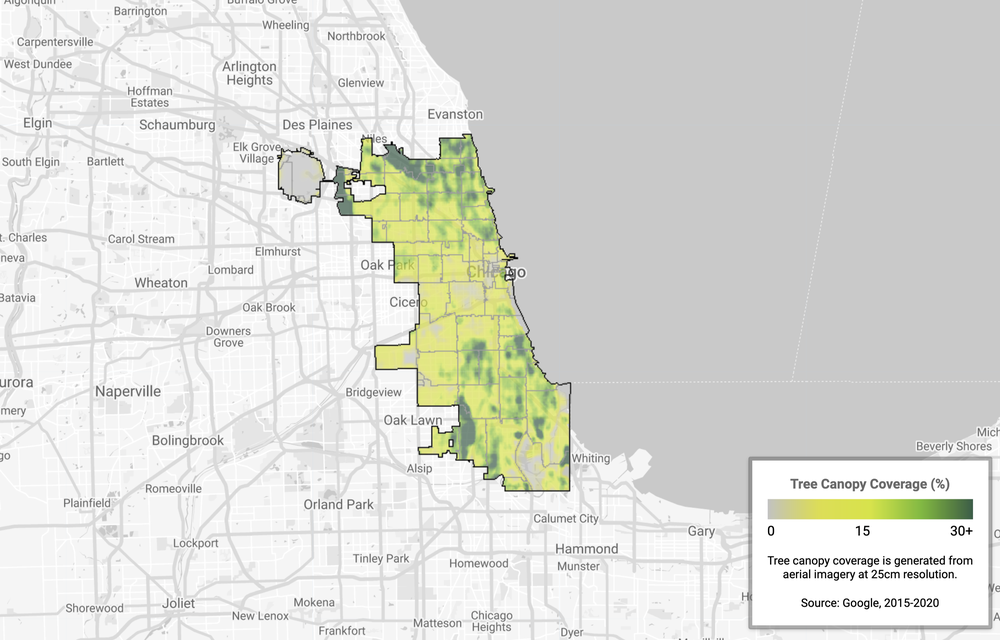
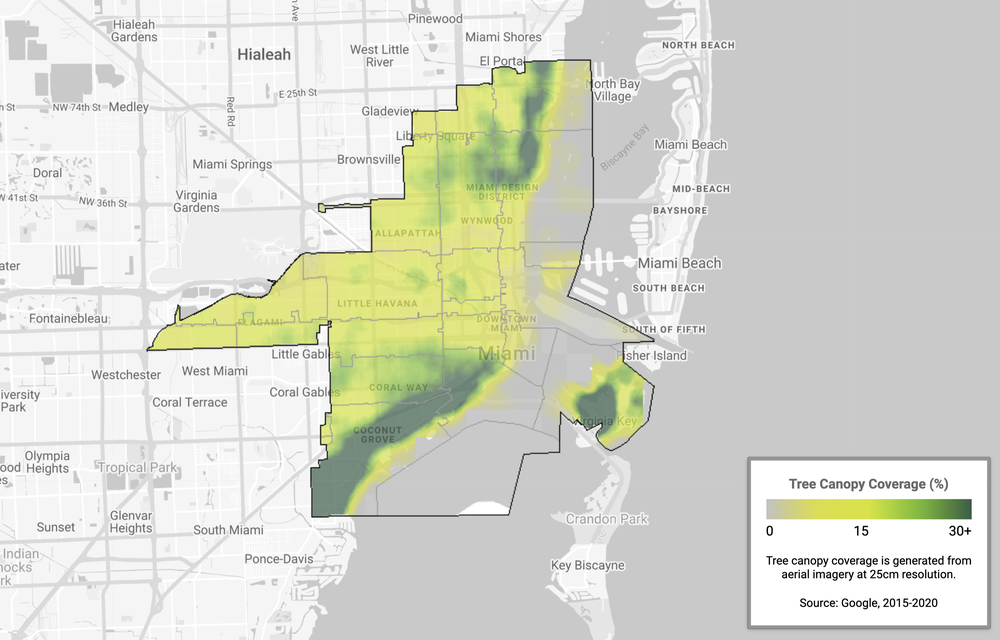
Today, there’s more information accessible at people’s fingertips than at any point in human history. And advances in artificial intelligence will radically transform the way we use that information, with the ability to uncover new insights that can help us both in our daily lives and in the ways we are able to tackle complex global challenges.
At our Search On livestream event today, we shared how we’re bringing the latest in AI to Google’s products, giving people new ways to search and explore information in more natural and intuitive ways.
Making multimodal search possible with MUM
Earlier this year at Google I/O, we announced we’ve reached a critical milestone for understanding information with Multitask Unified Model, or MUM for short.
We’ve been experimenting with using MUM’s capabilities to make our products more helpful and enable entirely new ways to search. Today, we’re sharing an early look at what will be possible with MUM.
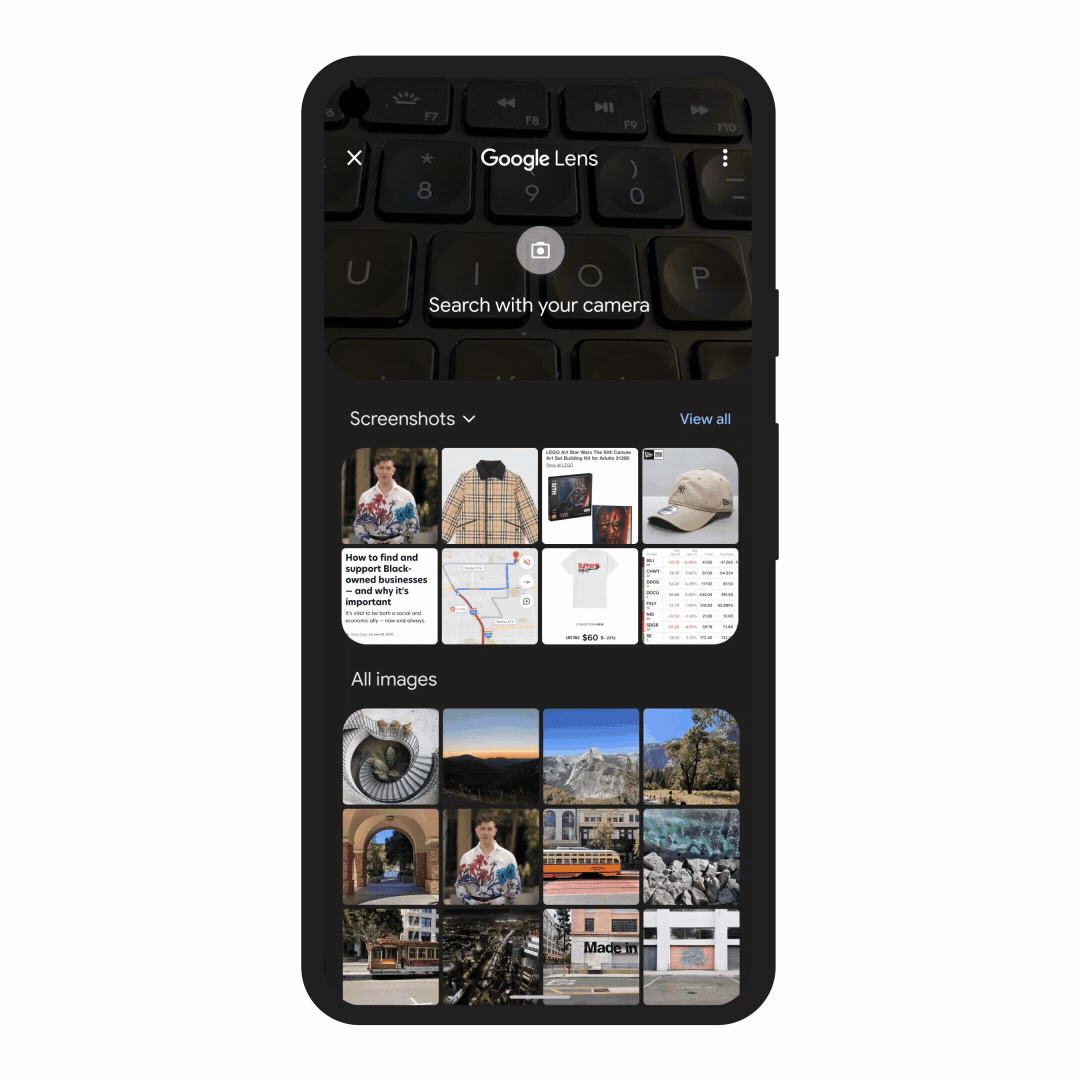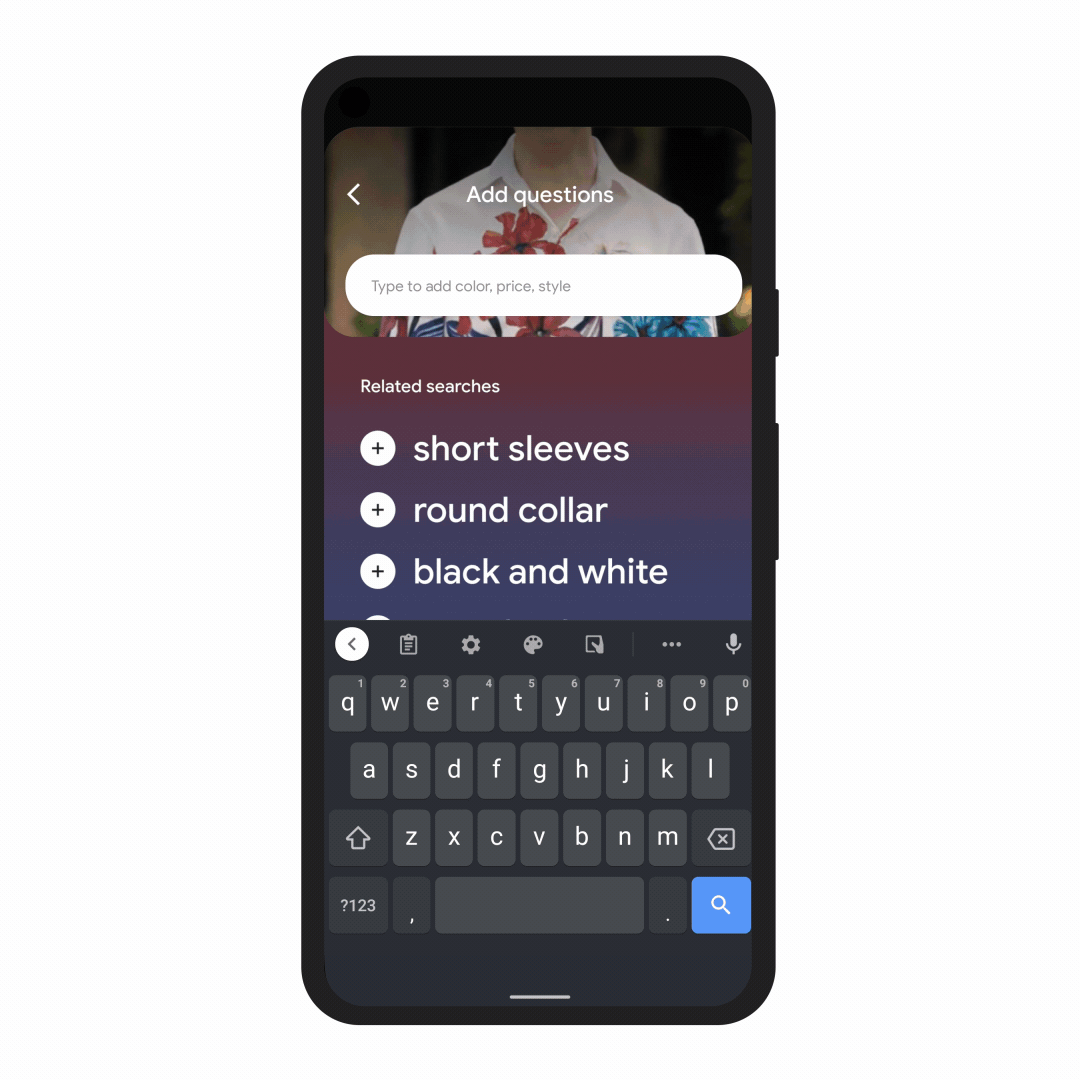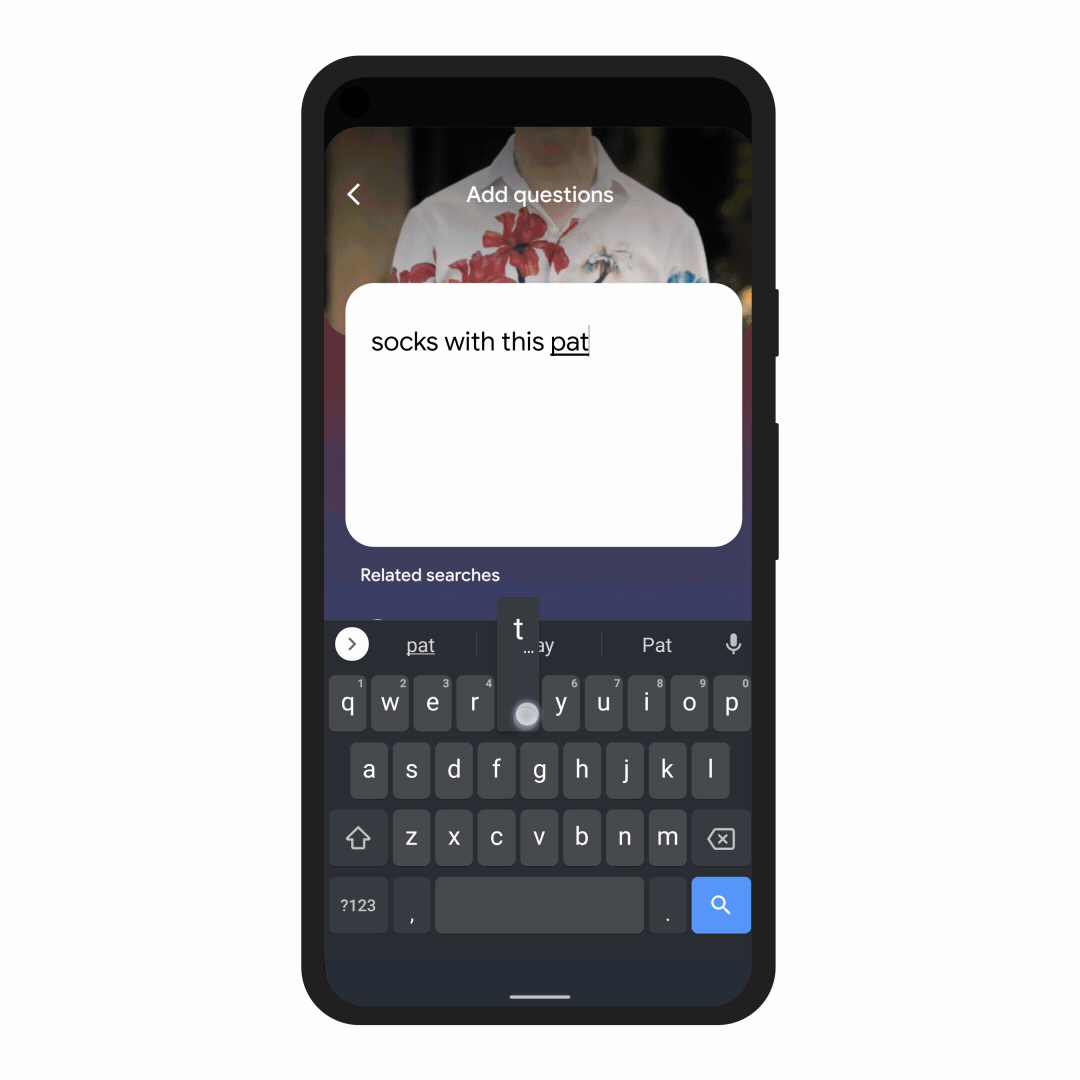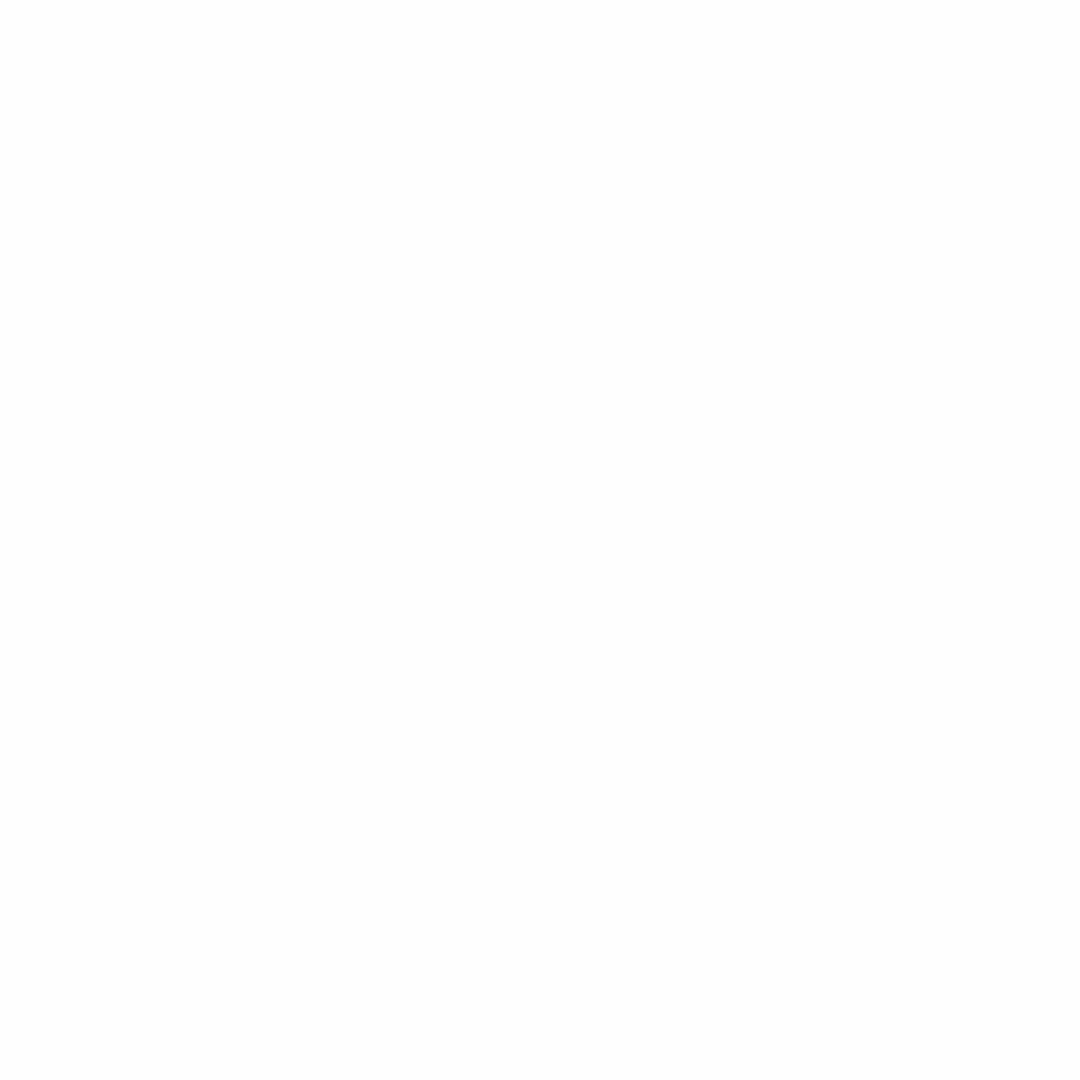
In the coming months, we’ll introduce a new way to search visually, with the ability to ask questions about what you see. Here are a couple of examples of what will be possible with MUM.
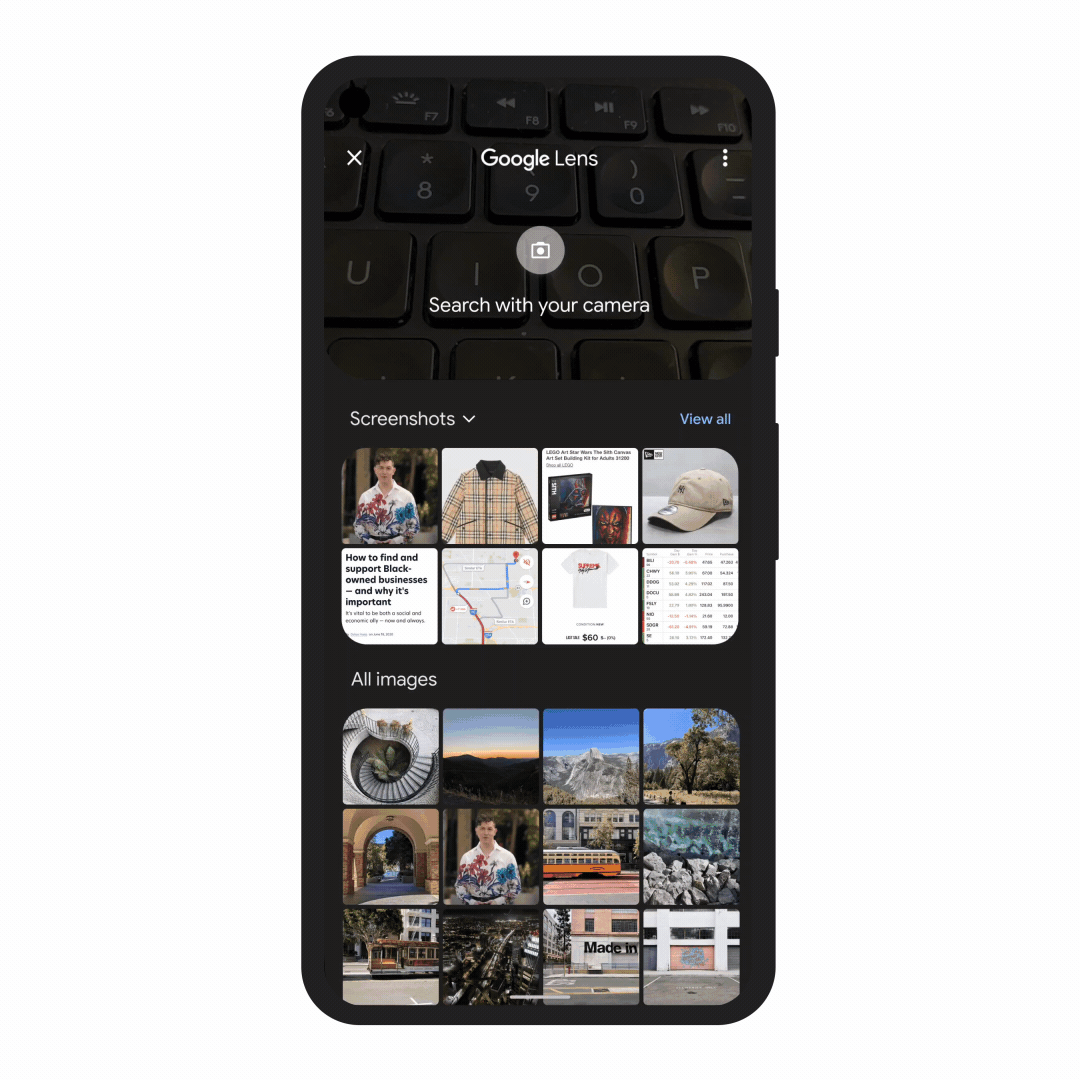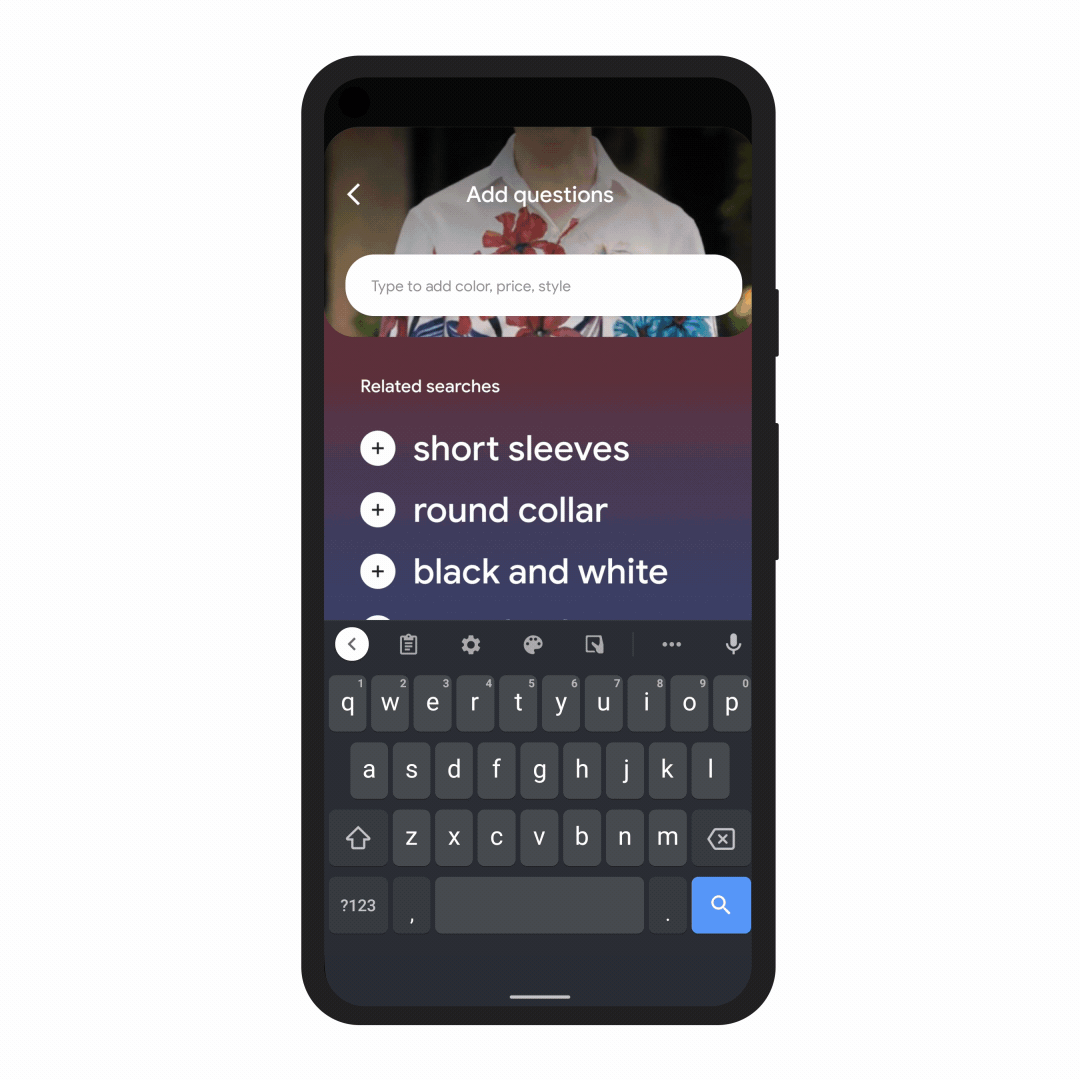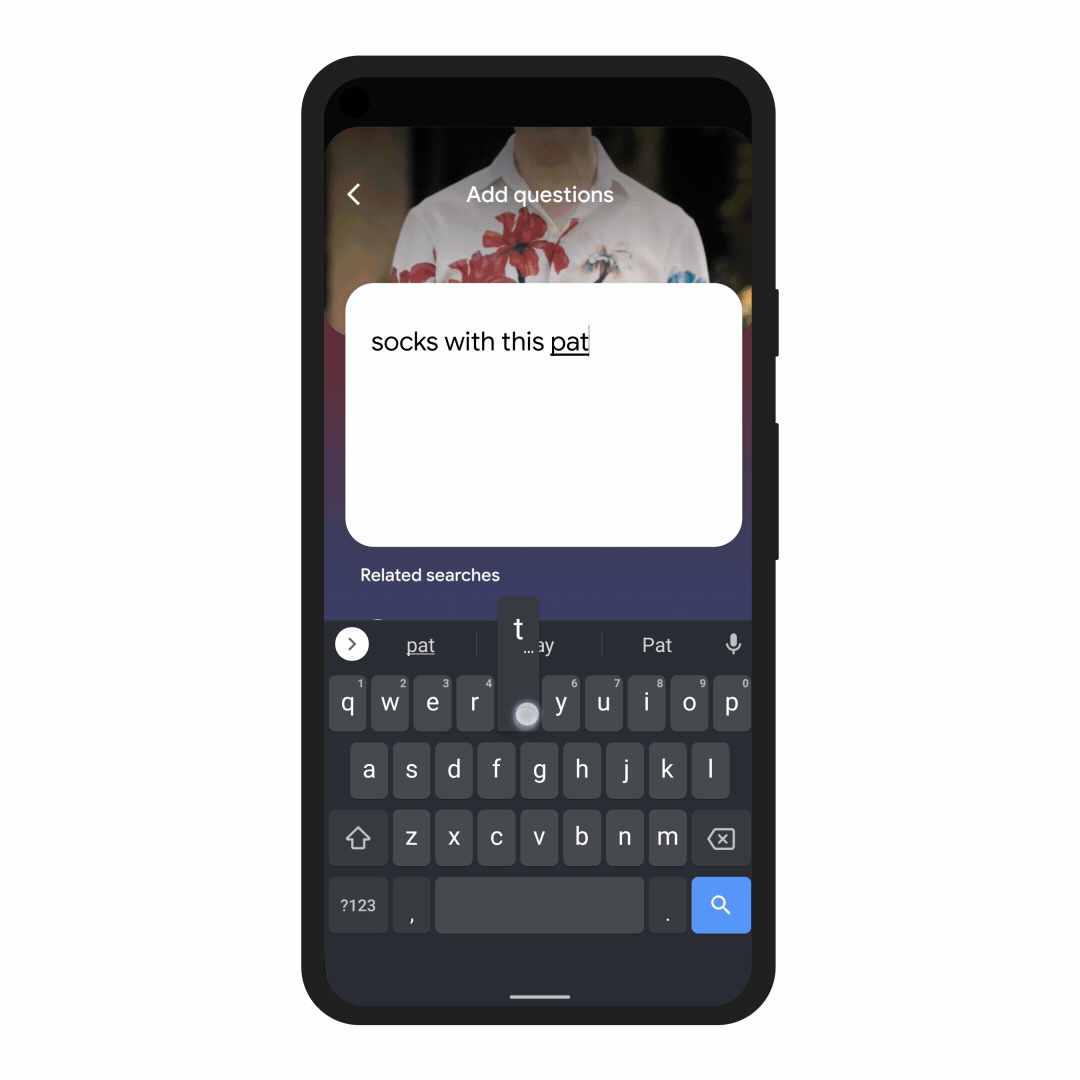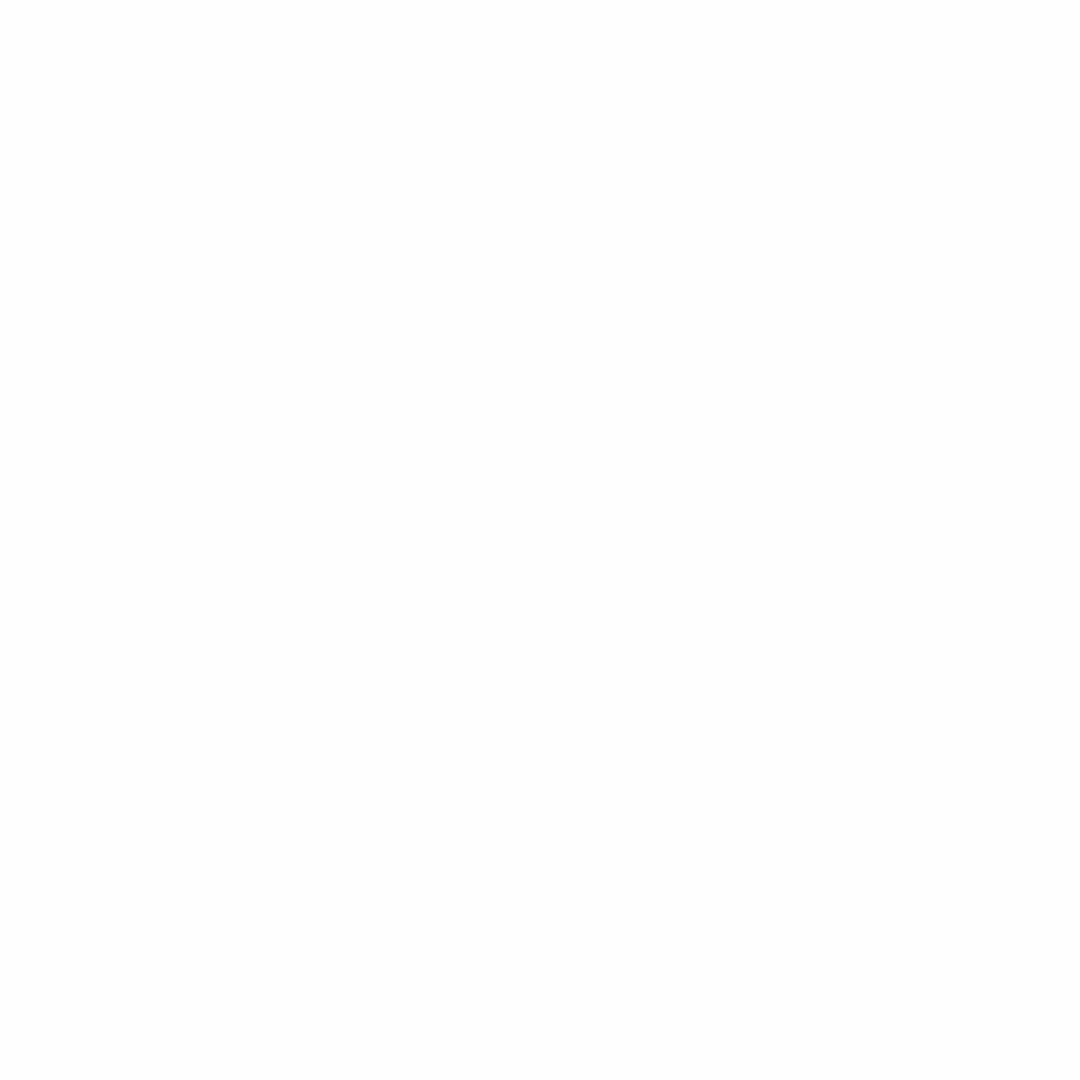
With this new capability, you can tap on the Lens icon when you’re looking at a picture of a shirt, and ask Google to find you the same pattern — but on another article of clothing, like socks. This helps when you’re looking for something that might be difficult to describe accurately with words alone. You could type “white floral Victorian socks,” but you might not find the exact pattern you’re looking for. By combining images and text into a single query, we’re making it easier to search visually and express your questions in more natural ways.

Some questions are even trickier: Your bike has a broken thingamajig, and you need some guidance on how to fix it. Instead of poring over catalogs of parts and then looking for a tutorial, the point-and-ask mode of searching will make it easier to find the exact moment in a video that can help.
Helping you explore with a redesigned Search page
We’re also announcing how we’re applying AI advances like MUM to redesign Google Search. These new features are the latest steps we’re taking to make searching more natural and intuitive.
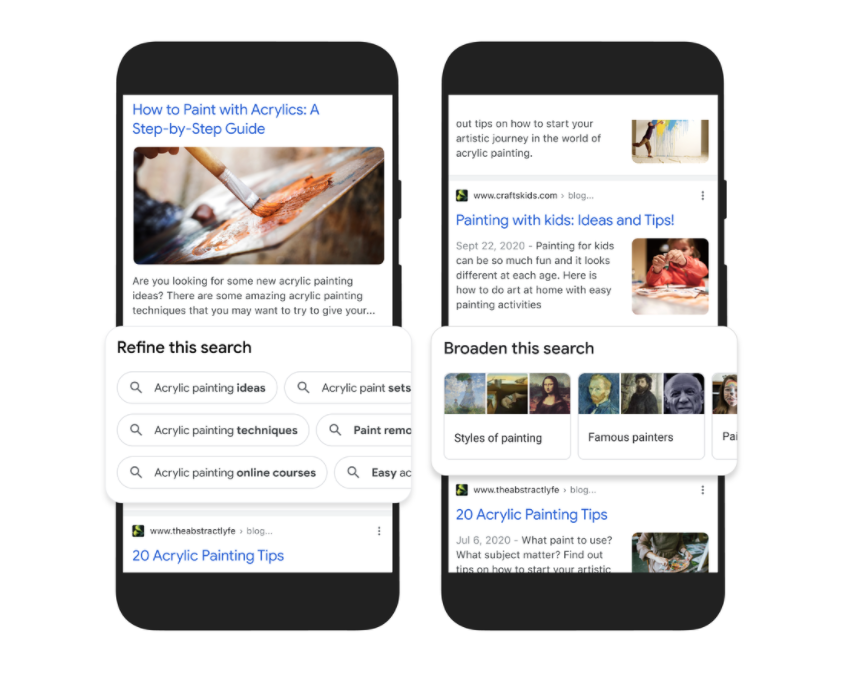
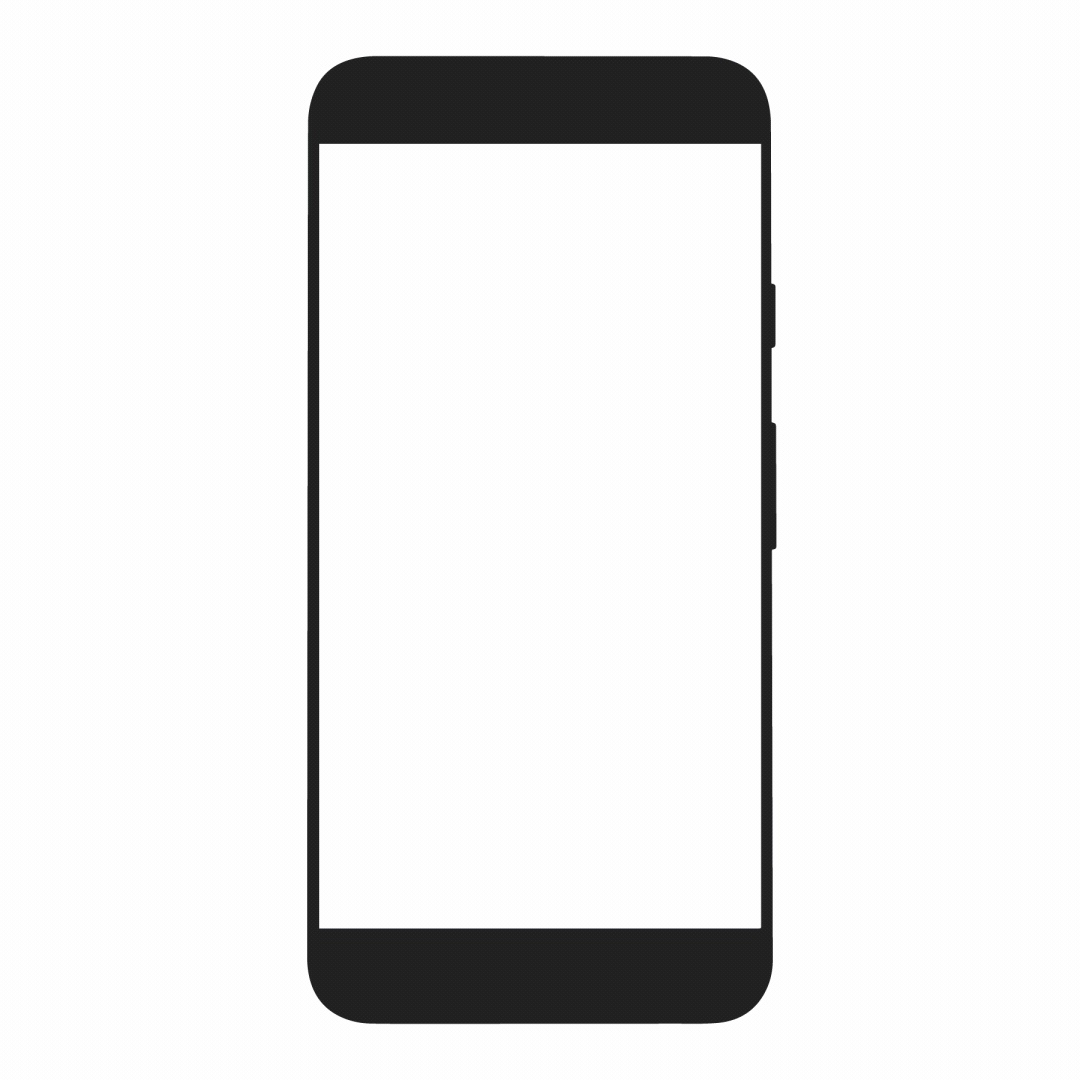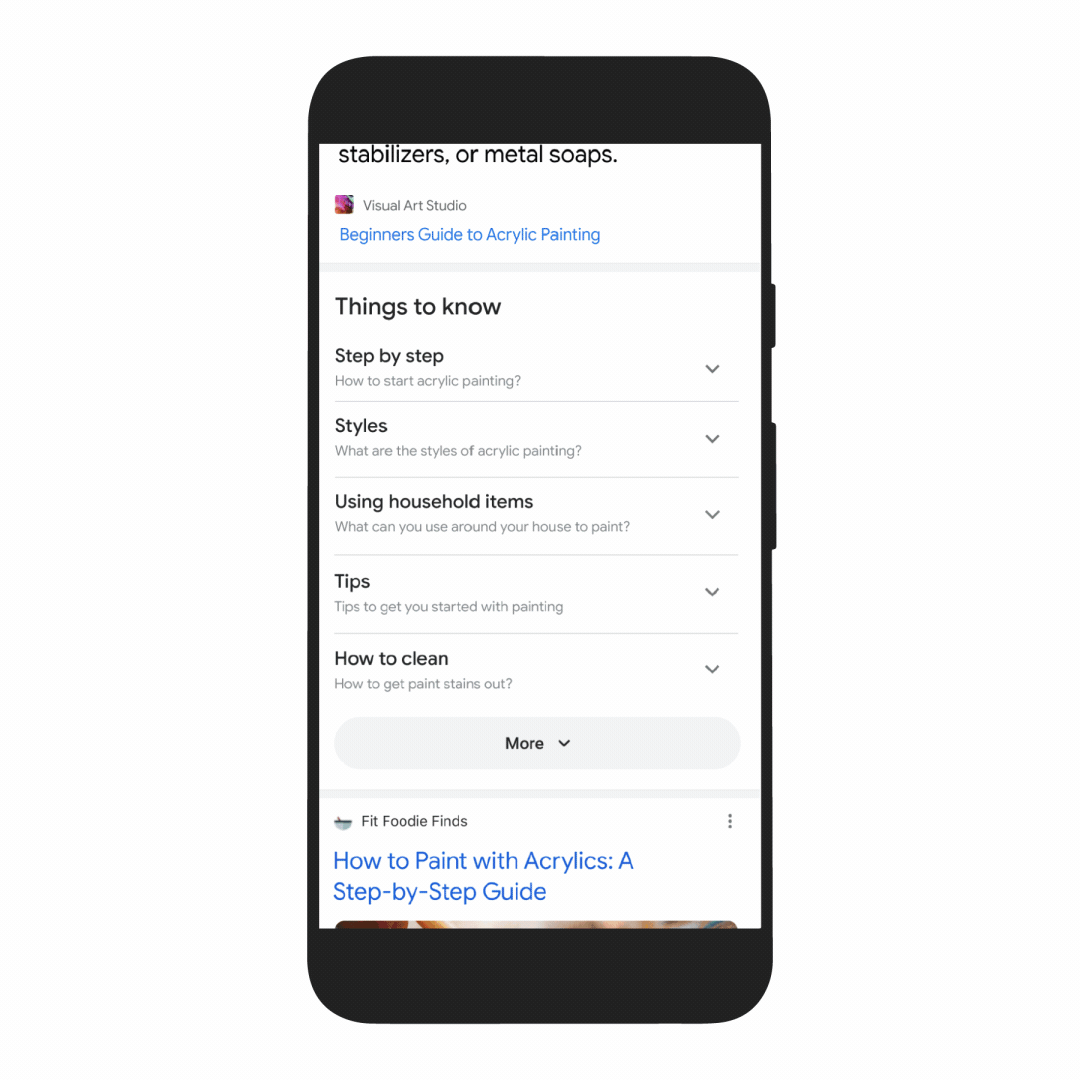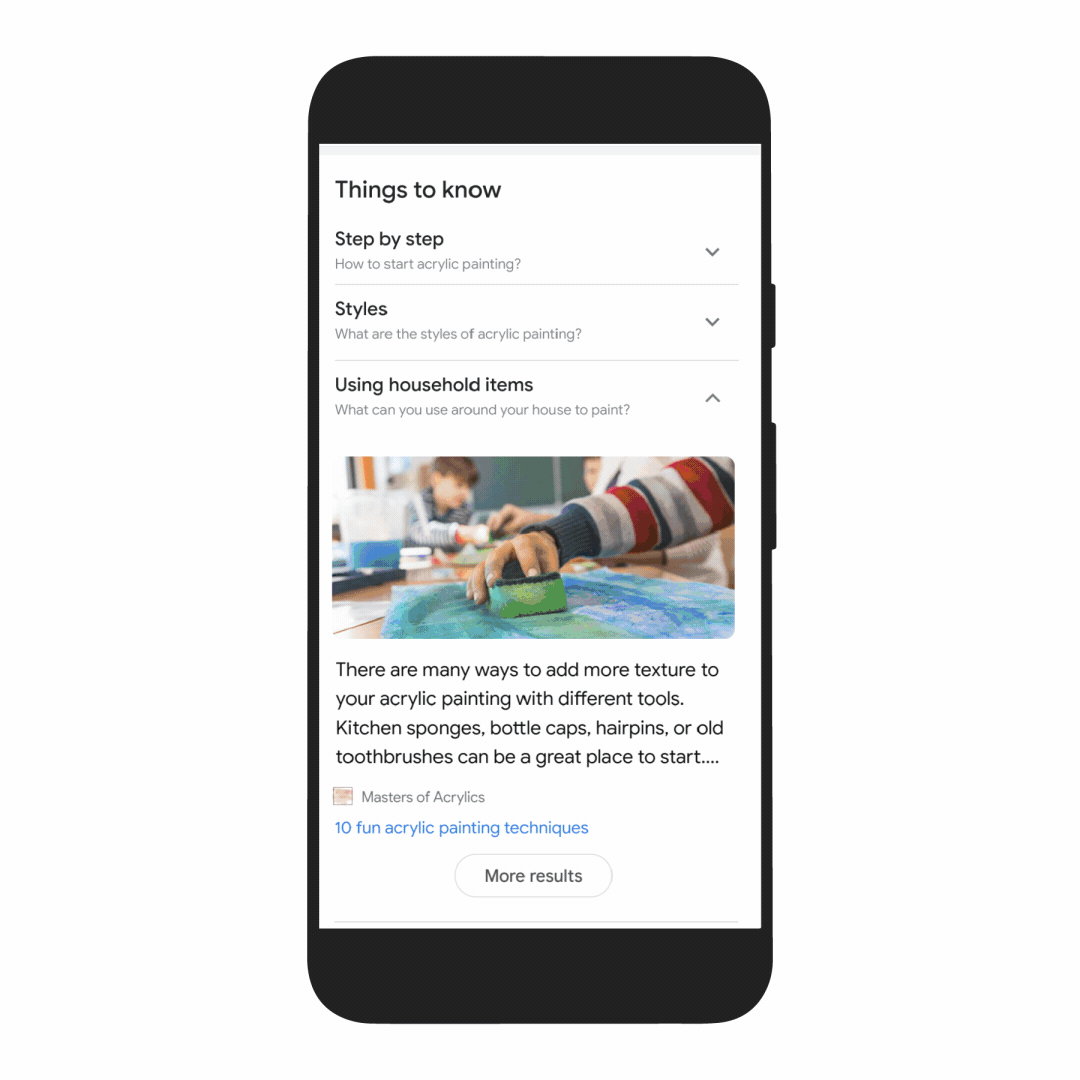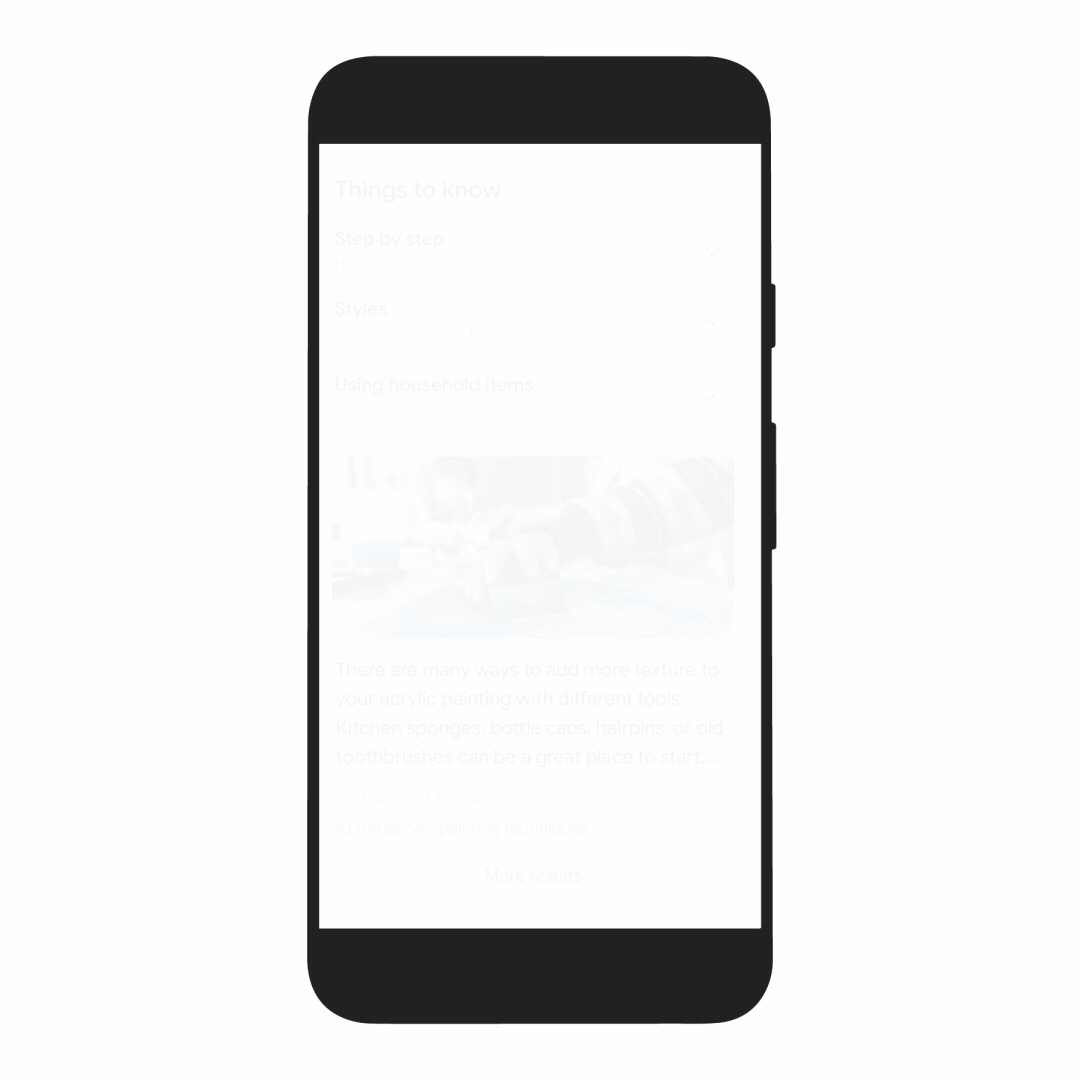
First, we’re making it easier to explore and understand new topics with “Things to know.” Let’s say you want to decorate your apartment, and you’re interested in learning more about creating acrylic paintings.
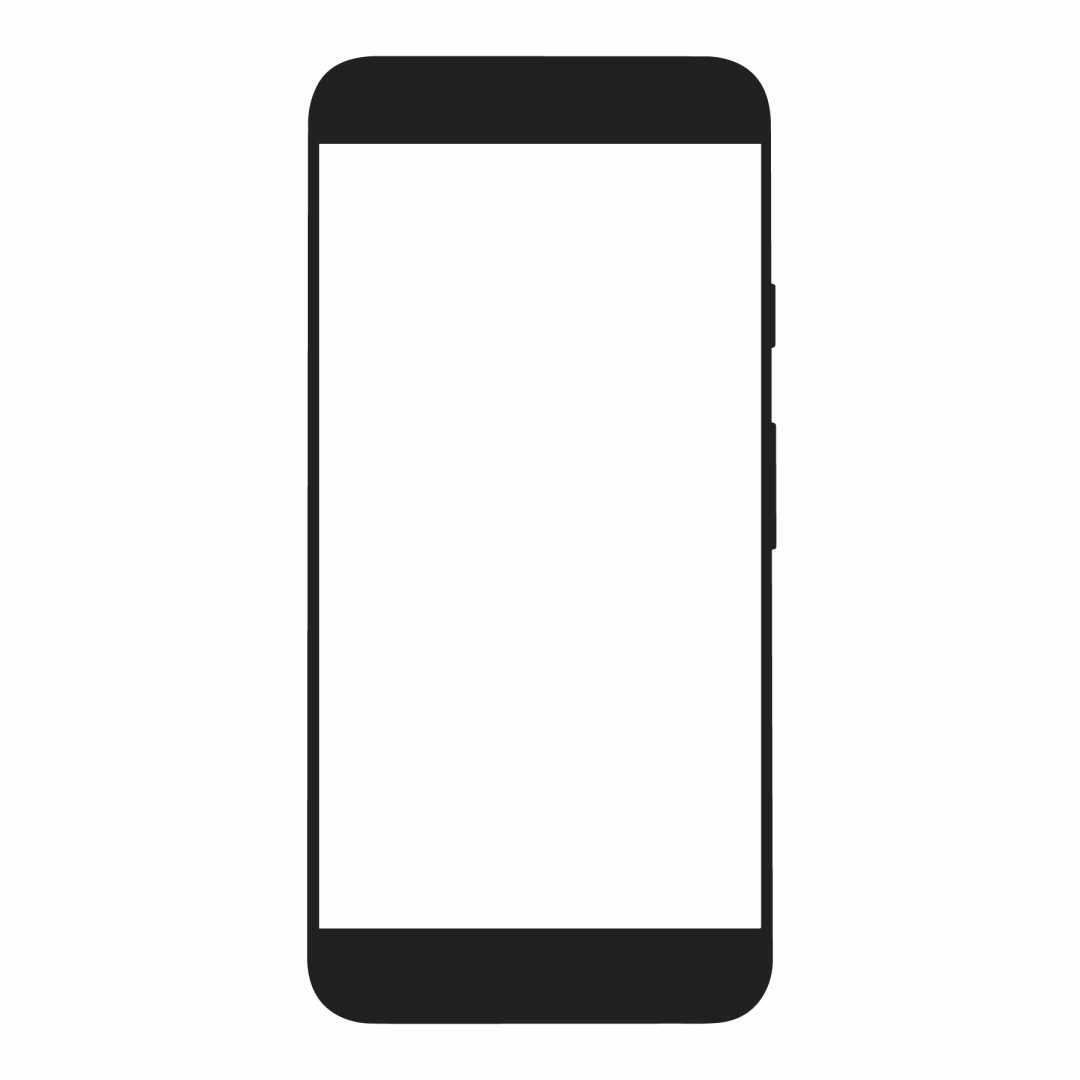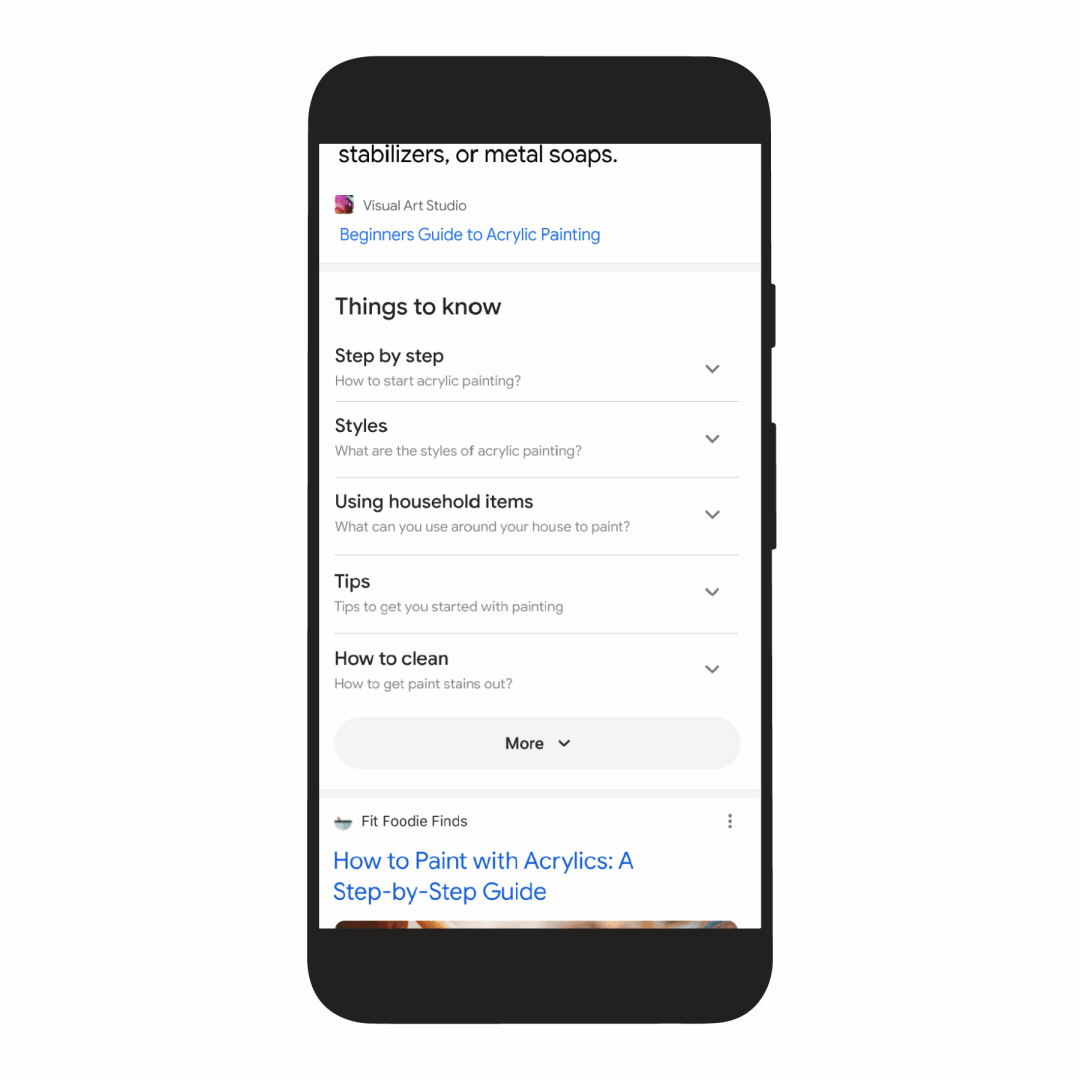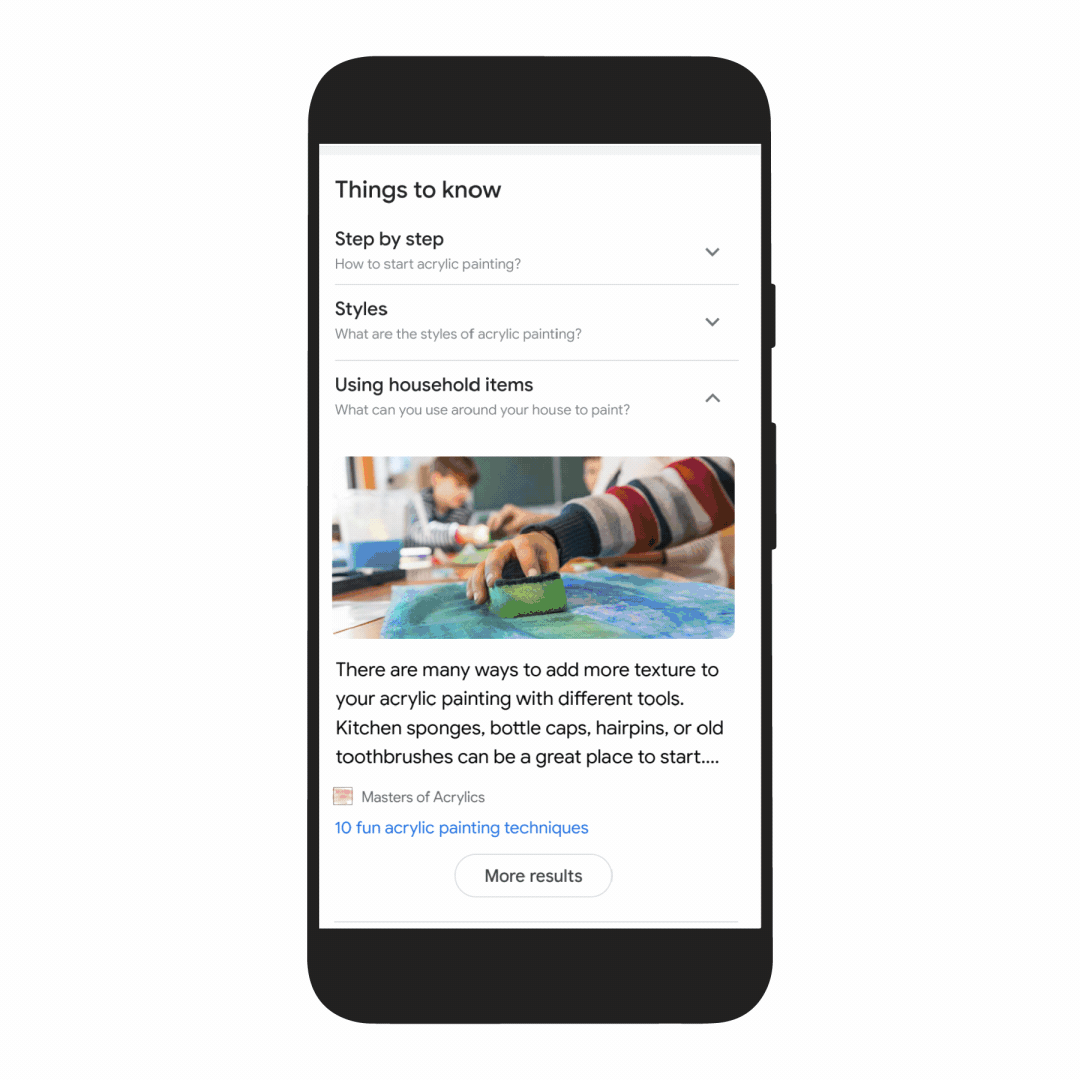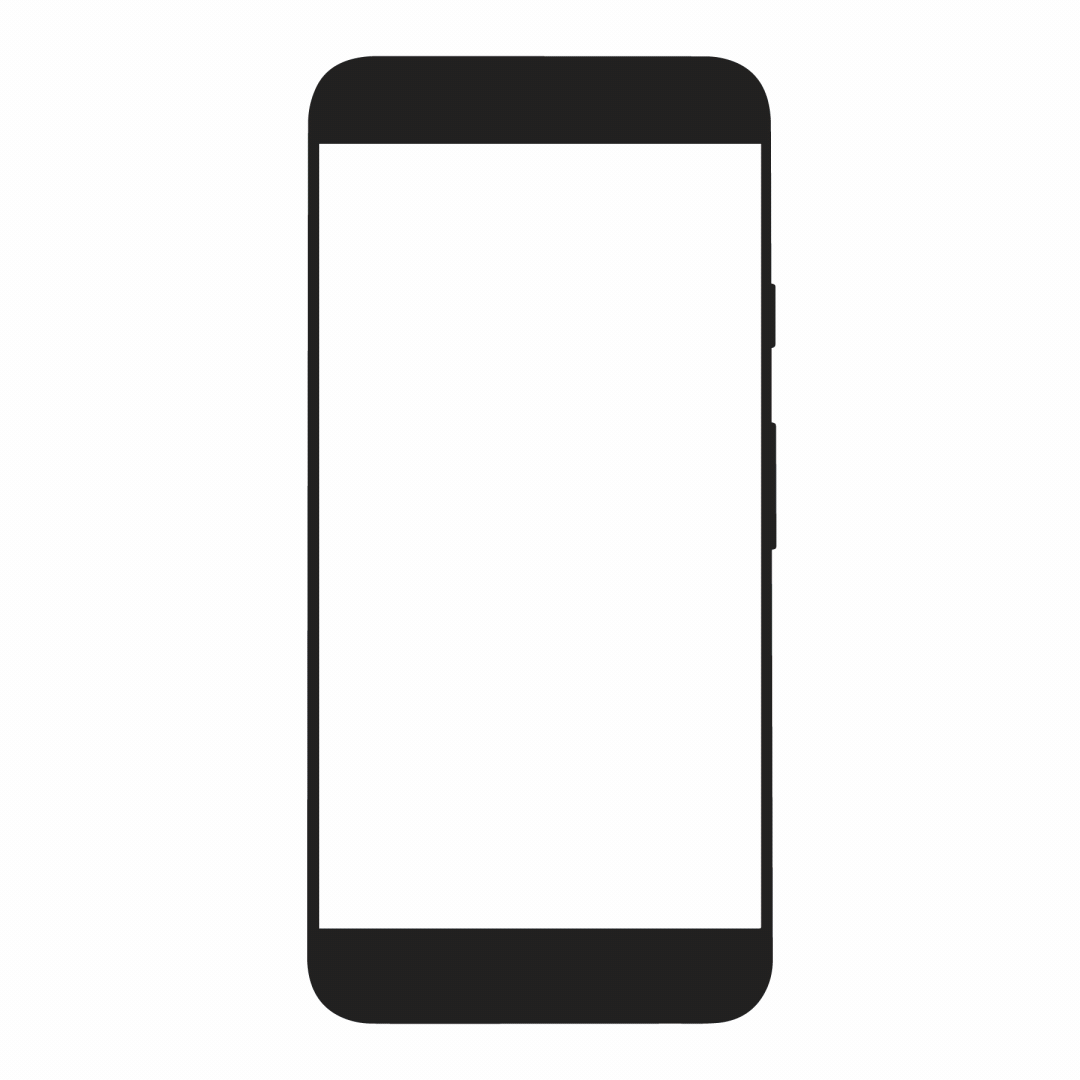
If you search for “acrylic painting,” Google understands how people typically explore this topic, and shows the aspects people are likely to look at first. For example, we can identify more than 350 topics related to acrylic painting, and help you find the right path to take.
We’ll be launching this feature in the coming months. In the future, MUM will unlock deeper insights you might not have known to search for — like “how to make acrylic paintings with household items” — and connect you with content on the web that you wouldn’t have otherwise found.
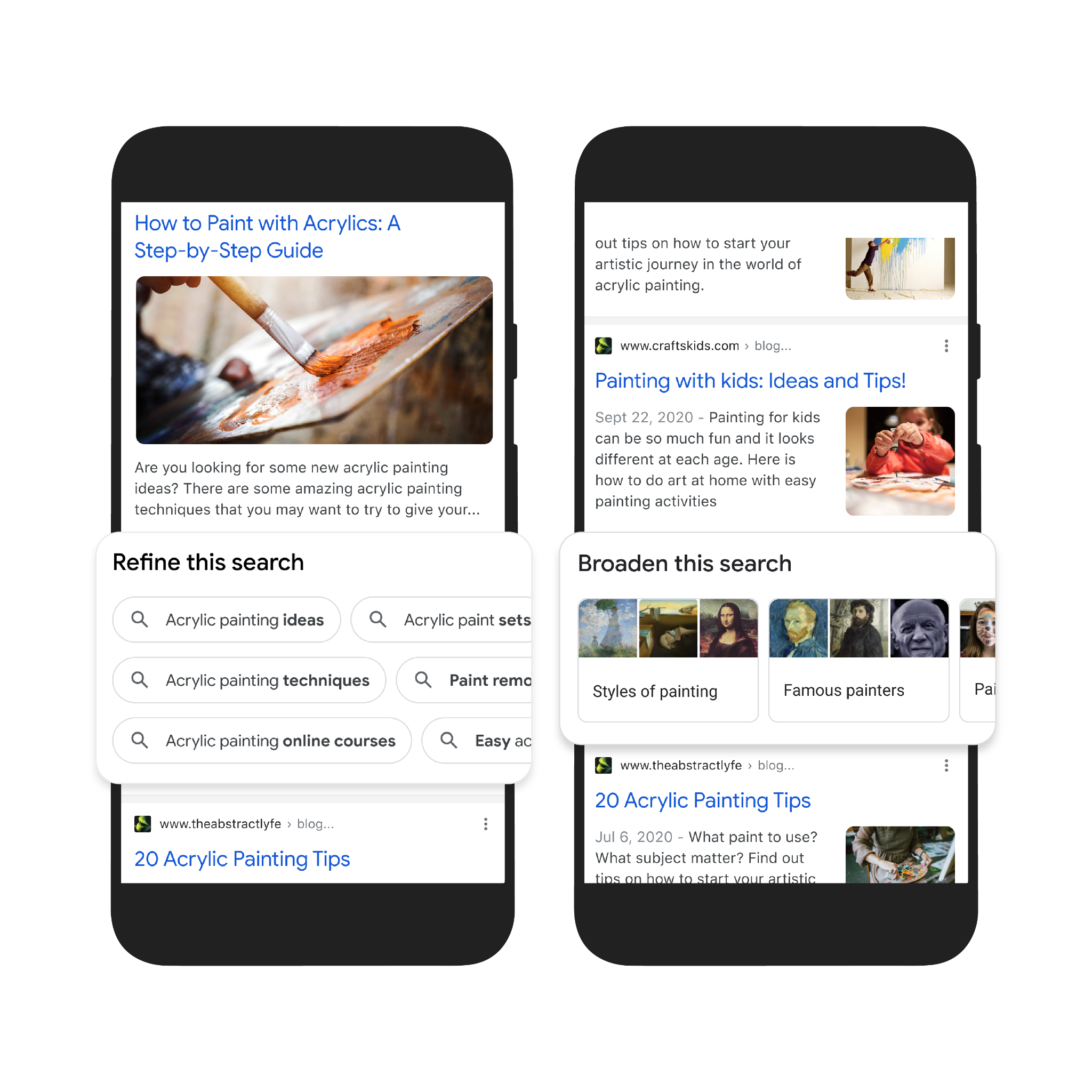
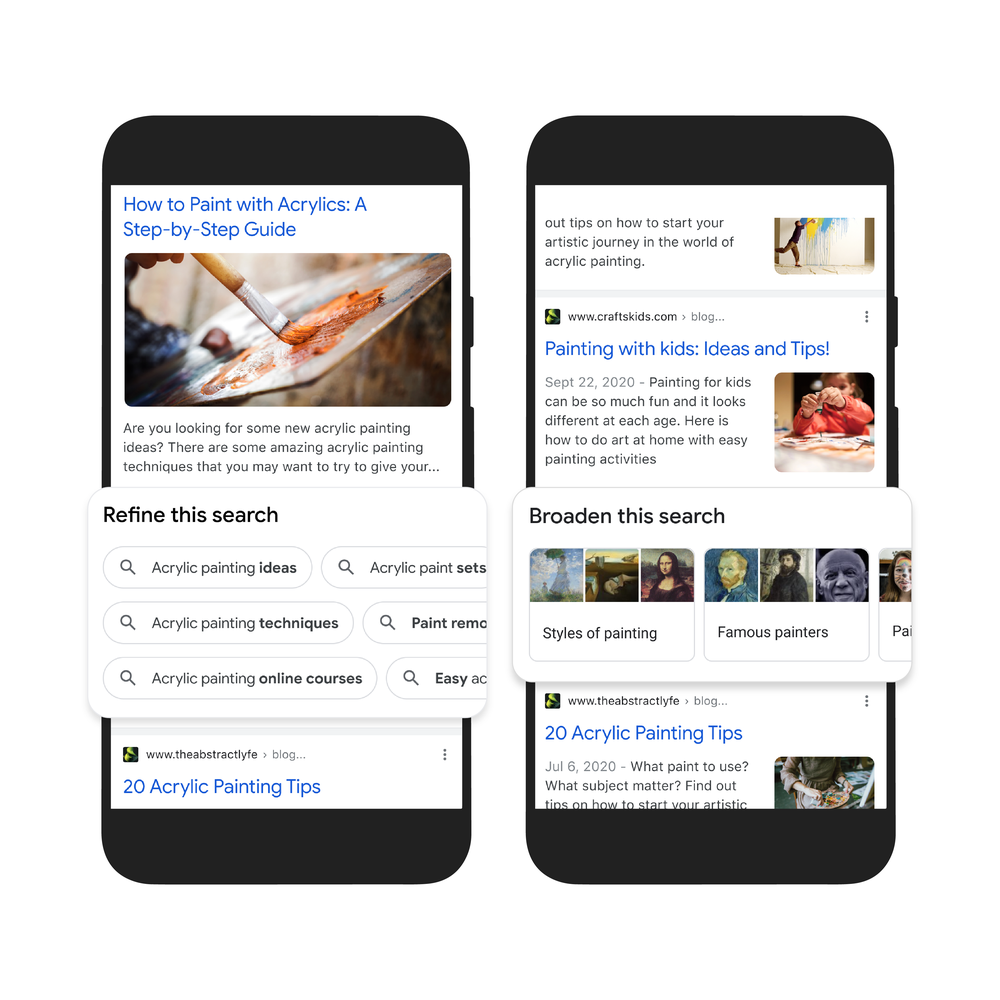
Second, to help you further explore ideas, we’re making it easy to zoom in and out of a topic with new features to refine and broaden searches.
In this case, you can learn more about specific techniques, like puddle pouring, or art classes you can take. You can also broaden your search to see other related topics, like other painting methods and famous painters. These features will launch in the coming months.

Third, we’re making it easier to find visual inspiration with a newly designed, browsable results page. If puddle pouring caught your eye, just search for “pour painting ideas" to see a visually rich page full of ideas from across the web, with articles, images, videos and more that you can easily scroll through.
This new visual results page is designed for searches that are looking for inspiration, like “Halloween decorating ideas” or “indoor vertical garden ideas,” and you can try it today.
Get more from videos
We already use advanced AI systems to identify key moments in videos, like the winning shot in a basketball game, or steps in a recipe. Today, we’re taking this a step further, introducing a new experience that identifies related topics in a video, with links to easily dig deeper and learn more.

Using MUM, we can even show related topics that aren’t explicitly mentioned in the video, based on our advanced understanding of information in the video. In this example, while the video doesn’t say the words “macaroni penguin’s life story,” our systems understand that topics contained in the video relate to this topic, like how macaroni penguins find their family members and navigate predators. The first version of this feature will roll out in the coming weeks, and we’ll add more visual enhancements in the coming months.
Across all these MUM experiences, we look forward to helping people discover more web pages, videos, images and ideas that they may not have come across or otherwise searched for.
A more helpful Google
The updates we’re announcing today don’t end with MUM, though. We’re also making it easier to shop from the widest range of merchants, big and small, no matter what you’re looking for. And we’re helping people better evaluate the credibility of information they find online. Plus, for the moments that matter most, we’re finding new ways to help people get access to information and insights.
All this work not only helps people around the world, but creators, publishers and businesses as well. Every day, we send visitors to well over 100 million different websites, and every month, Google connects people with more than 120 million businesses that don't have websites, by enabling phone calls, driving directions and local foot traffic.
As we continue to build more useful products and push the boundaries of what it means to search, we look forward to helping people find the answers they’re looking for, and inspiring more questions along the way.
Posted by Prabhakar Raghavan, Senior Vice President