Posted by Ady Abraham, Software Engineer
For a long time, phones have had a display that refreshes at 60Hz. Application and game developers could just assume that the refresh rate is 60Hz, frame deadline is 16.6ms, and things would just work. This is no longer the case. New flagship devices are built with higher refresh rate displays, providing smoother animations, lower latency, and an overall nicer user experience. There are also devices that support multiple refresh rates, such as the Pixel 4, which supports both 60Hz and 90Hz.
A 60Hz display refreshes the display content every 16.6ms. This means that an image will be shown for the duration of a multiple of 16.6ms (16.6ms, 33.3ms, 50ms, etc.). A display that supports multiple refresh rates, provides more options to render at different speeds without jitter. For example, a game that cannot sustain 60fps rendering must drop all the way to 30fps on a 60Hz display to remain smooth and stutter free (since the display is limited to present images at a multiple of 16.6ms, the next framerate available is a frame every 33.3ms or 30fps). On a 90Hz device, the same game can drop to 45fps (22.2ms for each frame), providing a much smoother user experience. A device that supports 90Hz and 120Hz can smoothly present content at 120, 90, 60 (120/2), 45(90/2), 40(120/3), 30(90/3), 24(120/5), etc. frames per second.
Rendering at high rates
The higher the rendering rate, the harder it is to sustain that frame rate, simply because there is less time available for the same amount of work. To render at 90Hz, applications only have 11.1ms to produce a frame as opposed to 16.6ms at 60Hz.
To demonstrate that, let’s take a look at the Android UI rendering pipeline. We can break frame rendering into roughly five pipeline stages:
- Application’s UI thread processes input events, calls app’s callbacks, and updates the View hierarchy’s list of recorded drawing commands
- Application’s RenderThread issues the recorded commands to the GPU
- GPU draws the frame
- SurfaceFlinger, which is the system service in charge of displaying the different application windows on the screen, composes the screen and submits the frame to the display HAL
- Display presents the frame
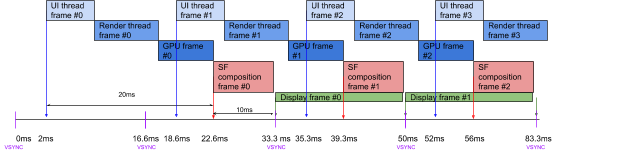
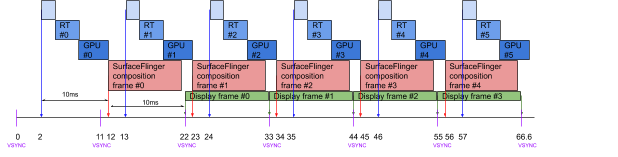
The entire pipeline is controlled by the Android Choreographer. The Choreographer is based on the display vertical synchronization (vsync) events, which indicate the time the display starts to scanout the image and update the display pixels. The Choreographer is based on the vsync events but has different wakeup offsets for the application and for SurfaceFlinger. The diagram below illustrates the pipeline on a Pixel 4 device running at 60Hz, where the application is woken up 2ms after the vsync event and SurfaceFlinger is woken up 6ms after the vsync event. This gives 20ms for an app to produce a frame, and 10ms for SurfaceFlinger to compose the screen.
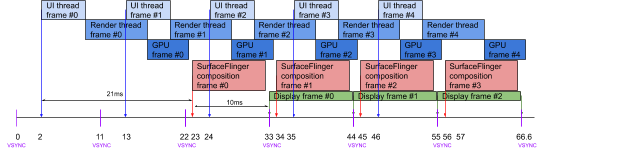
When running at 90Hz, the application is still woken up 2ms after the vsync event. However, SurfaceFlinger is woken up 1ms after the vsync event to have the same 10ms for composing the screen. The app, on the other hand, has just 10ms to render a frame, which is very short.
To mitigate that, the UI subsystem in Android is using “render ahead” (which delays a frame presentation while starting it at the same time) to deepen the pipeline and postpone frame presentation by one vsync. This gives the app 21ms to produce a frame, while keeping the throughput at 90Hz.
Some applications, including most games, have their own custom rendering pipelines. These pipelines might have more or fewer stages, depending on what they are trying to accomplish. In general, as the pipeline becomes deeper, more stages could be performed in parallel, which increases the overall throughput. On the other hand, this can increase the latency of a single frame (the latency will be number_of_pipeline_stages x longest_pipeline_stage). This tradeoff needs to be considered carefully.
Taking advantage of multiple refresh rates
As mentioned above, multiple refresh rates allow a broader range of available rendering rates to be used. This is especially useful for games which can control their rendering speed, and for video players which need to present content at a given rate. For example, to play a 24fps video on a 60Hz display, a 3:2 pulldown algorithm needs to be used, which creates jitter. However, if the device has a display that can present 24fps content natively (24/48/72/120Hz), it will eliminate the need for pulldown and the jitter associated with it.
The refresh rate that the device operates at is controlled by the Android platform. Applications and games can influence the refresh rate via various methods (explained below), but the ultimate decision is made by the platform. This is crucial when more than one app is present on the screen and the platform needs to satisfy all of them. A good example is a 24fps video player. 24Hz might be great for video playback, but it’s awful for responsive UI. A notification animating at only 24Hz feels janky. In situations like this, the platform will set the refresh rate to ensure that the content on the screen looks good.
For this reason, applications may need to know the current device refresh rate. This can be done in the following ways:
Applications can influence the device refresh rate by setting a frame rate on their Window or Surface. This is a new capability introduced in Android 11 and allows the platform to know the rendering intentions of the calling application. Applications can call one of the following methods:
Please refer to the frame rate guide on how to use these APIs.
The system will choose the most appropriate refresh rate based on the frame rate programmed on the Window or Surface.
On Older Android versions (before Android 11) where the setFrameRate API doesn’t exist, applications can still influence the refresh rate by directly setting WindowManager.LayoutParams.preferredDisplayModeId to one of the available modes from Display.getSupportedModes. This approach is discouraged starting with Android 11 since the platform doesn’t know the rendering intention of the app. For example, if a device supports 48Hz, 60Hz and 120Hz and there are two applications present on the screen that call setFrameRate(60, …) and setFrameRate(24, …) respectively, the platform can choose 120Hz and make both applications happy. On the other hand, if those applications used preferredDisplayModeId they would probably set the mode to 60Hz and 48Hz respectively, leaving the platform with no option to set 120Hz. The platform will choose either 60Hz or 48Hz, making one app unhappy.
Takeaways
Refresh rate is not always 60Hz - don’t assume 60Hz and don’t hardcode assumptions based on that historical artifact.
Refresh rate is not always constant - if you care about the refresh rate, you need to register a callback to find out when the refresh rate changes and update your internal data accordingly.
If you are not using the Android UI toolkit and have your own custom renderer, consider changing your rendering pipeline according to the current refresh rate. Deepening the pipeline can be done by setting a presentation timestamp using eglPresentationTimeANDROID on OpenGL or VkPresentTimesInfoGOOGLE on Vulkan. Setting a presentation timestamp indicates to SurfaceFlinger when to present the image. If it is set to a few frames in the future, it will deepen the pipeline by the number of frames it is set to. The Android UI in the example above is setting the present time to frameTimeNanos1 + 2 * vsyncPeriod2
Tell the platform your rendering intentions using the setFrameRate API. The platform will match different requests by selecting the appropriate refresh rate.
Use preferredDisplayModeId only when necessary, either when setFrameRate API is not available or when you need to use a very specific mode.
Lastly, familiarize yourself with the Android Frame Pacing library. This library handles proper frame pacing for your game and uses the methods described above to handle multiple refresh rates.
Notes