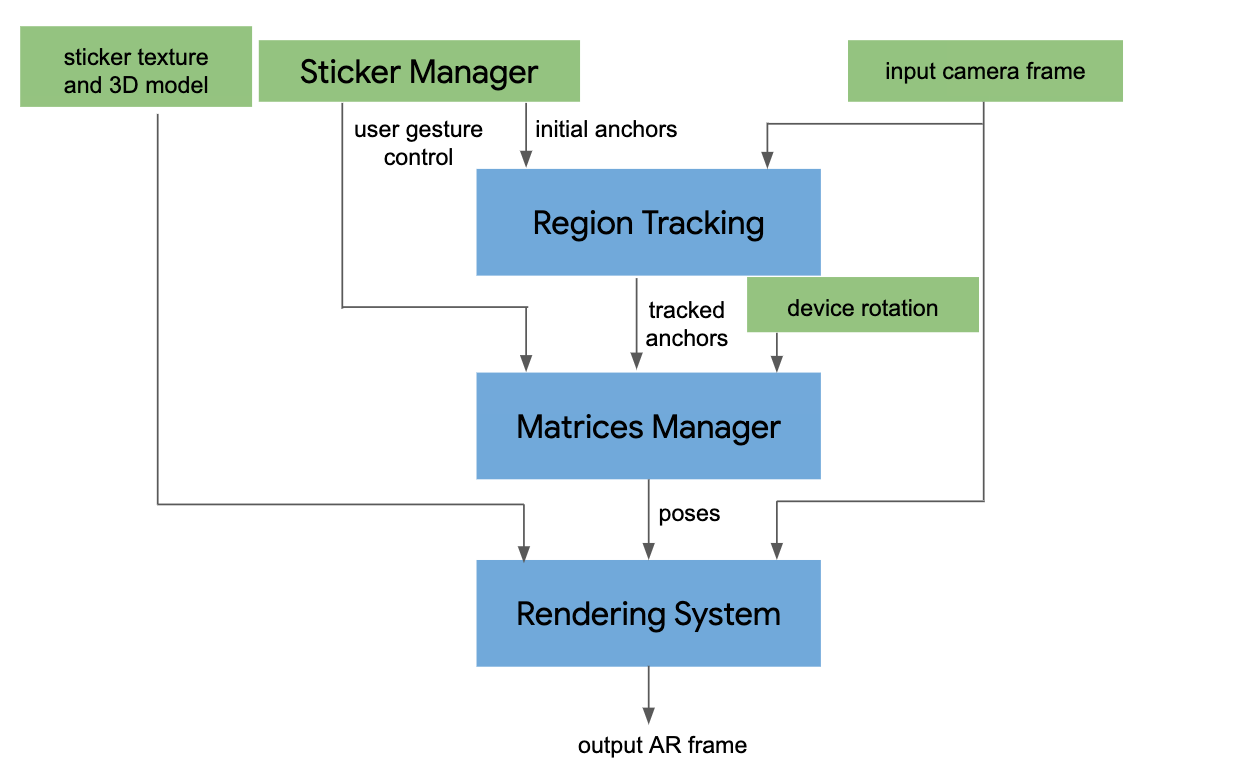
The face transform estimation pipeline is a key component, responsible for estimating face transform data within the Metric 3D space. On each frame, the following steps are executed in the given order:
- Face landmark screen coordinates are converted into the Metric 3D space coordinates;
- Face pose transformation matrix is estimated as a rigid linear mapping from the canonical face metric landmark set into the runtime face metric landmark set in a way that minimizes a difference between the two;
- A face mesh is created using the runtime face metric landmarks as the vertex positions (XYZ), while both the vertex texture coordinates (UV) and the triangular topology are inherited from the canonical face model.
Effect Renderer
The Effect Renderer is a component, which serves as a working example of a face effect renderer. It targets the OpenGL ES 2.0 API to enable a real-time performance on mobile devices and supports the following rendering modes:
- 3D object rendering mode: a virtual object is aligned with a detected face to emulate an object attached to the face (example: glasses);
- Face mesh rendering mode: a texture is stretched on top of the face mesh surface to emulate a face painting technique.
In both rendering modes, the face mesh is first rendered as an occluder straight into the depth buffer. This step helps to create a more believable effect via hiding invisible elements behind the face surface.

Figure 3: An example of face effects rendered by the Face Effect Renderer.
Using Face Transform Module
The face transform estimation module is available as a part of the MediaPipe Face Mesh solution. It comes with face effect application examples, available as graphs and mobile apps on Android or iOS. If you wish to go beyond examples, the module contains generic calculators and subgraphs - those can be flexibly applied to solve specific use cases in any MediaPipe graph. For more information, please visit our documentation.
Follow MediaPipe
We look forward to publishing more blog posts related to new MediaPipe pipeline examples and features. Please follow the MediaPipe label on Google Developers Blog and Google Developers twitter account (@googledevs).
Acknowledgements
We would like to thank Chuo-Ling Chang, Ming Guang Yong, Jiuqiang Tang, Gregory Karpiak, Siarhei Kazakou, Matsvei Zhdanovich and Matthias Grundman for contributing to this blog post.



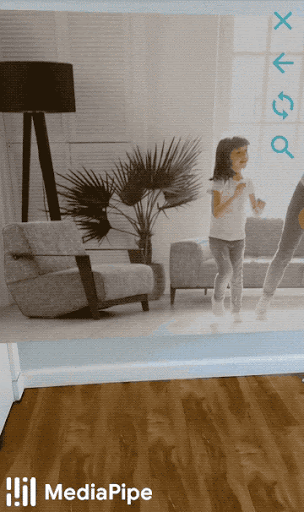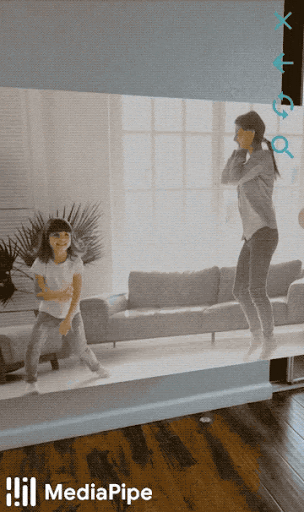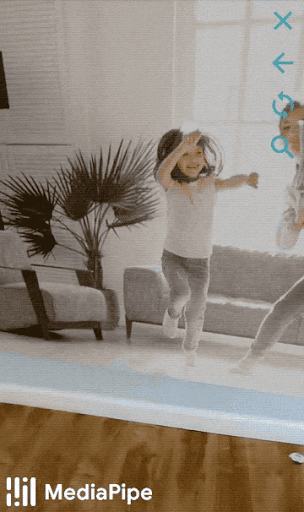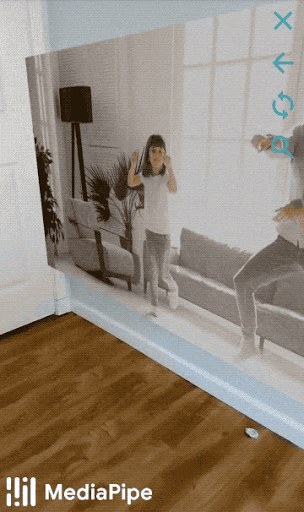














 Posted by Shahram Izadi, Director of Research and Engineering
Posted by Shahram Izadi, Director of Research and Engineering



 Posted by Christina Tong, Product Manager, Augmented Reality
Posted by Christina Tong, Product Manager, Augmented Reality 















