Guest post by the Engineering team at Alfred Camera
Guest post by the Engineering team at Alfred Camera Please note that the information, uses, and applications expressed in the below post are solely those of our guest author, Alfred Camera.
In this article, we’d like to give you a short overview of Alfred Camera and our experience of using MediaPipe to transform our moving object feature, and how MediaPipe has helped to get things easier to achieve our goals.
What is Alfred Camera?
Fig.1 Alfred Camera Logo
Alfred Camera is a smart home app for both Android and iOS devices, with over 15 million downloads worldwide. By downloading the app, users are able to turn their spare phones into security cameras and monitors directly, which allows them to watch their homes, shops, pets anytime. The mission of Alfred Camera is to provide affordable home security so that everyone can find peace of mind in this busy world.
The Alfred Camera team is composed of professionals in various fields, including an engineering team with several machine learning and computer vision experts. Our aim is to integrate AI technology into devices that are accessible to everyone.
Machine Learning in Alfred Camera
Alfred Camera currently has a feature called Moving Object Detection, which continuously uses the device’s camera to monitor a target scene. Once it identifies a moving object in the area, the app will begin recording the video and send notifications to the device owner. The machine learning models for detection are hand-crafted and trained by our team using TensorFlow, and run on TensorFlow Lite with good performance even on mid-tier devices. This is important because the app is leveraging old phones and we'd like the feature to reach as many users as possible.
The Challenges
We had started building our AI features at Alfred Camera since 2017. In order to have a solid foundation to support our AI feature requirements for the coming years, we decided to rebuild our real-time video analysis pipeline. At the beginning of the project, the goals were to create a new pipeline which should be 1) modular enough so we could swap core algorithms easily with minimal changes in other parts of the pipeline, 2) having GPU acceleration designed in place, 3) cross-platform as much as possible so there’s no need to create/maintain separate implementations for different platforms. Based on the goals, we had surveyed several open source projects that had the potential but we ended up using none of them as they either fell short on the features or were not providing the readiness/stabilities that we were looking for.
We started a small team to prototype on those goals first for the Android platform. What came later were some tough challenges way above what we originally anticipated. We ran into several major design changes as some key design basics were overlooked. We needed to implement some utilities to do things that sounded trivial but required significant effort to make it right and fast. Dealing with asynchronous processing also led us into a bunch of timing issues, which took the team quite some effort to address. Not to mention debugging on real devices was extremely inefficient and painful.
Things didn't just stop here. Our product is also on iOS and we had to tackle these challenges once again. Moreover, discrepancies in the behavior between the platform-specific implementations introduced additional issues that we needed to resolve.
Even though we finally managed to get the implementations to the confidence level we wanted, that was not a very pleasant experience and we have never stopped thinking if there is a better option.
MediaPipe - A Game Changer
Google open sourced MediaPipe project in June 2019 and it immediately caught our attention. We were surprised by how it is perfectly aligned with the previous goals we set, and has functionalities that could not have been developed with the amount of engineering resources we had as a small company.
We immediately decided to start an evaluation project by building a new product feature directly using MediaPipe to see if it could live up to all the promises.
Migrating to MediaPipe
To start the evaluation, we decided to migrate our existing moving object feature to see what exactly MediaPipe can do.
Our current Moving Object Detection pipeline consists of the following main components:
- (Moving) Object Detection Model
As explained earlier, a TensorFlow Lite model trained by our team, tailored to run on mid-tier devices. - Low-light Detection and Low-light Filter
Calculate the average luminance of the scene, and based on the result conditionally process the incoming frames to intensify the brightness of the pixels to let our users see things in the dark. We are also controlling whether we should run the detection or not as the moving object detection model does not work properly when the frame has been processed by the filter. - Motion Detection
Sending frames through Moving Object Detection still consumes a significant amount of power even with a small model like the one we created. Running inferences continuously does not seem to be a good idea as most of the time there may not be any moving object in front of the camera. We decided to implement a gating mechanism where the frames are only being sent to the Moving Object Detection model based on the movements detected from the scene. The detection is done mainly by calculating the differences between two frames with some additional tricks that take the movements detected in a few frames before into consideration. - Area of Interest
This is a mechanism to let users manually mask out the area where they do not want the camera to see. It can also be done automatically based on regional luminance that can be generated by the aforementioned low-light detection component.
Our current implementation has taken GPU into consideration as much as we can. A series of shaders are created to perform the tasks above and the pipeline is designed to avoid moving pixels between CPU/GPU frequently to eliminate the potential performance hits.
The pipeline involves multiple ML models that are conditionally executed, mixed CPU/GPU processing, etc. All the challenges here make it a perfect showcase for how MediaPipe could help develop a complicated pipeline.
Playing with MediaPipe
MediaPipe provides a lot of code samples for any developer to bootstrap with. We took the Object Detection on Android sample that comes with the project to start with because of the similarity with the back-end part of our pipeline. It did take us sometimes to fully understand the design concepts of MediaPipe and all the tools associated. But with the complete documentation and the great responsiveness from the MediaPipe team, we got up to speed soon to do most of the things we wanted.
That being said, there were a few challenges we needed to overcome on the road to full migration. Our original pipeline of Moving Object Detection takes the input frame asynchronously, but MediaPipe has timestamp bound limitations such that we cannot just show the result in an allochronic way. Meanwhile, we need to gather data through JNI in a specific data format. We came up with a workaround that conquered all the issues under the circumstances, which will be mentioned later.
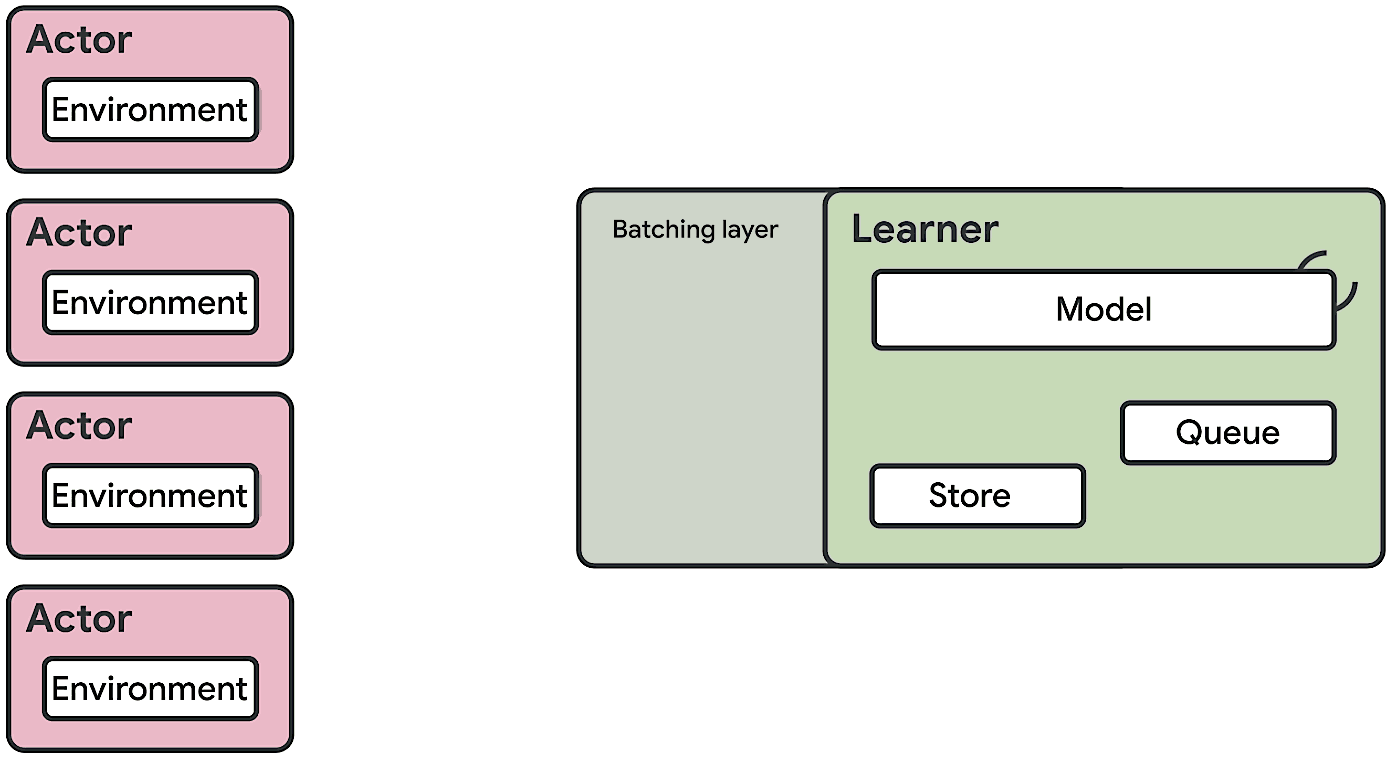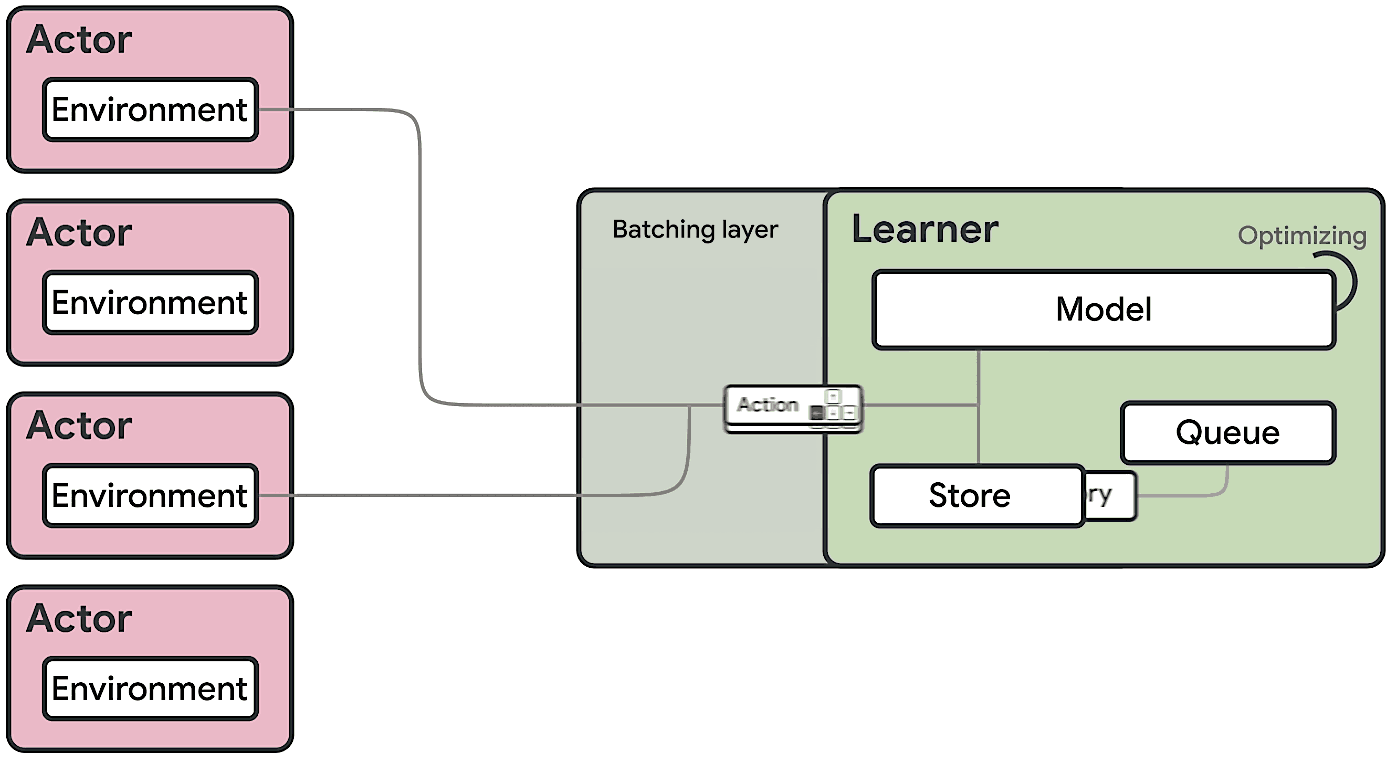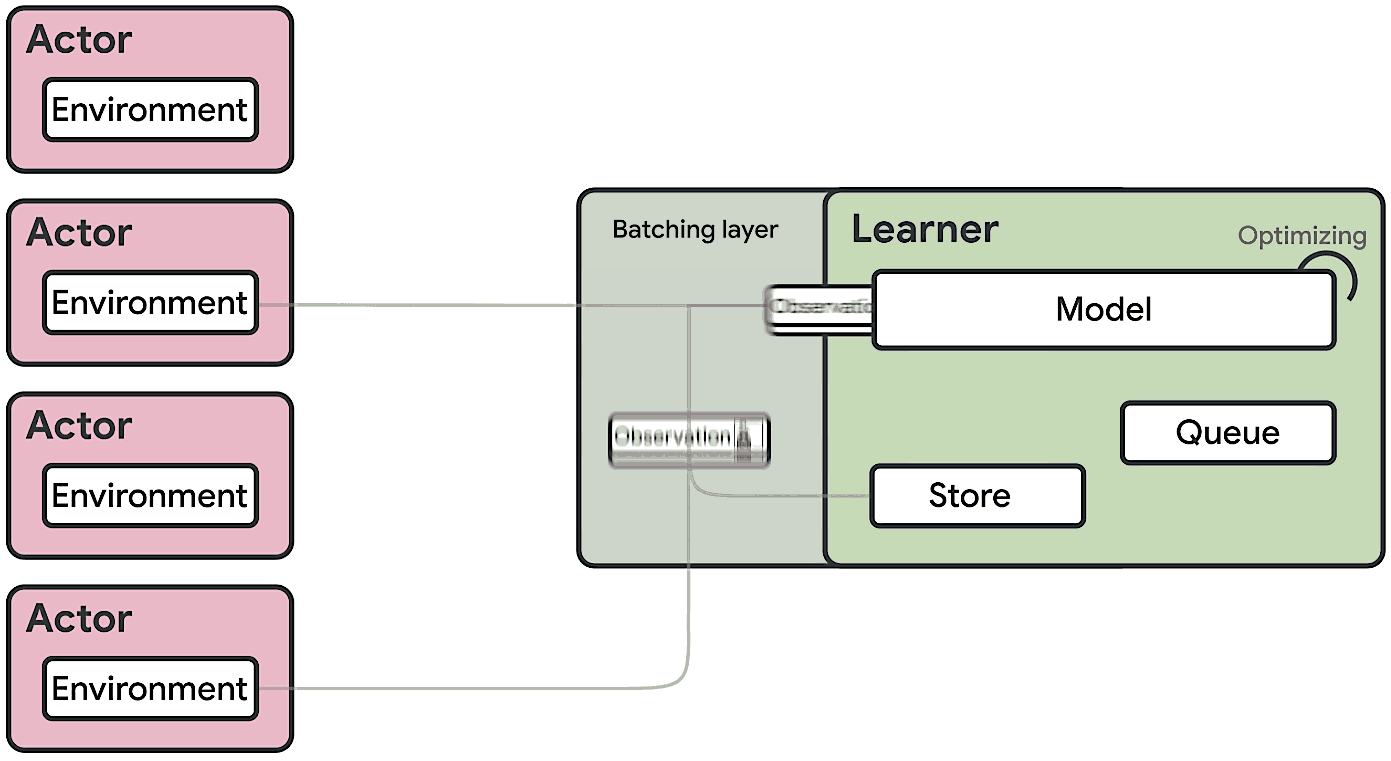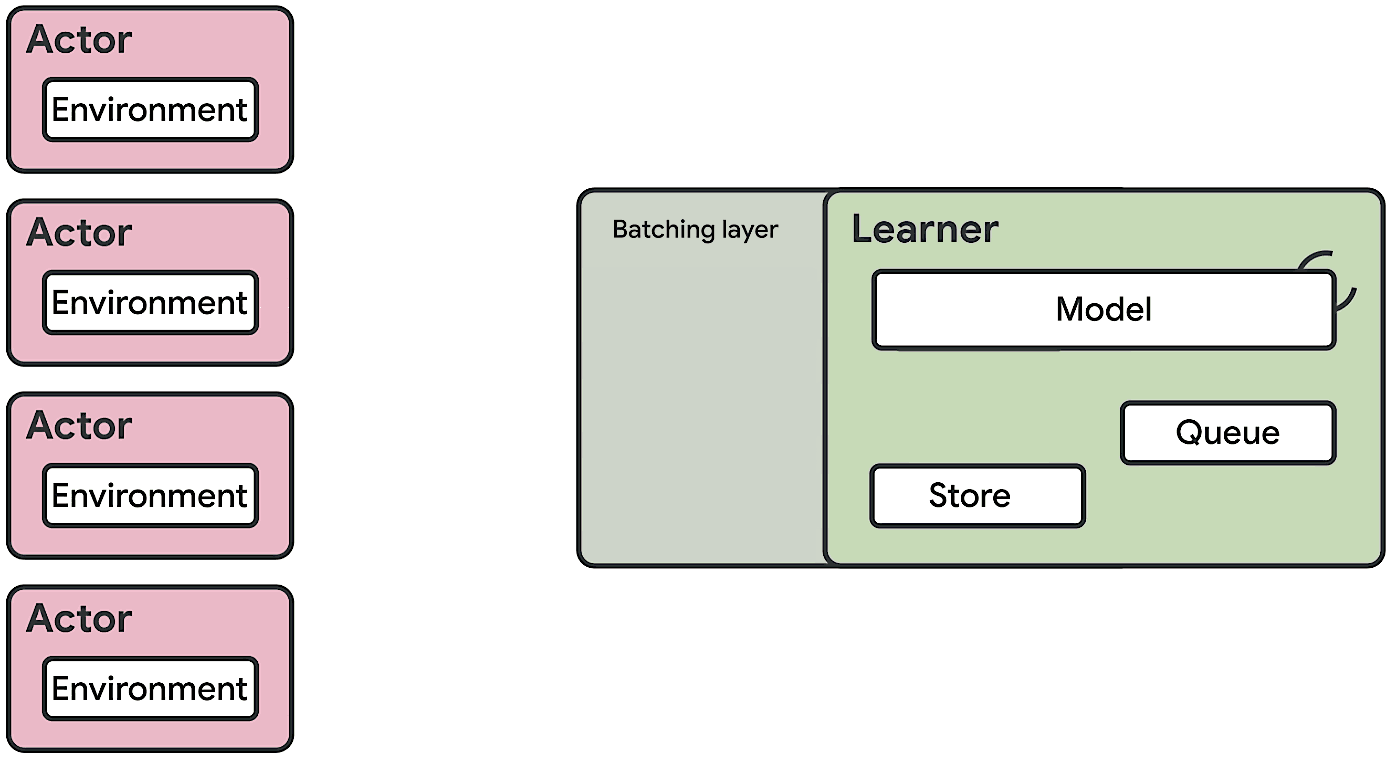
After wrapping our models and the processing logics into calculators and wired them up, we have successfully transformed our existing implementation and created our first MediaPipe Moving Object Detection pipeline like the figure below, running on Android devices:
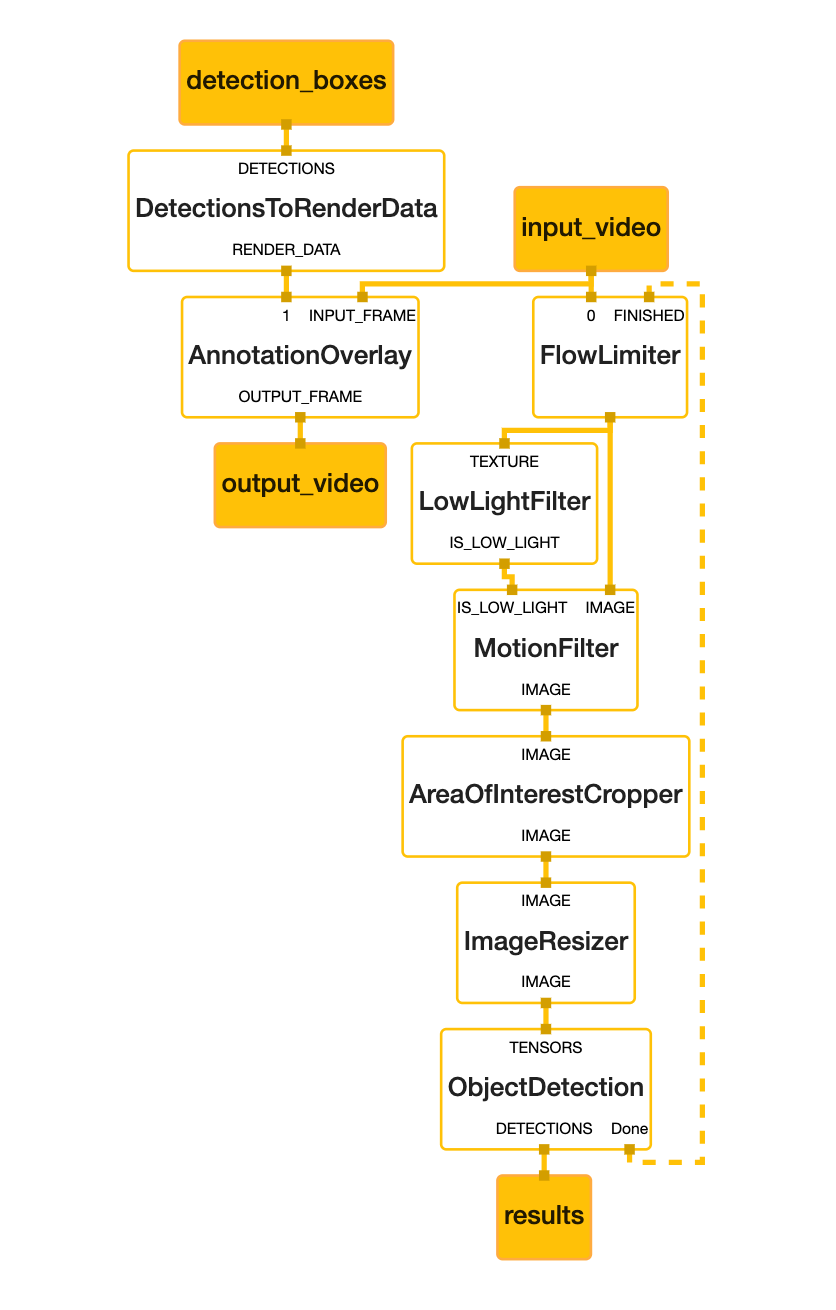
Fig.2 Moving Object Detection Graph
We do not block the video frame in the main calculation loop, and set the detection result as an input stream to show the annotation on the screen. The whole graph is designed as a multi-functioned process, the left chunk is the debug annotation and video frame output module, and the rest of the calculation occurs in the rest of the graph, e.g., low light detection, motion triggered detection, cropping of the area of interest and the detection process. In this way, the graph process will naturally separate into real-time display and asynchronous calculation.
As a result, we are able to complete a full processing for detection in under 40ms on a device with Snapdragon 660 chipset. MediaPipe’s tight integration with TensorFlow Lite provides us the flexibility to get even more performance gain by leveraging whatever acceleration techniques available (GPU or DSP) on the device.
The following figure shows the current implementation working in action:

Fig.3 Moving Object Detection running in Alfred Camera
After getting things to run on Android, Desktop GPU (OpenGL-ES) emulation was our next target to evaluate. We are already using OpenGL-ES shaders for some computer vision operations in our pipeline. Having the capability to develop the algorithm on desktop, seeing it work in action before deployment onto mobile platforms is a huge benefit to us. The feature was not ready at the time when the project was first released, but MediaPipe team had soon added Desktop GPU emulation support for Linux in follow-up releases to make this possible. We have used the capability to detect and fix some issues in the graphs we created even before we put things on the mobile devices. Although it currently only works on Linux, it is still a big leap forward for us.
Testing the algorithms and making sure they behave as expected is also a challenge for a camera application. MediaPipe helps us simplify this by using pre-recorded MP4 files as input so we could verify the behavior simply by replaying the files. There is also built-in profiling support that makes it easy for us to locate potential performance bottlenecks.
MediaPipe - Exactly What We Were Looking For
The result of the evaluation and the feedback from our engineering team were very positive and promising:
- We are able to design/verify the algorithm and complete core implementations directly on the desktop emulation environment, and then migrate to the target platforms with minimum efforts. As a result, complexities of debugging on real devices are greatly reduced.
- MediaPipe’s modular design of graphs/calculators enables us to better split up the development into different engineers/teams, try out new pipeline design easily by rewiring the graph, and test the building blocks independently to ensure quality before we put things together.
- MediaPipe’s cross-platform design maximizes the reusability and minimizes fragmentation of the implementations we created. Not only are the efforts required to support a new platform greatly reduced, but we are also less worried about the behavior discrepancies on different platforms due to different interpretations of the spec from platform engineers.
- Built-in graphics utilities and profiling support saved us a lot of time creating those common facilities and making them right, and we could be more focused on the key designs.
- Tight integration with TensorFlow Lite really saves lots of effort for a company like us that heavily depends on TensorFlow, and it still gives us the flexibility to easily interface with other solutions.
With just a few weeks working with MediaPipe, it has shown strong capabilities to fundamentally transform how we develop our products. Without MediaPipe we could have spent months creating the same features without the same level of performance.
Summary
Alfred Camera is designed to bring home security with AI to everyone, and MediaPipe has significantly made achieving that goal easier for our team. From Moving Object Detection to future AI-powered features, we are focusing on transforming a basic security camera use case into a smart housekeeper that can help provide even more context that our users care about. With the support of MediaPipe, we have been able to accelerate our development process and bring the features to the market at an unprecedented speed. Our team is really excited about how MediaPipe could help us progress and discover new possibilities, and is looking forward to the enhancements that are yet to come to the project.