Illiteracy affects at least 773 million people globally, both young and old. For these individuals, reading information from unfamiliar sources or on unfamiliar topics can be extremely difficult. Unfortunately, these inequalities have been further magnified by the global pandemic as a result of unequal access to education in reading and writing. In fact, UNESCO reports that over 100 million children are falling behind the minimum proficiency level in reading due to COVID-related school closures.
With increasing world-wide access to technology, reading on a device, such as a tablet or phone, has largely taken the place of traditional formats. This provides a unique opportunity to observe reading interactions, e.g., how a reader scrolls through a text, which can inform our understanding of what can make text difficult to read. This understanding is crucial when designing educational applications for low-proficiency readers and language learners, because it can be used to match learners with appropriately leveled texts as well as to support readers in understanding texts beyond their reading level.
In “Predicting Text Readability from Scrolling Interactions”, presented at CoNLL 2021, we show that data from on-device reading interactions can be used to predict how readable a text is. This novel approach provides insights into subjective readability — whether an individual reader has found a text accessible — and demonstrates that existing readability models can be improved by including feedback from scroll-based reading interactions. In order to encourage research in this area and to help enable more personalized tools for language learning and text simplification, we are releasing the dataset of reading interactions generated from our scrolling behavior–based readability assessment of English-language texts.
Understanding Text Difficulty
There are multiple aspects of a text that impact how difficult it is to read, including the vocabulary level, the syntactic structure, and overall coherence. Traditional machine learning approaches to measure readability have exclusively relied on such linguistic features. However, using these features alone does not work well for online content, because such content often contains abbreviations, emojis, broken text, and short passages, which detrimentally impact the performance of readability models.
To address this, we investigated whether aggregate data about the reading interactions of a group can be used to predict how difficult a text is, as well as how reading interactions may differ based on a readers’ understanding. When reading on a device, readers typically interact with text by scrolling in a vertical fashion, which we hypothesize can be used as a coarse proxy for reading comprehension. With this in mind, we recruited 518 paid participants and asked them to read English-language texts of different difficulty levels. We recorded the reading interactions by measuring different features of the participants’ scrolling behavior, such as the speed, acceleration and number of times areas of text were revisited. We then used this information to produce a set of features for a readability classifier.
Predicting Text Difficulty from Scrolling Behavior
We investigated which types of scrolling behaviors were most impacted by text difficulty and tested the significance using linear mixed effect models. In our set up, we have repeated measures, as multiple participants read the same texts and each participant reads more than one text. Using linear mixed-effect models gives us a higher confidence that the differences in interactions we are observing are because of the text difficulty, and not other random effects.
Our results showed that multiple reading behaviors differed significantly based on the text level, for example, the average, maximum and minimum acceleration of scrolling. We found the most significant features to be the total read time and the maximum reading speeds.
We then used these features as inputs to a machine learning algorithm. We designed and trained a support vector machine (i.e., a binary classifier) to predict whether a text is either advanced or elementary based only on scrolling behaviors as individuals interacted with it. The dataset on which the model was trained contains 60 articles, each of which were read by an average of 17 participants. From these interactions we produced aggregate features by taking the mean of the significant measures across participants.

We measured the accuracy of the approach using a metric called f-score, which measures how accurate the model is at classifying a text as either “easy” or “difficult” (where 1.0 reflects perfect classification accuracy). We are able to achieve an f-score of 0.77 on this task, using interaction features alone. This is the first work to show that it is possible to predict the readability of a text using only interaction features.
Improving Readability Models
In order to demonstrate the value of applying readability measures from scrolling behaviors to existing readability models, we integrated scroll-based features into the state-of-the-art automated readability assessment tool, which was released as part of the OneStopEnglish corpus. We found that the addition of interaction features improves the f-score of this model from 0.84 to 0.88. In addition, we were able to significantly outperform this system by using interaction information with simple vocabulary features, such as the number of words in the text, achieving an impressive f-score of 0.96.
In our study, we recorded comprehension scores to evaluate the understanding and readability of text for individuals. Participants were asked three questions per article to assess the reader’s understanding of what they had read. The interaction features of an individual’s scrolling behavior was represented as a high dimensional vector. To explore this data, we visualized the reading interaction features for each participant using t-distributed stochastic neighbor embeddings, which is a statistical method for visualizing high-dimensional data. The results revealed clusters in the comprehension score based on how well individuals understood the text. This shows that there is implicit information in reading interactions about the likelihood that an individual has understood a given text. We refer to this phenomenon as subjective readability. This information can be very useful for educational applications or for simplifying online content.
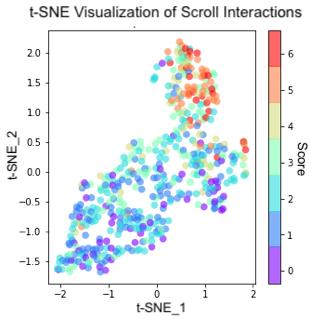 |
| Plot showing t-SNE projection of scroll interactions in 2-dimensions. The color of each data point corresponds to the comprehension score. Clusters of comprehension scores indicate that there are correlations between reading behaviors and comprehension. |
Finally, we investigated the extent to which reading interactions vary across audiences. We compared the average scrolling speed across different reader groups, covering reading proficiency and the reader’s first language. We found that the speed distribution varies depending on the proficiency and first language of the audience. This supports the case that first language and proficiency alter the reading behaviors of audiences, which allows us to contextualize the reading behavior of groups and better understand which areas of text may be harder for them to read.
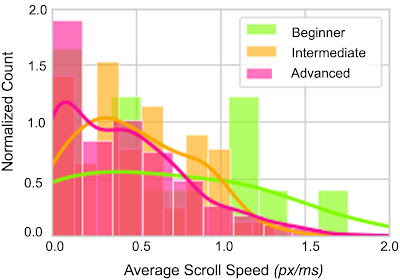 |
| Histogram showing the average speeds of scrolling (in vertical pixels per millisecond) across readers of different proficiency levels (beginner, intermediate and advanced), with lines showing the smoothed trend for each group. A higher average scroll speed indicates faster reading times. For example, a more challenging text that corresponds to slower scroll speeds by advanced readers is associated with higher scroll speeds by beginners because they engage with the text only superficially. |
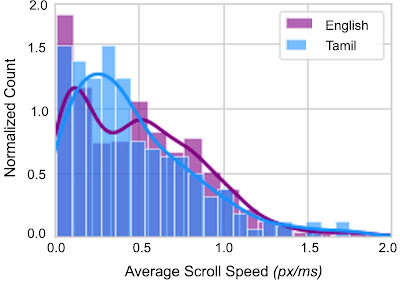 |
| Histogram showing the average speeds of scrolling (in vertical pixels per millisecond) across audiences by first language of the readers, Tamil or English, with lines showing the smoothed trend for each group. A higher average scroll speed indicates faster reading times. Dark blue bars are where the histograms overlap. |
Conclusion
This work is the first to show that reading interactions, such as scrolling behavior, can be used to predict the readability of text, which can yield numerous benefits. Such measures are language agnostic, unobtrusive, and robust to noisy text. Implicit user feedback allows insight into readability at an individual level, thereby allowing for a more inclusive and personalisable assessment of text difficulty. Furthermore, being able to judge the subjective readability of text benefits language learning and educational apps. We conducted a 518 participant study to investigate the impact of text readability on reading interactions and are releasing a novel dataset of the associated reading interactions. We confirm that there are statistically significant differences in the way that readers interact with advanced and elementary texts, and that the comprehension scores of individuals correlate with specific measures of scrolling interaction. For more information our conference presentation is available to view.
Acknowledgements
We thank our collaborators Yevgeni Berzak, Tony Mak and Matt Sharifi, as well as Dmitry Lagun and Blaise Aguera y Arcas for their helpful feedback on the paper.