Posted by Krishna Srinivasan, Software Engineer and Karthik Raman, Research Scientist, Google Research Multimodal visio-linguistic models rely on rich datasets in order to model the relationship between images and text. Traditionally, these datasets have been created by either manually captioning images, or crawling the web and extracting the alt-text as the caption. While the former approach tends to result in higher quality data, the intensive manual annotation process limits the amount of data that can be created. On the other hand, the automated extraction approach can lead to bigger datasets, but these require either heuristics and careful filtering to ensure data quality or scaling-up models to achieve strong performance. An additional shortcoming of existing datasets is the dearth of coverage in non-English languages. This naturally led us to ask: Can one overcome these limitations and create a high-quality, large-sized, multilingual dataset with a variety of content?
Today we introduce the Wikipedia-Based Image Text (WIT) Dataset, a large multimodal dataset, created by extracting multiple different text selections associated with an image from Wikipedia articles and Wikimedia image links. This was accompanied by rigorous filtering to only retain high quality image-text sets. As detailed in “WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning”, presented at SIGIR ‘21, this resulted in a curated set of 37.5 million entity-rich image-text examples with 11.5 million unique images across 108 languages. The WIT dataset is available for download and use under the Creative Commons license. We are also excited to announce that we are hosting a competition with the WIT dataset in Kaggle in collaboration with Wikimedia Research and other external collaborators.
| WIT’s increased language coverage and larger size relative to previous datasets. |
The unique advantages of the WIT dataset are:
- Size: WIT is the largest multimodal dataset of image-text examples that is publicly available.
- Multilingual: With 108 languages, WIT has 10x or more languages than any other dataset.
- Contextual information: Unlike typical multimodal datasets, which have only one caption per image, WIT includes many page-level and section-level contextual information.
- Real world entities: Wikipedia, being a broad knowledge-base, is rich with real world entities that are represented in WIT.
- Challenging test set: In our recent work accepted at EMNLP, all state-of-the-art models demonstrated significantly lower performance on WIT vs. traditional evaluation sets (e.g., ~30 point drop in recall).
Generating the Dataset
The main goal of WIT was to create a large dataset without sacrificing on quality or coverage of concepts. Thus, we started by leveraging the largest online encyclopedia available today: Wikipedia.
For an example of the depth of information available, consider the Wikipedia page for Half Dome (Yosemite National Park, CA). As shown below, the article has numerous interesting text captions and relevant contextual information for the image, such as the page title, main page description, and other contextual information and metadata.
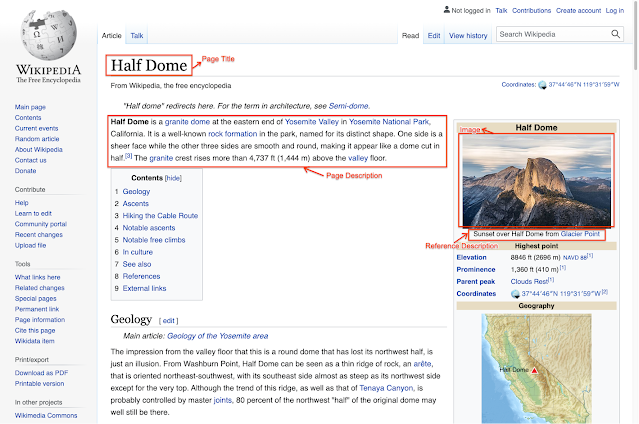 |
| Example wikipedia page with various image-associated text selections and contexts we can extract. From the Wikipedia page for Half Dome : Photo by DAVID ILIFF. License: CC BY-SA 3.0. |
We started by selecting Wikipedia pages that have images, then extracted various image-text associations and surrounding contexts. To further refine the data, we performed a rigorous filtering process to ensure data quality. This included text-based filtering to ensure caption availability, length and quality (e.g., by removing generic default filler text); image-based filtering to ensure each image is a certain size with permissible licensing; and finally, image-and-text-entity–based filtering to ensure suitability for research (e.g., excluding those classified as hate speech). We further randomly sampled image-caption sets for evaluation by human editors, who overwhelmingly agreed that 98% of the samples had good image-caption alignment.
Highly Multilingual
With data in 108 languages, WIT is the first large-scale, multilingual, multimodal dataset.
| # of Image-Text Sets | Unique Languages | # of Images | Unique Languages |
| > 1M | 9 | > 1M | 6 |
| 500K - 1M | 10 | 500K - 1M | 12 |
| 100K - 500K | 36 | 100K - 500K | 35 |
| 50K - 100K | 15 | 50K - 100K | 17 |
| 14K - 50K | 38 | 13K - 50K | 38 |
| WIT: coverage statistics across languages. |
 |
| Example of an image that is present in more than a dozen Wikipedia pages across >12 languages. From the Wikipedia page for Wolfgang Amadeus Mozart. |
The First Contextual Image-Text Dataset
Most multimodal datasets only offer a single text caption (or multiple versions of a similar caption) for the given image. WIT is the first dataset to provide contextual information, which can help researchers model the effect of context on image captions as well as the choice of images.
 |
| WIT dataset example showing image-text data and additional contextual information. |
In particular, key textual fields of WIT that may be useful for research include:
- Text captions: WIT offers three different kinds of image captions. This includes the (potentially context influenced) “Reference description”, the (likely context independent) “Attribution description” and “Alt-text description”.
- Contextual information: This includes the page title, page description, URL and local context about the Wikipedia section including the section title and text.
WIT has broad coverage across these different fields, as shown below.
| Image-Text Fields of WIT | Train | Val | Test | Total / Unique |
| Rows / Tuples | 37.1M | 261.8K | 210.7K | 37.6M |
| Unique Images | 11.4M | 58K | 57K | 11.5M |
| Reference Descriptions | 16.9M | 150K | 104K | 17.2M / 16.7M |
| Attribution Descriptions | 34.8M | 193K | 200K | 35.2M / 10.9M |
| Alt-Text | 5.3M | 29K | 29K | 5.4M / 5.3M |
| Context Texts | - | - | - | 119.8M |
| Key fields of WIT include both text captions and contextual information. |
A High-Quality Training Set and a Challenging Evaluation Benchmark
The broad coverage of diverse concepts in Wikipedia means that the WIT evaluation sets serve as a challenging benchmark, even for state-of-the-art models. We found that for image-text retrieval, the mean recall scores for traditional datasets were in the 80s, whereas for the WIT test set, it was in the 40s for well-resourced languages and in the 30s for the under-resourced languages. We hope this in turn can help researchers to build stronger, more robust models.
WIT Dataset and Competition with Wikimedia and Kaggle
Additionally, we are happy to announce that we are partnering with Wikimedia Research and a few external collaborators to organize a competition with the WIT test set. We are hosting this competition in Kaggle. The competition is an image-text retrieval task. Given a set of images and text captions, the task is to retrieve the appropriate caption(s) for each image.
To enable research in this area, Wikipedia has kindly made available images at 300-pixel resolution and a Resnet-50–based image embeddings for most of the training and the test dataset. Kaggle will be hosting all this image data in addition to the WIT dataset itself and will provide colab notebooks. Further, the competitors will have access to a discussion forum in Kaggle in order to share code and collaborate. This enables anyone interested in multimodality to get started and run experiments easily. We are excited and looking forward to what will result from the WIT dataset and the Wikipedia images in the Kaggle platform.
Conclusion
We believe that the WIT dataset will aid researchers in building better multimodal multilingual models and in identifying better learning and representation techniques, ultimately leading to improved Machine Learning models in real-world tasks over visio-linguistic data. For any questions, please contact [email protected]. We would love to hear about how you are using the WIT dataset.
Acknowledgements
We would like to thank our co-authors in Google Research: Jiecao Chen, Michael Bendersky and Marc Najork. We thank Beer Changpinyo, Corinna Cortes, Joshua Gang, Chao Jia, Ashwin Kakarla, Mike Lee, Zhen Li, Piyush Sharma, Radu Soricut, Ashish Vaswani, Yinfei Yang, and our reviewers for their insightful feedback and comments.
We thank Miriam Redi and Leila Zia from Wikimedia Research for collaborating with us on the competition and providing image pixels and image embedding data. We thank Addison Howard and Walter Reade for helping us host this competition in Kaggle. We also thank Diane Larlus (Naver Labs Europe (NLE)), Yannis Kalantidis (NLE), Stéphane Clinchant (NLE), Tiziano Piccardi Ph.D. student at EPFL, Lucie-Aimée Kaffee PhD student at University of Southampton and Yacine Jernite (Hugging Face) for their valuable contribution towards the competition.










{kind=link}
{kind=link}