Posted by Nari Yoon, Hee Jung, DevRel Community Manager / Soonson Kwon, DevRel Program Manager
Let’s explore highlights and accomplishments of vast Google Machine Learning communities over the second quarter of the year! We are enthusiastic and grateful about all the activities by the global network of ML communities. Here are the highlights!
TensorFlow/Keras
TFUG Agadir hosted #MLReady phase as a part of #30DaysOfML. #MLReady aimed to prepare the attendees with the knowledge required to understand the different types of problems which deep learning can solve, and helped attendees be prepared for the TensorFlow Certificate.
TFUG Taipei hosted the basic Python and TensorFlow courses named From Python to TensorFlow. The aim of these events is to help everyone learn about the basics of Python and TensorFlow, including TensorFlow Hub, TensorFlow API. The event videos are shared every week via Youtube playlist.

TFUG New York hosted Introduction to Neural Radiance Fields for TensorFlow users. The talk included Volume Rendering, 3D view synthesis, and links to a minimal implementation of NeRF using Keras and TensorFlow. In the event, ML GDE Aritra Roy Gosthipaty (India) had a talk focusing on breaking the concepts of the academic paper, NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis into simpler and more ingestible snippets.
TFUG Turkey, GDG Edirne and GDG Mersin organized a TensorFlow Bootcamp 22 and ML GDE M. Yusuf Sarıgöz (Turkey) participated as a speaker, TensorFlow Ecosystem: Get most out of auxiliary packages. Yusuf demonstrated the inner workings of TensorFlow, how variables, tensors and operations interact with each other, and how auxiliary packages are built upon this skeleton.

TFUG Mumbai hosted the June Meetup and 110 folks gathered. ML GDE Sayak Paul (India) and TFUG mentor Darshan Despande shared knowledge through sessions. And ML workshops for beginners went on and participants built up machine learning models without writing a single line of code.
ML GDE Hugo Zanini (Brazil) wrote Realtime SKU detection in the browser using TensorFlow.js. He shared a solution for a well-known problem in the consumer packaged goods (CPG) industry: real-time and offline SKU detection using TensorFlow.js.
ML GDE Gad Benram (Portugal) wrote Can a couple TensorFlow lines reduce overfitting? He explained how just a few lines of code can generate data augmentations and boost a model’s performance on the validation set.
ML GDE Victor Dibia (USA) wrote How to Build An Android App and Integrate Tensorflow ML Models sharing how to run machine learning models locally on Android mobile devices, How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0) explaining in 5 steps about how to verify the model is focusing on the right tokens to classify text. He also wrote how to finetune a HuggingFace model for text classification, using Tensorflow 2.0.
ML GDE Karthic Rao (India) released a new series ML for JS developers with TFJS. This series is a combination of short portrait and long landscape videos. You can learn how to build a toxic word detector using TensorFlow.js.

ML GDE Sayak Paul (India) implemented the DeiT family of ViT models, ported the pre-trained params into the implementation, and provided code for off-the-shelf inference, fine-tuning, visualizing attention rollout plots, distilling ViT models through attention. (code | pretrained model | tutorial)

ML GDE Sayak Paul (India) and ML GDE Aritra Roy Gosthipaty (India) inspected various phenomena of a Vision Transformer, shared insights from various relevant works done in the area, and provided concise implementations that are compatible with Keras models. They provide tools to probe into the representations learned by different families of Vision Transformers. (tutorial | code)
JAX/Flax

ML GDE Aakash Nain (India) had a special talk, Introduction to JAX for ML GDEs, TFUG organizers and ML community network organizers. He covered the fundamentals of JAX/Flax so that more and more people try out JAX in the near future.
ML GDE Seunghyun Lee (Korea) started a project, Training and Lightweighting Cookbook in JAX/FLAX. This project attempts to build a neural network training and lightweighting cookbook including three kinds of lightweighting solutions, i.e., knowledge distillation, filter pruning, and quantization.
ML GDE Yucheng Wang (China) wrote History and features of JAX and explained the difference between JAX and Tensorflow.
ML GDE Martin Andrews (Singapore) shared a video, Practical JAX : Using Hugging Face BERT on TPUs. He reviewed the Hugging Face BERT code, written in JAX/Flax, being fine-tuned on Google’s Colab using Google TPUs. (Notebook for the video)
ML GDE Soumik Rakshit (India) wrote Implementing NeRF in JAX. He attempts to create a minimal implementation of 3D volumetric rendering of scenes represented by Neural Radiance Fields.
Kaggle
ML GDEs’ Kaggle notebooks were announced as the winner of Google OSS Expert Prize on Kaggle: Sayak Paul and Aritra Roy Gosthipaty’s Masked Image Modeling with Autoencoders in March; Sayak Paul’s Distilling Vision Transformers in April; Sayak Paul & Aritra Roy Gosthipaty’s Investigating Vision Transformer Representations; Soumik Rakshit’s Tensorflow Implementation of Zero-Reference Deep Curve Estimation in May and Aakash Nain’s The Definitive Guide to Augmentation in TensorFlow and JAX in June.
ML GDE Luca Massaron (Italy) published The Kaggle Book with Konrad Banachewicz. This book details competition analysis, sample code, end-to-end pipelines, best practices, and tips & tricks. And in the online event, Luca and the co-author talked about how to compete on Kaggle.

ML GDE Ertuğrul Demir (Turkey) wrote Kaggle Handbook: Fundamentals to Survive a Kaggle Shake-up covering bias-variance tradeoff, validation set, and cross validation approach. In the second post of the series, he showed more techniques using analogies and case studies.

TFUG Chennai hosted ML Study Jam with Kaggle and created study groups for the interested participants. More than 60% of members were active during the whole program and many of them shared their completion certificates.
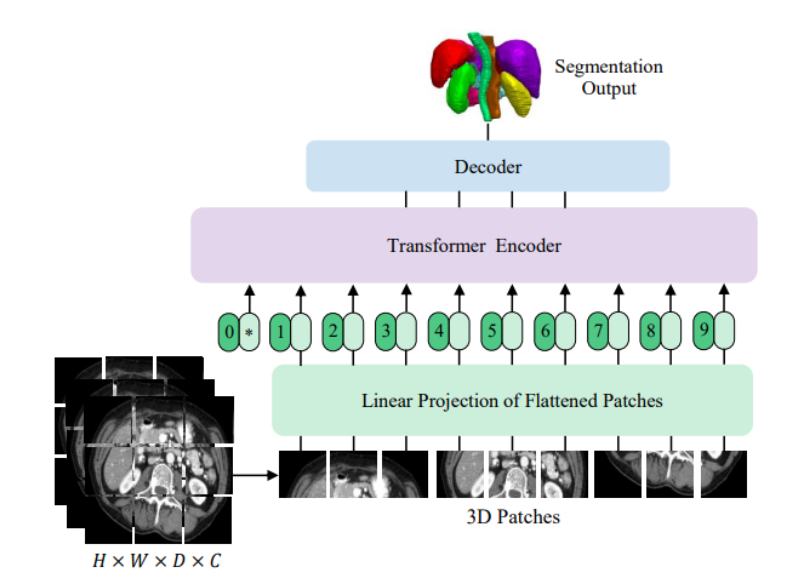
TFUG Mysuru organizer Usha Rengaraju shared a Kaggle notebook which contains the implementation of the research paper: UNETR - Transformers for 3D Biomedical Image Segmentation. The model automatically segments the stomach and intestines on MRI scans.
TFX
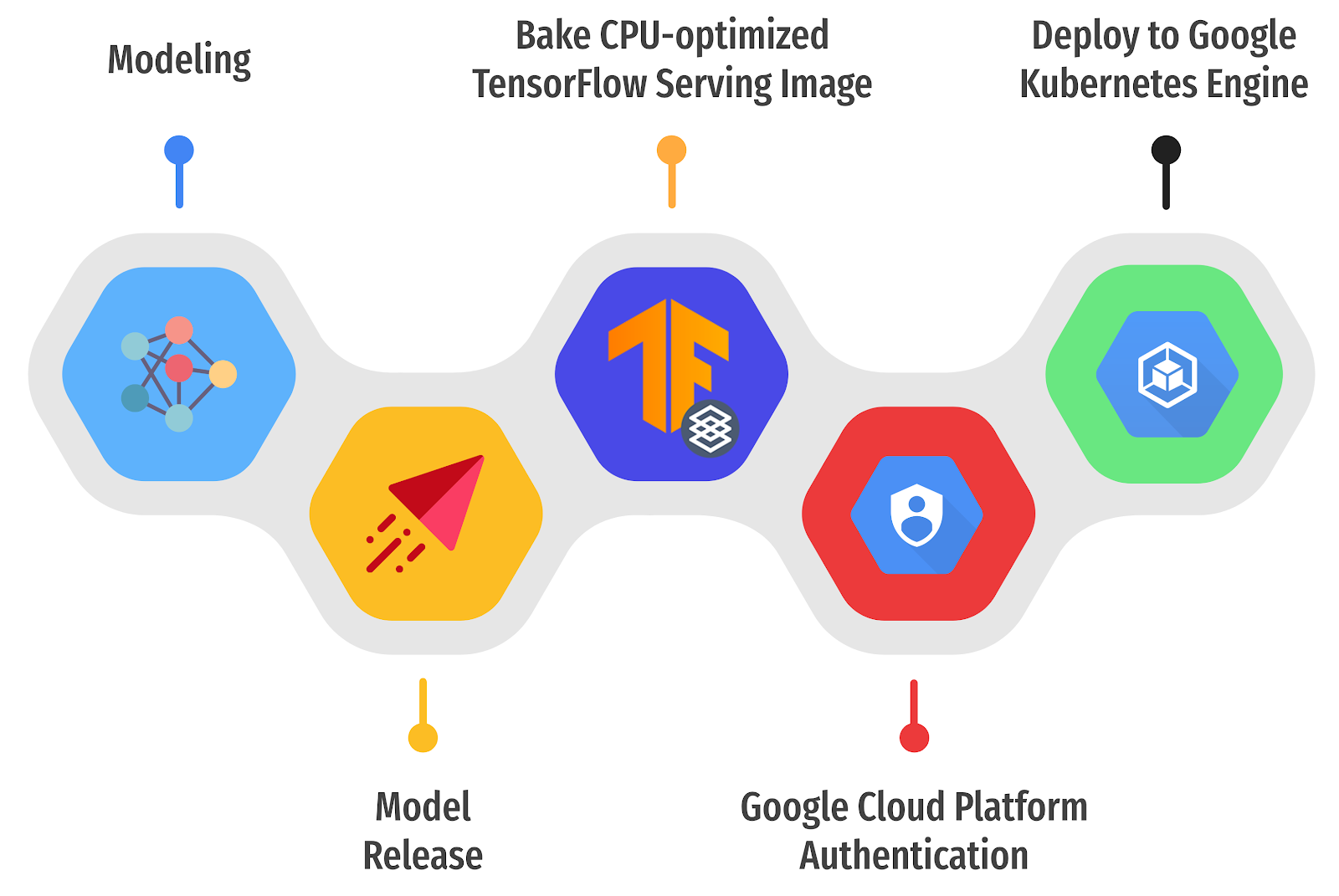
ML GDE Sayak Paul (India) and ML GDE Chansung Park (Korea) shared how to deploy a deep learning model with Docker, Kubernetes, and Github actions, with two promising ways - FastAPI (for REST) and TF Serving (for gRPC).
ML GDE Ukjae Jeong (Korea) and ML Engineers at Karrot Market, a mobile commerce unicorn with 23M users, wrote Why Karrot Uses TFX, and How to Improve Productivity on ML Pipeline Development.
ML GDE Jun Jiang (China) had a talk introducing the concept of MLOps, the production-level end-to-end solutions of Google & TensorFlow, and how to use TFX to build the search and recommendation system & scientific research platform for large-scale machine learning training.
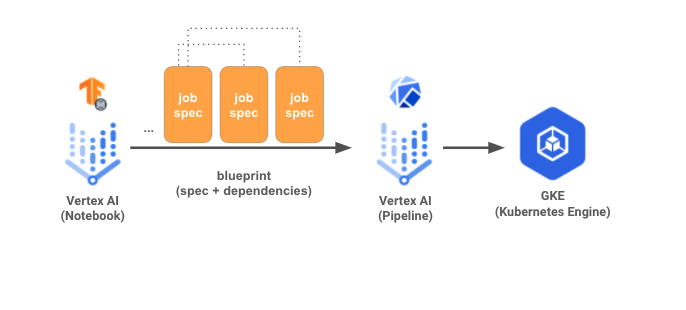
ML GDE Piero Esposito (Brazil) wrote Building Deep Learning Pipelines with Tensorflow Extended. He showed how to get started with TFX locally and how to move a TFX pipeline from local environment to Vertex AI; and provided code samples to adapt and get started with TFX.

TFUG São Paulo (Brazil) had a series of online webinars on TensorFlow and TFX. In the TFX session, they focused on how to put the models into production. They talked about the data structures in TFX and implementation of the first pipeline in TFX: ingesting and validating data.
TFUG Stockholm hosted MLOps, TensorFlow in Production, and TFX covering why, what and how you can effectively leverage MLOps best practices to scale ML efforts and had a look at how TFX can be used for designing and deploying ML pipelines.
Cloud AI
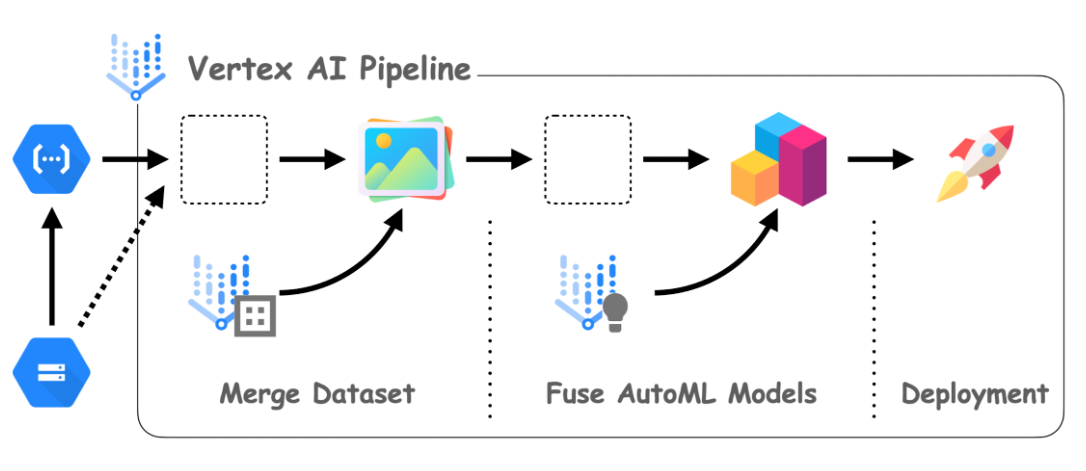
ML GDE Chansung Park (Korea) wrote MLOps System with AutoML and Pipeline in Vertex AI on GCP official blog. He showed how Google Cloud Storage and Google Cloud Functions can help manage data and handle events in the MLOps system.
He also shared the Github repository, Continuous Adaptation with VertexAI's AutoML and Pipeline. This contains two notebooks to demonstrate how to automate to produce a new AutoML model when the new dataset comes in.
TFUG Northwest (Portland) hosted The State and Future of AI + ML/MLOps/VertexAI lab walkthrough. In this event, ML GDE Al Kari (USA) outlined the technology landscape of AI, ML, MLOps and frameworks. Googler Andrew Ferlitsch had a talk about Google Cloud AI’s definition of the 8 stages of MLOps for enterprise scale production and how Vertex AI fits into each stage. And MLOps engineer Chris Thompson covered how easy it is to deploy a model using the Vertex AI tools.
Research
ML GDE Qinghua Duan (China) released a video which introduces Google’s latest 540 billion parameter model. He introduced the paper PaLM, and described the basic training process and innovations.
ML GDE Rumei LI (China) wrote blog postings reviewing papers, DeepMind's Flamingo and Google's PaLM.